Python中生僻的用法——对我而言
super 函数
class CrowdCounter(nn.Module):
def __init__(self,gpus,model_name):
super(CrowdCounter, self).__init__() (用处):具有单继承的类层级结构中,super 可用来引用父类而不必显式地指定它们的名称,从而令代码更易维护。
比如上面这个地方:CrowdCounter这个类继承了 nn.Module这个类。通过super(CrowdCounter)可以间接调用到CrowdCounter这个类的父类,而不需要明确的写出 CrowdCounter这个类的父类的名字nn.Module。因为在代码开发的过程,有可能这个类的父类是会变的。如果你修改了CrowdCounter的父类,改成别的东西。那你调用的父类的这个代码不用改写。如果你不用super的话,你修改了父类,这里还要把改后的父类的名字在这里多改一次。
super的使用有两种形式
# 形式1
super(CrowdCounter, self).__init__()
# super(子类的名字,self).method_name(arguments)
# 形式2
super().__init__()
# super(省去子类的名字默认将当前类的名字填入,
# self也省去 默认填入).method_name(arguments)给个例子
# 定义父类
class initial(object):
def __init__(self):
print ('This print is from initial object')
# 定义父类参数
self.param = 3
# 定义父类函数
def func(self):
return 1
# 定义子类
class new(initial):
def __init__(self): # 构造函数,只要声明类的对象,比如new(),就会调用这个构造函数
print ('This print is from new object') # “This print is from new object”
# 打印子类函数值
print (self.func()) # “2”,父类和子类中都有 名字完全相同的一个 方法 ,在子类中调用这个方法,有限调用子类自己的method
# 执行父类初始化函数
super(new, self).__init__() # “This print is from initial object”,
# 调用new这个子类 的父类 的self的 __init__这个构造函数
# 这个构造函数 做两件事,第一件事 打印这句话“This print is from initial object”;
# 第二件事,给self的这个变量赋值self.param = 3
# 打印父类参数值
print(self.param) # 这里是3,上一句调用构造函数,声明并赋值了这个变量self.param
self.param = 4
# 定义子类函数
def func(self):
return 2
if __name__ == '__main__':
new()输出是
This print is from new object
2
This print is from initial object
3什么是魔法方法?
(1)python中的魔法方法是指方法名以两个下划线开头并以两个下划线结尾的方法,
(2)魔法方法会在对类的某个操作时自动调用,而不需要自己直接调用。
python魔法方法之__call__
如果你在定义类的时候没有写这个函数,__call__,那么类的实例(1)不可调用的 not callable(2)这个实例不可以拿来当函数用。比如下面这样
class student:
def __init__(self,height,weight):
self.height=height
self.weight=weight
a=student(172,60)
print(callable(a)) # 输出是“False”,意思是不可调用
# 自然你也不可以用a(12,70)这样 向里面传参,
# 也不会输出值,月就是说,不能当做函数来用定义类的时候如果你定义了__call__函数,那么(1)类的实例是可调用的 callable(2)这个实例可以当做函数来用,可以向里面传进去参数,可以拿到输出值
class student:
def __init__(self,height,weight):
self.height=height
self.weight=weight
def __call__(self,words:str):
print(words) # I'm a fool!
print("*"*10) # **********
return("print:————"+words) # "print:————I'm a fool!"
a=student(172,60)
print(callable(a)) # 输出# True;
# 说明加了__call__函数以后是可调用的了
# 实例函数化
# 类的实例本身可以当做一个函数,
# (1)这个函数里面还可以传参。
# (2)使用“实例名()”这句命令就会执行__call__()函数里面写的命令
# (3)这个函数如果return东西可以返回出来这个东西
a("I'm a fool!")
# True
# I'm a fool!
# **********
# "print:————I'm a fool!"python魔法方法之__len__()
你调用 len(实例) 的时候会执行的东西,就是__len__()函数中定义的东西。
像下面,len(sample)就会执行def __len__(self)函数里面写的代码,将里面return的东西返回出来
class MyTest(object):
def __init__(self):
self.name = 'ab'
self.age = 22
self.weight = 90.5
def __len__(self):
# len() 函数一般返回对象(序列)的长度或元素个数
return len(self.__dict__)
sample = MyTest()
len(sample) # 3python魔法方法之__dict__()
每次给类的属性赋值的时候,都会执行这句话,向self.__dict__这个字典里面新增key,赋值
def __setattr__(self, key, value):
self.__dict__[key] = valueself.__dict__输出的是这个实例的 所有的属性名和属性值,格式是{属性1名:属性1值,属性2名:属性2值,...}
class AnotherFun:
def __init__(self):
self.name = "Liu"
print(self.__dict__)
self.age = 12
print(self.__dict__)
self.male = True
print(self.__dict__)
another_fun = AnotherFun()
# {'name': 'Liu'}
# {'name': 'Liu', 'age': 12}
# {'name': 'Liu', 'age': 12, 'male': True}python魔法方法之__setattr__()
__setattr__()负责对属性进行注册
__setattr__()函数和__init__()函数一样都是定义在类下面的。
每一次,当你给一个类的属性赋值的时候,都会自动调用__setattr__()这个函数,将属性名赋值给key,将属性值赋值给value。然后__setattr__的里面肯定有一行,把属性名和属性值以key和value的字典的格式存进self.__dict__
class Fun:
def __init__(self):
self.name = "Liu"
self.age = 12
self.male = True
# 每一次,当你给一个类的属性赋值的时候,都会自动调用__setattr__()这个函数,
# 将属性名赋值给key,将属性值赋值给value
def __setattr__(self, key, value):
print("*"*50)
print("setting:{}, with:{}".format(key, value))
print("current __dict__ : {}".format(self.__dict__))
print("\n")
# 然后__setattr__的里面肯定有一行,把属性名和属性值以key和value的字典的格式存进self.__dict__
self.__dict__[key] = value
fun = Fun()
# **************************************************
# setting:name, with:Liu
# current __dict__ : {}
# **************************************************
# setting:age, with:12
# current __dict__ : {'name': 'Liu'}
# **************************************************
# setting:male, with:True
# current __dict__ : {'name': 'Liu', 'age': 12}numpy的广播机制是什么?
两个数组,有一个维度相同,另一个维度不同,一个是1,一个是N。这个时候会把这个为1的维度扩展到N,使得两个数组的size完全相同,然后完成加减乘除。
一维情况下的广播机制
a的维度是 1行3列,b的维度是1行1列,所以将b横向复制两次,扩展为1行3列。然后两个1行三列的数组对应元素相加
import numpy as np
a = np.array([1, 2, 3])
b = np.array([2])
print(a*b) # [2 4 6]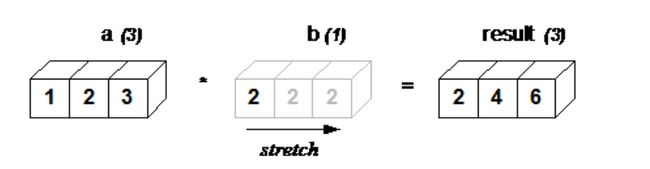
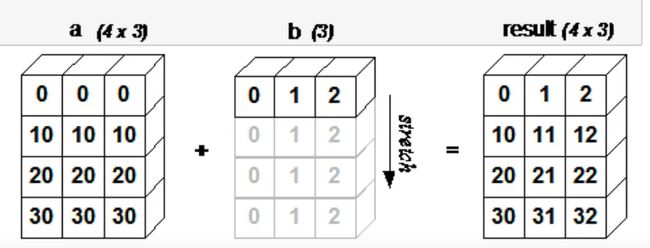
二维情况下的广播机制
a的维度是4行3列,b的维度是1行3列。a和b的列数相同,都是3。但是行数一个是4,一个是1,因此满足广播机制的条件。
现在将b的1行3列复制两份,拼起来,形成3行3列,然后与a相加
import numpy as np
a = np.array([[0, 0, 0],
[10, 10, 10],
[20, 20, 20],
[30, 30, 30]])
b = np.array([1, 2, 3])
print(a+b)
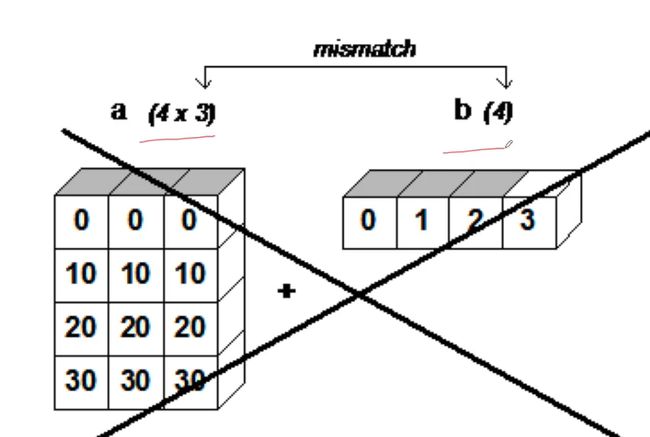
下面演示一个没有维度相同的行或者没有维度相同的列,引发的广播机制无法运行的例子
a是一个4行3列的数组,b是一个1行4列的数组,因为a和b的行数不相同(一个4,一个1)且a和b的列数也不相同(一个3,一个4)。因此无法使用广播机制。所以报错。
此处有同学说,我可不可以把b转置一下,变成4行1列的数组,然后让他们再相加,然后就可以用广播机制了。这样确实就可以相加,可以用广播机制了,但是如果你不写命令要转置,是不会自动转的,还是会报错
import numpy as np
a = np.array([[0, 0, 0],
[10, 10, 10],
[20, 20, 20],
[30, 30, 30]])
b = np.array([0, 1, 2, 3])
a+b
转置一下,二者行数都是4,列数一个3、一个1,就会调动广播机制,从一列填充到3列
import numpy as np
a = np.array([[0, 0, 0],
[10, 10, 10],
[20, 20, 20],
[30, 30, 30]])
b = np.array([0, 1, 2, 3])
a.T+b

三维情况下的广播机制
import numpy as np
a = np.arange(6).reshape((2, 3, 1))
b = np.arange(6).reshape((1, 3, 2))a和b是什么?
a是:
array([[[0],
[1],
[2]],
[[3],
[4],
[5]]])
b是:
array([[[0, 1],
[2, 3],
[4, 5]]])
a和b的维度分别为2页3行1列和1页3行2列。两个矩阵有共同的维度,行数,为3。目前将维度数为1的那个维度扩展为非1的那个维度。
这里将a的列数从1扩展为b的列数2,也就是将一列复制一份,变成两列,a就变成
a在广播机制以后变成
array([[[0,1],
[1,1],
[2,2]],
[[3,3],
[4,4],
[5,5]]])将b的页数从1变为,a的页数2
b在广播机制后变成
array([[[0, 1],
[2, 3],
[4, 5]],
[[0, 1],
[2, 3],
[4, 5]]
])此时a和b的维度一样了都是(2,3,2),a+b就是逐个元素相加,得到的结果如下
a+b是:
array([[[ 0, 1],
[ 3, 4],
[ 6, 7]],
[[ 3, 4],
[ 6, 7],
[ 9, 10]]])共同维度为1,扩展为1这个维度的广播机制
其他
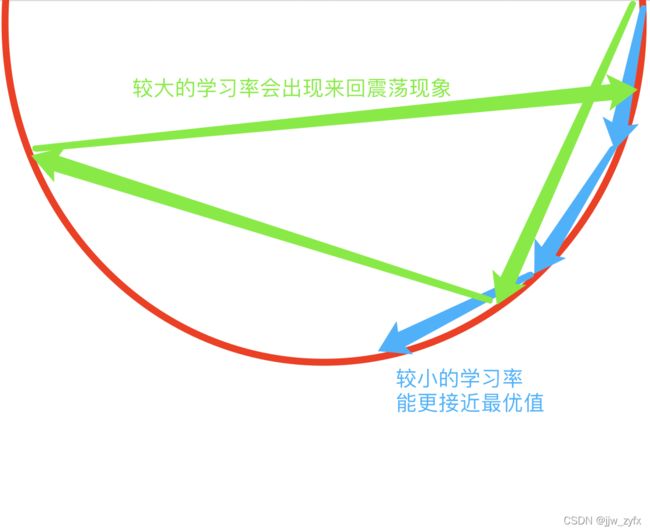
学习率过大,引发的来回震荡,无法到达最低点
![]()