为了小论文之跟着李沐学AI(十二)
NiN网络

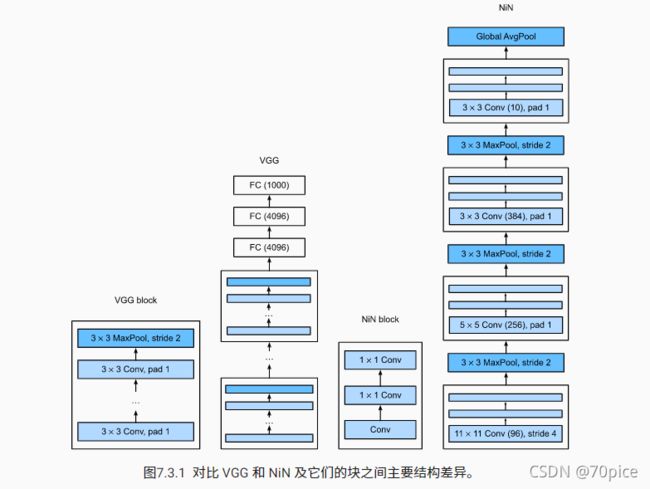
其实在前面我们也说过,我们是把宽高的信息,拉给了通道,现在我们把通道当特征来进行计算,进行融合。
import torch
from torch import nn
from d2l import torch as d2l
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2),
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
# 将四维的输出转成二维的输出,其形状为(批量大小, 10)
nn.Flatten())
GoogLeNet
在理解这个网络之前,我不得不吐槽一下。咱就是说,这个卷积这一块都没有什么大的变化呀,都是卷积层的叠加,对通道数的变化,其核心还是看谁机器多跑得快呗。
在这之前,对于卷积核的大小,对于通道数的选择,都是没有定数的,那么在GoogleNet中,他就解决了这个问题(其实也不算解决吧,可恶,就仗着自己有钱,把东西全部包括进去了)
在GoogleNet中,代替VGG块的一个结构是Inception
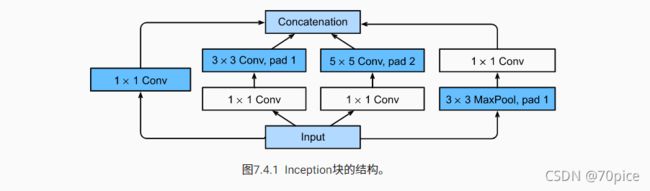
对于一个input,我们进行了一个进行了多个途径的特征提取并且进行汇总
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Inception(nn.Module):
# `c1`--`c4` 是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1 x 1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1 x 1卷积层后接3 x 3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1 x 1卷积层后接5 x 5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3 x 3最大汇聚层后接1 x 1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
最终的一点在于cat这个函数,它最后会把每一个卷积层的输出,在维度上进行拼接,如果说一个像素是一个样本点,就是增加了这个样本的维数,这个就是GoogleNet真的血马简单