C语言中指针的介绍(终极版!!!)
文章目录
- 指针
-
- 一:指针是什么?
-
- 1:内存
- 2:地址的生成
- 3:数据的储存
- 4:指针变量
-
- (1):指针变量的大小
- (2):如何一口气定义好几个指针变量?
- 二:指针与指针类型
-
- 1:指针+-整数
- 2.指针的解引用
- 三:野指针
-
- 1:野指针成因
-
- (1) 指针未初始化
- (2)指针越界访问
- (3) 指针指向的空间释放
- 2:如何规避野指针
- 四:指针的运算
-
- 1:指针+-整数
- 2:指针-指针
- 3:指针的关系运算
- 五:指针和数组
- 六:二级指针
- 七:字符指针
-
- 1:使用方式
- 2:笔试题
- 八:指针数组
- 九:数组指针
-
- 1:数组指针的定义
- 2:&数组名和数组名
- 3:数组指针的使用
- 十:数组与指针的传参
-
- 1:一维数组传参
- 2:二维数组传参
- 3:一级指针传参
- 4:二级指针传参
- 十一:函数指针
-
- 1:函数指针的介绍
- 2:用函数指针实现一个计算器程序
- 十二:函数指针数组
-
- 1:函数指针的定义
- 十三:指向函数指针数组的指针
- 十四:回调函数
-
- 1:qsort函数
- 2:利用冒泡排序思想模拟实现qsort函数
指针
一:指针是什么?
指针是什么?
指针理解的2个要点:
- 指针是内存中一个最小单元的编号,也就是地址
- 平时口语中说的指针,通常指的是指针变量,是用来存放内存地址的变量
总结:指针就是地址,口语中说的指针通常指的是指针变量。
1:内存
程序的运行需要内存,我们为了有效地使用内存,就需要将内存划分为一个个小的内存单元,每一个单元的大小是一个字节。(一个字节比较合理,这个内存单元太小也不好,太大也不好)为了 能够有效地使用每个内存单元,我们给每一个单元都定了一个编号,这个编号就叫做这个内存单元的地址。
就像在我们的生活中,比如说你在网上购物。你就一定需要告诉商家,你自己的确切位置,比如说xx市xx区xx路xx号(几号楼)几号宿舍。)这个内存的地址也是这个道理,就像楼中的门牌号,通过编号的方式,内存的单元地址也就确定了。我们可以轻松地找到对应的地址,而不需要一个一个去找。
2:地址的生成
我们的电脑中都有硬件电路,用于生成地址的电线叫地址线。当电路中有电路通过时,会产生正负脉冲,从而表示0与1.此处我们以32位电脑为例,它在生成地址时32根地址线同时产生电信号表示1或0,当每一个地址线组合起来时就有了许许多多的不同的排列组合方式。
00000000000000000000000000000000——对应0
00000000000000000000000000000001——对应1
…
1111111111111111111111111111111111111——最终可能会变成32个1
这样的排序方式一共有2^32次方种 内存中一共有这么多byte的空间。
(1024B=1KB 1024KB=1MB 1024MB=1GB) (1byte=8bit)
但是这个数字不是很直观,我们先对它除以1024得到4194304个KB,再除1024得到4096个MB,再除以1024得到4GB,也就是说在早期的三十二位电脑内存中一共有4GB的内存空间。
3:数据的储存
变量是创建内存中的(在内存分配空间的),每个单元都有地址,所以变量也有地址
利用&:
&:取地址操作符,取出谁的地址。
打印地址,%p是以地址的形式打印
#include 打印出来后 通过调试F10 内存 监视窗口得到此图

我们实际上取出的只有0x010FF808这个地址(起始位置的地址)
0a 00 00 00一行显示了四个字节 (设置了四列)
a的值为10,用二进制表示即为:0000 0000 0000 0000 0000 0000 0000 1010(二进制的数字表达最后一位表示2的0次方,倒数第二位就表示2的1次方,以此类推,十就是2的3次方加2的一次方也就是1010),在这个时候我们以每个四位为一组,就可以得到数据的表示方法:00 00 00 0a(在16进制数中,a表示10,b表示11,c表示12,d表示13,e表示14,f表示15)
** 0000 0000 0000 0000 0000 0000 0000 1010
0 0 0 0 0 0 0 a**
其实十进制的储存方式是这样的
0x 00 00 00 0a 倒着存
4:指针变量
#include在内存单元中:
1:编号就是地址 而地址就是指针
2:当a创建好后,占用了4个字节,每个字节都有一个地址,&a拿到的是第一个字节的地址
对int* pa =&a;的理解
1.pa代表0x010FF808这个起始位置的地址
2.中间的*表示p是个指针变量,注意指针变量是pa,而不是*pa
3.int说明pa指向的对象是int类型的(本例子说明pa指向的是a)
4.pa为指针变量,接受&a的内容,(即应该将地址存到指针变量中去)也就是变量的首地址
5.int*整体是一个整型指针类型

创建变量的本质:
向内存申请了空间。有了内存空间之后,每个变量都有了属于自己的地址。
(1):指针变量的大小
%zu表示打印sizeof
#include 你可能认为输出结果是:1 2 4 4 8
但实际上是:4\8 4\8 4\8 4\8 4\8 (4或8)
因为:
指针变量储存的是地址,也就是说指针变量的大小取决于存放一个地址需要多大的空间,32位平台下地址是32个bit位(即4个字节),而64位平台下地址是64个bit位(即8个字节),所以指针变量的大小就是4或8.
结论:
32位环境下,地址的序列就由32个0/1组成的二进制序列,要存储进来,需要4个字节。
64位环境下,地址的序列就由64个0/1组成的二进制序列,要存储进来,需要8个字节。
(2):如何一口气定义好几个指针变量?
int main()
{
int* p1,p2,p3 = &a;
//这个定义方式是不正确的,
//只有p1是指针变量而其他两个是整型变量
int* p1,*p2,*p3;
//这个定义方法才是正确的,
//在第一种方法下,*只给第一个变量使用
return 0;
}
二:指针与指针类型
这里我们在讨论一下:指针的类型
我们都知道,变量有不同的类型,整形,浮点型等。那指针有没有类型呢?
准确的说:有的。
当有这样的代码:
int num = 10;
p = #
要将&num(num的地址)保存到p中,我们知道p就是一个指针变量,那它的类型是怎样的呢?
我们给指针变量相应的类型。
char *pc = NULL;
int *pi = NULL;
short *ps = NULL;
long *pl = NULL;
float *pf = NULL;
double *pd = NULL;
这里可以看到,指针的定义方式是: type + * 。
其实:
char* 类型的指针是为了存放 char 类型变量的地址。
short* 类型的指针是为了存放 short 类型变量的地址。
int* 类型的指针是为了存放 int 类型变量的地址。
那指针类型的意义是什么?
1:指针+-整数
#include 打印1~10
//用指针打印1~10
#include总结:
1:无论我们打印&n,还是指针变量pc还是pi,它们的结果都是一样的。
2:(当我们观察pc+1与pi+1的时候发现两者结果并不相同)
+1表示跳过一个数据类型(char、int、double…)
指针的类型决定了,对指针解引用的时候有多大的权限(能操作几个字节)。
比如: char* 的指针解引用就只能访问1个字节,而 int* 的指针的解引用就能访问4个字节,double*的指针的解引用就能访问8个字节
3:指针类型决定了指针的步长(向前/向后,走n步有多大距离)
比如:
char*+1,意思是跳过一个字符,也就是向后走了1个字节
short*+1,意思是跳过一个短整型,也就是向后走了2个字节
int*+1,意思是跳过一个整型,也就是向后走了4个字节
double*+1,意思是跳过一个double,也就是向后走了8个字节
2.指针的解引用
#include 在内存中,0x11223344这个数字以小端字节序存储(44 33 22 11),先用char* 的指针解引用只能访问一个字节,所以会把第一个字节改为0,也就会打印11223300;而 int* 的指针解引用能访问四个字节,所以会把第四个字节都改为0,也就会打印0
总结:
指针的类型决定了,对指针解引用的时候有多大的权限(能操作几个字节)。
三:野指针
概念: 野指针就是指针指向的位置是不可知的(随机的、不正确的、没有明确限制的)
对于野指针,我们形象的可以把它比喻成野狗,接近它会受伤。
1:野指针成因
(1) 指针未初始化
#include (2)指针越界访问
用个代码来演示一下
#include 用图来解释的话:
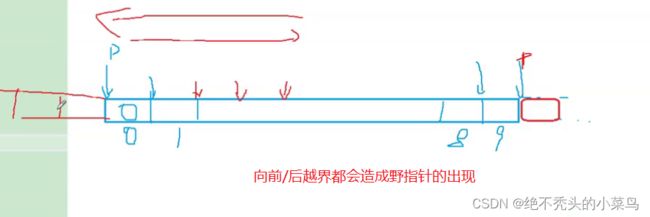
图中表面 向后访问 当i=10的时候 p++会访问红色区域(即越界),向前访问也类似这种情况
(3) 指针指向的空间释放
int* test()
{
int num = 100;
return #
//num是局部变量,
//其生命周期是从test函数进入开始到出test函数
//出函数后,num这块空间需要还给我们的操作系统
//返回后这块空间已经被释放,
//不属于我们了(这个空间已经不在程序的作用域内)
}
int main()
{
int* p = test();
*p = 200;
//但是当我们回到主函数里面去的时候,p记住了这块空间的地址
//p有能力能够找到这块空间,但地址不属于我们了(非法访问)
//这个时候p就为野指针
//我们无法确定是否会有其他的操作会改变它的值
return 0;
}
形象的理解方式就是:
假设张三2天住进了一个酒店,订了302号房间,2天后他退房,可这个时候他记得当时他来的酒店住的房间是302,他硬要住302号房间,结果却发现不能住进去了。
这里放在动态内存开辟的时候讲解,这里可以简单提示一下。
2:如何规避野指针
- 指针初始化
- 小心指针越界
- 指针指向空间释放即使置NULL
- 避免返回局部变量的地址(准确来说是避免返回
栈空间的地址) - 指针使用之前检查有效性
#include 四:指针的运算
1:指针±整数
#include指针加减整数可以让地址向后或向前移动对应的字节数。
2:指针-指针
注:指针+指针是无意义的
#include3:指针的关系运算
for(vp = &values[N_VALUES]; vp > &values[0];)
{
*--vp = 0;
}
//
for(vp = &values[N_VALUES-1]; vp >= &values[0];vp--) {
*vp = 0; }
实际在绝大部分的编译器上是可以顺利完成任务的,然而我们还是应该避免这样写,因为标准并不保证它可行
标准规定:
允许指向数组元素的指针与指向数组最后一个元素后面的那个内存位置的指针比较,但是不允许与指向第一个元素之前的那个内存位置的指针进行比较。
五:指针和数组
区别:
数组和指针不是一个东西。
数组是能够存放一组数,连续的空间,数组的大小取决于元素个数
指针是一个变量,是存放地址的,大小为4/8个字节。
相同点:
数组名就是地址(指针)
数组把首元素的地址,交给一个指针变量后,可以通过指针来访问数组。
#include 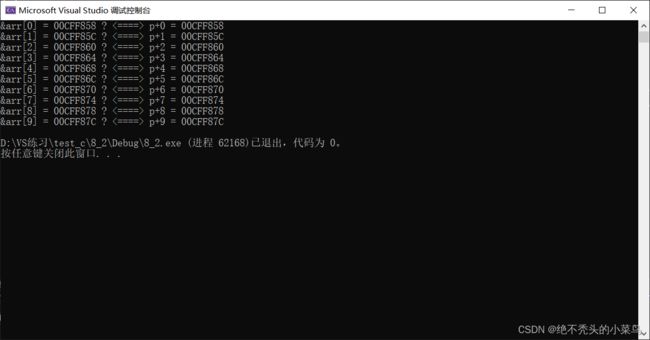
六:二级指针
指针变量也是变量,是变量就有地址,那指针变量的地址就可以储存在二级指针内
二级指针解引用需要两次才能找到变量
#include七:字符指针
在指针的类型中我们知道有一种指针类型为字符指针 char* ;
1:使用方式
#include2:笔试题
#include 这两个语句比较的都是地址
数组储存在栈区,
每创建一个新的数组都需要占用内存空间存储,所以两个地址不同;
字符串常量储存在静态区,
不需要储存多个这样的字符串,所以两个指针变量都指向了同一个地址。
如果要比较字符串的内容
可以利用strcmp函数
八:指针数组
指针数组是指针还是数组?
答案:是数组。是存放指针的数组。
数组我们已经知道整形数组,字符数组。
#include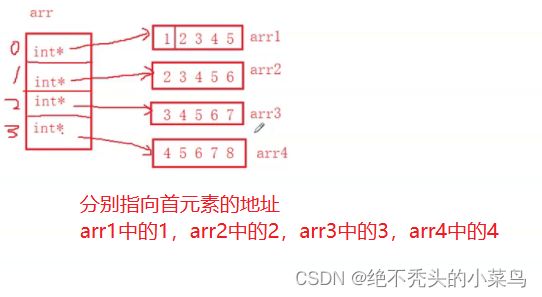
九:数组指针
1:数组指针的定义
数组指针是指针?还是数组?
答案是:指针。
我们已经熟悉:
整形指针: int * pint; 能够指向整形数据的指针。
浮点型指针: float * pf; 能够指向浮点型数据的指针。
那数组指针应该是:能够指向数组的指针。
#include2:&数组名和数组名
//数组名是首元素的地址,但有两个例外
//1:sizeof(数组名)
//2:&数组名
#include根据上面的代码我们发现,其实&arr和arr,虽然值是一样的,但是意义应该不一样的。
arr是数组名,数组名其实是数组首元素的地址,arr就是&arr[0],首元素的地址用*来接收
实际上: &arr 表示的是数组的地址,而不是数组首元素的地址。
本例中 &arr 的类型是: int(*)[10] ,是一种数组指针类型
数组的地址+1,跳过整个数组的大小(刚好跳到整个数组中越界处),所以 &arr+1 相对于 &arr 的差值是40
3:数组指针的使用
#include学了指针数组和数组指针我们来一起回顾并看看下面代码的意思
#include十:数组与指针的传参
1:一维数组传参
#include 2:二维数组传参
void test(int arr[3][5])//ok
{}
void test(int arr[][])//err
{}
void test(int arr[][5])//ok
{}
//总结:二维数组传参,函数形参的设计只能省略第一个[]的数字。
//因为对一个二维数组,可以不知道有多少,
//但是必须知道一行多少元素才方便运算。
//二维数组的首元素地址是一维数组第1行的地址
void test(int* arr)//这是一个整型指针,不符合
{}
void test(int* arr[5])//这是一个整型指针数组,不符合
{}
void test(int(*arr)[5])//这是一个整型数组指针,符合
{}
void test(int** arr)//这是一个二级指针,(接收一级指针变量的地址),不符合
{}
int main()
{
int arr[3][5] = { 0 };
test(arr);
//arr为二维数组的数组名,数组名表示首元素的地址,
//所以arr就是二维数组里第一行的地址
return 0;
}
3:一级指针传参
#include 思考:
当一个函数的参数部分为一级指针的时候,函数能接收什么参数?
void test1(int *p)
{
//test1函数能接收什么参数?
int a = 0;
test1(&a);//ok
int* ptr = &a;
test1(ptr);//ok
int arr[10];
test1(arr);//ok
}
void test2(char* p)
{
//test2函数能接收什么参数?
//同上
}
4:二级指针传参
#include 十一:函数指针
1:函数指针的介绍
#include#include输出的是两个地址,这两个地址是Add 函数的地址。
那我们的函数的地址要想保存起来,怎么保存?
下面我们看代码:
void test()
{
printf("hehe\n");
}
//下面pfun1和pfun2哪个有能力存放test函数的地址?
void (*pfun1)();
void *pfun2();
首先,能给存储地址,就要求pfun1或者pfun2是指针,那哪个是指针?
答案是:
pfun1可以存放。pfun1先和*结合,说明pfun1是指针,指针指向的是一个函数,指向的函数无参数,返回值类型为void
阅读两段有趣的代码:
#include2:用函数指针实现一个计算器程序
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void menu()
{
printf("***************************\n");
printf("***** 1.add 2. sub ****\n");
printf("***** 3.mul 4. div ****\n");
printf("***** 0.exit ****\n");
printf("***************************\n");
}
int main()
{
int input = 0;
int x = 0;
int y = 0;
int ret = 0;
do
{
menu();
printf("请选择:>");
scanf("%d", &input);
switch (input)
{
case 1:
printf("请输入2个操作数:>");
scanf("%d %d", &x, &y);//防止在计算器里面输错数字
ret = Add(x, y);
printf("%d\n", ret);
break;
case 2:
printf("请输入2个操作数:>");
scanf("%d %d", &x, &y);
ret = Sub(x, y);
printf("%d\n", ret);
break;
case 3:
printf("请输入2个操作数:>");
scanf("%d %d", &x, &y);
ret = Mul(x, y);
printf("%d\n", ret);
break;
case 4:
printf("请输入2个操作数:>");
scanf("%d %d", &x, &y);
ret = Div(x, y);
printf("%d\n", ret);
break;
case 0:
printf("退出计算器\n");
break;
default:
printf("选择错误\n");
break;
}
} while (input);
}
//简化一下代码
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void menu()
{
printf("***************************\n");
printf("***** 1.add 2. sub ****\n");
printf("***** 3.mul 4. div ****\n");
printf("***** 0.exit ****\n");
printf("***************************\n");
}
int main()
{
int input = 0;
int x = 0;
int y = 0;
int ret = 0;
//前面的scanf输入input的地址,有4种情况
//为了简化,先把这几个函数的地址存起来,得用到函数指针
//函数指针数组 - 转移表
int (*pfArr[])(int, int) = { 0, Add, Sub, Mul, Div };
//首元素故意放0的原因是数组下标与菜单对应
do
{
menu();
printf("请选择:>");
scanf("%d", &input);
//防止输入0的时候依然进入程序有效计算
if (input == 0)
{
printf("退出计算器\n");
break;
}
if (input >= 1 && input <= 4)
{
printf("请输入2个操作数:>");
scanf("%d %d", &x, &y);
ret = pfArr[input](x, y);
printf("%d\n", ret);
}
else
{
printf("选择错误\n");
}
} while (input);
}
//又或者
#include十二:函数指针数组
1:函数指针的定义
函数指针数组是存储函数指针的数组
它可以存放多个参数相同,返回类型相同 的函数地址
#include十三:指向函数指针数组的指针
void test(const char* str)
{
printf("%s\n", str);
}
int main()
{
//函数指针pfun
void (*pfun)(const char*) = test;
//函数指针数组pfunArr
void (*pfunArr[5])(const char* str);
pfunArr[0] = test;
//指向函数指针数组pfunArr的指针ppfunArr
void (*(*ppfunArr)[5])(const char*) = &pfunArr;
return 0;
}
十四:回调函数
回调函数就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
1:qsort函数

- qsort的头文件是
。 - qsort一共有四个参数,需要排序元素的首地址(void*),需要排序元素的个数(size_t),需要排序元素的大小(size_t)单位是字节,用于定义判定大小方式的compare函数,也就是回调函数的使用。
- qsort不返回任何值。
- compare函数需要满足参数为void*的指针,两个元素相减的结果为正数,前大于后;两个元素相减的结果为负数,后大于前;两个元素相减的结果为零,二者相等。(上述的结果为返回值)
- qsort函数可以排序任何类型的数据且默认排升序。
- void*指针能接收任意类型的地址(但void指针不能直接解引用)
#include#include2:利用冒泡排序思想模拟实现qsort函数
#include