cuda编程入门笔记
1. Hello Cuda
一个基本的hello cuda程序包含以下三个部分:
- GPU函数前加 __global__ 前缀,且核函数必须为void类型
- 调用GPU函数时指定资源: <<
- 使用同步函数
#include >> 线程块的个数与线程的个数
gpu<<<1,1>>>();
// 3. 加上cudaDeviceSynchronize(), 等待GPU代码执行完成,才能在cpu上恢复执行
cudaDeviceSynchronize();
return 0;
}
2. GPU基本知识
2.1 基本资源:网格(grid)、块(block)、线程(thread)
一块GPU拥有多个Grid,一个Grid含有多个Block,一个Block中含有多个Thread,每个Thread都可以并行处理一个程序,下图黑框表示一个Grid, 蓝色框表示Block,白色框表示 Thread

gridDim.x:表示一个Grid里面Block块数量(图示为2)
blockIdx.x:表示当前Block在Grid中的索引
blockDim.x:表示一个Block中x方向上Thread数量
threadIdx.x:表示当前Thread在对应Block中的索引
<<
启动核函数时,核函数代码在每个已配置的线程块中的每个线程中都执行;
2.2 创建多线程
设置 function<<<2, 2>>> 则表示创建两个block,每个block有2个线程来同时执行function函数:
#include >> 线程块的个数与线程的个数
gpu<<<2,2>>>(); //创建两个Block,每个block有2个thread来执行该函数
// 3. 加上cudaDeviceSynchronize(), 等待GPU代码执行完成,才能在cpu上恢复执行
cudaDeviceSynchronize();
return 0;
}
同时4个线程执行该函数,得到4个输出

若只需要在block 0 的 thread 0 来进行一些操作:就需要使用 blockIdx与 threadIdx,若只在第一个block的第一个thread输出,只需要将函数修改为:
__global__ void gpu(){
// 在第一个block的第一个thread输出
if(blockIdx.x ==0 && threadIdx.x==0) {
printf("hello gpu\n");
}
}
2.3 获取Grid中线程的唯一索引
// 一个block中的线程数量 * 当前block的Id + 当前线程在当前block中的id (将二维索引转换为1维索引)
int threadi = blockDim.x * blockIdx.x + threadIdx.x;
2.4 cuda显存分配
2.4.1 统一内存(UM)分配
cudaMallocManaged(&ptr, size):
该函数既可以为cpu预分配内存,也可以为gpu预分配内存,分配UM时,内存尚未驻留在主机或设备上。当主机或设备尝试访问内存时会发生 页错误,此时设备会将数据进行迁移。同理,当GPU尝试访问尚未驻留在显存上的数据时会触发缺页中断并将数据进行迁移,这个过程是耗时的。
#include 数据迁移cudaMemPrefetchAsync(&ptr, size, DeviceId):
在即将要在gpu上使用某个数据时提前开辟Gpu显存空间,避免缺页中断导致的效率低问题,同理在Gpu运算完成后,后面通过cpu处理该数据前需要在cpu预分配内存;
#include 例程
将数组中的每个元素扩大两倍
#include 输出:

2.4.2 手动内存分配
- cudaMalloc:将直接处于活动状态的 GPU 分配显存,可以防止出现所有的 GPU 分页错误,而代价是主机代码无法访问该命令返回的指针;
- cudaMallocHost: 将直接为 CPU 分配内存,该命令可 “固定” 内存(pinned memory) 或 “锁页”内存(page-lock memory),次举允许将内存异步拷贝至 GPU 或从 GPU 异步拷贝至内存。固定内存过多会干扰 cpu的性能。释放固定内存使用 cudaFreeHost 命令
- 无论是从主机到设备还是从设备到主机,cudaMemcpy命令均可以拷贝(非传输) 内存。
// 在cpu和gpu都注册一块内存
int *host_a, *device_a;
cudaMalloc(&device_a, size); // 在gpu上分配显存
initializeOnHost(host_a, N); // 将cpu内存空间初始化
// 将cpu内存上的值host_a拷贝到显存device_a上
cudaMemcpy(device_a, host_a, size, cudaMemcpyHostToDevice);
// 在gpu上执行核函数
kenel_function<<<blocks_num, thread_num, 0, someStream>>>(device_a, N);
// 将显存中的值拷device_a贝到cpu内存host_a中
cudaMemcpy(host_a, device_a, size, cudaMemcpyDeviceToHost);
verifyOnHost(host_a, N);
// 释放内存和显存
cudaFree(device_a);
cudaFreeHost(host_a);
3. 跨步循环
当数据量大于总的分配线程数时,需要将数据切分成块来运行,即以跨步循环的方式运行;如:当数组长度为32而注册的总线程数为8时,需要分4次来 循环处理数组中的元素。

#include 4. 异常处理
#include 5. 矩阵加法
#include 6. 流
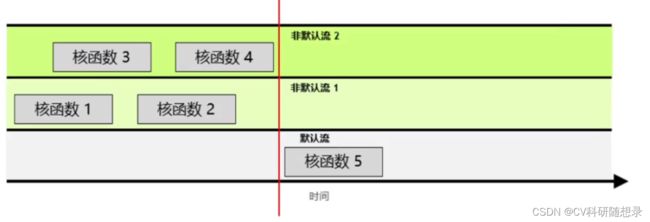
cuda中的流遵循以下规则:
- 指定流中的所有操作会按序执行;
- 非默认流之间的核函数的执行顺序是无法保证的;
- 默认流具有阻断能力,会等待其他流完成当前的操作后开始执行和函数,期间其他流无法执行和函数,直到默认流的该核函数执行完毕;
sudaStream_t stream; // 创建流
cudaStreamCreate(&stream);
// 执行核函数
kernel_function<<<blocks_num, threads_num, 0, stream>>>();
// 销毁流
cudaStreamDestroy(stream);