ACL2022 | 引入对比学习给生成的过程中加入负样本的模式使得模型能够有效地学习不同层级上的知识...
每天给你送来NLP技术干货!
作者:支付宝搜索团队
来自蚂蚁集团、北大等机构的研究者提出了一种多粒度对比生成方法,设计了层次化对比结构。
文本生成任务通常采用 teacher forcing 的方式进行训练,这种训练方式使得模型在训练过程中只能见到正样本。然而生成目标与输入之间通常会存在某些约束,这些约束通常由句子中的关键元素体现,例如在 query 改写任务中,“麦当劳点餐” 不能改成 “肯德基点餐”,这里面起到约束作用的关键元素是品牌关键词。通过引入对比学习给生成的过程中加入负样本的模式使得模型能够有效地学习到这些约束。
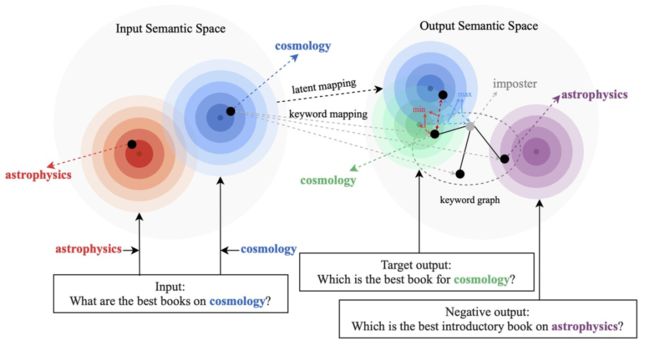
现有的基于对比学习方法主要集中在整句层面实现 [1][2],而忽略了句子中的词粒度的实体的信息,下图中的例子展示了句子中关键词的重要意义,对于一个输入的句子,如果对它的关键词进行替换(e.g. cosmology->astrophysics),句子的含义会发生变化,从而在语义空间中的位置(由分布来表示)也会变化。而关键词作为句子中最重要的信息,对应于语义分布上的一个点,它很大程度上也决定了句子分布的位置。同时,在某些情况下,现有的对比学习目标对模型来说显得过于容易,导致模型无法真正学习到区分正负例之间的关键信息。
基于此,来自蚂蚁集团、北大等机构的研究者提出了一种多粒度对比生成方法,设计了层次化对比结构,在不同层级上进行信息增强,在句子粒度上增强学习整体的语义,在词粒度上增强局部重要信息。研究论文已被 ACL 2022 接收。

论文地址:https://aclanthology.org/2022.acl-long.304.pdf
方法
我们的方法基于经典的 CVAE 文本生成框架 [3][4],每个句子都可以映射成为向量空间中的一个分布,而句子中的关键词则可以看成是这个分布上采样得到的一个点。我们一方面通过句子粒度的对比来增强隐空间向量分布的表达,另一方面通过构造的全局关键词 graph 来增强关键词点粒度的表达,最后通过马氏距离对关键词的点和句子的分布构造层次间的对比来增强两个粒度的信息表达。最终的损失函数由三种不同的对比学习 loss 相加而得到。
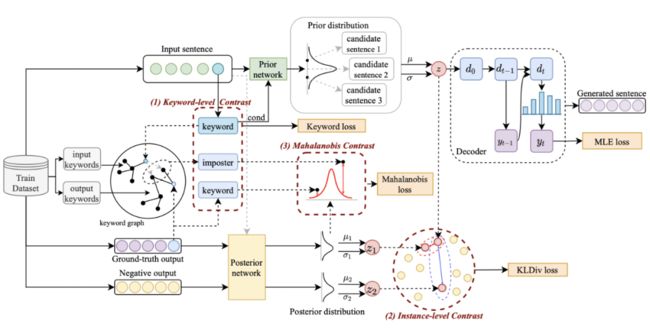
句子粒度对比学习
在 Instance-level,我们利用原始输入 x、目标输出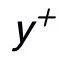 及对应的输出负样本构成了句子粒度的对比 pair
及对应的输出负样本构成了句子粒度的对比 pair 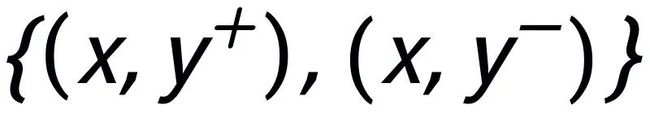 。我们利用一个先验网络学习到先验分布
。我们利用一个先验网络学习到先验分布 ,记为
,记为 ;通过一个后验网络学习到近似的后验分布
;通过一个后验网络学习到近似的后验分布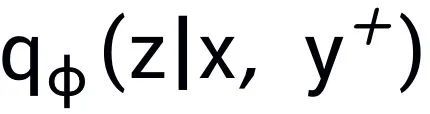 和
和 ,分别记为
,分别记为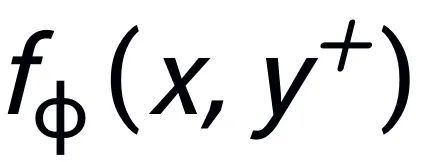 和
和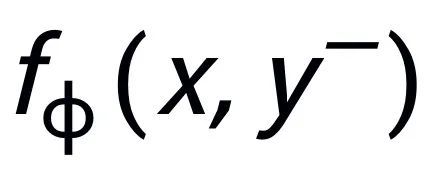 。句子粒度对比学习的目标就是尽可能的缩小先验分布和正后验分布的距离,同时尽可能的推大先验分布和负后验分布的距离,相应的损失函数如下:
。句子粒度对比学习的目标就是尽可能的缩小先验分布和正后验分布的距离,同时尽可能的推大先验分布和负后验分布的距离,相应的损失函数如下:
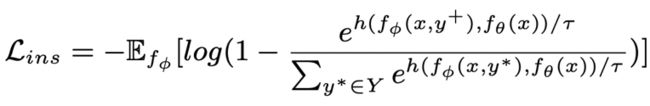
其中为正样本或负样本,为温度系数,用来表示距离度量,这里我们使用 KL 散度(Kullback–Leibler divergence )[5] 来度量两个分布直接的距离。
关键词粒度对比学习
关键词网络
关键词粒度的对比学习是用来让模型更多的关注到句子中的关键信息,我们通过利用输入输出文本对应的正负关系构建一个 keyword graph 来达到这个目标。具体来说,根据一个给定的句对 ,我们可以分别从其中确定一个关键词
,我们可以分别从其中确定一个关键词 和
和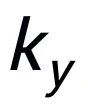 (关键词抽取的方法我采用经典的 TextRank 算法 [6]);对于一个句子
(关键词抽取的方法我采用经典的 TextRank 算法 [6]);对于一个句子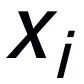 ,可能存在与其关键词
,可能存在与其关键词 相同的其他句子,这些句子共同组成一个集合
相同的其他句子,这些句子共同组成一个集合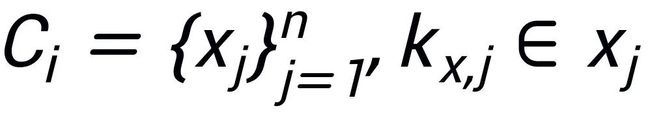 ,这里面每一个句子
,这里面每一个句子 都有一对正负例输出句子
都有一对正负例输出句子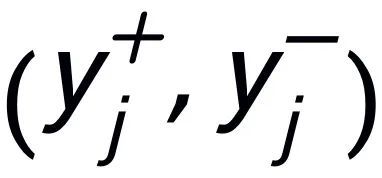 ,他们分别又有一个正例关键词
,他们分别又有一个正例关键词 和负例关键词
和负例关键词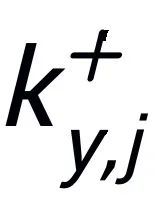 。这样在整个集合中,对任何一个输出的句子
。这样在整个集合中,对任何一个输出的句子 ,可以认为它所对应的关键词
,可以认为它所对应的关键词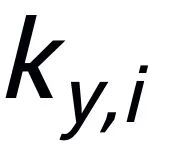 和每一个周围的
和每一个周围的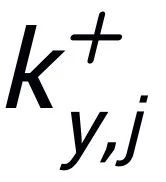 (通过句子之间的正负关系关联)之间都存在一条正边
(通过句子之间的正负关系关联)之间都存在一条正边 ,和每一个周围的
,和每一个周围的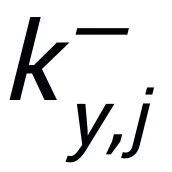 之间都存在一条负边
之间都存在一条负边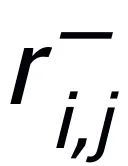 。基于这些关键词节点和他们直接的边,我们就可以构建一个 keyword graph
。基于这些关键词节点和他们直接的边,我们就可以构建一个 keyword graph  。
。
我们使用 BERT embedding[7] 来作为每个节点 的初始化,并使用一个 MLP 层来学习每条边的表示
的初始化,并使用一个 MLP 层来学习每条边的表示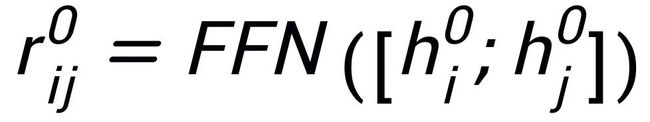 。我们通过一个 graph attention (GAT) 层和 MLP 层来迭代式地更新关键词网络中的节点和边,每个迭代中我们先通过如下的方式更新边的表示:
。我们通过一个 graph attention (GAT) 层和 MLP 层来迭代式地更新关键词网络中的节点和边,每个迭代中我们先通过如下的方式更新边的表示:
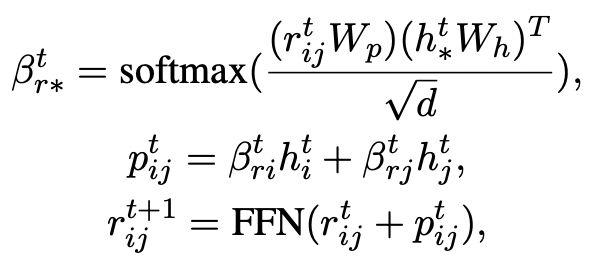
这里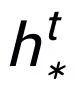 可以是
可以是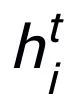 或者
或者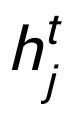 。
。
然后根据更新后的边 ,我们通过一个 graph attention 层来更新每个节点的表示:
,我们通过一个 graph attention 层来更新每个节点的表示:
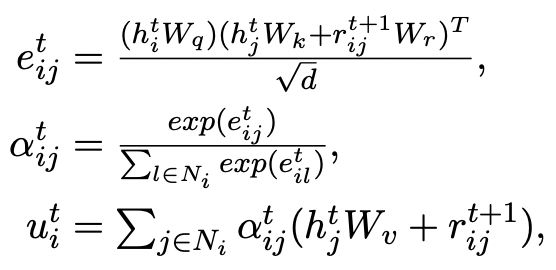
这里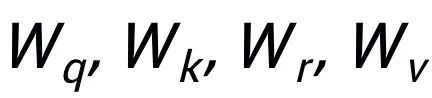 都是可学习的参数,
都是可学习的参数,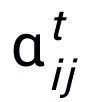 为注意力权重。为了防止梯度消失的问题,我们在
为注意力权重。为了防止梯度消失的问题,我们在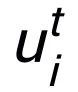 上加上了残差连接,得到该迭代中节点的表示
上加上了残差连接,得到该迭代中节点的表示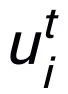 。我们使用最后一个迭代的节点表示作为关键词的表示,记为 u。
。我们使用最后一个迭代的节点表示作为关键词的表示,记为 u。
关键词对比
关键词粒度的对比来自于输入句子的关键词 和一个伪装(impostor)节点
和一个伪装(impostor)节点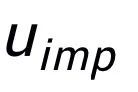 。我们将输入句子的输出正样本中提取的关键词记为
。我们将输入句子的输出正样本中提取的关键词记为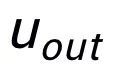 ,它在上述关键词网络中的负邻居节点记为
,它在上述关键词网络中的负邻居节点记为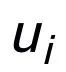 ,则
,则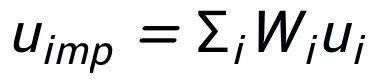 ,关键词粒度的对比学习 loss 计算如下:
,关键词粒度的对比学习 loss 计算如下:
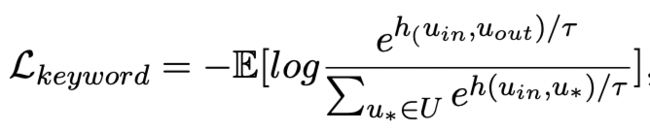
这里 用来指代
用来指代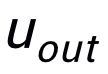 或者
或者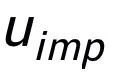 ,h(·) 用来表示距离度量,在关键词粒度的对比学习中我们选用了余弦相似度来计算两个点之间的距离。
,h(·) 用来表示距离度量,在关键词粒度的对比学习中我们选用了余弦相似度来计算两个点之间的距离。
跨粒度对比学习
可以注意到上述句子粒度和关键词粒度的对比学习分别是在分布和点上实现,这样两个粒度的独立对比可能由于差异较小导致增强效果减弱。对此,我们基于点和分布之间的马氏距离(Mahalanobis distance)[8] 构建不同粒度之间对比关联,使得目标输出关键词到句子分布的距离尽可能小于 imposter 到该分布的距离,从而弥补各粒度独立对比可能带来的对比消失的缺陷。具体来说,跨粒度的马氏距离对比学习希望尽可能缩小句子的后验语义分布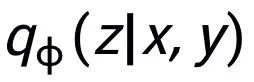 和
和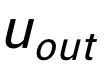 之间的距离,同时尽可能拉大其与
之间的距离,同时尽可能拉大其与 之间的距离,损失函数如下:
之间的距离,损失函数如下:
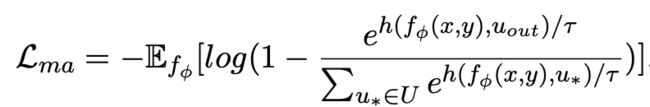
这里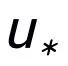 同样用来指代
同样用来指代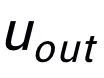 或者
或者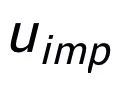 ,而 h(·) 为马氏距离。
,而 h(·) 为马氏距离。
实验 & 分析
实验结果
我们在三个公开数据集 Douban(Dialogue)[9],QQP(Paraphrasing)[10][11] 和 RocStories(Storytelling)[12] 上进行了实验,均取得了 SOTA 的效果。我们对比的基线包括传统的生成模型(e.g. CVAE[13],Seq2Seq[14],Transformer[15]),基于预训练模型的方法(e.g. Seq2Seq-DU[16],DialoGPT[17],BERT-GEN[7],T5[18])以及基于对比学习的方法(e.g. Group-wise[9],T5-CLAPS[19])。我们通过计算 BLEU score[20] 和句对之间的 BOW embedding 距离(extrema/average/greedy)[21] 来作为自动化评价指标,结果如下图所示:

我们在 QQP 数据集上还采用了人工评估的方式,3 个标注人员分别对 T5-CLAPS,DialoGPT,Seq2Seq-DU 以及我们的模型产生的结果进行了标注,结果如下图所示:

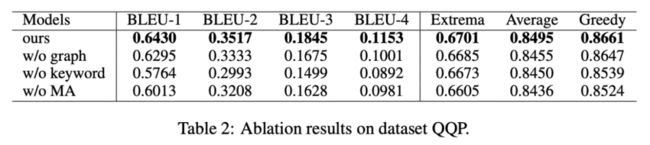
消融分析
我们对是否采用关键词、是否采用关键词网络以及是否采用马氏距离对比分布进行了消融分析实验,结果显示这三种设计对最后的结果确实起到了重要的作用,实验结果如下图所示。
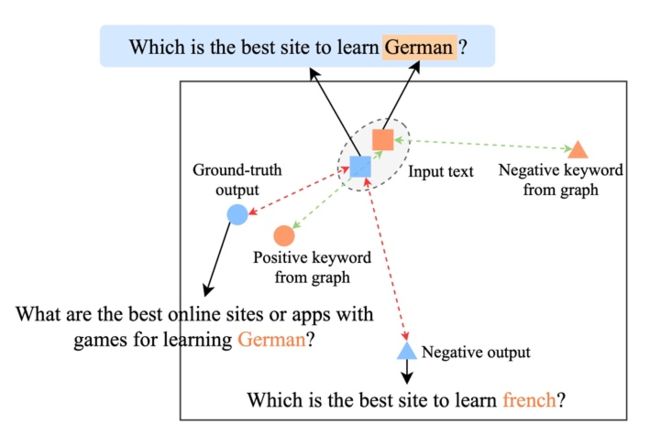
可视化分析
为了研究不同层级对比学习的作用,我们对随机采样的 case 进行了可视化,通过 t-sne[22] 进行降维处理后得到下图。图中可以看出,输入句子的表示与抽取的关键词表示接近,这说明关键词作为句子中最重要的信息,通常会决定语义分布的位置。并且,在对比学习中我们可以看到经过训练,输入句子的分布与正样本更接近,与负样本远离,这说明对比学习可以起到帮助修正语义分布的作用。
关键词重要性分析
最后,我们探索采样不同关键词的影响。如下表所示,对于一个输入问题,我们通过 TextRank 抽取和随机选择的方法分别提供关键词作为控制语义分布的条件,并检查生成文本的质量。关键词作为句子中最重要的信息单元,不同的关键词会导致不同的语义分布,产生不同的测试,选择的关键词越多,生成的句子越准确。同时,其他模型生成的结果也展示在下表中。

业务应用
这篇文章中我们提出了一种跨粒度的层次化对比学习机制,在多个文本生成的数据集上均超过了具有竞争力的基线工作。基于该工作的 query 改写模型在也在支付宝搜索的实际业务场景成功落地,取得了显著的效果。支付宝搜索中的服务覆盖领域宽广并且领域特色显著,用户的搜索 query 表达与服务的表达存在巨大的字面差异,导致直接基于关键词的匹配难以取得理想的效果(例如用户输入 query“新上市汽车查询”,无法召回服务 “新车上市查询”),query 改写的目标是在保持 query 意图不变的情况下,将用户输入的 query 改写为更贴近服务表达的方式,从而更好的匹配到目标服务。如下是一些改写示例:

参考文献
[1] Seanie Lee, Dong Bok Lee, and Sung Ju Hwang. 2021. Contrastive learning with adversarial perturbations for conditional text generation. In 9th International Conference on Learning Representations, ICLR.
[2] Hengyi Cai, Hongshen Chen, Yonghao Song, Zhuoye Ding, Yongjun Bao, Weipeng Yan, and Xiaofang Zhao. 2020. Group-wise contrastive learning for neural dialogue generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, EMNLP 2020.
[3] Jiwei Li, Minh-Thang Luong, and Dan Jurafsky. 2015. A hierarchical neural autoencoder for paragraphs and documents. arXiv preprint.
[4] Meng-Hsuan Yu, Juntao Li, Zhangming Chan, Dongyan Zhao, and Rui Yan. 2021. Content learning with structure-aware writing: A graph-infused dual conditional variational autoencoder for automatic storytelling. In Proceedings of the AAAI Conference on Artificial Intelligence.
[5] Solomon Kullback and Richard A Leibler. 1951. On information and sufficiency. The annals of mathematical statistics.
[6] Rada Mihalcea and Paul Tarau. 2004. Textrank: Bringing order into text. In Proceedings of the 2004 conference on empirical methods in natural language processing.
[7] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint.
[8] Roy De Maesschalck, Delphine Jouan-Rimbaud, and Désiré L Massart. 2000. The mahalanobis distance. Chemometrics and intelligent laboratory systems.
[9] Hengyi Cai, Hongshen Chen, Yonghao Song, Zhuoye Ding, Yongjun Bao, Weipeng Yan, and Xiaofang Zhao. 2020. Group-wise contrastive learning for neural dialogue generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, EMNLP 2020.
[10] Shankar Iyer, Nikhil Dandekar, and Kornel Csernai. 2017. First quora dataset release: Question pairs.
[11] Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In the Proceedings of ICLR.
[12] Nasrin Mostafazadeh, Nathanael Chambers, Xiaodong He, Devi Parikh, Dhruv Batra, Lucy Vanderwende, Pushmeet Kohli, and James Allen. 2016. A corpus and cloze evaluation for deeper understanding of commonsense stories. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
[13] Tiancheng Zhao, Ran Zhao, and Maxine Eskenazi. 2017. Learning discourse-level diversity for neural dialog models using conditional variational autoencoders. arXiv preprint.
[14] Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. 2014. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information.
[15] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017.
[16] Yue Feng, Yang Wang, and Hang Li. 2021. A sequence-to-sequence approach to dialogue state tracking. ACL 2021.
[17] Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, and Bill Dolan. 2020. Dialogpt: Large-scale generative pre-training for conversational response generation. In ACL, system demonstration.
[18] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res.
[19] Seanie Lee, Dong Bok Lee, and Sung Ju Hwang. 2021.
Contrastive learning with adversarial perturbations for conditional text generation. In 9th International Conference on Learning Representations, ICLR 2021.
[20] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In ACL.
[21] Xiaodong Gu, Kyunghyun Cho, Jung-Woo Ha, and Sunghun Kim. 2019. DialogWAE: Multimodal response generation with conditional wasserstein autoencoder. In International Conference on Learning Representations.
[22] Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-sne. Journal of machine learning research.
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型,刷新了14种数据集并达到新SoTA
阿里+北大 | 在梯度上做简单mask竟有如此的神奇效果
ACL'22 | 快手+中科院提出一种数据增强方法:Text Smoothing,非常简单且有效尤其在数据不足的情况下