卷积神经网络的形象理解
一、CNN的局部感受野、共享权重和池化
学了很久的卷积神经网络,看了关于它的tutorial,也看没有明白它(convnet 中的卷积层)到底要做什么?说它再做特征提取,怎么看不出来提取的是什么特征?卷积输入尺寸和输出尺寸是如何匹配的?所谓共享权重体现在哪里?怎么突然就扁平化处理了?我们到底要怎样彻底理清楚,搞明白,还会运用它?
网络类别
接下来,我形象比喻(自认为很形象)的方式解释今天的主人公,卷积层和卷积神经网络。
首先,以图–看人为引。
我们看到一个人,假设分三层得出结论。
输入:看见一个人
第一层:得到‘外形’ ‘肤色’ ‘脸’三类大体特征
第二层:对第一层的输出,作为这一层的输入。分别就粗特征,分解得到更细致或者更具体的特征:高度 宽度 重量 颜色 亮度 色泽 眼睛 五官 形状
第三层:扁平化,将这些特征聚集
输出:美人
当然,人的思维远远比这个复杂多变,但这样分解是不是能抽象一下。完成认知过程。

这个抽象认知过程的重点和难点是大脑给我们提供了很多滤波核函数,让我们轻松get到目标的特征。你每辨别出一个特征,可以看作是基于大脑核的条件下完成的。

我们怎么一下子就辨别出来了呢?那是因为这些核的参数已经训练好啦!从小到大,你从各个方面学到的,都是再更新对应的核的过程。怎么有时候看着是美人,有时候又觉得不够美了呢?—这其中诱因太不稳定,那么就在每个识别层上加一个’有色眼镜‘,带个偏置。
所以同样有大脑这个结构的婴儿们,为甚么辨别不出这个‘美人’,我们轻易就认出来了,因为他们的众核(很多、各种核的值权重)还在训练更新当中,也有很多核的值还是零,所以不指望立即就有这个认知。
接下来,我要说的是,卷积神经网络,它就像这样悄悄咪咪的也把抽象认知过程模拟了一遍。
下图来自:http://c.biancheng.net/view/1928.html
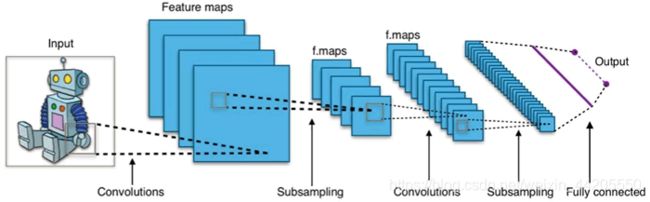
开始:网络的输入是个图–机器人
第一层:得到了四个特征,假设也是粗特征“外形 肤色 脸 天线”,那么此处,必有四个核对应,才识别得出这四个特征。—卷积
第二层:向下采样,就是把粗特征变简单一点。每四个值选一个最大值当代表就行了–命名:最大值池化
第三层:就得到的四个特征进行精细辨别,得到12个习特征,“高度 宽度 重量……”等12个特征(以图例,代表性的形象解释)。同样,这里识别出12个精细特征也需要12个核与之对应。—卷积注意,这里与上上面的抽象有些出入,12个核是针对所有输入都有溜,不是每三个溜一个。
第四层:乡下采样,同理。
第五层:扁平化,把这些特征组合起来
最后:得出–#@#¥##
???为什么,它没有得出“美机器人的结论”
那是因为,它的这些核还没有值,没训练,就核婴儿一样。所以它也需要训练啊。
参数理解
接下来,我们举例介绍要训练的核的表示形式:以tensorflow定义卷积网络为例。
在机器人图说明中,只有两层涉及核。
’ # 第一个卷积层
conv1 = conv2d(x,weights[‘wc1’], biases[‘bc1’])
# 第二个卷积层
conv2 = conv2d(pool1,weights[‘wc2’], biases[‘bc2’])
‘
这里的weights[‘wc1’]里面装的第一层的四个核的参数,weights[‘wc2’]里装的第二个卷积的12个核的参数。biases[‘bc1’]和 biases[‘bc2’]分别是防止脑抽,加的偏置变量。
表示如下:
’
weights = {
# 5x5 conv, 1 input,and 4 outputs
‘wc1’: tf.Variable(tf.random_normal([5,5,1,4])),
‘wc2’: tf.Variable(tf.random_normal([5,5,4,12]))
}
biases = {
‘bc1’: tf.Variable(tf.random_normal([4])),
‘bc2’: tf.Variable(tf.random_normal([12])),
}
‘
这里解释一下,输入输出的尺寸是怎么匹配的。
第一次卷积: ‘wc1’: tf.Variable(tf.random_normal([5,5,1,4])),
以上可以跟着我念:[5,5,1,4]表示,输入一幅图像(或特征),四个5x5的核分别各自浏览一遍输入,得到四副特征输出。
紧接着第二次卷积:‘wc2’: tf.Variable(tf.random_normal([5,5,4,12]))
跟我一起念:[5,5,4,12]表示,输入四幅特征,一共被12个核溜一遍,得到12副特征输出。
至于,直观深度变化:每一个核(filter)的输出被堆叠在一起,形成卷积图像的纵深维度。
假设我们有一个 32323 的输入。我们使用 553,带有 valid padding 的 10 个过滤器。输出的维度将会是 282810。

权重共享
好了,到这里有没有感受到权重共享?
第一此卷积对输入用四个核卷积,得到四个不同程度或方向的特征,但好像还看不出来权值共享没?那请看第二次卷积的4个输入,分别各自被12个核卷积一遍,输出12个不同程度或方向的特征,那么,这4个输入共享了12个卷积核的权重。一个庞大的卷积神经网络的各个卷积层就像传送带上的每一个站点,站点设立了不同个数的核操作,所以,不论是一开始是一个输入,还是一排输入,都经过相同的洗礼,得出计算机明白的特征集合,从而判断是什么。
还不懂?换句人话是:之前你一个人,站在4个花洒下洗澡,输出4个你(每个特征都代表你);然后4个你站在12个花洒下洗澡,输出12个新的你,然后到下一个花洒聚集地。懂否?那么卷积网络的各个卷积层就像一个大的澡堂子,分别有4个花洒一间的,12个花洒一间的,36个花洒一间的,要准备多少间都行。每一间里的人都共享当前房间的花洒。
最后的最后,所有特征都理得差不多得时候,把最后卷积层的大家聚集到一块儿,用全连接层加softmax把它们归为一个结果。
看到这里,不明白的,请看详细。另一位博主的理解。
实践
ok,了解完这些理论,我们接下来实践一番,怎么完成网络架构,怎么利用数据训练,最后又是怎样预测的。
tensorflow中文教材上的例子。以下是我的理解和实践。解释都在代码中。如果你还不清楚一些基础,比如,全连接,神经元,或框架基础,都可以看看教程: http://c.biancheng.net/view/1885.html。推荐看原版或中文教程学习和入门。
关于卷积神经网络识别手写数字mnist数据集数字的实践。
代码和说明:
#!/usr/bin/python
# -*- coding = utf-8 -*-
# author: beauthy
# date: 20200116
# version:1.0.0
'''Convnets 背后有三个关键动机:局部感受野、共享权重和池化。
如果想保留图像中的空间信息,那么用像素矩阵表示每个图像是很方便的。
然后,编码局部结构的简单方法是将相邻输入神经元的子矩阵连接成属于下一层的单隐藏层神经元。
这个单隐藏层神经元代表一个局部感受野。此操作名为“卷积”,此类网络也因此而得名。'''
# from __future__ import division,print_function #意味着在新旧版本的兼容性方面存在差异,处理方法是按照最新的特性来处理。
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
'''共享权重和偏置
假设想要从原始像素表示中获得移除与输入图像中位置信息无关的相同特征的能力。
一个简单的直觉就是对隐藏层中的所有神经元使用相同的权重和偏置。
通过这种方式,每层将从图像中学习到独立于位置信息的潜在特征'''
'''
tf.nn.conv2d() 理解的关键是滤波器不是预先设定好的,而是在训练阶段学习的,以使得恰当的损失函数被最小化。
参数说明如下:
input:张量,必须是 half、float32、float64 三种类型之一。
filter:张量必须具有与输入相同的类型。
strides:整数列表。长度是 4 的一维向量。输入的每一维度的滑动窗口步幅。必须与指定格式维度的顺序相同。
padding:可选字符串为 SAME、VALID。要使用的填充算法的类型。
use_cudnn_on_gpu:一个可选的布尔值,默认为 True。
data_format:可选字符串为 NHWC、NCHW,默认为 NHWC。指定输入和输出数据的数据格式。使用默认格式 NHWC,数据按照以下顺序存储:[batch,in_height,in_width,in_channels]。或者,格式可以是 NCHW,数据存储顺序为:[batch,in_channels,in_height,in_width]。
name:操作的名称(可选)
'''
'''
最大池化层:tf.nn.max_pool()
平均池化:tf.nn.mean_pool()
参数说明如下:
value:形状为 [batch,height,width,channels] 和类型是 tf.float32 的四维张量。
ksize:长度 >=4 的整数列表。输入张量的每个维度的窗口大小。
strides:长度 >=4 的整数列表。输入张量的每个维度的滑动窗口的步幅。
padding:一个字符串,可以是 VALID 或 SAME。
data_format:一个字符串,支持 NHWC 和 NCHW。
name:操作的可选名称。
'''
'''CNN 在时间维度上对音频和文本数据进行一维卷积和池化操作,
沿(高度×宽度)维度对图像进行二维处理,
沿(高度×宽度×时间)维度对视频进行三维处理。'''
'''视觉特征在网络的前面几层很简单,然后随着网络的加深,组合成更加复杂的全局特征'''
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
# 超参数
learning_rate = 0.001
training_iters = 500
batch_size = 128
display_step = 10
# 网络参数
n_input = 784
n_classes = 10
dropout = 0.75
def conv2d(x,W,b,strides=1):
'''输入为 x,权值为 W,偏置为 b,给定步幅的卷积层。
激活函数是 ReLU,padding 设定为 SAME 模式'''
x = tf.nn.conv2d(x,W,
strides=[1,strides,strides,1],
padding='SAME')
x = tf.nn.bias_add(x,b)
return tf.nn.relu(x)
def maxpool2d(x,k=2):
'''输入是 x 的 maxpool 层,卷积核为 ksize
并且 padding 为 SAME'''
return tf.nn.max_pool(x,ksize=[1,k,k,1],
strides=[1,k,k,1],
padding='SAME')
def conv_net(x,weights,biases,dropout):
# reshape the input picture
x = tf.reshape(x,shape=[-1,28,28,1])
# 第一个卷积层
conv1 = conv2d(x,weights['wc1'],biases['bc1'])
# 池化层
pool1 = maxpool2d(conv1,k=2)
# 第二个卷积层
conv2 = conv2d(pool1,weights['wc2'],biases['bc2'])
# maxpooling
pool2 = maxpool2d(conv2,k=2)
# reshape pool2 output to match the input of fully connected layer
fc1 = tf.reshape(pool2,
[-1,weights['wd1'].get_shape().as_list()[0]])
fc1 = tf.add(tf.matmul(fc1,weights['wd1']), biases['bd1'])
fc1 = tf.nn.relu(fc1)
# dropout
fc1 = tf.nn.dropout(fc1,dropout)
# 输出层
out = tf.add(tf.matmul(fc1,weights['out']),biases['out'])
return out
def train_model():
x = tf.placeholder(tf.float32,[None, n_input])
y = tf.placeholder(tf.float32,[None, n_classes])
keep_prob = tf.placeholder(tf.float32)
weights = {
# 5x5 conv, 1 input,and 32 outputs
'wc1': tf.Variable(tf.random_normal([5,5,1,32])),
'wc2': tf.Variable(tf.random_normal([5,5,32,64])),
# 全连接层,7x7x64 inputs,1024 outputs
'wd1': tf.Variable(tf.random_normal([7*7*64,1024])),
'out': tf.Variable(tf.random_normal([1024,n_classes]))
}
biases = {
'bc1': tf.Variable(tf.random_normal([32])),
'bc2': tf.Variable(tf.random_normal([64])),
'bd1': tf.Variable(tf.random_normal([1024])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
# 建立一个给定权重和偏置的 convnet卷积神经网络。
# 定义基于 cross_entropy_with_logits 的损失函数,
# 并使用 Adam 优化器进行损失最小化。
pred = conv_net(x,weights,biases,keep_prob)
cost = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits=pred,labels=y)
)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
correct_prediction = tf.equal(
tf.argmax(pred,1),
tf.argmax(y,1)
)
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
init = tf.global_variables_initializer()
train_loss = []
train_acc = []
test_acc = []
with tf.Session() as sess:
sess.run(init)
step = 1
while step <= training_iters:
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(optimizer,feed_dict = {x:batch_xs,y:batch_ys,keep_prob:dropout})
if step%display_step == 0:
loss_train, acc_train = sess.run([cost,accuracy],
feed_dict={
x: batch_xs,
y: batch_ys,
keep_prob: 1.
})
print("Iter"+str(step)+",Minibatch Loss="+
"{:.2f}".format(loss_train)+
"Training Accuracy =" +
"{:.2f}".format(acc_train))
acc_test = sess.run(accuracy,
feed_dict={
x:mnist.test.images,
y:mnist.test.labels,
keep_prob:1.
})
print("Testing Accuracy:"+
"{:.2f}".format(acc_train))
train_loss.append(loss_train)
train_acc.append(acc_train)
test_acc.append(acc_test)
step += 1
return train_loss,train_acc,test_acc # 返回训练的受损变化 准确率 和测试准确率 的变化
def display_result(train_loss,train_acc,test_acc):
'''画训练损失曲线和测试精确度变化曲线'''
eval_indices = range(0,training_iters,display_step)
# plot loss overtime
plt.plot(eval_indices, train_loss,'k-')
plt.title('Softmax Loss Per Iteration')
plt.xlabel('Iteration')
plt.ylabel('Softmax Loss')
plt.show()
# plot train and test accuracy
plt.plot(eval_indices,train_acc,'k-',label='Train set Accuracy')
plt.plot(eval_indices,test_acc,'r--',label='Test set Accuracy')
plt.title('Train and Test Accuracy')
plt.xlabel('Generation')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
# 数据集的情况
def train_size(num):
print('Total Training Images in Datasets = '+
str(mnist.train.images.shape))
print('Total Training Images in Datasets = '+
str(mnist.test.images.shape))
print('------------------------------------------------')
X_train = mnist.train.images[:num,:]
y_train = mnist.train.labels[:num,:]
X_test = mnist.test.images[:int(num/10),:]
y_test = mnist.test.labels[:int(num/10),:]
print('X_train Examples Loaded = '+
str(X_train.shape))
print('y_train Examples Loaded = '+
str(y_train.shape))
print('X_test Examples Loaded = '+
str(X_test.shape))
print('y_test Examples Loaded = '+
str(y_test.shape))
return X_train, y_train, X_test, y_test
def display_digit(x,y,num):
print(y[num])
label = y[num].argmax(axis=0)#对列取最大值,并返回最大值的位置下标
image = x[num].reshape([28,28])
plt.title('Example:%d Label:%d'%(num,label))
plt.imshow(image,cmap=plt.get_cmap('gray_r'))
plt.show()
def display_mul_flat(x,y,start,stop):
images = x[start].reshape([1,784])
for i in range(start+1,stop):
# 拼接 axis=0,默认按列拼接
images = np.concatenate((images,
x[i].reshape([1,784])))
plt.imshow(images,cmap=plt.get_cmap('gray_r'))
plt.show()
if __name__ == "__main__":
# X_train, y_train, X_test, y_test = train_size(20000)
# display_digit(X_train,y_train,9)
# display_mul_flat(X_train,y_train,1,100)
train_loss, train_acc, test_acc = train_model()
display_result(train_loss,train_acc,test_acc)
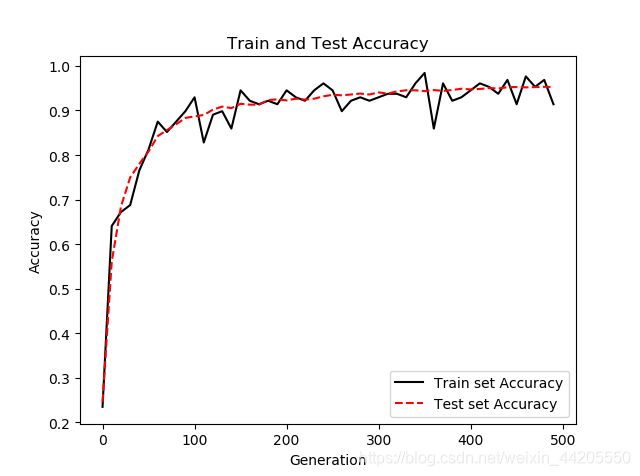
训练情况:

最后,分享经验教训,也是在帮助别人更新大脑核链接权重的过程,加强自己网络稳定性和可靠性的过程,另如果有误,请不吝赐教,我也好修正大脑权重。感谢友情分享,共同进步,互勉!