R-CNN论文笔记
论文地址:https://arxiv.org/abs/1311.2524v1
是R-CNN论文的V1版本。
论文题目《Rich feature hierarchies for accurate object detection and semantic segmentation Tech report》
最新论文地址:https://arxiv.org/abs/1311.2524
是R-CNN论文的V5版本。
更新放在最后了。
摘要
使用ImageNet预训练获取图片的特征然后计算分类可以达到48%的 mAP在VOC2007.方法名称R-CNN: Regions with CNN features. 基于目标检测问题提出的方法,同样可以应用在语义分割问题上。作者采用了多种分析方法测试模型学习到的特征。
1 Introduction
介绍了目前的方法都是使用的SIFT和HOG特征。目前的检测方法使用四类方法:
- (1) rich structuredmodels [20, 42]; 丰富的结构化模型
- (2) multiple feature learning [38, 41]; 多特征学习
- (3) learned histogram-based features [11, 29, 32]; 学习基于直方图的特征
- (4) unsupervised feature learning [34]. 无监督特征学习
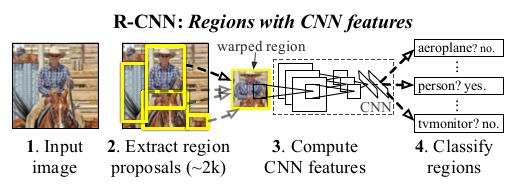
物体检测系统概述:
- (1)输入图像
- (2)提取大约2000个自下而上的区域提议(bottom-up region proposals)
- (3)使用大型卷积神经网络(CNN)计算每个区域的特征
- (4)使用类别特定的线性SVM对每个区域进行分类 。
在PASCAL VOC 2010上,该系统的平均精度(mAP)为43.5%。
测试时,提取大约2000个类别无关的区域候选框(region proposals),使用CNN提取每个候选框(proposal )的特征,然后使用二分类的类别信息分类器SVM(category-specific linear SVMs)分类每个特征。
作者使用同样的方法,做了一些修改在VOC 2011测试集上达到了47.9%的平均分割准确率(average segmentation accuracy)
2 Object detection
R-CNN分三个部分
第一部分:生成类别无关的检测框(region proposals),这些是最后的目标检测结果的集合。
第二部分:使用大的CNN给每个region提取固定长度的特征
第三部分:类别的线性分类器SVM(class-specific linear SVMs)
2.1 Module design
Region proposals.
有很多提出Region Proposal框的方法:
- objectness [1]
- selective search [36],
- category-independent object proposals [14]
- constrained parametric min-cuts (CPMC) [6],
- a method based on merging superpixels from ultrametric contour maps [2]
最后选择使用selective search
Feature extraction
作者使用自己实现的AlexNet给每个region提取4096维的特征向量。
每个减均值后的224x224的RGB图片通过5个卷积核2个全连接来计算图片特征
CNN网络的输入固定是224x224的图片,为了计算每个region的特征,且每个region的大小不确定,所以需要把每个region图片转换到CNN可以接受的图片大小。作者采用最简单的方式:直接resize图片到224x224。就可以计算每个region固定长度的特征大小了。
2.2 Inference
使用selective search在一副测试图片上提取2000个region proosals(所有实验使用的是 selective search的 fast mode)。然后把proposal变形到CNN需要的大小,并且前向传播计算特征图,然后对于每个类别,使用针对该类别训练的SVM对每个提取的特征图进行评分
没看懂:计算得出图片中所有的得分区域,使用针对每个类别使用贪婪的非最大抑制,如果该区域和另一个得分更高的区域的IoU大于一个阈值(所有的实验使用0.3),那么就抑制该区域。
应该每个region都有class num个得分,对于每个类别做NMS的意思是:只有这个region的任意一个类别的得分低于IoU大于0.3的区域,该区域就会抑制么?
Run-time analysis
有两个关键的属性使得该方法非常有效:
- 第一个:所有类别共用CNN的参数
- 第二个:CNN计算出的特征维度非常低,相比于其他的相似方法spatial pyramids with bag-ofvisual-word encodings
在UVA detection system [36]的特征维度高2个数量级:360k vs. 4k-dimensional
计算每个region的特征耗时:13s/image on a GPU or 53s/image on a CPU
类别相关的计算在特征和SVM权重的点积和non-maximum suppression(NMS)。
实际的计算时,每个图片的特征一起计算即特征矩阵2000x4096,SVM的权重是4096xN的,N是类别的个数。
2.3 Training
CNN pre-training
使用ILSVRC 2012数据集使用预训练CNN分类网络。
CNN fine-tuning
为了让CNN适应新的检测任务和新领域PASCAL数据集。使用PASCAL数据集的变形的Region Proposal继续训练CNN。在预训练阶段Learning rate三次降低10分之一。在fine-tuning阶段,使用预训练阶段LR初始值的0.1倍即:0.001,基于SGD开始训练。
所有region proposal 和ground-truth box IoU >= 0.5 的region作为正样本,其余作为负样本。在SGD迭代过程中,从训练集选择2张图片构造一个128batch的训练集,从每张图片的2000 region proposal中选64个 proposal构成。由于正样本数量少,所有每个mini batch中至少1/4是正样本。
Object category classifiers
对于二分类的的猫分类而言,正好包含一整只猫的是正样本,完全不包含猫的是负样本。对于部分包含的情况,作者测试了{0, 0.1, 0.2, …, 0.5}最后选择了0.3。基于IoU,低于0.3作为负样本。这个值得设定比较重要。
每个类别的正样本是图片的ground-truth框;负样本是和ground-truth的IoU小于0.3的框。
样本训练集确定后可以对每个类别训练SVM分类器。
作者使用了hard negative mining method [17, 35]. 发现非常有效,训练一个epoch后mAP就停止增加了。
在GPU上计算每个region的特征耗时5ms,训练20个分类的SVM使用PASCAL的5k数据耗时1.5h。
2.4 Results on PASCAL VOC 2010-12
作者在VOC 2007数据集确定方案。所有的结果是在VOC 2010-12上计算,在VOC 2012训练数据集fine-tuned CNN网络。训练SVM网络使用VOC 2012 训练验证数据集。
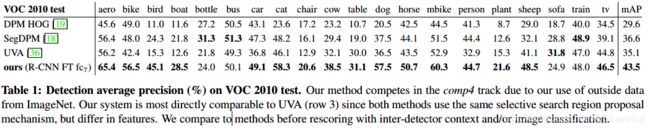
R-CNN模型不仅比UVA效果好,还快。
3 Visualization, ablation, and modes of error
这一部分作者主要是讨论CNN模型学到了什么?什么原因导致CNN模型有效?什么原因导致某些情况失败?
3.1 Visualizing learned features
论文提出一中可视化方案:没太理解
The idea is to single out a particular unit (artificial “neuron”) in the network and use it as if it were an object detector in its own right. That is, we compute the unit’s activations on a large set of held-out region proposals (about 10 million), sort the proposals from highest to lowest response, perform non-maximum suppression (within each image), and then display the top-scoring regions.
5k个图片,每张图片2k region proposal,计算每个region在该单元的激活值,将激活值从高到低排序且在每张图片上使用NMS,然后展示最高得分的region。
可视化实验中特征取得是pool5,使用pool5的特征训练的SVM,激活值使用的是pool5的特征在SVM分类后的得分。
3.2 Ablation studies
Performance layer-by-layer, without fine-tuning

Table 2 rows 1-3:fc7比fc6性能没有好处,甚至还要差。这意味着29% 16.8million的参数可以删除而且不影响mAP。如果删除fc6和fc7的参数使用pool5的特征结果仍然比较好,这只有6%的CNN参数。CNN的表示能力大部分来自于卷积层,而不是全连接层。
Color
为了测试颜色的影响,使用灰度图预训练CNN网络。使用PASCAL的灰度图CNN的fc6的特征训练SVMs。在VOC 2007测试集上mAP由43.4%降低到40.1%.
Performance layer-by-layer, with fine-tuning
在VOC 2007 trainval上fine-tuned CNN网络。
fine-tuned后,fc6和fc7层的特征比pool5的特征提高的更多。
这表明从ImageNet上学到的pool5层的特征对于PASCAL数据集完全可以使用,而大幅改善的地方是在fc6层,改进了如何组合各种不同的特征方法。
卷积层提取纹理和边缘特征,一层一层组合组成高级特征。而全连接层使用卷积层提取的特征进行组合。
Comparison to recent feature learning methods
作者介绍了DPM HOG、DPM ST、DPM HSC具体方法。
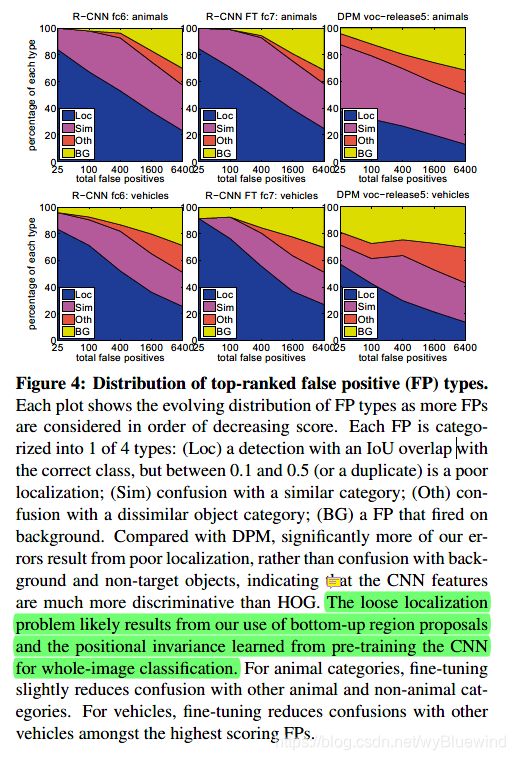
3.3 Detection error analysis
分析错误例子
4 Semantic segmentation
O2P的效果好,由于使用了CPMC生成了150个高质量的region proposal,然后使用SVR预测每个region的得分。在特征上使用了非常有效的second-order pooling 方法。
CNN features for segmentation
使用CPMC提取region,为了提取region的特征测试了3种方法:
- full:直接把region图片resize到224x224。但是这个做法无法处理不是矩形的region,两个region可能有相似的bounding boxes,但是两个region不重合。
- fg:仅计算前景的特征,把背景使用均值代替,这样在输入的时候背景部分就会变成0.
- full+fg:把full和fg的特征算concatenates。

Results on VOC 2011

fc6的结果比fc7的结果好。fg的结果比full的结果只好一点点,表示mask的前景部分提供了很强的信息。然后full+fg 达到了最有的效果,表示即使使用fg特征,full提供的上下文信息也非常有用

和其他论文结果的对比。如果加上fine-tuned结果应该会更好
5 Discussion
利用大型辅助数据集是方法成功的关键。
为什么也不给其他方法更多的培训数据呢? 一个问题是,受益于来自不同域的数据并不是一件容易的事,而且它被标记为执行不同的任务。例如,训练DPM for PASCAL要求PASCAL类别的边界框注释。
CNN网络在利用“大的视觉数据”来学习丰富的特征层次方面非常有效,这些特征层次可以在标准的PASCAL VOC挑战赛上获得以前无法实现的物体检测结果。
对于检测器而言,ILSVRC 2012标签是弱的,因为缺少一些关键的标签,比如“人”。CNN轻松将这些数据转换为性能最佳的检测结果的能力确实令人兴奋。
其他实验
后面CNN数据图片输入尺寸变成:227x227;
讨论region proposal形状变形到CNN可接受的227x227的不同方案:

一组试验性实验表明,使用上下文填充(p = 16像素)的变形的方案在很大程度上优于其他方案(3-5 mAP点)
训练样本的定义不一样
和作者的实验过程有关,具体可以查看原文。
为什么训练CNN后不直接使用softmax分类,还需要训练SVM分类。
作者通过实验测试使用softmax会是结果降低大约4%。54.2% to 50.9% mAP
原因,作者原文:
This performance drop likely arises from a combination of several factors including that the definition of positive examples used in fine-tuning does not emphasize precise localization and the softmax classifier was trained on randomly sampled negative examples rather than on the subset of “hard negatives” used for SVM training
Bounding-box regression



其他好论文:
-
检测分析工具:D. Hoiem, Y. Chodpathumwan, and Q. Dai. 《Diagnosing error in object detectors》. In ECCV. 2012.
-
可视化,deconvolutional approach:《Adaptive deconvolutional
networks for mid and high level feature learning》 -
扩展PASCAL语义分割数据集方法:《Semantic segmentation using regions and parts》[2] 、《Semantic segmentation with second-order pooling》[5]、《Semantic contours from inverse detectors》[22]
-
GIST 特征描述符 对于相似图片有很好的性能:《Evaluation of gist descriptors for web-scale image search. In Proc. of the ACM International Conference on Image and Video Retrieval》