【论文向】Knowledge-Based Systems Multi-interest Semantic Changes Over Time in Short-Text Microblogs
【论文向】LNCS2020-多主题的时序短文本挖掘
Knowledge-Based Systems Multi-interest Semantic Changes Over Time in Short-Text Microblogs
目录
- 【论文向】LNCS2020-多主题的时序短文本挖掘
- Humble opinion
- Abstract
- Highlights
- Introduction
- Related Works
- Their Approach
- Experimentation
- Results
- Discussion and Application Areas
- Conclusion
注:论文阅读笔记仅帮助大家快读了解、知晓论文的创新点、重点等,如需详细掌握请点击上方标题自行阅读,在此是存在一定博主和读者偏见的,有任何问题欢迎留言指正或讨论。
(中英文版,推荐大家直接看英文截图,截图是笔者自己细读论文后做的ppt进行一一总结截图的
Humble opinion
愚见总结:
优点:鄙人少见的将时间加入到文本挖掘的论文,所用技术包含用FastText、Word2vec和 Glove 做词向量和主题向量(可以理解为句向量),LDA抽无监督主题。优点总结就是在用户兴趣topic中考虑时间因素。
缺点:不值得细读,套话太多,核心算法如下图

最主要的部分就是第“4”行(行首标号4)的公式,

σ: M维的词向量
α k t α_k^{t} αkt:在t时间点上第k个主题topic的主题向量
θ x k \theta_{xk} θxk:由LDA得到在每一条tweet 推文或文章x下主题k的概率
σ和 α k t α_k^{t} αkt做inner product点积得到一个主题下面的词向量
Abstract


个人用户及其友谊网络的利益需要在很大程度上消耗短文本微博中的内容。 即使随着时间的流逝,即使对于单个用户,语义优势也会随着时间而改变。 实质上,几个月后,用户在此类平台上感兴趣的当前主题和相关主题可能并不代表同一用户的兴趣。 为了确定在任何给定时间最有代表性的用户的兴趣,我们将每个主题词建模为单词嵌入和不同时间段的指定主题的基于时间的嵌入表示之间的内积。 为了验证模型,在语义上权衡了随时间的变化,以便从随时间变化的数据集中提取用户的利益。
计算了整个数据集的兴趣权重,并在五个子主题中进行了为期两年半的验证。 可以确定测试集和验证集之间关系的线性,尤其是在新兴主题中更是如此。 在测试期间的兴趣变化验证中,Pearson相关系数高达0.871。
Highlights

•一个新的用户代表分析框架,其中仅将基于时间的传播内容视为建模框架中的输入。
•时间序列文档中的用户兴趣被建模为单词嵌入的分类分布以及单词分配主题的基于时间的表示形式。
•向量表示法用于通过提取突出随时间变化的兴趣动态的集体时间语义模式,在每个时间戳上对主题兴趣进行建模。
•在五年内对Twitter用户及其传播的内容进行了测试和验证。
•为短消息第三方第三方内容提供商和平台提供集体知识。 随着时间的流逝,这是语义上的兴趣变化和整个用户概况,以便将来进行预测以服务于某些用户/用户组。
Introduction

在Twitter上,用户能够以“转发”,“评论”和/或“喜欢”原始推文的形式重新共享散布的推文。 通常,高音扬声器根据当时的主要兴趣在平台上消费内容。 例如,在政治运动时期,许多与人口相关的高音喇叭可能会表达出对政治内容的兴趣。 这种用户传播模式和代表利益的建模和提取是一项艰巨的任务,特别是对于旧系统而言。 这归因于两个因素:
(i)数据波动性影响其传播吞吐量(吞吐量)
(ii)感兴趣的主题的基于时间的变化(时间)

他们提出了一个能够识别短文本微博用户的语义用户兴趣的框架。 由于每个文档的字符数限制(280个字符),这在短文本微博中具有挑战性。 预处理推文中的每个标记都被矢量化,并建模为词汇和特定时期内主题嵌入之间的内积。 捕获每个时期的兴趣主题,整体语义表示是整个数据集收集时期的用户兴趣权重。

在开发此类框架时,目的是解决以下研究问题:
•是否可以在基于时间序列的流简短文本中提取用户代表兴趣进行概要分析?
•短文本中提取的模式是否足以为广义的短文本内容传播者提供与时间相关的用户/内容建议/预测?

在算法上,将期望最大化(EM)和高斯混合模型(GMM)应用于矢量表示以提取软聚类。
此外,假设每个用户聚合向量表示形式到聚类的语义距离为主题聚类中的兴趣级别。
从算法上讲1.术语和主题嵌入的融合作为时变分布模型不同于相关工作。2.在识别不断发展的用户兴趣时,在简短和不断发展的文本中提取对时间敏感的主题兴趣,以突出其动态性以更好地进行用户分析。 这与关键字,概念和混合配置文件方法不同。
Related Works


用户资料表示:基于关键字,基于概念或基于多面/混合的
基于关键字的配置文件:关键字或关键字组用于表示用户兴趣。 (TF-IDF)
基于概念的概要文件:使用知识库(Wikipedia)中的概念是因为它们提供了背景知识,可以更好地提取概念
混合配置文件:在建模过程中对目标用户感兴趣的几个方面的融合会产生一个混合配置文件。(node2vec)在伪造信息源的性能分析中考虑了用户特征和社交图
Their Approach
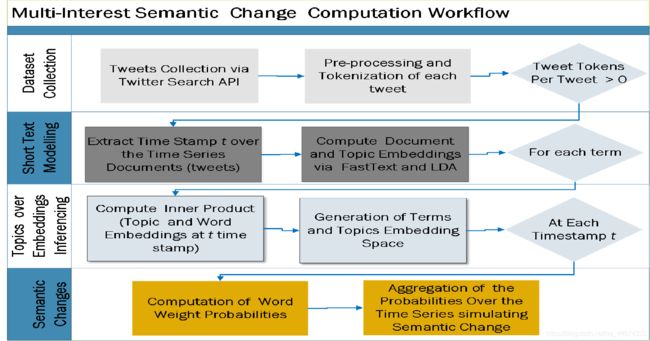

所提出的框架包括与主题兴趣的产生,词嵌入和时变分布模型有关的几个过程。
主题兴趣分布在单词表示中作为模型中的时间变化主题。时间变化是用户定义的,因为数据集是时间序列文档。 LDA用于在每个时间戳生成主题信息。

-
数据集:Twitter的搜索API
-
短文本建模:
时间戳信息是从标记化推文中提取的。
FastText,Word2Vec和Glove进行矢量化和标记化。
为了进行比较,使用了LDA和Twitter-LDA。 -
词嵌入推理主题:
对于每个术语,主题代表词在词嵌入上的分布模型。 输出是在每个时期获取主题的主题和单词嵌入的乘积。 -
多兴趣语义更改:在每个时间戳记中,都会计算单词权重概率。 通过在指定时间段内对主题中的兴趣关键字进行加权来捕获兴趣变化。


Experimentation

通用的推文集:推文是通过Twitter的searchAPI收集的。 从肯尼亚收集了地理定位但通用的推文集,理想情况下,这提供了可通过控制集验证的数据集。 语言独立性:大约90%的推文都以英语传播。 其余部分在斯瓦希里语中,并且是两者的混合。理想情况下,建模过程(尤其是嵌入过程)是与语言无关的。 时间差异:提取的tweet跨度为期五年,分为几个季度,即从2015年第一季度(Q1)到2020年第二季度(Q2)。 包含每个推文的时间戳变化t x。
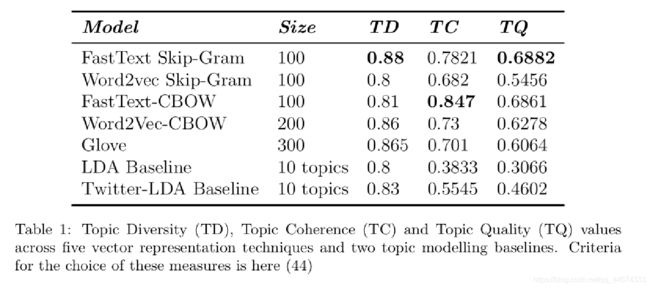
Results

Discussion and Application Areas

讨论:
他们的工作目标是识别短文本中不断发展的主题兴趣,并最终建立具有代表性的用户个人资料。
应用领域:
- 在短文本平台上向用户传播时变内容。(推荐)
- 对内容用户类型/性质的预测势必会消耗
- 内容参与模式
- 第三方内容发布者确定最相关的用户来提供内容。 这也与冷启动场景有关。
Conclusion

本文提供了一个以时间为因素的增强建模框架。
该框架是在设计短文本第三方推荐系统时取得的进步,其利息收益和收益都有波动。 在这项工作中,可以通过跟踪随时间变化的传播模式来推断感兴趣主题的兴趣变化。
将来,可能会倾向于使用更大的语言表示模型(例如BERT)来增强短文本中的兴趣提取过程。