文本情感分类TextCNN原理+IMDB数据集实战

1.任务背景
情感分类:

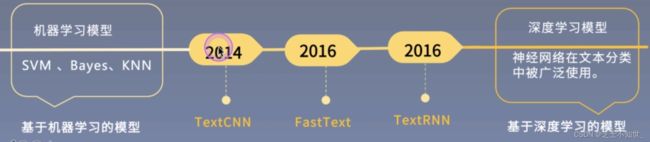
发展历程:
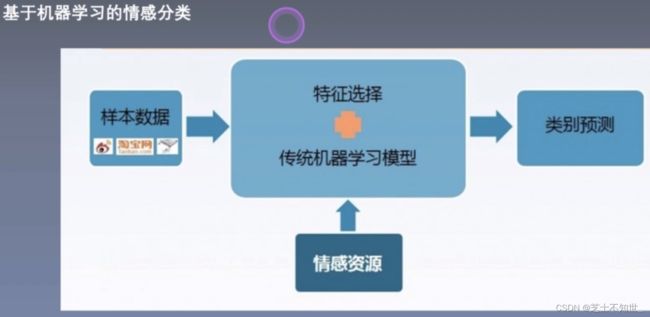

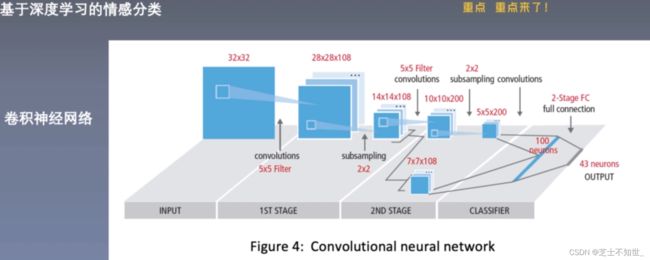

2.数据集
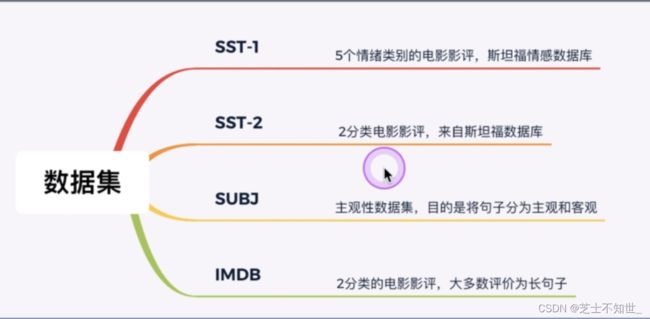
本次使用IMDB数据集进行训练。
3.模型结构


3.1 CNN基础
卷积:

单通道卷积:每组卷积核只包含一个。
单通道输入 单输出:设置一组卷积核。
单通道输入 多输出:设置多组卷积核。

RGB三通道卷积:每组卷积核只包含三个。
三通道输入 单输出:设置一组卷积核。
三通道输入 多输出:设置多组卷积核。
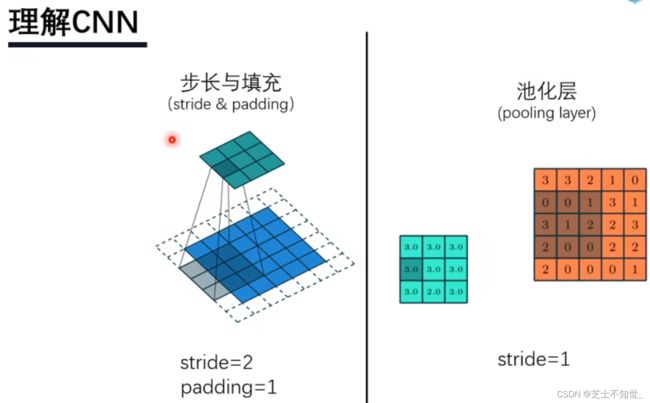
步长、池化:
全连接层: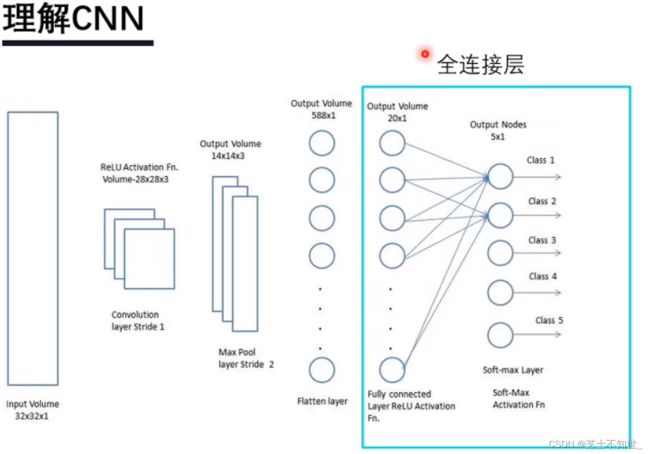
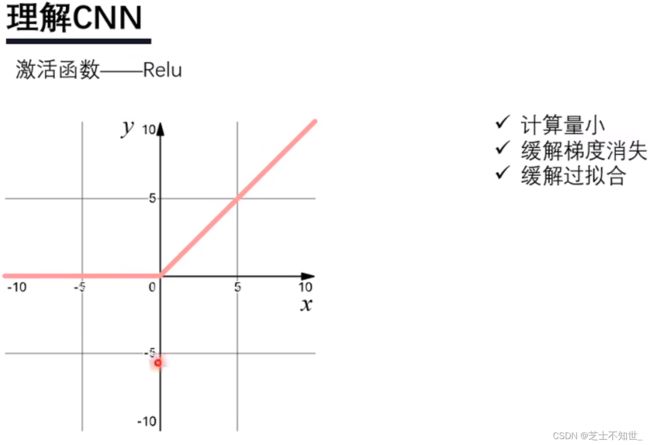
激活函数:
3.2 Text基础
字向量、词向量:
字向量——多用于古诗生成
词向量——多用于翻译、生成小说、文本分类

语料库:
word2index:先要做分词,语料库找出唯一不重复的词语,再给它分配一个唯一的id。
index2word:word2index反过来。
word2onehot:onehot编码。


预处理:
- 固定句子长度(超过截断、缺少补0).
- 构建词表、给每个word设置索引.
- embedding 将每个词训练转化为词向量.

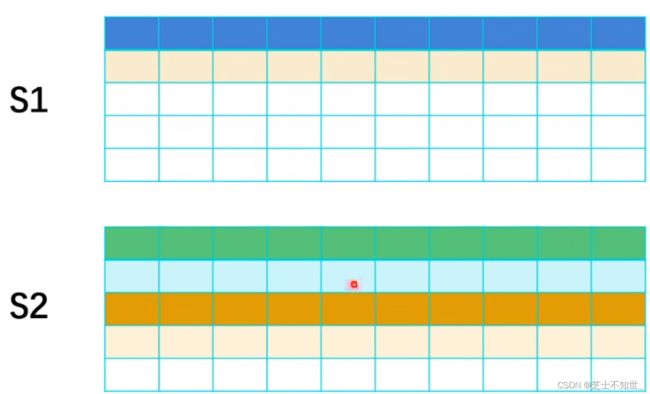
3.3 TextCNN

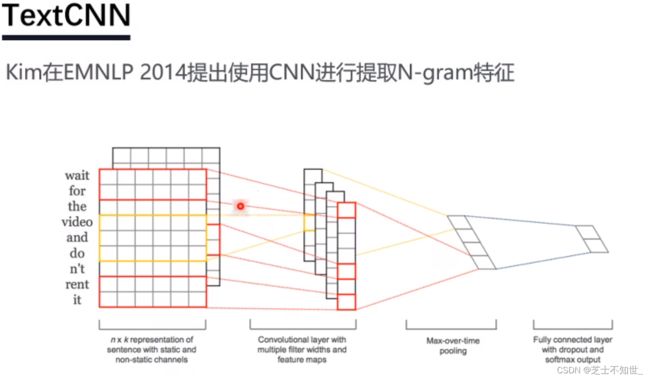

- 输入层:输入表示的是一句话或者一段文字,文字不像图片、语音信号,不是天然的数值类型,需要将一句话处理成数字之后,才能作为神经网络的输入。每个词使用一个向量进行表示,这个向量称为词向量。每一句话可以表示成一个二维的矩阵,如上图,“I like this movie very much!”,先对这句话进行分词,得到7个词(此处包括!),倘若每个词的词向量的维度d=5,则这句话可以表示成一个7x5的矩阵。需要注意的是,神经网络的结构输入的shape是固定的,但是每一篇评论的长度是不固定的,所以我们要固定神经网络输入的词数量。比如人为设定一篇评论的最大词数量sentence_max_size=300,d=5,则输入为300x5。对超过300词的评论进行截断,不足300词的进行padding,补0
- 卷积层:图像的卷积核一般为正方形,而NLP中的卷积核一般为矩形。对于一个7x5的input,卷积核的宽度width=词向量的大小,长度的取值按需选取。因为词向量长度=5,三组卷积核(每组2个卷积核,分别为4x5,3x5,2x5)纵向维度均=5,这样只需要卷积核向下滑动即可实现卷积。卷积完成后,每个卷积核 都会得到 两个特征图(3组,6个特征图,分别为3x1,4x1,5x1)。
- 池化层:将6个特征图进行Maxpooling后,拼接在一起,组成一个6x1的特征图。
- 全连接层:在经过一个softmax,求得情感2分类概率分布。
4.代码训练
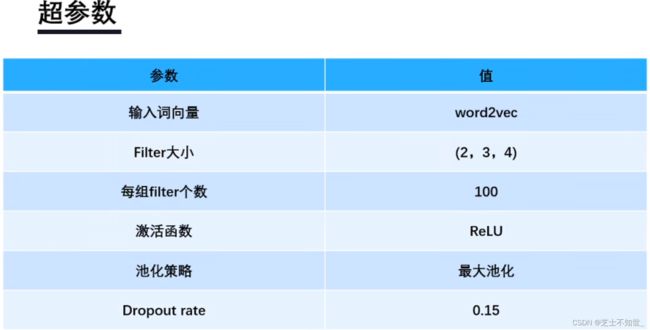
baseline超参数:
4.1数据预处理
下载IMDB数据集
下载glove的300维的词向量模型

4.1.1扫描数据集文件
get_file_list(source_dir):扫描文件夹source_dir下的所有文件,并将该文件夹下 所有文件的路径名 保存在file_list中
get_label_list(file_list):根据file_list,从文件路径名中提取出文件对应的label
def get_file_list(source_dir):
file_list = [] # 文件路径名列表
# os.walk()遍历给定目录下的所有子目录,每个walk是三元组(root,dirs,files)
# root 所指的是当前正在遍历的这个文件夹的本身的地址
# dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
# files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
# 遍历所有评论
for root, dirs, files in os.walk(source_dir):
file = [os.path.join(root, filename) for filename in files]
file_list.extend(file)
return file_list
def get_label_list(file_list):
# 提取出标签名
label_name_list = [file.split("\\")[4] for file in file_list]
# 标签名对应的数字
label_list = []
for label_name in label_name_list:
if label_name == "neg":
label_list.append(0)
elif label_name == "pos":
label_list.append(1)
return label_list
4.1.2载入预训练的词向量模型
获得gensim可用的glove词向量模型
- 可以使用google或者glove训练好的词向量模型,本文使用glove的300维的词向量模型,下载地址:glove vectors
- 但是下载的glove词向量模型,gensim不能拿来直接使用,运行以下代码得到文件glove.model.6B.300d.txt,该文件可供gensim直接使用
import gensim
import shutil
from sys import platform
# 计算行数,就是单词数
def getFileLineNums(filename):
f = open(filename, 'r', encoding="utf8")
count = 0
for line in f:
count += 1
return count
# Linux或者Windows下打开词向量文件,在开始增加一行
def prepend_line(infile, outfile, line):
with open(infile, 'r', encoding="utf8") as old:
with open(outfile, 'w', encoding="utf8") as new:
new.write(str(line) + "\n")
shutil.copyfileobj(old, new)
def prepend_slow(infile, outfile, line):
with open(infile, 'r', encoding="utf8") as fin:
with open(outfile, 'w', encoding="utf8") as fout:
fout.write(line + "\n")
for line in fin:
fout.write(line)
def load(filename):
num_lines = getFileLineNums(filename)
gensim_file = 'E:/data_source/glove.6B/glove.model.6B.300d.txt'
gensim_first_line = "{} {}".format(num_lines, 200)
# Prepends the line.
if platform == "linux" or platform == "linux2":
prepend_line(filename, gensim_file, gensim_first_line)
else:
prepend_slow(filename, gensim_file, gensim_first_line)
model = gensim.models.KeyedVectors.load_word2vec_format(gensim_file)
load('E:/data_source/glove.6B/glove.6B.300d.txt')
加载预训练的词向量
wv.index2word:包含了词向量模型中所有的词
wv.vectors:包含了词向量模型中所有词的词向量
embedding对象:将wv.vectors中的词向量表示成Tensor
其中wv.index2word与wv.vectors(embedding.weight)相同位置的word与vector是一一对应的,为了从embedding.weight中获得word的vector,需要得到word在的index2word中的index,所以需要使用字典word2id 将其保存起来
word2vec_dir="glove.6B.300d.txt"# 训练好的词向量文件
# 加载词向量模型
wv = KeyedVectors.load_word2vec_format(datapath(word2vec_dir), binary=False)
word2id = {} # word2id是一个字典,存储{word:id}的映射
for i, word in enumerate(wv.index2word):
word2id[word] = i
# 根据已经训练好的词向量模型,生成Embedding对象
embedding = nn.Embedding.from_pretrained(torch.FloatTensor(wv.vectors))
4.1.3生成训练集与测试集
根据评论内容生成tensor
sentence是一个list,对输入的一篇评论的内容进行分词,过滤停用词之后,便得到sentence
根据sentence,得到一篇评论的Tensor表示,需要注意的是:我们定义的神经网络的输入是四维的[batch_size,channel,sentence_max_size,vec_dim],第一维是批大小,第二维是通道数,这里输入通道均为1,第三维是词数量,第四维是词向量的维度
def generate_tensor(sentence, sentence_max_size, embedding, word2id):
"""
对一篇评论生成对应的词向量矩阵
:param sentence:一篇评论的分词列表
:param sentence_max_size:认为设定的一篇评论的最大分词数量
:param embedding:词向量对象
:param word2id:字典{word:id}
:return:一篇评论的词向量矩阵
"""
tensor = torch.zeros([sentence_max_size, embedding.embedding_dim])
for index in range(0, sentence_max_size):
if index >= len(sentence):
break
else:
word = sentence[index]
if word in word2id:
vector = embedding.weight[word2id[word]]
tensor[index] = vector
elif word.lower() in word2id:
vector = embedding.weight[word2id[word.lower()]]
tensor[index] = vector
return tensor.unsqueeze(0) # tensor是二维的,必须扩充为三维,否则会报错
4.2实现Dataset、生成Dataloader
训练集保存在一个个小文件中,对于小数据集来说,一次性将所有数据读入内存勉强可行,但对于大数据集则是不可行的。此时,通过继承Dataset来实现自己的MyDataset,主要重写以下几个方法(方法名前后均有两道下划线,显示不出):
- init(self, file_list, label_list, sentence_max_size, embedding, word2id, stopwords):初始化参数
- getitem(self, index):MyDataset的实现原理就是通过遍历file_list,得到每一个文件路径名,根据路径名,将其内容读到内存中,通过generate_tensor()函数将文件内容转化为tensor,函数返回tensor与对应的label,其中index就是list的下标
- len(self):返回list的长度
class MyDataset(Dataset):
def __init__(self, file_list, label_list, sentence_max_size, embedding, word2id, stopwords):
self.x = file_list
self.y = label_list
self.sentence_max_size = sentence_max_size
self.embedding = embedding
self.word2id = word2id
self.stopwords = stopwords
def __getitem__(self, index):
# 读取评论内容
words = []
with open(self.x[index], "r", encoding="utf8") as file:
for line in file.readlines():
words.extend(segment(line.strip(), stopwords))
# 生成评论的词向量矩阵
tensor = generate_tensor(words, self.sentence_max_size, self.embedding, self.word2id)
return tensor, self.y[index]
def __len__(self):
return len(self.x)
get_file_list()与get_label_list()函数详见2.2
Dataloader是个可遍历的对象,batch_size表示批大小,shuffle表示是否打乱数据
# 获取训练数据
logging.info("获取训练数据")
train_set = get_file_list(train_dir)
train_label = get_label_list(train_set)
train_dataset = MyDataset(train_set, train_label, sentence_max_size, embedding, word2id, stopwords)
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 获取测试数据
logging.info("获取测试数据")
test_set = get_file_list(test_dir)
test_label = get_label_list(test_set)
test_dataset = MyDataset(test_set, test_label, sentence_max_size, embedding, word2id, stopwords)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True)
4.3定义TextCNN模型
class TextCNN(nn.Module):
def __init__(self, vec_dim, filter_num, sentence_max_size, label_size, kernel_list):
"""
:param vec_dim: 词向量的维度
:param filter_num: 每种卷积核的个数
:param sentence_max_size:一篇文章的包含的最大的词数量
:param label_size:标签个数,全连接层输出的神经元数量=标签个数
:param kernel_list:卷积核列表
"""
super(TextCNN, self).__init__()
chanel_num = 1
# nn.ModuleList相当于一个卷积的列表,相当于一个list
# nn.Conv1d()是一维卷积。in_channels:词向量的维度, out_channels:输出通道数
# nn.MaxPool1d()是最大池化,此处对每一个向量取最大值,所有kernel_size为卷积操作之后的向量维度
self.convs = nn.ModuleList([nn.Sequential(
nn.Conv2d(chanel_num, filter_num, (kernel, vec_dim)),
nn.ReLU(),
# 经过卷积之后,得到一个维度为sentence_max_size - kernel + 1的一维向量
nn.MaxPool2d((sentence_max_size - kernel + 1, 1))
)
for kernel in kernel_list])
# 全连接层,因为有2个标签
self.fc = nn.Linear(filter_num * len(kernel_list), label_size)
# dropout操作,防止过拟合
self.dropout = nn.Dropout(0.5)
# 分类
self.sm = nn.Softmax(0)
def forward(self, x):
# Conv2d的输入是个四维的tensor,每一位分别代表batch_size、channel、length、width
in_size = x.size(0) # x.size(0),表示的是输入x的batch_size
out = [conv(x) for conv in self.convs]
out = torch.cat(out, dim=1)
out = out.view(in_size, -1) # 设经过max pooling之后,有output_num个数,将out变成(batch_size,output_num),-1表示自适应
out = F.dropout(out)
out = self.fc(out) # nn.Linear接收的参数类型是二维的tensor(batch_size,output_num),一批有多少数据,就有多少行
return out
4.4训练测试脚本
train_loader就是一个Dataloader对象,是个可遍历对象。迭代次数为epoch,每训练一批数据则输出该批数据的平均loss
可以下载我已经训练好模型进行测试:链接:https://pan.baidu.com/s/1Gxu9Wt0lTcTNUsZlg0dLyQ 提取码:8fd8
复制这段内容后打开百度网盘手机App,操作更方便哦
def train_textcnn_model(net, train_loader, epoch, lr):
print("begin training")
net.train() # 必备,将模型设置为训练模式
optimizer = optim.Adam(net.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
for i in range(epoch): # 多批次循环
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad() # 清除所有优化的梯度
output = net(data) # 传入数据并前向传播获取输出
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 打印状态信息
logging.info("train epoch=" + str(i) + ",batch_id=" + str(batch_idx) + ",loss=" + str(loss.item() / 64))
print('Finished Training')
test_loader也是一个Dataloader对象,累计每个batch的正确个数,并且每个batch都计算一次当前的accuracy
最终在测试集上的预测正确率为84%
def textcnn_model_test(net, test_loader):
net.eval() # 必备,将模型设置为训练模式
correct = 0
total = 0
test_acc = 0.0
with torch.no_grad():
for i, (data, label) in enumerate(test_loader):
logging.info("test batch_id=" + str(i))
outputs = net(data)
# torch.max()[0]表示最大值的值,troch.max()[1]表示回最大值的每个索引
_, predicted = torch.max(outputs.data, 1) # 每个output是一行n列的数据,取一行中最大的值
total += label.size(0)
correct += (predicted == label).sum().item()
print('Accuracy of the network on test set: %d %%' % (100 * correct / total))