2021.3.25学习笔记
Keras中的Sequential
可以实现快速构建模型结构
Keras中的另外一个组件Application
中包含了大量的预训练模型组件,可以很方便的实现对自然场景的图像分类操作,当前支持的模型主要有如下:

这些模型全部兼容tensorflow、CNTK、Theano后台。这些模型在ImageNet数据集上的识别精度与模型技术参数见上表。
TFRecord 是什么?
TFRecord 是谷歌推荐的一种二进制文件格式,理论上它可以保存任何格式的信息。
uint64 length
uint32 masked_crc32_of_length
byte data[length]
uint32 masked_crc32_of_data
整个文件由文件长度信息、长度校验码、数据、数据校验码组成。
但对于我们普通开发者而言,我们并不需要关心这些,Tensorflow 提供了丰富的 API 可以帮助我们轻松读写 TFRecord 文件。
TFRecord 的核心内容在于内部有一系列的 Example ,Example 是 protocolbuf 协议下的消息体。
Google Protocol Buffer 协议
Google Protocol Buffer(简称 Protobuf)是一种轻便高效的结构化数据存储格式,可以用于结构化数据序列化,很适合做数据存储或 RPC 数据交换格式。它可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。目前提供了 C++、Java、Python、JS、Ruby等多种语言的 API。
为什么要用 TFRecord ?
TFRecord 也不是非用不可,但它确实是谷歌官方推荐的文件格式。
1、它特别适应于 Tensorflow ,或者说它就是为 Tensorflow 量身打造的。
2、因为 Tensorflow开发者众多,统一训练时数据的文件格式是一件很有意义的事情。也有助于降低学习成本和迁移成本。
————————————————
版权声明:本文为CSDN博主「frank909」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/briblue/article/details/80789608
创建 TFRecord 文件
因为深度学习很多都是与图片集打交道,那么,我们可以尝试下把一张张的图片转换成 TFRecord 文件。
利用tf.parse_single_example 读写tfrecord文件
如何使用 Google 开源的目标检测 API 来训练目标检测器
Google 开源的目标检测项目 object_detection 位于与 tensorflow 独立的项目 models(独立指的是:在安装 tensorflow 的时候并没有安装 models 部分)内:models/research/object_detection。models 部分的 GitHub 主页为:
https://github.com/tensorflow/models
要使用 models 部分内的目标检测功能 object_detection,需要用户手动安装 object_detection。
训练 TensorFlow 目标检测器
成功安装好 TensorFlow Object Detection API 之后,就可以按照 models/research/object_detection 文件夹下的演示文件 object_detection_tutorial.ipynb 来查看 Google 自带的目标检测的检测效果。其中,Google 自己训练好后的目标检测器都放在:
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
可以自己下载这些模型,一一查看检测效果。以下,假设你把某些预训练模型下载好了,放在models/ research/ object_detection 的某个文件夹下,比如自定义文件夹 pretrained_models。
要训练自己的模型,除了使用 Google 自带的预训练模型之外,最关键的是需要准备自己的训练数据。

python utils是一个小型python函数和类的集合
ipywidgets 包
可以实现 jupyter notebook 笔记本的交互式控件操作。也就是这个控件只能再jupyter notebook中使用,你再命令行下或其他IDE中时不能够使用的。它是基于网页的。
不管是Jupyter Notebook还是IPython Notebook,用过的人都知道,要想达成本地python-opencv一样窗口播放视频的效果是非常麻烦的。
现在给大家介绍一个新的方法,可以在jupyter网页开发时像opencv“窗口”一样播放视频、预览图片,甚至可以做一个在线播放器以查看远程服务器里的视频、图片文件,那就是使用ipywidgets里的Image控件。
ipywidgets.Image控件可以在Jupyter中开辟一个用于显示图片的窗口,与matplotlib.pyplot的figure不同的是,这个窗口支持随时更改其图片内容,而不需要使用IPython.display.clear_output来清除上一次的输出。
但问题是,ipywidgets.Image控件输入的value不是matplotlib与opencv支持的numpy格式的图片,而是流媒体格式,那么我们就要先把numpy图像数组转换成流媒体,方法就是cv2.imencode(’.jpg/.png/…’, img)[1].tobytes()。
CSI
CSI接口,图像采集和数据处理通过专门的数据通道和指令,使用显卡GPU。必须买这种接口的,不方便买。
USB的话,使用的是CPU。但是兼容性好,好买。
如果摄像头是个重要的考虑点,对帧率和分辨率有需求的话,用CSI。USB到时候CPU占用率太高。
安装Jetcam 使用CSI摄像头
from jetcam.csi_camera import CSICamera
camera = CSICamera(capture_device=0, width=224, height=224)
frame = camera.read()
这个变量frame便可以送入opencv进行运算处理了。capture_device不一定等于0,根据你的连接摄像头的端口来。
COCO
的 全称是Common Objects in COntext,是微软团队提供的一个可以用来进行图像识别的数据集。MS COCO数据集中的图像分为训练、验证和测试集。
MobileNetv2-SSDLite 实现以及训练自己的数据集
从 tensorflow 下载 MobileNetv2-SSDLite 的 tensorflow 模型到 ssdlite/ 路径,并解压。
Caffe
的全称应该是Convolutional Architecture for Fast Feature Embedding,它是一个清晰、高效的深度学习框架,它是开源的,核心语言是C++,它支持命令行、Python和Matlab接口,它既可以在CPU上运行也可以在GPU上运行。它的license是BSD 2-Clause
————————————————
版权声明:本文为CSDN博主「Cche1」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_27923041/article/details/77431833
MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17'
MODEL_FILE = MODEL_NAME + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')
NUM_CLASSES = 90
#github上有对应官方的各种模型,这些都是基于不用的数据集事先训练好的模型,下载好以后就可以直接调用。下载的文件以 '.tar.gz'结尾。'PATH_TO_CKPT'为‘.pb’文件的目录,'.pb'文件是训练好的模型(frozen detection graph),即用来预测时使用的模型。‘PATH_TO_LABELS’为标签文件,记录了哪些标签需要识别,'NUM_CLASSES'为类别的数目,根据实际需要修改。
、Model name上的名字与代码中“MODEL_NAME”后面变量的名字不一样,可以发现后者还有日期,在写代码的时候需要像后者那样将名字写完整,想得到完整的名字,可以直接在网站上点击对应的模型,弹出“另存为”对话框时就能够发现完整的“MODEL_NAME”,如下图所示。
第五部分Download Model 为下载模型,通过向对应网站发送请求进行下载解压操作。第六部分Load a (frozen) Tensorflow model into memory 将训练完的模型载入内存,第六部分Loading label map将标签map载入,这几个部分都不用修改,直接复制即可。
————————————————
版权声明:本文为CSDN博主「dy_guox」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/dy_guox/article/details/79111949
tf.Graph()
该函数非常重要,注意提现在两个方面
-
它可以通过tensorboard用图形化界面展示出来流程结构
-
它可以整合一段代码为一个整体存在于一个图中
tf.compat.v1.get_default_graph()
The returned graph will be the innermost graph on which a Graph.as_default() context has been entered, or a global default graph if none has been explicitly created.
NOTE: The default graph is a property of the current thread. If you create a new thread, and wish to use the default graph in that thread, you must explicitly add a with g.as_default(): in that thread’s function.
Returns:
The default Graph being used in the current thread.
————————————————
版权声明:本文为CSDN博主「于小勇」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_36670529/article/details/102799778
**
## 目标检测bounding box图像标注教程(使用LabelImg标注工具)
**
文字绘制——putText
TensorBoard
是用于可视化 TensorFlow 模型的训练过程的工具(the flow of tensors),在你安装 TensorFlow 的时候就已经安装了 TensorBoard
图像标注
COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的segmentation进行位置的标定。图像包括91类目标,328,000影像和2,500,000个label。目前为止有语义分割的最大数据集,提供的类别有80 类,有超过33 万张图片,其中20 万张有标注,整个数据集中个体的数目超过150 万个。
COCO有5种类型的标注,分别是:物体检测、关键点检测、实例分割、全景分割、图片标注,都是对应一个json文件。
————————————————
版权声明:本文为CSDN博主「持久决心」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u013832707/article/details/93710810
annotation{
"id" : int,
"image_id" : int,
"caption" : str,
}
YOLO V1


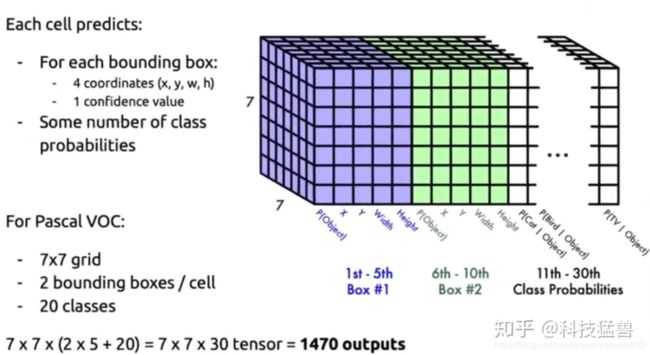
由于输入要是one-hot形式,所以最后我们设计了2个fc层(fully connencted layer),我们称之为“分类头”或者“决策层”。
检测层的设计:回归坐标值+one-hot分类

## 样本不均衡的问题解决了吗?
作者为了方便写成了求和的形式:
前2行计算前景的geo_loss。
第3行计算前景的confidence_loss。
第4行计算背景的confidence_loss。
第5行计算分类损失class_loss。
所以没有。计算背景的geo_loss,只计算了前景的geo_loss,这个问题YOLO v1回避了,依然存在。
检测器和分类器的输入输出有什么不一样
首先他们的输入都是image,但是分类器的输出是一个one-hot vector,而检测器的输出是一个框(Bounding Box)
不管你用什么形式去表达这个Bounding Box,你模型输出的结果一定是一个vector,那这个vector和分类模型输出的vector本质上有什么区别吗?
答案是:没有,都是向量而已,只是分类模型输出是one-hot向量,检测模型输出是我们标注的结果。
那分类模型可以用来做检测吗?
当然可以,这时,你可以把检测的任务当做是遍历性的分类任务。
先预设一个框的大小,然后在图片上遍历这个框.接下来要遍历框的大小。
这种方法其实就是RCNN全家桶的初衷,专业术语叫做:滑动窗口分类方法
现在需要你思考一个问题:这种方法的精确和什么因素有关?
答案是:遍历得彻不彻底。遍历得越精确,检测器的精度就越高。所以这也就带来一个问题就是:检测的耗时非常大。
backbone
backbone这个单词原意指的是人的脊梁骨,后来引申为支柱,核心的意思。在神经网络中,尤其是CV领域,一般先对图像进行特征提取(常见的有vggnet,resnet,谷歌的inception),这一部分是整个CV任务的根基,因为后续的下游任务都是基于提取出来的图像特征去做文章(比如分类,生成等等)。所以将这一部分网络结构称为backbone十分形象,仿佛是一个人站起来的支柱。
检测模型=特征提取器+检测头
R-CNN
利用预训练与微调解决标注数据缺乏的问题
采用在 ImageNet 上已经训练好的模型,然后在 PASCAL VOC 数据集上进行 fine-tune。
因为 ImageNet 的图像高达几百万张,利用卷积神经网络充分学习浅层的特征,然后在小规模数据集做规模化训练,从而可以达到好的效果。
现在,我们称之为迁移学习,是必不可少的一种技能。
R-CNN 系统分为 3 个阶段,反应到架构上由 3 个模块完成。
1.生产类别独立的候选区域,这些候选区域其中包含了 R-CNN 最终定位的结果。
2.神经网络去针对每个候选区域提取固定长度的特征向量。
3.一系列的 SVM 分类器。
YOLOV2
anchor是从数据集中统计得到的(Faster-RCNN中的Anchor的宽高和大小是手动挑选的)。
感受野
感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应输入图上的区域。


两层33卷积核操作之后的感受野是55
recall vs. complexity的trade off
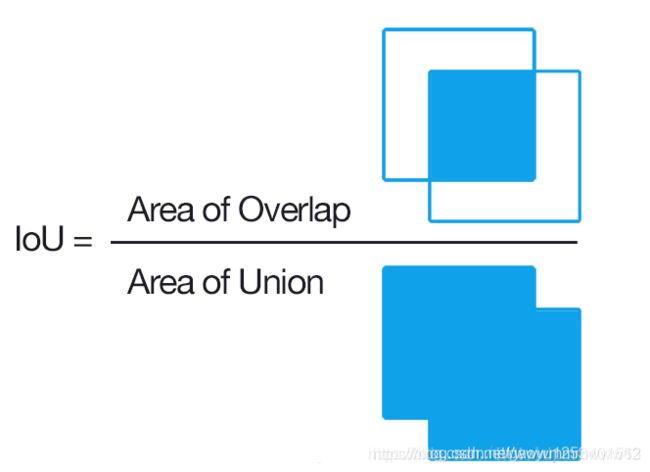
什么是IoU(Intersection over Union)
IoU是一种测量在特定数据集中检测相应物体准确度的一个标准。IoU是一个简单的测量标准,只要是在输出中得出一个预测范围(bounding boxex)的任务都可以用IoU来进行测量。为了可以使IoU用于测量任意大小形状的物体检测,我们需要:
ground-truth bounding boxes(人为在训练集图像中标出要检测物体的大概范围)
我们的算法得出的结果范围。
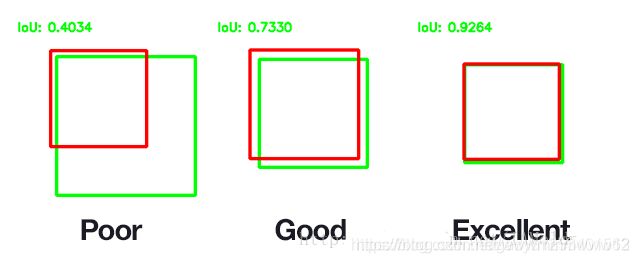
也就是说,这个标准用于测量真实和预测之间的相关度,相关度越高,该值越高。如下图所示。绿色标线是人为标记的正确结果(ground-truth),红色标线是算法预测的结果(predicted)。

目标检测中如何对忽略的GT目标进行处理?
数据集存在某片区域的目标太小且密集了,所以该区域被标定为忽略区域,精度计算时会忽略该区域的所有目标。
现在训练模型时我想让模型对忽略区域不计算损失(正负Loss),这个想法该如何实现呢?
尝试过将该区域直接涂黑,同时去除忽略区域的GT,但效果并不好,反而精度下降了。
YOLO V3
正样本:与GT的IOU最大的框。
负样本:与GT的IOU<0.5 的框。
忽略的样本:与GT的IOU>0.5 但不是最大的框。
使用 tx 和ty (而不是 bx 和by )来计算损失。
Mosaic数据增强
把4张图片,通过随机缩放、随机裁减、随机排布的方式进行拼接。根据论文的说法,优点是丰富了检测物体的背景和小目标,并且在计算Batch Normalization的时候一次会计算四张图片的数据,使得mini-batch大小不需要很大,一个GPU就可以达到比较好的效果。

优点
丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好
减少GPU:直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果
缺点
如果我们的数据集本身就有很多的小目标,那么Mosaic数据增强会导致本来较小的目标变得更小,导致模型的泛化能力变差
SAT自对抗训练
为什么会产生对抗样本
训练样本集不可能覆盖所有的可能性,并且很可能只能覆盖一小部分,所以不可能从中训练出一个覆盖所有样本特征的模型
用模型训练分类问题的时候,目标是如何更好的分类,所以模型会尽量扩大样本和boundary之间的距离,扩大每一个class区域的空间。这样做的好处是让分类更容易,但坏处是也在每一个区域里包括了很多并不属于这个class的空间。
生成对抗样本的方法
在一个黑盒攻击中,我们能够得知模型对应的输入输出,由于对抗样本存在的必然性,理论上,我们只需要在原样本中随机的添加扰动,然后不断暴力尝试,测试是否攻击成功即可。
黑盒攻击就是已知输入输出的对应关系,攻击者去寻找对抗样本来实现对模型的攻击。而白盒攻击就是已知模型的所有结构和知识,来实现对模型的攻击。在论文Practical Black-Box Attacks against Machine Learning中,提出对于模型的黑盒攻击可以通过观察其输入输出的对应关系,构造一个相似的机器学习模型,然后对其进行白盒攻击,得到的对抗样本通常也具有迁移性,能够对需要攻击的黑盒达到很高的成功率。
在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。
在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。
在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。
但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。