YCSB初步介绍
随着大数据时代的到来和云计算的不断发展,作为云计算最基础的设施存储产品也越来越多,开源分布式存储系统有BigTable-like系统HBase,dynamo-like系统Cassandra,voldemort,Riak,淘宝开源的OceanBase等。当然还有一些未开源系统如Yahoo! 的PNUTS,Google的BigTable等。没有一种系统能够在所有的workload下都是最合适的。
各个系统都会作出一些tradeoff来最大化的适应目标应用的workload。所以这就产生了一个问题,应用开发中在进行存储系统选型的时候,哪个系统最合适?
Yahoo! Cloud Serving Benchmark (YCSB) 是一个用来测试在线数据库性能,扩展性的框架,Java语言实现的,下载地址在https://github.com/brianfrankcooper/YCSB/wiki 这个框架可以给系统的选型作一些指导。这个框架具有很好的可扩展性,用户可以通过编写Java代码的方式来测试自己的数据库,可以通过配置文件来指定需要进行什么样的workload的测试,比如读写比例多少,每条记录多大,每个字段多大,并发数多大,进行随机选择使用的分布(比如读一条数据的时候)等。
以下为YCSB的架构图:
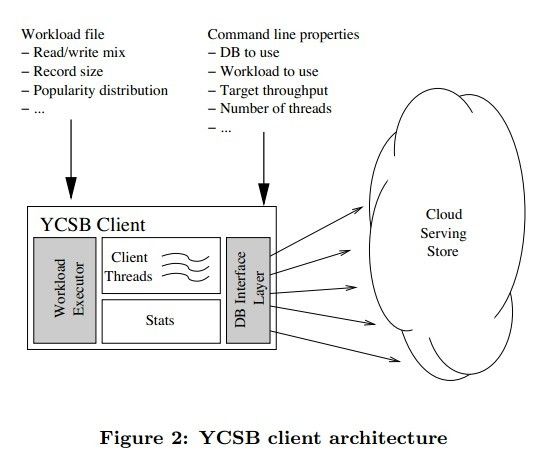
其中,灰色部分用户可以自己定制。
DB Interface Layer
和存储服务进行交互,例如read,update,delete,scan,insert记录等操作,最终都是通过DB Interface Layer交互的。针对具体的数据库,需要实现自己的DB Interface Layer,所以这个类的实现需要调用数据库服务器的AP,DB Interface LayerI对应于抽象类 com.yahoo.ycsb.DB ,这个抽象类中主要有如下方法:
//Read a single record public int read(String table, String key, Set fields, HashMap result); //Perform a range scan public int scan(String table, String startkey, int recordcount, Set fields, Vector> result); //Update a single record public int update(String table, String key, HashMap values); //Insert a single record public int insert(String table, String key, HashMap values); //Delete a single record public int delete(String table, String key);
Workload Executor:
是用来产生workload的,针对存储服务的操作最终都是通过调用com.yahoo.ycsb.DB中的方法来实现的,Workload Executor对应于抽象类com.yahoo.ycsb.Workload
这个抽象类中有如下几个主要方法:
public void init(Properties p) throws WorkloadException
YCSB Client启动的时候可以指定使用的线程数,这个方法用来初始化scenario和一些线程间的共享信息,只会被调用一次。
public Object initThread(Properties p, int mythreadid, int threadcount) throws WorkloadException
每个客户端线程都会执行一次这个方法,用来初始化thread-specific的一些状态信息,返回的Object对象封装所有的和这个线程相关的状态信息,并且这个返回的Object会被
传递给以下两个方法的第二个参数。
public abstract boolean doInsert(DB db, Object threadstate)
这个函数用于创建一条record,它需要知道目标数据库服务器的record的结构,然后插入数据库,插入操作会调用DB中的相应的方法。
public abstract boolean doTransaction(DB db, Object threadstate)
这个函数会被多个线程调用,所以这个函数必须是线程安全的。这个函数用来进行一次transaction操作,其实就是一种逻辑的操作,这个逻辑的操作中可能会包含多个DB中的基本操作。客户端启动的时候可以指定operation的次数,这个次数就是这个函数的调用次数。
客户端的每个线程都会维护一个DB的instance和一个workload的instance 。