机器学习笔记三:经典算法
第三章: 机器学习经典算法
机器学习之经典算法
- 第三章: 机器学习经典算法
-
- 一、KNN算法
-
- 定义:
- 距离计算公式:
- 适用案例:
- 算法优缺点:
- 特征工程处理:
- skLearn API:
- spark API:
- 二、朴素贝叶斯分类算法
-
- 原理:
- 应用场景:
- 优缺点:
- API:
- 三、决策树
-
- 分类原理:
- API
- 优缺点:
- 四、随机森林
-
- 原理:
- API:
- 优缺点:
- 五、线性回归
-
- 原理:
- 目标:
- 损失函数:最小二乘法
- 优化方法:
- API:
- 回归性能评估方法:
- 两种线性回归方法对比:
- 集中梯度下降的优化方法:
- 六: 岭回归- RidgeRegressor
- 关于正则化:
-
- API:
- 带交叉验证的岭回归
- 七:逻辑回归与二分类
- 逻辑回归原理:
-
- 逻辑回归API:
- 逻辑回归模型评估:
- 混淆矩阵、精确率(Precision)、召回率(Recall)
- 混淆矩阵计算API:
- ROC曲线和AUC指标
- AUC指标计算API:
- AUC总结
- 八: 无监督学习-K-means算法
-
- KMeans API:
- kMeans性能评估:
- 轮廓系数API:
- 总结:
机器学习适用的数据为具有特征值(属性,label)和目标值(结果,point)的数据集。通过从历史数据集中学习经验,建立模型,从而达到预测新特征值对应的目标值的效果。因此在数据方面,越见多识广的数据集(样本集越大越全),越能进行更可信的预测(越准确的预测)。
算法分类:
按有无特征值分类:1、监督学习:有特征值 2、无监督学习:无特征值
按特征值类型分类;1、分类算法:特征值为一组有限且固定的序列 2、回归算法:特征值为一个连续的数值空间
算法选择:sklearn中提供了基础的算法选择图谱。

一、KNN算法
定义:
如果一个样本在特征空间中的K个最相似(距离最近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
人以类聚,物以群分。
距离计算公式:
欧式距离(平方根距离)、曼哈顿距离(绝对值距离),明科夫斯基距离(以上两种距离均是明科夫斯基距离的特例)
适用案例:
iris,根据鸢尾花的一些特征判断一个鸢尾花所属的种类
适用于小数据场景,K-W数据量级别的样本。
算法优缺点:
优点:简单、易于理解,易于实现,无需训练
缺点:1、懒惰算法,对预测样本分类时才进行计算,计算量大,内存开销大。
2、必须指定K值,K值选择会极大程度影响分类的准确度。
关于K值选取:K值过小,容易受到异常数据的影响。而K值过大,容易受样本不均衡的影响。
特征工程处理:
需尽量保证各个维度的数据公平性。无量纲化-标准化处理。尽量保证各个维度的数据公平性。
skLearn API:
sklearn.neighbors.KNeighborsClassifier(n_neighbor=5,algrithm='auto')
n_neighbors: int 可选,默认5 , K值
algorithm : {'auto','ball_tree','kd_tree','brute'} .可选。用于计算最近的算法。有ball_tree、kd_tree。不同的实现方式会影响效率,但不影响结果。一般用auto,会自己根据fit方法的值来选择合适的算法。
spark API:
未找到。
二、朴素贝叶斯分类算法
朴素:假定了特征与特征之间相互独立,没有影响。
贝叶斯:贝叶斯概率计算公式。
原理:
30%的男人是好人,80%的老人是好人, 那男老人有24%的概率是好人
应用场景:
文本分类、评论区分好差评
优缺点:
优点:发源于古典数学理论,有稳定的分类效率
对缺失数据不敏感,算法也比较简单,常用语文本分类。
分类速度快,准确度相对较高。
缺点:由于使用了样本属性独立的假设,当特征属性之间有关联时,其效果就不太好。
API:
sklearn:
sklearn.naive_bayes.MuitinomialNB(alpha = 1.0)
alpha:拉普拉斯平滑系数,一般用1 。
spark: JavaNaiveBayesExample
三、决策树
决策树模型就是一个多层的if-else结构
分类原理:
特征判断的先后顺序,要能尽量快速过滤掉大部分不符合标准的情况。决策树的划分依据之一:信息熵,信息增益。
信息熵可认为是信息的混乱程度。而信息增益可以理解为按某一个属性进行划分后的信息熵增益。决策树的划分方式就是在每一个节点选择信息增益最大的属性进行划分。
另外,在理论上,信息增益准则对可取值数据较多的属性是有偏好的,为了减少这种不利影响,改进方法是使用信息增益率来选择最优划分属性。–这个选择偏好可以这样理解,比如对一般的数据库,大都有ID作为唯一标识。那如果按照信息增益准则,这个ID就是最优的划分属性,因为按照这个属性可以唯一的将数据分出类别,这就是所谓的偏好。而增益率则可以减少这种偏好的不利影响。比较高端的做法是先从候选划分属性中找出信息增益高出平均水平的属性,再从中选择增益率高的属性,作为最优的属性。
信息熵计算公式,信息增益计算公式,信息增益率计算公式,gini系数。。全都看得似懂非懂。
API
sklearn:
sklearn.tree.DecisionTreClassifier(criterion='gini',max_depth=None,random_state=None)
决策树分类器
criterion: 默认是'gini'系数,也可以选择信息增益的熵‘entropy’
max_depth:树的深度大小
random_state:随机数种子
spark:
JavaDCTExample、JavaDecisionTreeClassificationExample、JavaDecisionTreeRegressionExample
优缺点:
优点: sklearn中有可视化工具,并且模型的可解释能力强,不需要进行数据归一。模型就是一个多层的If-else结构,比较容易理解。
缺点:不太容易扩展到更复杂的情况,整个决策树容易过大。容易产生过拟合。过拟合的调整方式是配置maxDepth参数,修改树的深度。
另一种改进方法是进行剪枝。
四、随机森林
通过建立几个模型组合来解决单一预测问题。其原理就是生成多个分类器(模型),各自独立地学习和做出预测。这样预测最后结合成组合预测,一般都优于任何一个单一分类器做出的预测。其输出的类别就是取多数的结果。
原理:
BootStrap随机有放回抽样。从训练集中随机取一个样本,让如新训练集。然后从原训练集中再随机抽取(已抽取的样本放回原训练集)。这样,每棵树的训练集都是独有的。
相当于将数据分散成不同的树。随机的预测思想就是这些树中有“正确”的树,也有“错误”的树。而“错误”的树的学习结果会互相抵消,最终“正确”的树就会脱颖而出。
API:
sklearn:
sklearn.ensemble.RandomForestClassifier(n_estimators=10,criterion='gini',max_depth=None,bootstrap=True,random_state=None,min_samples_split=2)
n_estimators: Int 默认10 森林里的数据数量
criteria: String 默认gini . 分隔特征的测量方法 entropy
max_depth: Integer或者None,可选。树的最大深度
max_features="auto" 每个决策树的最大特征数量
auto, sqrt log2 None
auto和sqrt是一个意思,开根号。 None取跟原样本一样的特征树。
bootstrap: boolean 默认true 是否在构建树时使用放回抽样
min_samples_split:节点划分最少样本数
min_samples_leaf:叶子节点的最小样本数
超参数:n_estimator, max_depth,min_samples_split,min_samples_leaf。 可用网格搜索
spark中也有多个官方示例。
优缺点:
在所有分类算法中,具有较好的准确率。能够有效的运行在大数据集上,处理具有高维特征的输入样本,而且不需要降维。能够评估各个特征在分类问题上的重要性。
五、线性回归
回归问题:目标值是一组连续的数据。

原理:
用一个多元一次方程来描述特征值与目标值之间的关系,线性关系。
使用场景:波士顿方法预测Demo
目标:
模型参数能够尽量准确的预测目标值。–损失函数最小。
损失函数:最小二乘法
预测目标值减去实际目标值,再求平方和。优化的方法就是求出模型中的一组参数,使得损失函数打到最小。

优化方法:
1、正规方程: --打不出公式来,参数矩阵一通转置,求逆。 直接按照方程求最优解。类似于抛物线方程直接求极值。

缺点:当特征过多且复杂时,求解速度太慢,而且可能得不到结果。 另外,无法解决过拟合的问题。 所以一般都是用下面的梯度下降。
2、梯度下降:先假定一组解,再不断试错,逼近正确答案。
原理:沿着坡度最陡的方向()移动一段距离,不断逼近损失函数最小值。

API:
sklearn.linear_model.LinearRegression(fit_interfcept=True)
- 通过正规方程优化
- fit_intercept: 是否计算偏置--参数序列最后的b
- LinearRegression.coef_ : 回归系数
- LinearRegression.intercept_ : 偏置
sklearn.linear_model.SGDRegressor(loss="squard_loss",fit_intercept=True,learning_rate='invscaling',eta0=0.01)
- SGDRegressor类实现了随机梯度下降学习,支持不同的loss函数和正则化惩罚项来拟合线性回归模型
- loss: 损失类型 squared_loss 普通最小二乘法
- fit_intercept: 是否计算偏置
- learning_rate: string,可选项:
constant : eta=eta0
optimal: eta=1.0/(alpha*(t+t0)) --default
invscaling.: eta = eta0/pow(t,power_t)
常用constant,并使用eta0指定学习率。
SGDRegressor.coef_ :回归系数
SGDRegressor.intercept_ :偏置
回归性能评估方法:
均方误差MSE(Mean Squared Error)-跟损失函数长得挺像的。

两种线性回归方法对比:
梯度下降:有超参数-学习率。迭代求解。可以使用于大规模数据集。可以通过调整解决过拟合问题。
正规方程:不需要学习率,一次运算的出。大规模数据计算太过复杂,只适用于小规模数据。不能解决过拟合问题。
集中梯度下降的优化方法:
GD: Grandient Descent ; 原始的梯度下降方式。需要计算所有样本的值才能的出梯度,计算量大,后面会有一系列的改进。
SGD:Stochastic Grandient Descent:随机梯度下降,他在一次迭代时只考虑一个训练样本。比较高效,节省时间。缺点是需要许多超参数,对特征标准化敏感。
SAG:Stochastic Average Gradient 。 随机平均梯度法。比SGD的收敛速度更快
六: 岭回归- RidgeRegressor
岭回归也是一种线性回归,只不过在算法建立回归方案时,加上了正则化的限制,从而达到解决过拟合的效果。因此比线性回归更常用。
关于正则化:
当原始数据的特征较多时,容易存在一些嘈杂特性。而模型为了去兼顾所有特征会变得过于复杂,这样很容易产生过拟合。
而优化的方式是使用正则化。在损失函数中加入一个惩罚项。可以使模型中一些参数w都很小,很接近于0,削弱某个特征的影响。越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合。
有L1正则化和L2正则化,L2更常用。

正则化力度越大,权重系数会越小。
API:
sklearn.linear_model.Ridge(alpha=1.0. fit_intercept=True,solver='auto',normalize=False)
- 具有L2正则化的线性回归。、
- alpha: 正则化力度,也叫λ 取值范围: 0~1 1~10
- solver: auto 会根据数据自动选择优化方法。sag:如果数据集、特征都比较大,可以ixuanze随机梯度下降优化
- normalize:数据是否进行标准化。设置为true时,相当于先进行标准化,在进行预估器流程。
- 返回值: Ridge.coef_: 回归参数
- Ridge.intercept_: 回归偏置
带交叉验证的岭回归
sklearn.linear_model.RidgeCV(_BaseRidgeCV,RegressorMixin)
七:逻辑回归与二分类
二分类问题: 是否垃圾邮件、是否金融诈骗、是否虚假帐号。。。
这里即是用逻辑回归来解决二分类问题。
逻辑回归原理:
先对一组数据建立线性回归模型,h(w) = w1x1 + w2x2+…+b
然后用线性回归的输出作为逻辑回归的输入,将特征值映射到一个分类中,作为预测的目标值。例如:sigmoid激活函数:

线性回归的输出作为逻辑回归的输入

例如,看下图的计算示例,逻辑回归的结果可以认为是样本的二分类概率。然后,同样通过损失函数来计算逻辑回归的模型性能。

逻辑回归API:
sklearn.linear_model.LogisticRegrsssion(solver='liblinear',penalty='l2',C=1.0)
- solver: 优化求解模式。 默认 liblinear , 还有sag 随机平均梯度下降
- penalty: 正则化的种类。 l1 l2
- C: 正则化力度
逻辑回归模型评估:
逻辑回归的结果只是一个二分类的概率,如有80%的可能是垃圾邮件。然而这种概率结果其实是很虚的,用模型评估拿到也是一个概率,闭上眼睛瞎蒙也能说出一种概率,因此,对计算模型需要有更详细的评估标准。
混淆矩阵、精确率(Precision)、召回率(Recall)
在二分类任务中,预测结果与正确标记之间存在四种不同的组合,构成混淆矩阵(这个矩阵其实在多分类问题中也能建立,只是更加复杂)
| 真实结果\预测结果 | 正例 | 假例 |
|---|---|---|
| 正例 | 真正例TP | 为反例FN |
| 假例 | 伪正例FP | 真反例TN |
精确率Precision: 预测结果未正例样本中真实为正例的比例:
一批西瓜中,预测为好西瓜的瓜有多少真正是好西瓜。体现模型的准确性。–要把好西瓜挑出来

召回率Recall:真实为正例的样本中预测结果也为正例的比例:对正样本的区分能力。
一批西瓜中,所有真正为好西瓜的西瓜中有多少是被正确预测为好西瓜。体现模型对正样本的区分能力。–要把坏西瓜扔掉

另外,还有其他更复杂的评估标准。如F1-Score,反映了模型的稳健型

混淆矩阵计算API:
`sklearn.metrics.classification_report(y_true,y_pred,labels=[],target_name=None)`
- `y_true : 真实目标值数组`
- `y_pred: 估计器预测目标值`
- `labels: 指定类别对应的数字`
- `target_names: 目标类别名称`
- `return: 每个类别精确率与召回率`
- `precision 精确率`
- `recall 召回率`
- `f1-scoreL 稳健度`
- `support 样本数`
有了这些指标后,能够一定程度上评估模型的健康度。但是光有这些指标还不太够,例如在样本不均衡,正样本太多,负样本太少时,这些指标评估结果就不太可信。看下面的这个例子:

这样随便进行预测的模型显然是不靠谱的,但是这些指标都很高。而为了能更准确的评估二分类模型,就引入了ROC曲线和AOC指标。
ROC曲线和AUC指标
首先需要了解TPRate和FPRate
-
TPRate = TP / (TP+FN): 所有真实类别为1的样本中,预测类别也为1的比例
-
FPRate = FP/( FP + TN):所有真实类别为0的样本中,预测类别为1的比例
有这两个数据后,对于每一个分类器,就可以建立一条ROC曲线

而AUC指标就可以认为是ROC曲线下方的图形面积。
因此,
-
AUC指标的概率意义是随机取一对正负样本,正样本得分大于负样本的概率。
-
AUC指标的最小值是0.5,最大值是1,取值越大越好
-
AUC=1,就是完美分类器,采用这个预测模型时,不管设定什么阈值都能的出完美预测结果。但是,在绝大多数预测的场合,都不存在完美分类器。
-
0.5
-
同时,AUC指标也能用于比较多个不同的分类器的性能。
AUC指标计算API:
`sklearn.metrics.roc_auc_score(y_true,y_score)`
- `计算ROC曲线面积,即AUC值`
- `y_true: 每个样本的真是类别,必须为0-反例,1-正例 标记`
- `y_score:预测得分,可以是正类的估计概率、可信值或者分类器方法的返回值`
AUC总结
AUC只能用来评估二分类问题
AUC非常适合评价样本不均衡时的分类器性能。
回到开始的那个例子,通过AUC指标就能评估出癌症逻辑回归的模型不太好了。

八: 无监督学习-K-means算法
无监督学习:无目标值
示例场景:一家广告平台需要根据相似的人口学特征和客户消费习惯将目标客户分成不同的小组,以便广告客户可以通过有关联的广告解除到他们的目标客户
算法:K-Means聚类, PCA(主成分分析法)降维
以下KMeans效果图: 将一群点随机分成三类
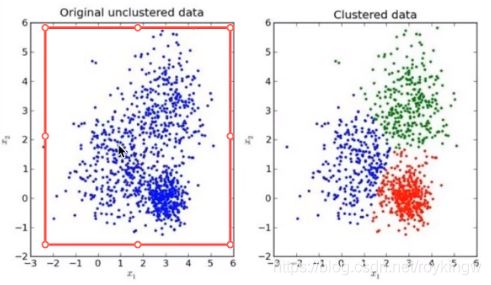
而下面这个图说明了KMeans的计算步骤:
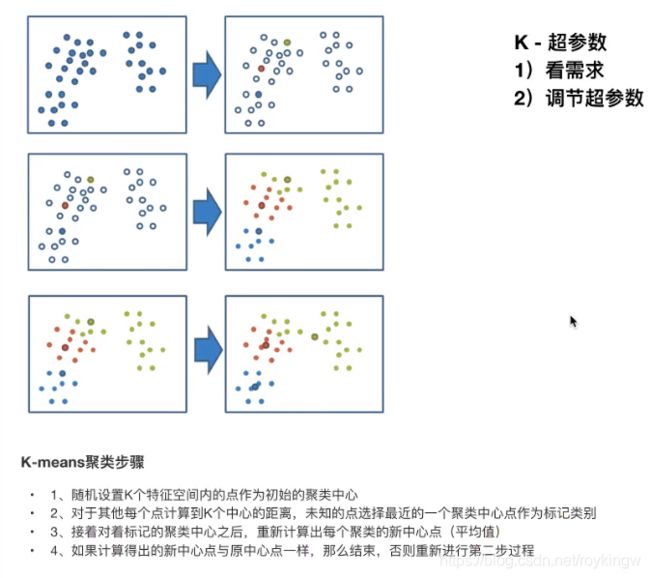
KMeans API:
kMeans实现走预估器代码流程
`sklearn.cluster.KMeans(n_clusters=8, init = 'k-means++')`
`n_clusters:开始的聚类中心数量`
`init : 初始化方法。`
`labels_ : 默认标记的类型,可以和真实值比较(不是值比较)`
kMeans性能评估:
KMeans采用轮廓系数来进行评估,轮廓系数在-1,1之间,越接近1,分类效果越好,越接近-1 ,分类效果越差。

轮廓系数API:
sklearn.metrics.silhouette_score(X,labels)`
计算所有样本的平均轮廓系数`
X: 特征值`
labels: 被聚类标记的目标值
总结:
特点: KMeans采用迭代式算法,直观易懂并且非常实用
缺点:容易收敛到局部最优解 : 一开始随机选取的聚类中心过于集中 , 可以多次聚类来解决。
应用场景:聚类一般用在分类之前。没有目标值,先用聚类计算出一部分目标值,再用目标值进行分类。