手撕Pytorch源码#3.Dataset类 part3
写在前面
手撕Pytorch源码系列目的:
通过手撕源码复习+了解高级python语法
熟悉对pytorch框架的掌握
在每一类完成源码分析后,会与常规深度学习训练脚本进行对照
本系列预计先手撕python层源码,再进一步手撕c源码
版本信息
python:3.6.13
pytorch:1.10.2
本博文涉及python语法点
泛型类Union和Optional
__getattr__方法
Iterable,Iterator和forloop
functools.partial
MRO与C3算法
目录
[TOC]
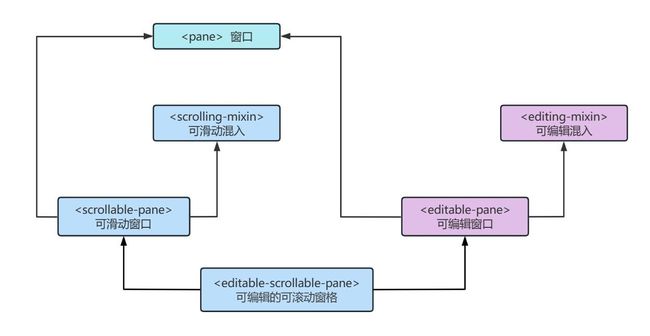
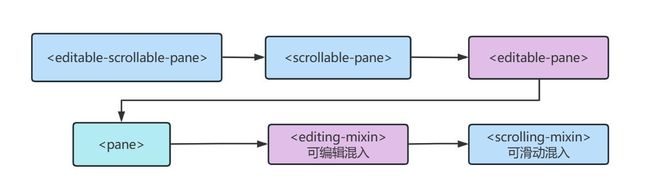
零、流程图
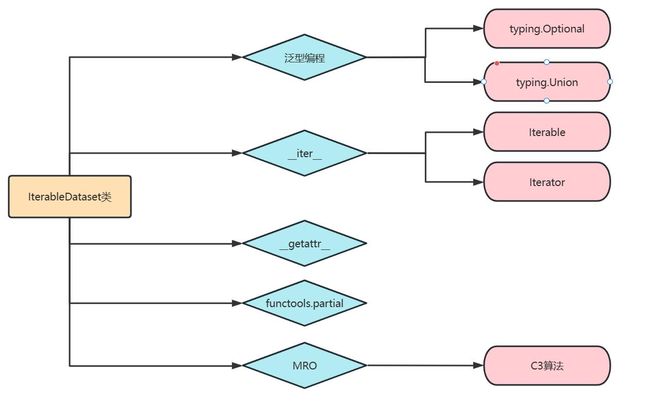
一、IterableDataset
1.0 源代码
class IterableDataset(Dataset[T_co], metaclass=_DataPipeMeta):
functions: Dict[str, Callable] = {}
# Optional也是泛型编程的常用函数,表示
reduce_ex_hook : Optional[Callable] = None
# __iter__方法说明此类是Iterable可迭代对象
# 而__iter__函数返回的是Iterattor迭代器对象
def __iter__(self) -> Iterator[T_co]:
raise NotImplementedError
# __add__函数在Dataset类中同样出现了,用于数据集的拼接
# Dataset中的__add__方法是通过ConcatDataset来实现的
def __add__(self, other: Dataset[T_co]):
# ChainDataset的源码分析见下一篇博文
return ChainDataset([self, other])
# No `def __len__(self)` default? Subclasses raise `TypeError` when needed.
# See NOTE [ Lack of Default `__len__` in Python Abstract Base Classes ]
def __getattr__(self, attribute_name):
# 注意IterableDataset.functions与self.functions是不同的
# 前者是调用类属性,后者是调用对象属性
# 根据前面functions的定义,其为类属性
if attribute_name in IterableDataset.functions:
function = functools.partial(IterableDataset.functions[attribute_name], self)
return function
else:
raise AttributeError
def __reduce_ex__(self, *args, **kwargs):
if IterableDataset.reduce_ex_hook is not None:
try:
return IterableDataset.reduce_ex_hook(self)
except NotImplementedError:
pass
return super().__reduce_ex__(*args, **kwargs)
@classmethod
def set_reduce_ex_hook(cls, hook_fn):
if IterableDataset.reduce_ex_hook is not None and hook_fn is not None:
raise Exception("Attempt to override existing reduce_ex_hook")
IterableDataset.reduce_ex_hook = hook_fn1.1 reduce_ex_hook : Optional[Callable] = None
Optional[Callable]:Optional也是泛型编程的重要函数,与Union,Generic等类常出现在程序中
Union[int,str]表示可能的类型范围是int以及str,因而Union类表示类比的或操作
Optional[Callable]相当于输入类Callable与None类的结合,即Union[Callable,None]
4.泛型编程概念见博文**[【手撕Pytorch源码#1.Dataset类 part1】]((12条消息) 手撕Pytorch源码#1.Dataset类 part1_望 尘�的博客-CSDN博客)**
1.2 def __iter__(self) -> Iterator[T_co]
__iter__函数标志该类是可迭代对象Iterable,关于可迭代对象Iterable和迭代器Iterator以及最常用的for循环的原理见【2.1节 Iterable与Iterator和for loop】
此处的__iter__和Dataset类的__iter__方法一样都需要自己实现,否则就会报错NotImplementedError
1.3 def __getattr__(self, attribute_name)
__getattr__方法用于当对象效用的属性或方法无法找到时,解释器便会调用__getattr__函数
1.4 function = functools.partial(IterableDataset.functions[attribute_name], self)
functions.partial可以给固定函数传入相应的值,精讲见【2.2节 functools.partial】
1.5 __reduce_ex__(self, *args, **kwargs)与@classmethod
由于本期内容较为硬核,因而关于__reduce__,__reduce_ex__,*args,**kwargs和@classmethod放到下一期进行精讲
二、相应的Python语法补充
2.1 Iterable与Iterator和for loop
前文源代码中出现了__iter__方法,声明该类是Iterable可迭代对象,而__iter__方法返回的则是一个Iterator迭代器对象,因而趁此机会研究一下Iterable和Iterator的区别
为了比较两者的区别,我用python实现了链表的数据结构,代码如下:
# 用python实现链表的数据结构
class NodeIterator():
def __init__(self,node:'Node') -> None:
# Iterator必须要储存当下的状态,也就是现在调用到哪一位
# 有点像C语言的指针
# 下面的self.current_node就是储存当前状态的
self.current_node = node
def __next__(self):
if self.current_node is None:
raise StopIteration
node,self.current_node = self.current_node,self.current_node.next
return node
# python官方要求Iterator对象也必须定义__iter__方法,原因见下①
def __iter__(self):
return self
class Node():
def __init__(self,data) -> None:
# self.data是链表结点存的数据
# 可迭代对象Iterable更像是一个数据的容器,而不太在乎当前数据迭代的对象
# 下面self.data其实就是承装了数据,起到container的作用
self.data = data
# self.next是链表结点的next指针
self.next = None
# 我要让链表是一个可迭代对象,必然需要__iter__
def __iter__(self):
return NodeIterator(self)
node1 = Node("Node1")
node2 = Node("Node2")
node3 = Node("Node3")
node1.next = node2
node2.next = node3
# 如果有人希望直接从node1链表中的第二个元素开始遍历,会写出以下代码
it = iter(node1)
first = next(it)
print(first.data)
# 如果这里不在Iterator中定义__iter__函数,那么下面的代码就会报错
for node in it:
print(node.data)在上述代码中Node是可迭代对象Iterable,NodeIterator是迭代器对象Iterator
对比两个类,迭代器对象于可迭代对象的最大区别为:
Iterable对象更像是一个数据容器container,能够承装数据,如常见的数据结构list,tuple,dict都是可迭代对象
而Iterator则不需要保存数据,而需要保存状态,即当前迭代到哪一个数据为,上述代码中,class NodeIterator里的self.current_node就是用于保存当前迭代到的结点
同时,从类程序上看,定义了__iter__方法就可以成为Iterable对象,定义了__next__方法就可以成为Iterator对象
Iterable类与Iterator类定义的其他注意事项
Iterable类中__iter__返回的是一个迭代器Iterator对象
Iterator中也必须定义__iter__函数,保证其也是一个Iterable对象,而其__iter__函数一般直接return self即可,如果在Iterator中不定义__iter__函数,则有可能出现错误(见上述代码的注释)
Iterator类的__next__函数,需要判断迭代是否结束,如果结束,需要raise StopIteration以标志迭代结束
for loop的运作过程
首先程序会判断for .. in x中的x是否为可迭代对象,如果不是,直接报错
在运行for循环之前,程序会首先将可迭代对象Iterable通过iter(Iterable)调用其__iter__方法生成迭代器Iterator,在通过迭代器逐步取值
可以查看以下for循环的字节码,便可以直观了解上述过程
# 查看以下for循环的字节码Bytecode
import typing
import dis
def for_func(lst:typing.List[int])->None:
for num in lst:
print(num)
dis.dis(for_func)
# 上述代码的字节码如下:
# 49 0 LOAD_FAST 0 (lst)
# 2 GET_ITER
# >> 4 FOR_ITER 12 (to 18)
# 6 STORE_FAST 1 (num)
# 50 8 LOAD_GLOBAL 0 (print)
# 10 LOAD_FAST 1 (num)
# 12 CALL_FUNCTION 1
# 14 POP_TOP
# 16 JUMP_ABSOLUTE 4
# >> 18 LOAD_CONST 0 (None)
# 20 RETURN_VALUE上述字节码中49-2 GET_ITER就是从Iterable中取出对应的Iterator
关于字节码ByteCode的相关理论,等有空再开一期专门研究Cpython源码
2.2 functools.partial
functools.partial()用于给函数传递参数,并且返回传参后的函数:该函数第一个参数为函数名,后面的参数为需要对函数传入的参数值
下面是functools.partial的实用场景,直接上代码
import functools
import typing
def display_age(age:int)->None:
print("your age:{}".format(age))
def display_height(height:float)->None:
print("your height:{} cm".format(height))
def callback_fn(callback:typing.Callable)->None:
print("That's where functools.partial works!")
callback()
# 由于callback_fn的输入是一个函数,且该函数没有参数列表
# 因此需要提前对其进行传参
d_age = functools.partial(display_age,30)
d_height = functools.partial(display_height,235.62)
callback_fn(d_age)
callback_fn(d_height)
# 输出结果为:
# That's where functools.partial works!
# your age:30
# That's where functools.partial works!
# your height:235.62 cm在上述代码中,由于callback_fn的输入参数为一个函数,且其没有默认参数,因而需要提前对该函数进行传参。可能你有这样的问题:那么下面这种写法不久好了?
def callback_fn(callback:typing.Callable,age:int)->None:
print("That's where functools.partial works!")
callback(int)的确,如果仅对于display_age函数,这样写确实可以,但如果callback_fn的参数为多个不同输入值的函数,那么这种写法就必然会造成极大的麻烦,functools.partial就有比较大的优越性
2.3 MRO
mro:Method Resolution Order(方法解析顺序),即一个子类,其父类函数的优先级顺序链
2.4 C3算法
本博文最硬核的部分来了,先亮出1996年原论文,干王可以手撕原论文[A monotonic Superclass Linearization for Dylan](A monotonic superclass linearization for Dylan (acm.org))
本博文仅就C3算法的三个假设以及计算方法进行阐述,由于概念较为抽象,因而尽量采用图与代码对应的形式进行呈现
2.4.1 C3算法的三个假设
preservation of local precedence order局部优先顺序
先上代码:
class A:
def display(self):
print("A")
class B(A):
def display(self):
print("B")
class C(A):
pass
class D(C,B):
pass
d = D()
d.display()
# 输出结果为:
# B再看继承结构图和MRO链
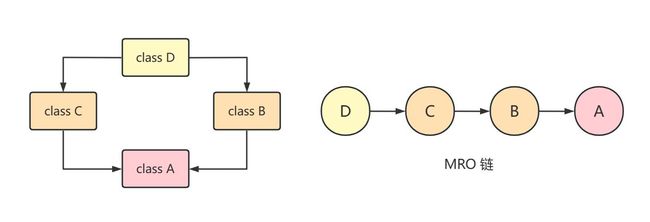
局部优先顺序指的是D类同时继承C类和B类,程序代码为class D(C,B),因此,依照此顺序,在D以及其所有子类的MRO链中,C类一定排在B类的前面
fitting a monotonically criterion单调性准则
单调性准则的描述:子类的MRO链选择必须来自其直接父类,而不能是其他的选择
单调性准则引用原论文中的例子
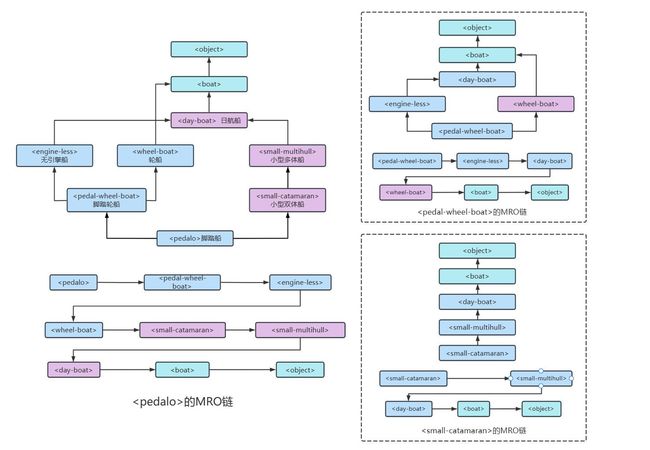
首先对
类进行分析,可以看见, 类是 和 的直接子类,因此 类的MRO直接选择必须来自 和 两类之一
而观察
类和 类的MRO链可以发现: 类中 类排序高于 类,且 类中MRO链没有 类
但是观察
类的MRO链可以发现: 类排序高于 类。因此,如果一个类函数仅存在于 类和 类中,那么 类和 类将会执行 类的函数,而 类将会执行 类的函数,与单调性原则不符
a consistent extended precedence graph拓展优先图
用于解决一个类的子类和其父类的优先级顺序
抽象的表达:取决于两个的最小公共子类上,两类或其子类的优先级顺序
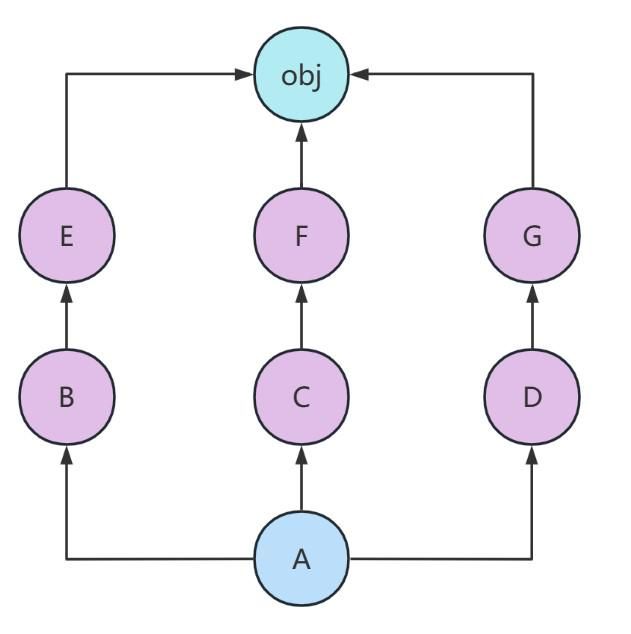
同样用论文中的例子进行演示
根据local precedence原则,对于
类而言, 类排在 类之前。对于 类而言, 类排在 类之前。对于 类而言, 类排在 类之前。
但是我们希望能够对
类和 类进行排序
首先我们找到
类和 类的最小公共子类 类
在从
类开始依次比较 类和 类以及其子类的优先顺序
在上图中,我们比较
类的子类 类以及 类的子类 类的优先级顺序。
明显,由local precedence原则,
类排在 类之前,因此 类排在 类之前
因此,上述继承图的MRO链如下:
2.4.2 C3算法计算方法
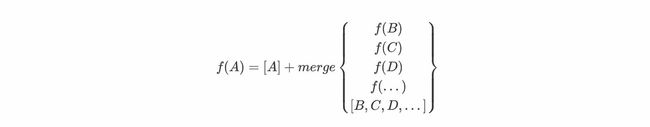
看一个例子:

最后计算f(A)
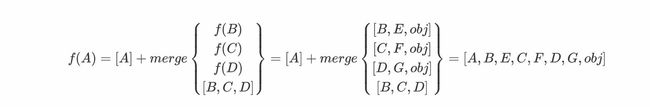
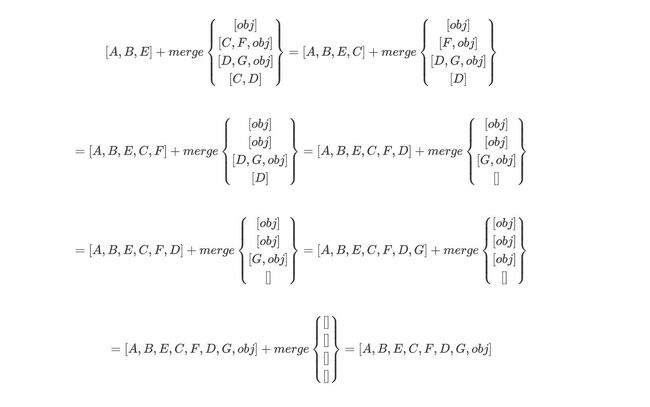
2.4.3 merge函数计算方法
以上例中最后一步的merge函数计算为例
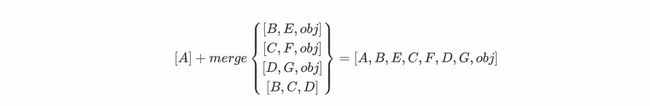
首先观察merge函数中的参数,从第一个参数的一个元素B开始取,观察所有参数的后几位(第二位及以后)是否有B元素出现,若有,则不能加入结果列表中,否则就可以加入结果列表中,运算如下:
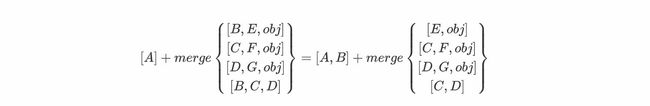
接着对第一个参数的第二个元素重复上述操作,运算如下:
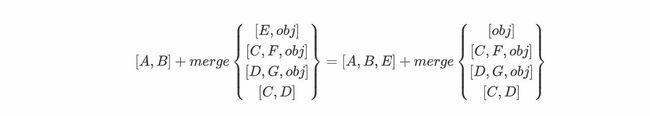
接着对第一个参数第三个元素obj进行分析,发现其余参数的第二位及以后的元素中仍有obj元素出现,因而obj不可以加入结果列表中
后面的步骤依次运算如下: