机器学习之K-means、Canopy聚类
一、K-means算法
K-均值算法是发现给定数据集的k个簇的算法,簇个数是用户给定的,每一个簇通过其质心(centroid)即簇中所有点的中心来描述。
1、K-均值算法的流程:
(1)对于输入样本集 {x1,x2,...,xm},随机确定k个质心 {μ1,μ2,...,μk};
(2)计算每个样本xj到各个质心μi的欧式距离:dji=||xj-μi||2;
(3)根据距离最近的μ确定样本xj的簇标记:labelj=arg minidji;
(4)循环将数据集中的每个样本分配到各个簇中(染色),每个簇的样本数量为N1,N2,...,Nk;
(5)更新每个簇的质心的位置,为该簇所有样本的均值;

(6)重复上述步骤(染色分配-移动质心-重新染色-再次移动...),直到所有的质心均不再更新;或者达到设定的某个终止条件,如最大迭代次数、最小调整幅度阈值、最小平方误差MSE等。

2、K-means效果度量及改进方法
可以使用误差平方和SSE度量聚类效果,SSE值越小说明样本点越接近于它们的质心,聚类效果越好。由于对误差取了平方,因此更加重视那些远离质心的点。
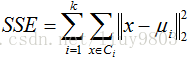
由于质心随机初始化导致K-means算法效果可能不是很好,不同的初值可能导致不同的簇划分结果,因此可以选取多种不同的初值,然后选择SSE最小的一个。另一种改进的方法是对生成的簇进行后处理,如将最大SSE分值的簇划分为两个簇,或者在包含样本数最多的簇运行K-means算法。
在不增加簇个数的情况下,改进的方法有:合并距离最近的质心,或者合并两个使总SSE增幅最小的质心。
K-means算法在迭代的过程中使用所有点的均值作为新的中心点,如果簇中存在异常点,将导致均值偏差比较严重。因此可以根据数据集的特点采取不同的聚类算法,如K-medoids、K-medians、kernel trick等。
Medians、medoids的区别(详见Wikipedia k-medians clustering)
The median is computed in each single dimension in the Manhattan-distance formulation of the k-medians problem, so the individual attributes will come from the dataset. This makes the algorithm more reliable for discrete or even binary data sets. In contrast, the use of means or Euclidean-distance medians will not necessarily yield individual attributes from the dataset. Even with the Manhattan-distance formulation, the individual attributes may come from different instances in the dataset; thus, the resulting median may not be a member of the input dataset.
This algorithm is often confused with the k-medoids algorithm. However, a medoid has to be an actual instance from the dataset, while for the multivariate Manhattan-distance median this only holds for single attribute values. The actual median can thus be a combination of multiple instances. For example, given the vectors (0,1), (1,0) and (2,2), the Manhattan-distance median is (1,1), which does not exist in the original data, and thus cannot be a medoid.
3、K-means的优缺点
优点:
|
理解、实现容易; |
当数据集近似高斯分布时,聚类效果非常不错; |
|
处理大数据集的时候可以保证较好的伸缩性,时间复杂度为O(nkt),其中n为数据集样本数量,t为迭代次数。 |
|
缺点: |
k值需要调参,不同的值得到的结果不一样; |
对初始质心点敏感,离群值对模型的影响比较大; |
|
不适合非凸形状的簇、大小差别较大的簇; |
|
可能收敛到局部极小值,在大规模数据集上收敛较慢。 |
二、二分K-means算法
为了克服K-means算法容易收敛于局部极小值的问题,可以使用bisecting K-means算法弱化随机初始质心的影响。该算法首先将所有的样本作为一个簇,然后根据某种规则将该簇一分为二;之后选择其中一个簇继续划分,直到达到停止条件(聚簇数量、迭代次数、最小SSE等)。
选择划分聚簇的规则一般有两种:
(1)选择样本量最大的簇进行划分;
(2)选择SSE值最大的簇进行划分。
伪代码如下:
将所有样本作为一个簇
当簇数目小于k时
对于每一个簇
计算总误差SSE
将给定的簇划分,对其进行k=2的K-means聚类
计算将该簇一分为二后的总误差
选择使总误差最小的那个簇进行划分操作
三、K-means++算法
K-means++算法可以解决K-means对初始质心比较敏感的问题,算法的区别主要在于选择的初始k个质心的之间的相互距离要尽可能的远。
K-means++算法的流程是:
(1)从数据集中随机选择一个样本作为第一个质心;
(2)对数据集中的每个样本,计算它到所有已有质心的距离的总和D(x);
(3)采用线性概率选择出下一个聚类中心点,即D(x)较大的点成为新增质心的概率较大;
(4)重复步骤2直到找到k个聚类中心点
(5)使用得到的k个质心作为初始化质心运行K-means算法。
K-means++算法的缺点:
(1)有可能选中离群点作为质心;
(2)计算距离质心最远的点的开销比较大;
(3)由于质心的选择过程中的内在有序性(第k个质心的选择依赖前k-1个质心的值),在扩展方面存在着性能问题。
四、K-means||算法
解决K-means++算法缺点而产生的一种算法,主要思路是改变每次遍历时候的取样规则,并非按照K-means++算法每次遍历只获取一个样本,而是每次获取k个样本,重复该取样操作logm次,然后再将这些抽样出来的样本聚类出k个质心,作为K-means算法的初始质心。实践证明,一般只需要5次重复采样就可以得到比较好的初始质心。
五、Mini Batch K-means算法
Mini Batch K-means算法是K-means算法的一种优化变种,采用随机抽取的小规模数据子集训练算法,减少计算时间,同时试图优化目标函数。Mini Batch K-means算法可以减少K-means算法的收敛时间,而且产生的结果一般只略差于K-means算法。
算法步骤如下:
(1)首先抽取数据集部分样本,使用K-means构建出k个质心的模型;
(2)继续抽取数据集中的部分样本,将其添加到模型中,分别分配给距离最近的质心;
(3)更新质心的位置;
(4)循环迭代(2、3)步操作,直到质心稳定或者达到指定迭代次数,停止计算。
六、Canopy算法
Canopy属于一种‘粗’聚类算法,即使用一种简单、快捷的距离计算方法将数据集分为若干可重叠的子集canopy,这种算法不需要指定k值、但精度较低,可以结合K-means算法一起使用:先由Canopy算法进行粗聚类得到k个质心,再使用K-means算法进行聚类。
Canopy算法步骤如下:
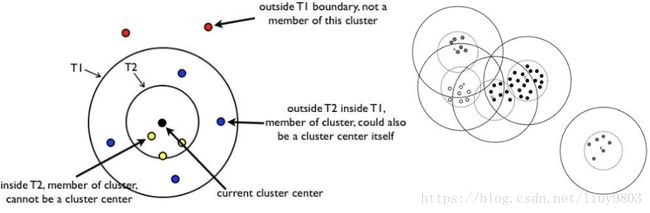
(1)将原始样本集随机排列成样本列表L=[x1,x2,...,xm](排列好后不再更改),根据先验知识或交叉验证调参设定初始距离阈值T1、T2,且T1>T2 。
(2)从列表L中随机选取一个样本P作为第一个canopy的质心,并将P从列表中删除。
(3)从列表L中随机选取一个样本Q,计算Q到所有质心的距离,考察其中最小的距离D:
如果D≤T1,则给Q一个弱标记,表示Q属于该canopy,并将Q加入其中;
如果D≤T2,则给Q一个强标记,表示Q属于该canopy,且和质心非常接近,所以将该canopy的质心设为所有强标记样本的中心位置,并将Q从列表L中删除;
如果D>T1,则Q形成一个新的聚簇,并将Q从列表L中删除。
(4)重复第三步直到列表L中元素个数为零。
注意:
(1)‘粗’距离计算的选择对canopy的分布非常重要,如选择其中某个属性、其他外部属性、欧式距离等。
(2)当T2
(3)T1、T2的取值影响canopy的重叠率及粒度:当T1过大时,会使样本属于多个canopy,各个canopy间区别不明显;当T2过大时,会减少canopy个数,而当T2过小时,会增加canopy个数,同时增加计算时间。
(4)canopy之间可能存在重叠的情况,但是不会存在某个样本不属于任何canopy的情况。
(5)Canopy算法可以消除孤立点,即删除包含样本数目较少的canopy,往往这些canopy包含的是孤立点或噪音点。
七、scikit-learn相关API
1、生成聚类数据集的方法:

返回产生的样本集数组X和每个样本的簇标签数组Y。
n_samples:数据集样本总数,默认值为100个;
n_features:每个样本的维度,默认为2维;
centers:产生的质心点个数,默认为3个;
cluster_std:数据集的标准差,默认值为1.0;
center_box:质心确定后的数据边界,默认值(-10.0, 10.0)。
2、K-means聚类算法:

返回质心数组、簇标记以及所有样本与离它最近的质心距离的平方和。
n_clusters:k的数量,默认为8个;
init:初始化方法,可以使用K-means++、random、或自定义的ndarray,默认使用K-means++;
max_iter:最大迭代次数;
tol:容忍度/阈值,即算法收敛的条件。
3、Mini Batch K-means算法:

类似K-means。
batch_size:数据子集的规模
max_no_improvement:连续多少个小批量聚类计算后效果没有改善,就停止算法。默认值是10,如果不想使用这个参数可以设置为None。