工业蒸汽量预测
关与作者更多博客请访问云里云外开源社区
工业蒸汽量预测
1 赛题理解
1.1 赛题背景
火力发电的基本原理是:燃料在燃烧时加热水生成蒸汽,蒸汽压力推动汽轮机旋转,然后汽轮机带动发电机旋转,产生电能。在这一系列的能量转化中,影响发电效率的核心是锅炉的燃烧效率,即燃料燃烧加热水产生高温高压蒸汽。锅炉的燃烧效率的影响因素很多,包括锅炉的可调参数,如燃烧给量,一二次风,引风,返料风,给水水量;以及锅炉的工况,比如锅炉床温、床压,炉膛温度、压力,过热器的温度等。
1.2 赛题目标
经脱敏后的锅炉传感器采集的数据(采集频率是分钟级别),根据锅炉的工况,预测产生的蒸汽量。
1 数据概览
1.数据下载
在阿里云天池平台学习赛中可以找到此次比赛,参加比赛后在赛题与数据栏可以免费下载脱敏后的数据。
2.数据说明
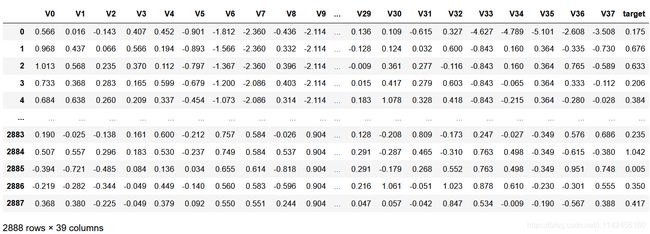
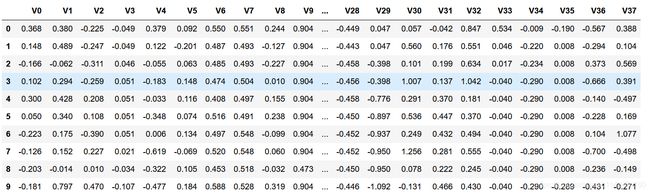
其中V0-V37共38个字段是特征向量,target是目标变量。可以理解为V0~V37是影响锅炉燃烧效率的因素,target是在某一时间及给定的因素下锅炉产生的蒸汽量。
1.4评估指标
预测结果以均方误差MSE(Mean Squared Error)作为评判标准。
M S E = S S E n = 1 n ∑ i = 1 n w i ( y i − y ^ i ) 2 MSE=\frac{SSE}{n}=\frac{1}{n}\sum_{i=1}^nw_i(y_i-\widehat{y}_i)^2 MSE=nSSE=n1i=1∑nwi(yi−y i)2
其中 y i y_i yi为真实值, y ^ i \widehat{y}_i y i为你的预测值。MSE是衡量“平均误差”的一种较为方便的方法。MSE值越小,说明预测模型描述数据具有越高的准确度。在sklearn中可以直接调用mean_squared_error函数计算MSE。
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test,t_predict)
1.5 赛题模型
在赛题分析中,很重要的一点就是要根据赛题的特点和目标明确问题的类型,并选择合适的模型。在机器学习中,根据问题类型的不同,常用的模型包括回归预测模型和分类预测模型
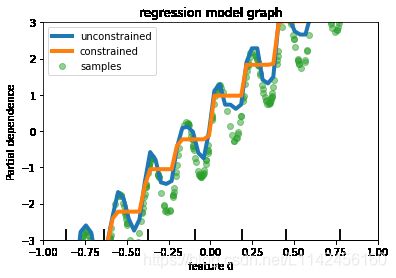
1.回归预测模型
回归预测模型的预测结果是一个连续值域上的任意值。我们通常吧多个输入变量的回归问题称为多元回归问题,输入变量按时间排序的问题称为时间序列排序问题。
2.分类预测模型
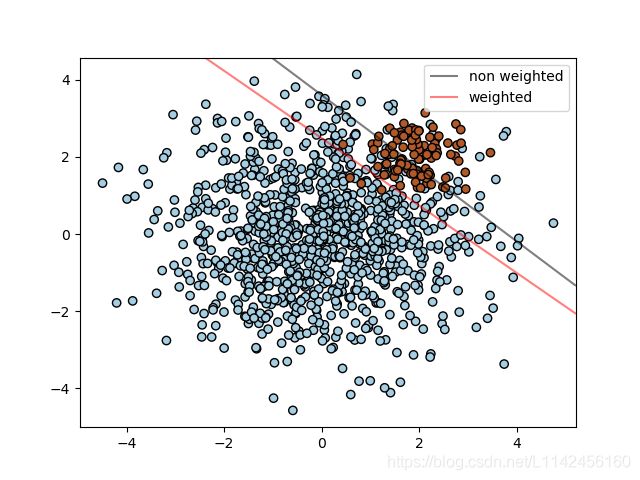
分类预测模型的分类问题要求将实例分为两个或多个类中的一个,并具有实值或离散的输入变量。其中,两个类别的问题通常被称为二类分类问题或二元分类问题,多于两个类别的问题通常被称为多类别分类问题。
下图为SVM分类分类二维数据的示意图,图中的红线将红点和蓝点分开
3.解题思路
在本赛题中,需要用到V0~V37共38个特征变量来预测蒸汽量的数值,数值是一个连续值域上的任意值,故此问题用回归预测算法求解。
回归预测模型使用的算法包括线性回归(Liner Regression)、岭回归(Ridge Regression)、LASSO(Least Absolute Shrinkage and Selection Operator)回归、决策树回归(Decision Tree Regressor)、梯度提升树回归(Gradient Boosting Decision Tree Regressor)。在后面的模型训练中,我们将采用这些模型来预测目标值。
2 数据探索
2.1理论知识
2.1.1变量识别
这一部分即是对数据表的一个归纳整理,具体要做到区分以下几点。分别给出数据表中的变量分别在不同的分类标准中是什么。
- 输入变量与输出变量
输入变量(predictor或特征):V0~V37
输出变量(target或标签):target
- 数据类型
字符型数据有:很遗憾,此次赛题中没有字符型数据
数值型数据有:V0~V37,target
- 连续型变量与类别型变量
连续型变量(特征):V0~V37,target
类别型变量(特征):无
2.1.2 变量分析
1. 单变量分析
对于连续型变量,需要统计数据的中心分布趋势和变量的分布
| Central Tendency(中心分布趋势) | Measure of Dispersion(离散程度) | Visualization Methods(可视化方法) |
|---|---|---|
| Mean(均值) | Range | Histogram(直方图) |
| Median(中位数) | Quartile(四分位数) | Box Plot(箱型图) |
| Mode(众数) | IQR四分位距 | |
| Min | Variance(方差) | |
| Max | Standard Deviation(标准差) | |
| Slewness and Kurtosis(偏度和峰度) |
对于类别型变量,一般使用频次或占比表示每一个变量分分布情况,对应的衡量指标分别是类别变量的频次和频率,可以用柱形图来表示可视化分布情况。
2. 双变量分析
使用双变量分析可以发现变量之间的关系。根据变量类型的不同,可以分为连续型与连续型、类别型与类别型、类别型与连续型三种双变量分析组合。
(1)连续型与连续型。
绘制散点图和计算相关性是分析连续型与连续型双变量的常用方法。
-
绘制散点图:散点图的形状可以反映变量之间的关系是线性(linear)还是非线性(non-linear)。
-
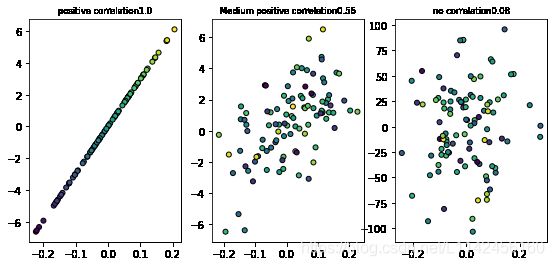
计算相关性:散点图只能直观的显示双变量(特征)之间的关系,但并不能说明关系的强弱,而相关性可以对变量之间的关系进行量化分析。相关性系数的公式如下
C o r r e l a t i o n = C o v a r i a n c e ( X , Y ) V a r ( X ) ∗ V a r ( Y ) 2 Correlation=\frac{Covariance(X,Y)}{\sqrt[2]{Var(X)*Var(Y)}} Correlation=2Var(X)∗Var(Y)Covariance(X,Y)
相关性系数的取值区间为[-1,1]。当相关性系数为-1时,表示强负线性相关;当相关性系数为1时,表示强正相关;当相关性系数为0时,表示不相关。
对相关性进行计算。用np.corrcoef();前提是X与Y的维度数必须一致。参考资料
import numpy as np
Array1 = [[1, 2, 3], [4, 5, 6]]
Array2 = [[11, 25, 346], [734, 48, 49]]
Mat1 = np.array(Array1)
Mat2 = np.array(Array2)
correlation = np.corrcoef(Mat1, Mat2)
print("矩阵1=\n", Mat1)
print("矩阵2=\n", Mat2)
print("相关系数矩阵=\n", correlation)
矩阵1=
[[1 2 3]
[4 5 6]]
矩阵2=
[[ 11 25 346]
[734 48 49]]
相关系数矩阵=
[[ 1. 1. 0.88390399 -0.86539304]
[ 1. 1. 0.88390399 -0.86539304]
[ 0.88390399 0.88390399 1. -0.53057867]
[-0.86539304 -0.86539304 -0.53057867 1. ]]
一般来说,在取绝对值后,0-0.09为没有相关性,0.1-0.3为弱相关,0.3-0.5为中相关,0.5-0.1为强相关
(2)类别型与类别型
一般采用双向表、堆叠柱状图和卡方检验进行分析:
- 双向表:暂时还没找到可以用程序生成的库,但用python画表格是可以的。或者自己用excel做

- 堆叠柱状图:较双向表更加直观 参考资料
- 卡方检验:主要用于两个和两个以上样本率(构成比)及两个二值型离散变量的关联性分析,即比较理论频次与实际频次的吻合程度或拟合优度
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
iris = load_iris()
X,y = iris.data,iris.target
ChiValues = chi2(X,y)
X_new = SelectKBest(chi2,k=2).fit_transform(X,y)
X_new
(3)类别型与连续型
绘制小提琴图(Violin Plot),可以分析类别变量在不同类别时,另一个连续变量的分布情况。 参考资料

分布信息
小提琴图中间的黑色粗条用来显示四分位数。黑色粗条中间的白点表示中位数,粗条的顶边和底边分别表示上四分位数和下四分位 数,通过边的位置所对应的y轴的数值就可以看到四分位数的值。
由黑色粗条延伸出的黑细线表示95%的置信区间。
概率密度信息
从小提琴图的外形可以看到任意位置的数据密度,实际上就是旋转 了90度的密度图。
小提琴图越宽,表示密度越大。可以展示出数据的多个峰值。
2.1.3 缺失值处理
(1)删除
成列删除:某一个样本有一个或多个属性有缺失值则将此样本删除
成对删除:只删除对应样本的某个缺失值,在模型中使用不同大小的样本集(没看懂)
(2)平均值、中值、众数填充:最常用的方法
(3)预测模型填充:预测出的值往往更加“规范”;若变量间不存在关系,则得到的缺失值会不准确
2.1.4 异常值处理
1. 异常值检测
一般可以采用可视化方法进行异常值的检测,常用有箱线图、直方图、散点图
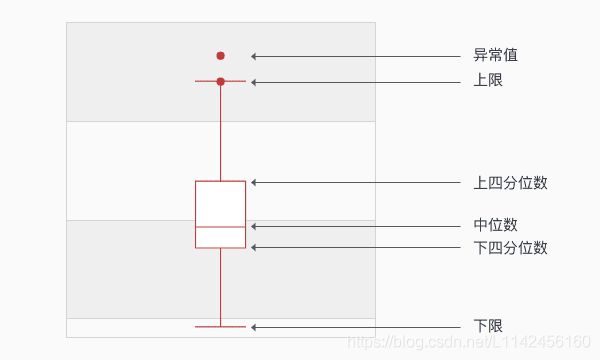
其中IQR(interquartile range)四分位距指的是上下四分位数的差值。上限和下限各距离上下四分位数1.5*IQR
还有两种方法:
- 使用封顶方法可以认为在第5和第95百分位数范围之外的任何值都是异常值
- 距离平均值为三倍标准差或者更大的数据点可以被认为是异常值
2. 异常值处理
- 删除
- 转换:可以对数据取对数
- 填充:使用平均值、中值进行填充,如果异常值是人为造成的,可用预测值填充处理
- 区别对待:如果存在大量的异常值,应在统计模型中区别对待。其中一个方法是将数据分为两个不同的组,异常值归位一组,非异常值归位一组,两组分别建立模型,最终将两组的输出合并
2.1.5 变量转换
在使用直方图、核密度估计等工具对特征分布进行分析时,可能会发现一些变量的取值分布不均匀,这将会极大影响估计。为此,我们需要对变量的取值区间等进行转换,使其分布落在合理的区间内。
方法:缩放比例或标准化、非线性关系转换成线性、使倾斜分布对称、变量分组等
| 变量转换方法 | 说明 |
|---|---|
| 缩放比例或标准化 | 数据具有不同的缩放比例,其不会更改变量的分布 |
| 非线性关系转换成线性 | 将非线性变量的关系转换为线性关系更容易理解,其中对数转换是最常用的一种转换方式 |
| 使倾斜分布对称 | 对于向右倾斜的分布,对变量取平方根或立方根或对数;对于向左倾斜的分布,对变量取平方根或立法或指数 |
| 变量分组 | 根据不同的目标把变量按不同类别分组 |
(1)对数变换:对变量取对数,可以更改变量的分布形状。其通常应用于向右倾斜的分布,缺点是不能用于含有零或负值的变量
(2)取平方根或立方根:变量的平方根和立方根对其分布有波形的影响。取平方根可用于包括零的正值,取立方根可用于取值中有负值(包括零)的情况。
(3)变量分组:对变量进行分类,如可以基于原始值、百分比或频率等对变量分类。例如,我们可以将收入分为高、中、低三类。其可以应用于连续型数据,超高维逻辑回归就是采用这种方式产生one-hot变量特征的。
2.1.6 新变量生成
变量生成是基于现有变量生成新变量的过程。生成的新变量可能与目标变量有更好的相关性,有助于数据分析。
例如,可以将日期20xx-xx-xx变量拆分成年、月、日,也可能会发现与目标变量相关性更强的新变量
- 创建派生变量:使用一组函数或不同方法从现有变量创建新变量。例如,在某个数据集中需要预测缺失的年龄值,为了预测缺失项的价值,我们可以提取名称中的称呼(Master、Mr、Mrs、Miss)作为新变量
- 创建哑变量:将类别型变量转换为数值型变量。例如将性别变量转换为男性和女性,1为是,0为否。
2.2 赛题数据探索
2.2.1 导入工具包
先导入一些常用的数据处理和可视化的包,numpy、pandas、matplotlib三剑客就不用说了;
Seaborn是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。应该把Seaborn视为matplotlib的补充,而不是替代物。同时它能高度兼容numpy与pandas数据结构以及scipy与statsmodels等统计模式。Seaborn简介
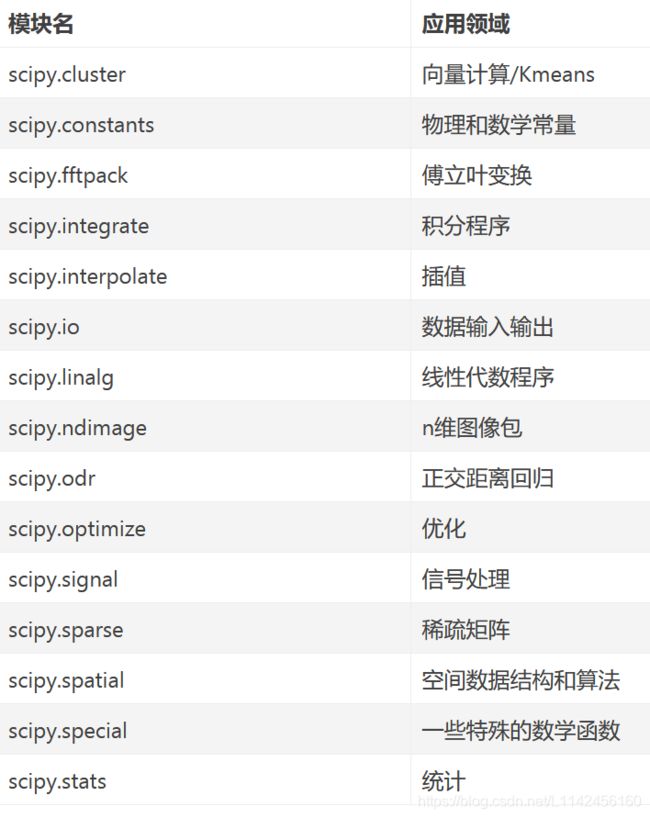
Scipy是一个用于数学、科学、工程领域的常用软件包,可以处理插值、积分、优化、图像处理、常微分方程数值解的求解、信号处理等问题。它用于有效计算Numpy矩阵,使Numpy和Scipy协同工作,高效解决问题。Scipy参考资料
Scipy是由针对特定任务的子模块组成:
warnings.filterwarnings(“ignore”)可以帮助过滤掉一些不必要的异常
%matplotlib inline 是一个魔法函数,加上之后不用plt.show()也可以显示图像 %matplotlib inline参考资料
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
2.2.2 读取并查看
这里基本上是用pandas的各个模块去做数据的基本使用和情况介绍
train_data_file = "./zhengqi_train.txt"
test_data_file = "./zhengqi_test.txt"
#读取文本文件,设置分隔符为‘\t’
train_data = pd.read_csv(train_data_file, sep='\t', encoding='utf-8')
test_data = pd.read_csv(test_data_file, sep='\t', encoding='utf-8')
这里也是基于pandas返回series或DataFrame对象调用对应的方法
- train_data.info():可以得出样本数、特征数及其变量类型,有无缺失值等情况
- train_data.describe():可以得出样本数、样本均值、标准差、最大最小值、各个分位点
- train_data.head():返回前n条数据
2.2.3 可视化数据分布
这里用seaborn和matplotlib搭配使用来做数据可视化
1. 箱形图(箱线图)
这里画出了38个特征变量V0~V37的箱形图,上面异常值处理的箱线图是竖立摆放,这里是横放,但原理一致。

fig = plt.figure(figsize=(80,60),dpi=75)
for i in range(38):
plt.subplot(7,8,i+1) #7行8列的第i个子图
sns.boxplot(train_data[columns[i]], orient="V", width=0.5) #箱式图
plt.ylabel(columns[i], fontsize=36)
2. 获取异常数据并画图
此方法是采用模型预测的形式找出异常值,在完成模型训练和验证的理论讲解后,再介绍此部分
3. 直方图和Q-Q图
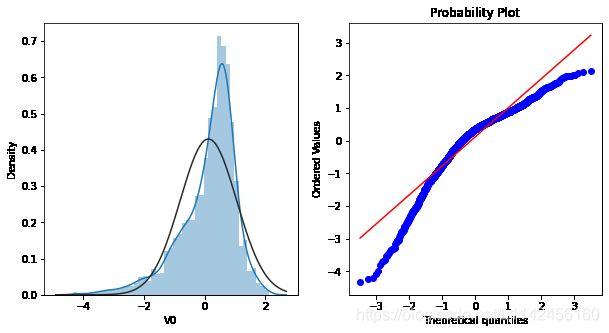
查看特征变量‘V0’的数据分布直方图,并绘制Q-Q图查看数据是否近似于正态分布
左侧的图为分布直方图,它由两部分组成,一是直方图,二是核密度估计(蓝色曲线),黑色曲线为正态分布;分别由以下三个参数来控制是否显示。 sns.distplot()
- hist=True:显示直方图
- kde=True:显示核密度估计
- fit=stats.norm:拟合正态分布
右侧的图为Q-Q图(quantiles-quantiles;Q代表分位数),也是散点图的一种,是指数据的分位数和正态分布的分位数对比参照的图。图中蓝色的散点是自己提供的数据,红线是正态分布的数据。主要用于回答下列问题
-
两组数据是否来自同一分布
-
两组数据的尺度范围是否一致
-
两组数据是否有类似的分布形状
Q-Q图可用stats.probplot(x, sparams=(), dist=‘norm’, fit=True, plot=None, rvalue=False)绘制 stats.probplot
stats.probplot(grade, dist=stats.norm, plot=plt) #正态分布
# stats.probplot(grade, dist=stats.expon, plot=plt) #指数分布
# stats.probplot(grade, dist=stats.logistic, plot=plt) #对数正态分布
plt.show()
至此,我们可以看到特征变量V0的分布不是正态分布。如上,对所有变量都做检测
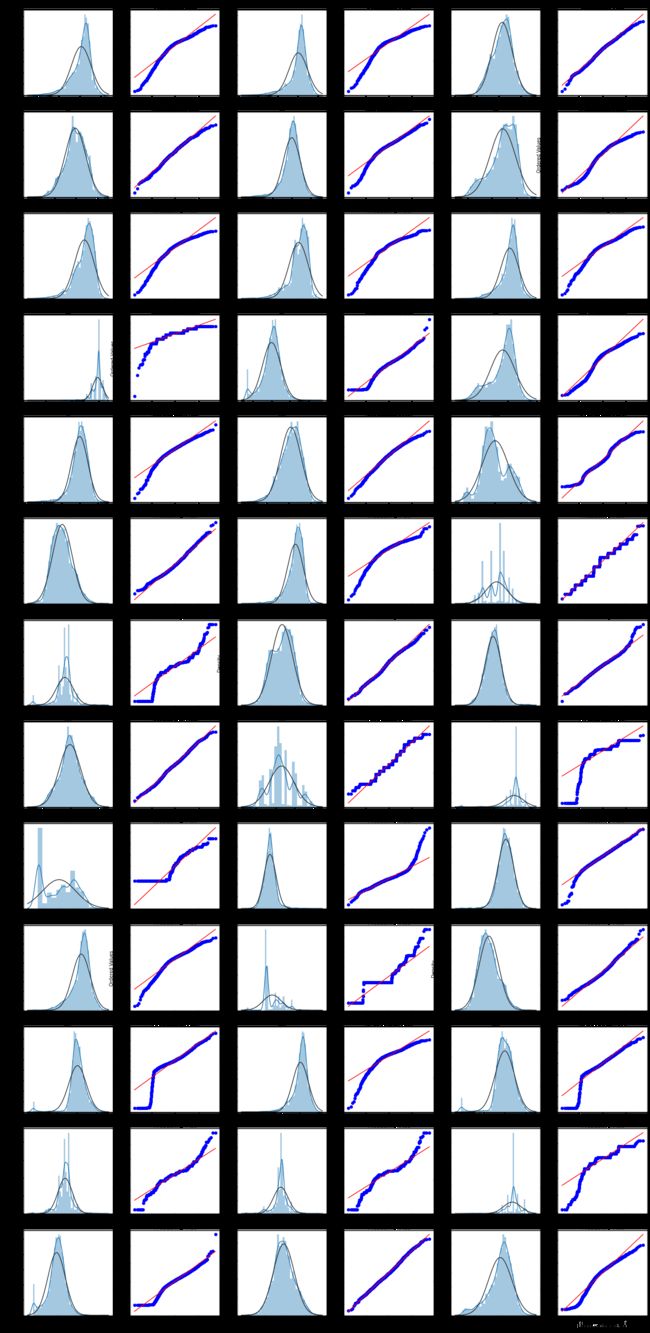
由上面的数据分布图信息可以看出,很多特征变量(如’V1’,‘V9’,‘V24’,'V28’等)的数据分布不是正态的,数据并不跟随对角线,后续可以使用数据变换对数据进行转换。
4. KDE分布图
KDE(Kernel Density Estimation,核密度估计)可以理解为对直方图的加窗平滑。可以对比训练集和测试集中的分布情况,并查看数据分布是否一致。
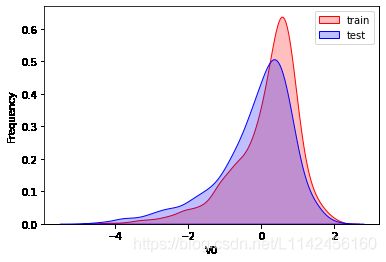
可以看到,V0在两个数据集中的分布基本一致。然后对比所有变量在训练集和测试集的KDE分布。
dist_cols = 6
dist_rows = len(test_data.columns)
plt.figure(figsize=(4*dist_cols,4*dist_rows))
i=1
for col in test_data.columns:
ax=plt.subplot(dist_rows,dist_cols,i)
ax = sns.kdeplot(train_data[col], color="Red", shade=True) # sns.kdeplot()核密度估计图
ax = sns.kdeplot(test_data[col], color="Blue", shade=True)
# 参考文章https://www.cnblogs.com/cgmcoding/p/13384442.html
ax.set_xlabel(col)
ax.set_ylabel("Frequency")
ax = ax.legend(["train","test"])
i+=1
plt.show()
可以发现,特征变量V5,V9,V11,V17,V22,V28在训练集与测试集中的分布不一致,这会导致模型的泛华能力变差,需要删除此类特征。
5. 线性回归关系图
用于分析两个变量之间的线性回归关系,首先查看特征变量V0与target变量的线性回归关系。
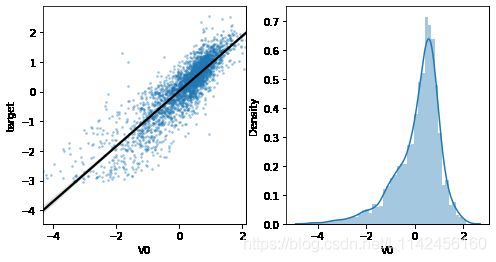
fcols = 2
frows = 1
plt.figure(figsize=(8,4))
ax=plt.subplot(1,2,1)
sns.regplot(x='V0', y='target', data=train_data, ax=ax,
scatter_kws={'marker':'.','s':3,'alpha':0.3},
line_kws={'color':'k'}); # 线性回归关系图用来比较两个变量的关系,是否符合线性回归。一般用来比较特征变量和标签变量上。
plt.xlabel('V0')
plt.ylabel('target')
ax=plt.subplot(1,2,2)
sns.distplot(train_data['V0'].dropna()) #核密度和直方图
# train_data['V0'].dropna()默认是删除带缺失值的所有行,默认并没有改变原数据,只是返回了修改后数据的副本
# 参考文章 https://blog.csdn.net/bamboo_128/article/details/106585634
plt.xlabel('V0')
plt.show()
sns.regplot(x,y,data,ax,…)
data:DataFrame
DataFrame,其中每列是变量,每行都是一个样本。
x, y:string, series, or vector array
x和y分别是横轴和纵轴对应的变量名,注意,如果x和y是String类型,其值必须来自data的列名
{scatter,line}_kws:字典类型
Additional keyword arguments to pass to
plt.scatterandplt.plot.scatter_kws和line_kws分别将参数传递给plt.scatter()和plt.plot()
seaborn官方文档
sns.regplot参考资料
实战应用文章
2.2.5 查看特征变量的相关性
对特征变量的相关性进行分析,可以发现特征变量和目标变量及特征变量之间的关系,为特征工程中提取特征做准备。
1. 计算相关性系数
在删除训练集和测试集中分布不一致的变量后,计算剩余变量与target之间的相关性系数
data_train1 = train_data.drop(['V5','V9','V11','V17','V22','V28'],axis=1)
train_corr = data_train1.corr()
train_corr
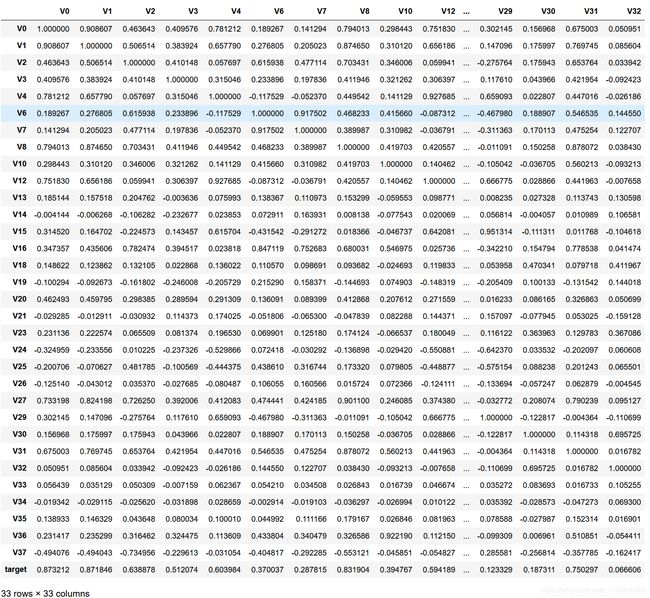
但这样看起来很累,也不直观,下面介绍一种比较直观的方法。
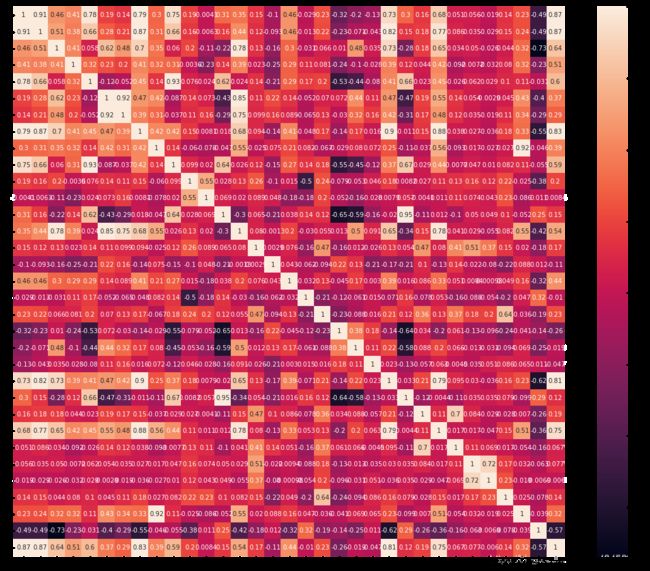
2. 画出相关性热力图
ax = plt.subplots(figsize=(20, 16))#调整画布大小
ax = sns.heatmap(train_corr, vmax=.8, square=True, annot=True)#画热力图 annot=True 显示系数
3. 根据相关系数筛选特征变量
首先寻找K个与target变量最相关的特征变量(K=10)
k = 10 # number of variables for heatmap
cols = train_corr.nlargest(k,'target')['target'].index
cm = np.corrcoef(train_data[cols].values.T)
hm = plt.subplots(figsize=(10,10))
hm= sns.heatmap(train_data[cols].corr(),annot=True,square=True)
plt.show()
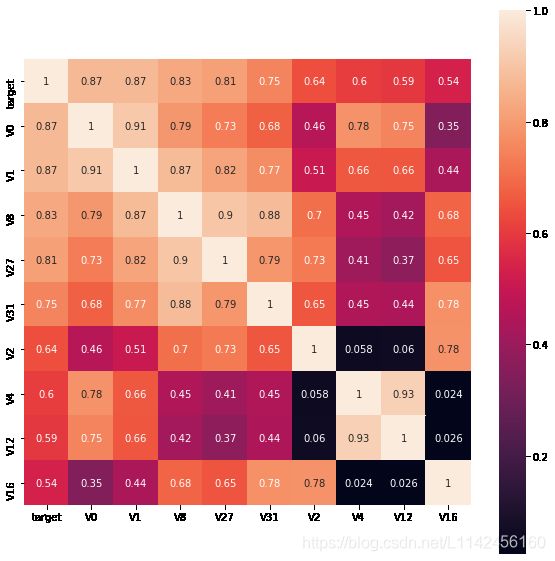
然后找出与target变量的相关系数大于0.5的特征变量:
threshold = 0.5
corrmat = train_data.corr()
top_corr_features = corrmat.index[abs(corrmat["target"])>threshold]
plt.figure(figsize=(10,10))
g = sns.heatmap(train_data[top_corr_features].corr(),annot=True,cmap="RdYlGn")
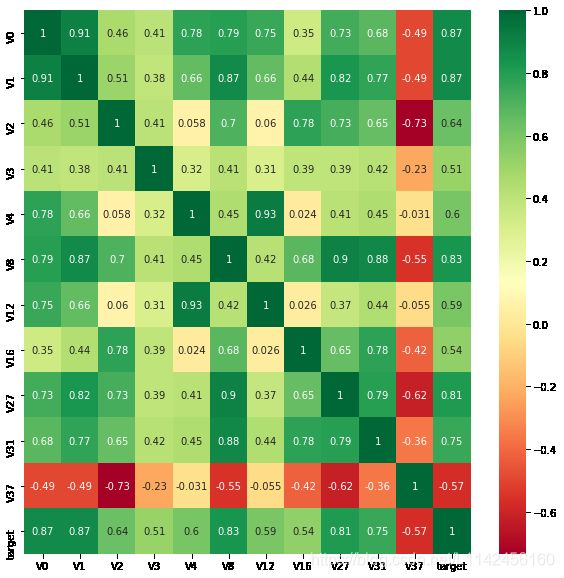
可以发现,与target变量的相关系数大于0.5的特征变量被直观地筛选出来。这一方法可以简单、直观地判断哪些特征变量线性相关,相关系数越大,就认为这些特征变量对target变量的线性影响越大
说明:相关性选择主要用于判别线性相关,对于target变量如果存在更复杂的函数形式的影响,则建议使用树模型的特征重要性去选择。
用相关系数阙值移除相关特征:(这里先不删除,因为后续分析还会用到)
threshold = 0.5
# Absolute value correlation matrix
corr_matrix = data_train1.corr().abs()
drop_col=corr_matrix[corr_matrix["target"]<threshold].index
#data_all.drop(drop_col, axis=1, inplace=True)
4. Box-Cox变换
由于线性回归是基于正态分布的,因此在进行统计分析时,需要将数据转换使其符合正态分布
Box-Cox变换是统计建模中常用的一种数据转换方法。在连续的响应变量不满足正太分布时,可以使用Box-Cox变换,这一变换可以使线性回归模型在满足线性、正态性、独立性及方差齐性的同时,又不丢失信息。在对数据做Box-Cox变换之后,可以在一定程度上减小不可观测的误差和预测变量的相关性,这有利于线性模型的拟合及分析出特征的相关性
在做Box-Cox变换之前,要对数据做归一化预处理。在归一化时,对数据进行合并操作可以使训练数据和测试数据一致。这种方式可以在线下分析建模中使用,而线上部署只需要采用训练数据的归一化即可。
#merge train_set and test_set
train_x = train_data.drop(['target'], axis=1)
#data_all=pd.concat([train_data,test_data],axis=0,ignore_index=True)
data_all = pd.concat([train_x,test_data])
data_all.drop(drop_columns,axis=1,inplace=True)
#View data
data_all.head()
对合并后的每列数据进行归一化
# normalise numeric columns
cols_numeric=list(data_all.columns)
def scale_minmax(col):
return (col-col.min())/(col.max()-col.min())
data_all[cols_numeric] = data_all[cols_numeric].apply(scale_minmax,axis=0)
data_all[cols_numeric].describe()
也可以分开对训练数据和测试数据进行归一化处理,不过这种方式需要建立在训练数据和测试数据分步一致的前提下,建议在数据量大的情况下使用(数据量大,一般分步比较一致),能加快归一化的速度。而数据量较小会存在分步差异较大的情况,此时,在数据分析和线下建模中应该将数据统一归一化。
#col_data_process = cols_numeric.append('target')
train_data_process = train_data[cols_numeric]
train_data_process = train_data_process[cols_numeric].apply(scale_minmax,axis=0)
test_data_process = test_data[cols_numeric]
test_data_process = test_data_process[cols_numeric].apply(scale_minmax,axis=0)
对特征变量做Box-Cox变换后,计算分位数并画图展示(基于正太分布),显示特征变量与target变量的线性关系
cols_numeric_left = cols_numeric[0:13]
cols_numeric_right = cols_numeric[13:] #这里是将特征分为两部分,前13个为第一部分
## Check effect of Box-Cox transforms on distributions of continuous variables
train_data_process = pd.concat([train_data_process, train_data['target']], axis=1)
fcols = 6
frows = len(cols_numeric_left)
plt.figure(figsize=(4*fcols,4*frows))
i=0
for var in cols_numeric_left:
dat = train_data_process[[var, 'target']].dropna()
i+=1
plt.subplot(frows,fcols,i)
sns.distplot(dat[var] , fit=stats.norm);
plt.title(var+' Original')
plt.xlabel('')
i+=1
plt.subplot(frows,fcols,i)
_=stats.probplot(dat[var], plot=plt)
plt.title('skew='+'{:.4f}'.format(stats.skew(dat[var]))) #计算数据集的偏度
plt.xlabel('')
plt.ylabel('')
i+=1
plt.subplot(frows,fcols,i)
plt.plot(dat[var], dat['target'],'.',alpha=0.5)
plt.title('corr='+'{:.2f}'.format(np.corrcoef(dat[var], dat['target'])[0][1]))
i+=1
plt.subplot(frows,fcols,i)
trans_var, lambda_var = stats.boxcox(dat[var].dropna()+1)
trans_var = scale_minmax(trans_var) # 数据归一化 参考文章 https://blog.csdn.net/Jiaach/article/details/79484990?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param
sns.distplot(trans_var , fit=stats.norm);
plt.title(var+' Tramsformed')
plt.xlabel('')
i+=1
plt.subplot(frows,fcols,i)
_=stats.probplot(trans_var, plot=plt)
plt.title('skew='+'{:.4f}'.format(stats.skew(trans_var))) #归一化后,偏度明显变小,相关性变化不大
plt.xlabel('')
plt.ylabel('')
i+=1
plt.subplot(frows,fcols,i)
plt.plot(trans_var, dat['target'],'.',alpha=0.5)
plt.title('corr='+'{:.2f}'.format(np.corrcoef(trans_var,dat['target'])[0][1]))
这里仅展示部分数据。可以发现,经过变换后,变量分布更接近正太分布,而且从图中可以更加直观地看出特征变量与target变量的线性相关性