向量与矩阵、矩阵与矩阵的余弦相似度
向量与矩阵、矩阵与矩阵的余弦相似度
很简单,将公式套上就行了。
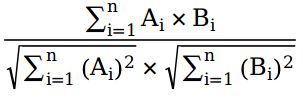
python 代码
import numpy as np
a = np.array([[1, 2, 1, 2, 3, 5, 6, 2]])
b = np.array([
[1, 2, 1, 2, 3, 5, 6, 2],
[1, 2, 1, 2, 3, 5, 6, 2],
[2, 3, 3, 2, 1, 2, 1, 1],
[2, 2, 1, 1, 1, 2, 4, 4]
])
c = np.array([
[1, 2, 1, 2, 3, 5, 6, 2],
[2, 1, 1, 2, 1, 2, 3, 3],
[2, 3, 3, 2, 1, 2, 1, 1],
[2, 2, 1, 1, 1, 2, 4, 4]
])
# 向量与向量的余弦相似度
def vector_vector(arr, brr):
# return arr.dot(brr.T) / (np.sqrt(np.sum(arr*arr)) * np.sqrt(np.sum(brr*brr)))
return np.sum(arr*brr) / (np.sqrt(np.sum(arr*arr)) * np.sqrt(np.sum(brr*brr)))
# 向量与矩阵的余弦相似度
def vector_matrix(arr, brr):
return arr.dot(brr.T) / (np.sqrt(np.sum(arr*arr)) * np.sqrt(np.sum(brr*brr, axis=1)))
# 矩阵与矩阵的余弦相似度
def matrix_matrix(arr, brr):
# return arr.dot(brr.T).diagonal() / ((np.sqrt(np.sum(arr * arr, axis=1))) * np.sqrt(np.sum(brr * brr, axis=1)))
return np.sum(arr*brr, axis=1) / (np.sqrt(np.sum(arr**2, axis=1)) * np.sqrt(np.sum(brr**2, axis=1)))
print(vector_vector(a, a))
print(vector_matrix(a, b))
print(matrix_matrix(b, c))
输出结果
1.0
[[1. 1. 0.68376346 0.85941947]]
[1. 0.87369775 1. 1. ]
另外,在像人脸识别这类底库巨大的情况下,可以先将底库的 L2 范式事先计算好,这样可以节省大量的时间,示例:
# -*- coding: utf-8 -*-
import numpy as np
import time
def vector_matrix(arr, brr):
return arr.dot(brr.T) / (np.sqrt(np.sum(arr*arr)) * np.sqrt(np.sum(brr*brr, axis=1)))
def vector_matrix_T(arr, brr, brr_l2):
return arr.dot(brr) / (np.sqrt(np.sum(arr*arr)) * brr_l2)
"""
测试条件
不使用 cuda,没有 cuda,只有 cpu
假设需要识别100个人,只统计相似度的时间,单个人脸特征长度为128,底库为100W
"""
# 当前检测到的人脸特征
faceFeat = np.random.random((128, ))
# 人脸底库特征
FeatDB = np.random.random((1000000, 128))
t1 = time.time()
for i in range(100):
sim = vector_matrix(faceFeat, FeatDB)
print("直接计算相似度耗时:", time.time() - t1)
t2 = time.time()
FeatDB_T = FeatDB.T
FeatDB_L2 = np.sqrt(np.sum(FeatDB*FeatDB, axis=1))
for i in range(100):
sim = vector_matrix_T(faceFeat, FeatDB_T, FeatDB_L2)
print("先计算L2,再计算相似度耗时:", time.time() - t2)
运行结果:
直接计算相似度耗时: 63.002615213394165
先计算L2,再计算相似度耗时: 5.581569194793701
这差距还是挺大的。