吴恩达《深度学习-序列模型》3 -- 序列模型和注意力机制
1. Basic model基础模型
例如将法语翻译成英语:
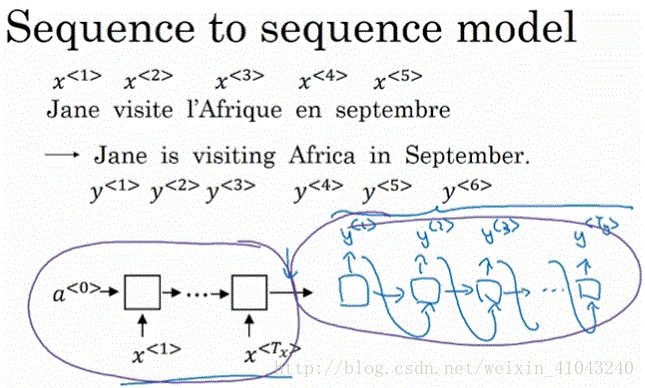
首先将法语单词逐个输入到CNN,这部分称为encoder network,然后一次输出一个英语单词,这部分称为decoder network。
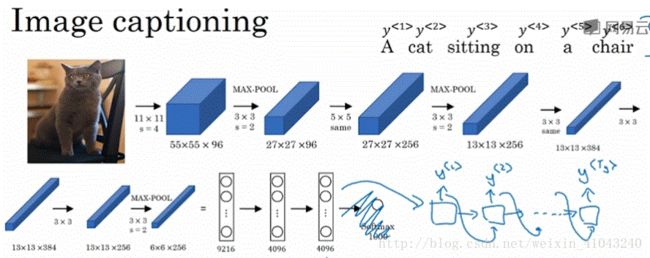
CNN结合RNN解读图片内容,如上图输入一副图像,生成一句描述图像的句子。
2.Picking the most likely sentence最优句子
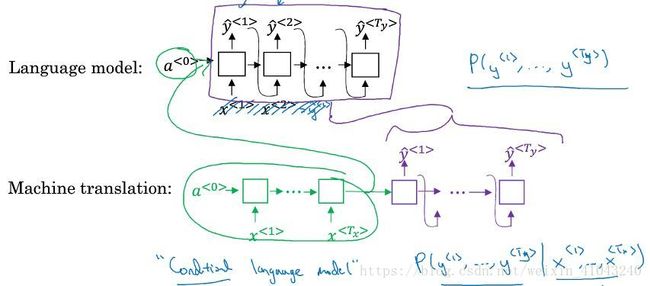
如图,是语言模型和机器翻译的流程对比,可以发现语言模型和机器翻译的decoder network部分非常相似,区别是语言模型的输入为0向量,所以输出为随机的一句话的概率。而机器翻译decoder network输入是非零向量,如果将机器翻译的encoder结果输入语言模型,语言模型的输出就是有输入决定的几句话的概率,称之为条件语言模型。
那么在输出的几句话中,如何选择最佳的一句呢?
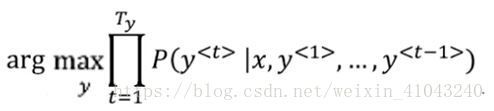
也就是找到能使条件概率最大的的序列,通常做法为Beam search集束搜索,下一节会讲。
为什么不用greedy search贪婪搜索呢?
贪婪搜索就是逐词的找到其概率最大的那个词,也就是先确定第一个词,找到其概率最大的词,然后确定第二个、第三个直到最后一个,这样产生的结果也不错,但我们需要的是最优序列,事实证明这样搜索通常很难找到我们所要的最佳序列
3. 序列模型—-定向搜索
Beam search集束搜索:
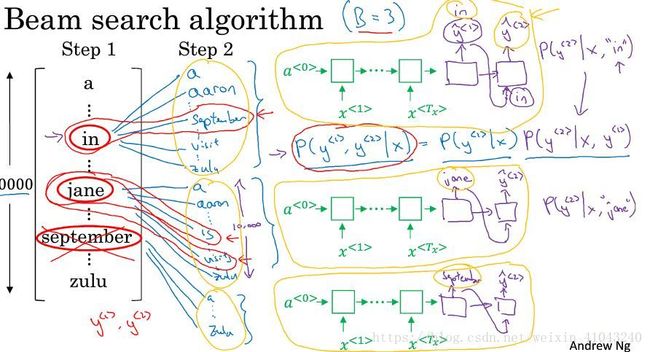
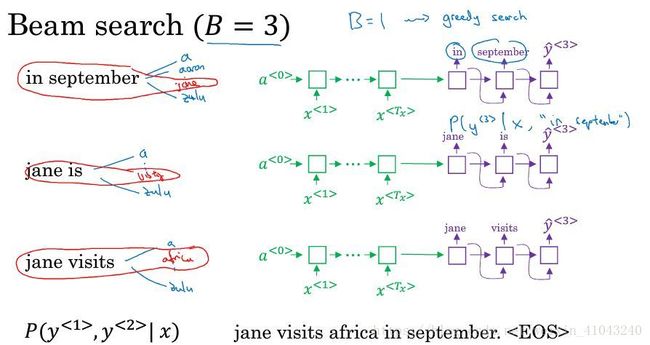
集束搜索也是逐词确定,但是与贪心搜索不同的是,它设置参数B(集束宽),对每个位置的词选择多个可能性较大的词,如B=3,那么对于第一个词来说,选择3个可能性最大的词,存到内存。
具体做法是:
1)将法语句子输入encoder network,然后输入softmax,输出第一个词 y<1> y < 1 > 的10000(词典长度)概率值 P(y<1>|x) P ( y < 1 > | x ) ,取前三个存起来。比如in,jane,september;

2)第二步是要选择第一个词和第二个词组合的可能性最大的前三个,第一个词有3种可能,对于每种可能,作为输入代入decoder的下一个单元,产生10000个概率值,也就是一共3*10000=30000个概率值 P(y<2>|x,y<1>) P ( y < 2 > | x , y < 1 > ) ,然后计算组合概率,公式如下:
选择概率最大的前3个,存入内存。
4. 序列模型—-改进定向搜索
长度归一化(length normalization)
定向搜索的目标是要最大化条件概率:
这样做有两个问题:
1)由于每一个概率P都是小于1的,多个小于1的数相乘,结果会越来越小,有可能小到超出float型的精度而无法表示,所以通常会取log,变成加法:
2)这样做通常会偏向较短的句子,因为较短的句子词少,因为每个词的概率都是小于1的数,所以乘的数越少那么结果就越大,解决办法就是用长度进行归一化,也就是除以长度:
在实际工作中有个实验性的做法,就是给长度 Ty T y 添加一个参数 α α :
通常 α=0.7 α = 0.7 ,虽然这样所并没有什么理论依据,但是这样做表现确实很好,有时候这个函数也叫做归一化的对数似然目标函数。
如何选择集束宽B
理论上B越大越好,但是B越大,计算代价也越高,对于产品系统来说通常B=10,对于学术研究来说B有可能取1000甚至更大的数。
总结:Beam search不像广度优先搜索BFS或深度优先搜索DFS等精确的搜索算法,它运算速度更快,但是不保证能找到最优结果。
5 定向搜索的误差分析

如图,人类翻译为理想结果,算法翻译跟人类翻译差异较大,这时候需要分析是RNN还是Beam搜索导致的这个问题,解决办法就是计算两个句子的概率:
-若人类翻译的概率大于算法翻译的概率,那么也就是Beam搜索并没有为我们找到最优的条件概率最大值,问题就在搜索算法;
-若人类翻译的概率小于等于算法翻译的概率,那么搜索算法没问题,就应该是RNN的问题。
以上是对单个例子来说的,但通常我们并不根据单个例子的结果采取行动,而是对多个误差样本进行分析,决定主因是谁,再采取行动。

如图是对多个误差样本分析的表格,At fault一列是原因,B代表Beam搜索算法,R代表RNN,通过这样的分析来定位主因。
6. Bleu score(Bilingual evaluation understudy)双语评估替补
作用:评估文本生成系统的单一实数评估指标,如机器翻译系统、图像描述系统等
具体做法,以机器翻译为例,给定一个或多个参考,一个机器翻译结果,然后逐词元的求机器翻译结果和给定参考的匹配概率,如先求一元词的匹配概率P1:

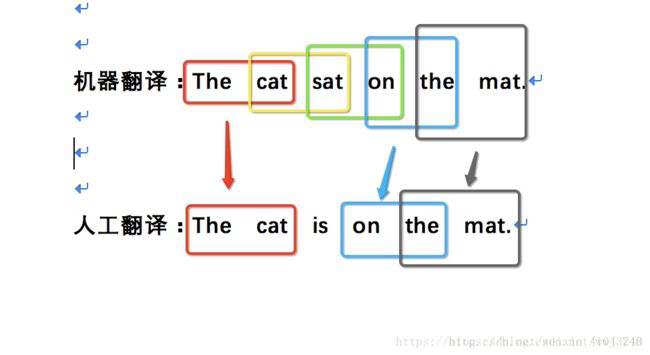
机器翻译句子是:The cat sat on the mat,找到这句话中所有在参考语句中出现的一元词在整句话中的占比,The cat on the mat这5个一元词都在参考语句中出现了,sat没有,所以匹配概率是 5/6。
但是这里有个问题那就是如果翻译句子是: the the the the the the the,显然这句翻译很不好,但这句话的一元词匹配概率却是P1=7/7,显然这是不合理的,所以定义一下有效词,也就是即使一个词出现在参考语句中,其有效个数不能超过其在参考语句中出现的次数,如上面的例子,the在参考语句1中出现了1词那么相对参考语句1其一元词匹配概率就是P1=1/7,换一句再试试,比如the cat the cat on the mat, the cat都出现了两次,但是在参考语句中只出现了一次,所以多出来的那次就是无效的,其匹配概率为P1=5/7。
到这里是计算了一元词的匹配概率,下面计算二元词的匹配概率P2:
如图,机器翻译的二元词有5组,其中有三组在人工翻译中出现了,那么其匹配概率就是P2=3/5;
同理可以算三元词、四元词等n元词。
计算出来之后,求均值,在这里为了防止短句子得分过高的情况,比如:The cat,其P1=P2=1,所以均值也是1,这是不合理的,所以这里增加一个参数BP惩罚因子,所以最终的计算公式为:
其中N为最高次元组,BP的取值见下图:

在实现过程中通常有封装好的函数,不需要自己实现。
具体参考博文https://blog.csdn.net/wwj_748/article/details/79686042
7. Attention model注意力机制
对于很长的句子,人工翻译的时候一般是一部分一部分的翻译,所以我们也希望RNN不要记忆太长的东西,而像人类一样一部分一部分的翻译,这样就引出了注意力机制,帮助决定将注意力放在多长的上下文上。
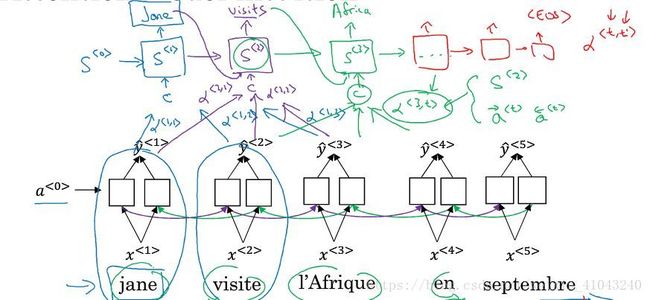
以法语翻译为英语为例,使用双向RNN,但是并不直接生成英语词y,而是将decoder部分增加一个注意力参数 α α 然后输入到一个新的RNN层,称之为S,比如 α<1,1> α < 1 , 1 > 表示生成第一个词的时候应该放多少注意力在第一个法语单词上, α<1,2> α < 1 , 2 > 表示生成第一个词的时候应该放多少注意力在第二个法语单词上,然后再由S层生成英语。下一节讲细节。
8 注意力机制的细节
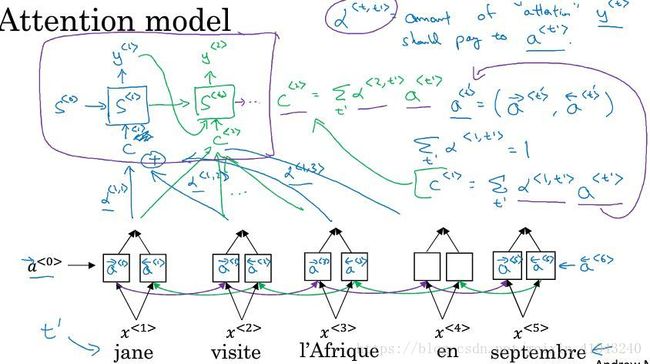
将法语单词逐个输入到RNN之后,计算前向传播和后向传播的激活值,然后用激活值乘以注意力参数,组合成context,context输入隐藏层S。
a<t′> a < t ′ > :表示输入法语单词的激活值(包括前向和后向)
α<t,t′> α < t , t ′ > :注意力参数,表示对于输出英语单词t应该放多少注意力在输入法语单词t’上,注意对于任意一个输出来说,其所有的注意力参数之和应该为1,即对于第t个输出单词来说 ∑t′α<t,t′>=1 ∑ t ′ α < t , t ′ > = 1
C:context,对于第t个单词来说其上下文环境 C<t>=∑t′α<t,t′>∗a<t′> C < t > = ∑ t ′ α < t , t ′ > ∗ a < t ′ >
接下来的问题就是注意力参数应该如何确定呢?

为了保证 ∑t′α<t,t′>=1 ∑ t ′ α < t , t ′ > = 1 我们采用了softmax,也就是把S层上一单元的预测结果 S<t−1> S < t − 1 > 以及所有的激活函数 a<t′> a < t ′ > 输入softmax函数,其输出为 e<t,t′> e < t , t ′ > 然后再根据上图公式计算注意力参数 α α 。
9 Speech Recognition语音识别
人耳能听到声音,是因为耳朵能够捕捉气压的变化。
预处理:
生成声谱图(spectrogram),为空白输出(false blank outputs)
以前语言学家认为用音位表示音频是做语音识别最好的方式,这种人工设计在小数据时代是必须的,但是在大数据时间人们发现在end-to-end模型中音位是不必要的,可以构建系统直接由输入的音频生成其文本。
语音识别方法:
1)用注意力模型实现语音识别
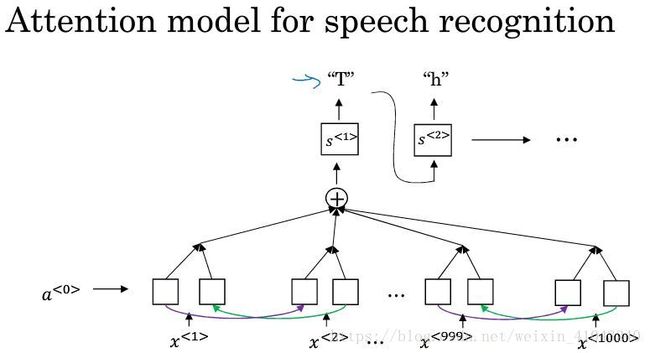
2)CTC损失函数和语音识别
这里举例用了单向的many-to-many结构的RNN,实际中更倾向于使用LSTM/GRU的双向RNN。语音识别的一个特点是输出可能会比输入少很多,CTC可以允许有空白字符输出,而且会把空白符和其之间的重复字符折叠。

10 Trigger Word Detection触发文字检测
这个功能玩过天猫精灵的伙伴应该很熟悉,只要你说“天猫精灵”,它就会被激活,不需要手动按开关,当你跟它说“安静”的时候,它就会停止一切活动进入睡眠状态
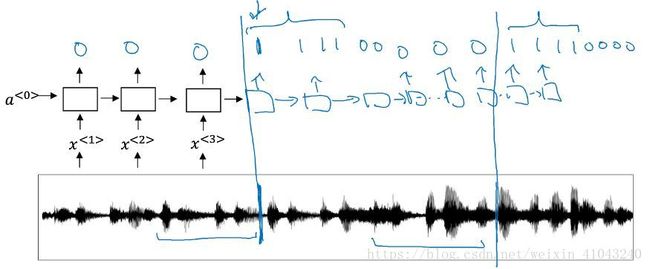
如图是解决触发文字检测的一种方法,预先设置检测标签为0,然后随着音频的输入,当检测到激活关键词的时候,就将标签置为1。