NLP学习—24.Pre-trained Word Embedding—ELMO、GPT、Bert
文章目录
-
-
- 引言
- 一、ELMO
-
- 1.ELMO预训练后的使用
- 2.ELMO的优点与缺点
- 3.ELMO把三种不同的向量叠加的意义
- 二、GPT
-
- 1.GPT缺点(与Bert相比)
- 三、Bert
- 四、总结
-
引言
预训练模型在NLP下游任务上非常重要。
一、ELMO
ELMO是"Embedding from Language Model"的简称,论文是《Deep Contextualized Word Representation》。在ELMO之前,word embedding 本质上是静态的表示方式,也就是在词向量训练之后每个单词的表达就固定住了,这个单词的word embedding 不会随着上下文场景的变化而改变。缺点就是对于多义词(如英文中的Bank),在不同语言场景下表达的是同一个word embedding,这是不应该的。ELMO的本质思想是,事先用语言模型学好一个单词的word embedding,此时多义词的word embedding是同一个表达,在句子中使用一个单词的word embedding时,此时单词已经具备了特定的上下文了,这时使用单词的上下文语义去调整单词的word embedding表示,这样经过调整后的word embedding更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题。本质上ELMO是根据上下文动态调整word embedding。

ELMO采用了典型的两阶段过程:
-
第一个阶段是利用语言模型进行预训练;
上图展示的是其预训练过程,它的网络结构采用了双层双向LSTM,目前语言模型训练的任务目标是根据单词 W i W_i Wi的上下文去正确预测单词 W i W_i Wi , W i W_i Wi之前的单词序列Context-before称为上文,之后的单词序列Context-after称为下文。图中左端的前向双层LSTM代表正方向编码器,输入的是从左到右顺序的除了预测单词 W i W_i Wi外的上文Context-before;右端的逆向双层LSTM代表反方向编码器,输入的是从右到左的逆序的句子下文Context-after;每个编码器的深度都是两层LSTM叠加。这个网络结构其实在NLP中是很常用的。
使用这个网络结构利用大量语料做语言模型任务就能预先训练好这个网络,如果训练好这个网络后,输入一个新句子sentence,句子中每个单词都能得到对应的三个Embedding:- 最底层是单词的Word Embedding,
- 往上走是第一层双向LSTM中对应单词位置的Embedding,这层编码单词的句法信息更多一些;
- 再往上走是第二层LSTM中对应单词位置的Embedding,这层编码单词的语义信息更多一些。
也就是说,ELMO的预训练过程不仅仅学会单词的Word Embedding,还学会了一个双层双向的LSTM网络结构,而这两者后面都有用。
-
第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。

那么预训练好网络结构后,如何给下游任务使用呢?上图展示了下游任务的使用过程,比如我们的下游任务仍然是QA问题,此时对于问句X,我们可以先将句子X作为预训练好的ELMO网络的输入,这样句子X中每个单词在ELMO网络中都能获得对应的三个Embedding,之后给予这三个Embedding中的每一个Embedding一个权重a,这个权重可以学习得来,根据各自权重累加求和,将三个Embedding整合成一个。然后将整合后的这个Embedding作为X句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。对于上图所示下游任务QA中的回答句子Y来说也是如此处理。因为ELMO给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为“Feature-based Pre-Training”。
1.ELMO预训练后的使用
ELMO训练好之后,对于输入的句子序列中的每个token,一个L层(这里L取2)的双向语言模型就会得到 2L+1个表示,即为:
![]()
其中, h k , 0 L M h_{k,0}^{LM} hk,0LM为token的表示, h k , j L M h_{k,j}^{LM} hk,jLM为每个双向LSTM层得到的表示。
注意:这里是将整个句子输入到双向语言模型中(双向LSTM网络结构),正向和反向LSTM网络共享token embedding 的输入,源码中token embedding、正向、反向LSTM的hidden state均为512维度,一个长度为n_sentences的句子,经过ELMO预训练网络,最后得到的embedding维度为:(n_sentences,3,max_sentence_length,1024)
下游任务将所有的表示都利用起来,并给他们分配权重,即为:
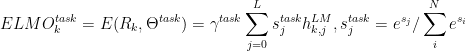
其中, s t a s k s^{task} stask是经过softmax归一化之后的权重,标量参数 γ t a s k \gamma^{task} γtask允许任务模型缩放整个ELMO向量。需要注意的是, γ t a s k \gamma^{task} γtask是一个超参数,实际上这个参数是经验参数,一定程度上能够增强模型的灵活性。总结起来整个为下游任务获取embedding的过程即为:
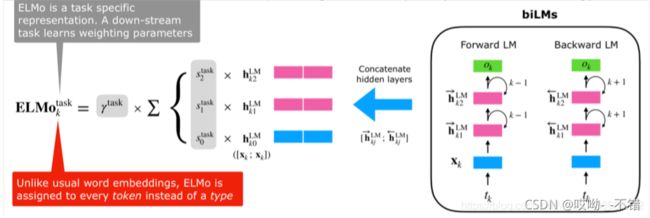
2.ELMO的优点与缺点
ELMo利用了深度上下文单词表征,该模型的优点:
- 引入双向语言模型,其实是 2 个单向语言模型(前向和后向)的集成
- 通过保存预训练好的 2 层 biLSTM,通过特征集成或 finetune 应用于下游任务
总结来说,通过上述结构,ELMo能够达到区分多义词的效果,每个单词(token)不再是只有一个上下文无关的embedding表示。
那么ELMo为什么有效呢?我认为主要原因有以下几点:
- 首先,ELMo的假设前提是一个词的词向量不应该是固定的,所以在多义词区分方面ELMo的效果必然比word2vec要好。
- 另外,ELMo通过语言模型生成的词向量是通过特定上下文的“传递”而来,再根据下游任务,不同维度的特征表示给予一个权重,这样既在原来的词向量中引入了上下文的信息,又能根据下游任务适时调整各部分的权重(权重是在网络中学习得来的),因此这也是ELMo有效的一个原因。
ELMo的缺点(与GPT和Bert对比):
- LSTM抽取特征能力远弱于Transformer
- 拼接方式双向融合,特征融合能力偏弱
3.ELMO把三种不同的向量叠加的意义
ELMo把三种不同的向量叠加的意义主要体现在以下两个点:
- 一是之前很多方法都只用了最顶层LSTM的hidden state,但是通过实验验证,在很多任务中,将每一层hidden
state融合在一起会取得更好的效果; - 二是在上述实验中得到结论,每一层LSTM得到单词的embedding所蕴含的信息是不一样的,因此将所有信息融合起来,会让单词embedding的表达更丰富。
这样做能够起到区分多义词的效果,而且在论文展示的6个任务中都取得了SOTA的效果。
二、GPT
GPT来自于Transformer的decoder,它是一个生成模型。
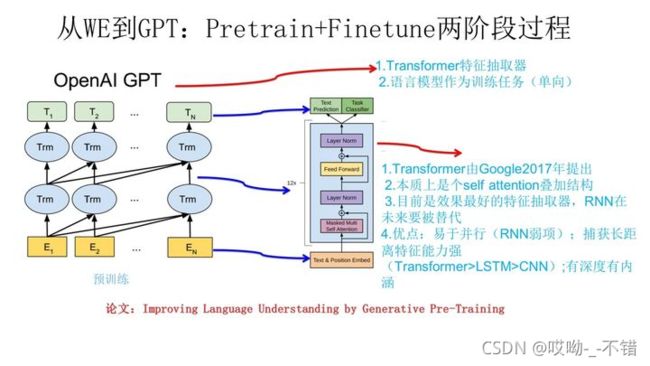
GPT是“Generative Pre-Training”的简称,从名字看其含义是指的生成式的预训练。GPT也采用两阶段过程:
-
第一个阶段是利用语言模型进行预训练,
上图展示了GPT的预训练过程,其实和ELMO是类似的,主要不同在于两点:- 首先,特征抽取器不是用的RNN,而是用的Transformer,上面提到过它的特征抽取能力要强于RNN,这个选择很明显是很明智的;
- 其次,GPT的预训练虽然仍然是以语言模型作为目标任务,但是采用的是单向的语言模型,所谓“单向”的含义是指:语言模型训练的任务目标是根据 W i W_i Wi单词的上下文去正确预测单词 W i W_i Wi , W i W_i Wi 之前的单词序列Context-before称为上文,之后的单词序列Context-after称为下文。ELMO在做语言模型预训练的时候,预测单词 W i W_i Wi同时使用了上文和下文,而**GPT则只采用Context-before这个单词的上文来进行预测,而抛开了下文。**这个选择现在看不是个太好的选择,原因很简单,它没有把单词的下文融合进来,这限制了其在更多应用场景的效果,比如阅读理解这种任务,在做任务的时候是可以允许同时看到上文和下文一起做决策的。如果预训练时候不把单词的下文嵌入到Word Embedding中,是很吃亏的,白白丢掉了很多信息。
-
第二阶段通过Fine-tuning的模式解决下游任务。
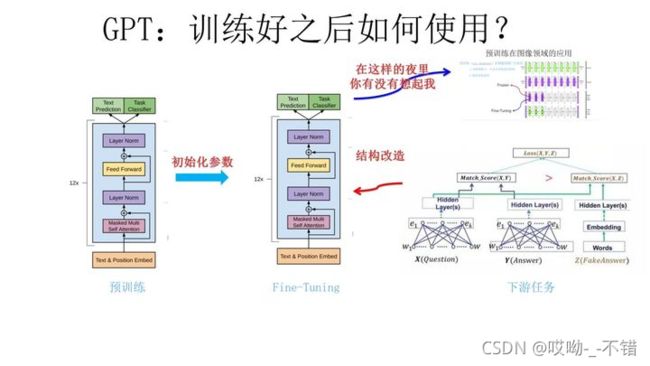
上图展示了GPT在第二阶段如何使用。首先,对于不同的下游任务来说,本来你可以任意设计自己的网络结构,现在不行了,你要向GPT的网络结构看齐,把任务的网络结构改造成和GPT的网络结构是一样的。然后,在做下游任务的时候,利用第一步预训练好的参数初始化GPT的网络结构,这样通过预训练学到的语言学知识就被引入到你手头的任务里来了,这是个非常好的事情。再次,你可以用手头的任务去训练这个网络,对网络参数进行Fine-tuning,使得这个网络更适合解决手头的问题。
对于NLP各种花样的不同任务,怎么改造才能靠近GPT的网络结构呢?

GPT论文给了一个改造施工图如上,其实也很简单:- 对于分类问题,不用怎么动,加上一个起始和终结符号即可;
- 对于句子关系判断问题,比如Entailment,两个句子中间再加个分隔符即可;
- 对文本相似性判断问题,把两个句子顺序颠倒下做出两个输入即可,这是为了告诉模型句子顺序不重要;
- 对于多项选择问题,则多路输入,每一路把文章和答案选项拼接作为输入即可。
- 对于生成任务,诸如:summarization,藏头诗、创意性写作,则

从上图可看出,这种改造还是很方便的,不同任务只需要在输入部分施工即可。
当然,由于GPT的基础模型是Transformer中的decoder部分。因此,GPT在训练过程中是一次输入,而在预测过程中,一步一步输入。其中,Mask Attention部分为:


1.GPT缺点(与Bert相比)
- GPT预训练阶段采用单向Transformer模型,而Bert模型是双向的。
三、Bert
GPT来自于Transformer的decoder,而Bert来自于Transformer的encoder。Bert的模型架构可参考:BERT模型—1.BERT模型架构。
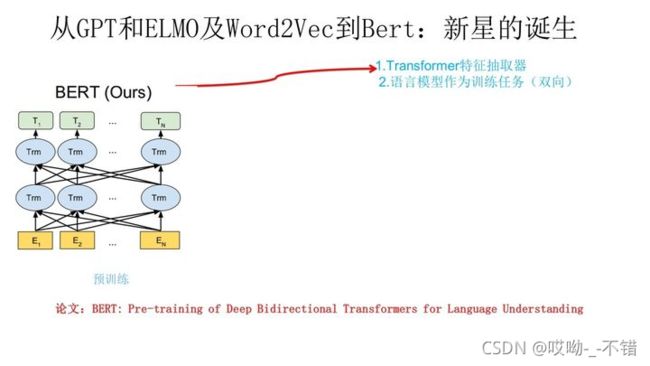
Bert采用和GPT完全相同的两阶段模型,首先是语言模型预训练;其次是使用Fine-Tuning模式解决下游任务。和GPT的最主要不同在于在预训练阶段采用了类似ELMO的双向语言模型,当然另外一点是语言模型的数据规模要比GPT大。
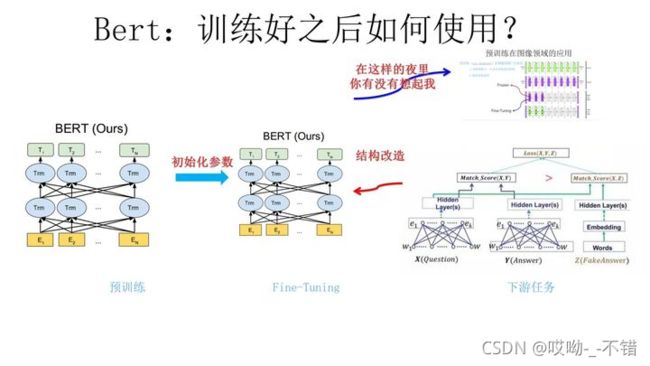
第二阶段,Fine-Tuning阶段,这个阶段的做法和GPT是一样的。当然,它也面临着下游任务网络结构改造的问题,在改造任务方面Bert和GPT有些不同。

在介绍Bert如何改造下游任务之前,先大致说下NLP的几类问题,说这个是为了强调Bert的普适性有多强。通常而言,绝大部分NLP问题可以归入上图所示的四类任务中:
- 第一类是序列标注,这是最典型的NLP任务,比如中文分词,词性标注,命名实体识别,语义角色标注等都可以归入这一类问题,它的特点是句子中每个单词要求模型根据上下文都要给出一个分类类别。
- 第二类是分类任务,比如我们常见的文本分类,情感计算等都可以归入这一类。它的特点是不管文章有多长,总体给出一个分类类别即可。
- 第三类任务是句子关系判断,比如Entailment,QA,语义改写,自然语言推理等任务都是这个模式,它的特点是给定两个句子,模型判断出两个句子是否具备某种语义关系;
- 第四类是生成式任务,比如机器翻译,文本摘要,写诗造句,看图说话等都属于这一类。它的特点是输入文本内容后,需要自主生成另外一段文字。

对于种类如此繁多而且各具特点的下游NLP任务,Bert如何改造输入输出部分使得大部分NLP任务都可以使用Bert预训练好的模型参数呢?上图给出示例:
- 对于句子关系类任务,很简单,和GPT类似,加上一个起始和终结符号,句子之间加个分隔符即可。对于输出来说,把第一个起始符号对应的Transformer最后一层位置上面串接一个softmax分类层即可。
- 对于分类问题,与GPT一样,只需要增加起始和终结符号,输出部分和句子关系判断任务类似改造;
- 对于序列标注问题,输入部分和单句分类是一样的,只需要输出部分Transformer最后一层每个单词对应位置都进行分类即可。
从这里可以看出,上面列出的NLP四大任务里面,除了生成类任务外,Bert其它都覆盖到了,而且改造起来很简单直观。尽管Bert论文没有提,但是稍微动动脑子就可以想到,其实对于机器翻译或者文本摘要,聊天机器人这种生成式任务,同样可以稍作改造即可引入Bert的预训练成果。只需要附着在seq2seq结构上,encoder部分是个深度Transformer结构,decoder部分也是个深度Transformer结构。根据任务选择不同的预训练数据初始化encoder和decoder即可。这是相当直观的一种改造方法。当然,也可以更简单一点,比如直接在单个Transformer结构上加装隐层产生输出也是可以的。不论如何,从这里可以看出,NLP四大类任务都可以比较方便地改造成Bert能够接受的方式。这其实是Bert的非常大的优点,这意味着它几乎可以做任何NLP的下游任务,具备普适性,这是很强的。
四、总结

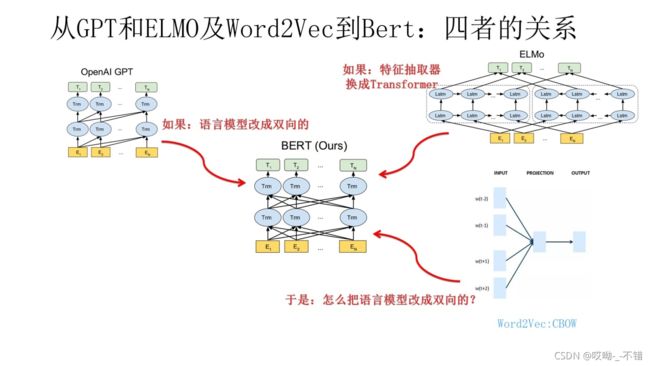
从上图可见,Bert其实和ELMO及GPT存在千丝万缕的关系,比如:如果我们把GPT预训练阶段换成双向语言模型,那么就得到了Bert;而如果我们把ELMO的特征抽取器换成Transformer,那么我们也会得到Bert。所以你可以看出:Bert最关键两点,一点是特征抽取器采用Transformer;第二点是预训练的时候采用双向语言模型。
那么新问题来了:对于Transformer来说,怎么才能在这个结构上做双向语言模型任务呢?乍一看上去好像不太好搞。我觉得吧,其实有一种很直观的思路,怎么办?看看ELMO的网络结构图,只需要把两个LSTM替换成两个Transformer,一个负责正向,一个负责反向特征提取,其实应该就可以。当然这是我自己的改造,Bert没这么做。那么Bert是怎么做的呢?我们前面不是提过Word2Vec吗?我前面肯定不是漫无目的地提到它,提它是为了在这里引出那个CBOW训练方法,所谓写作时候埋伏笔的“草蛇灰线,伏脉千里”,大概就是这个意思吧?前面提到了CBOW方法,它的核心思想是:在做语言模型任务的时候,我把要预测的单词抠掉,然后根据它的上文Context-Before和下文Context-after去预测单词。其实Bert怎么做的?Bert就是这么做的。从这里可以看到方法间的继承关系。
Bert模型使用了双向Transformer;GPT采用了从左到右的Transformer;ELMo只是将单独训练的从左到右与从右到左的LSTM模型的特征进行拼接,并没有在内部进行融合;Bert模型融合了所有层从左到右与从右到左的信息。
经验:拿到word embedding,如果想在上面接很多层的话,用ELMo的效果比Bert效果好;如果想在上面接一些简单的层的话,用Bert的效果比ELMo的效果好。
参考:
- 语言模型ELMO
- 从Word Embedding到Bert模型