信号处理深度学习机器学习
As a design engineer, I am increasingly exposed to more complex engineering challenges — some of which require a blend of multidisciplinary expertise. The Advanced Machine Learning and Signal Processing course provided me with the window to understand how machine learning and signal processing can be integrated and applied together.
作为一名设计工程师,我越来越多地面临更复杂的工程挑战,其中一些挑战需要综合多学科的专业知识。 高级机器学习和信号处理课程为我提供了一个窗口,以了解如何将机器学习和信号处理集成在一起并一起应用。
Although the title of the course sounded daunting at first, it is not difficult to follow. However, prior knowledge of statistics and calculus will come in handy during the later parts of the course. This course is delivered by IBM Chief Data Scientist Romeo Kienzler and Nickolay Manchev and is offered by Coursera as part of a 4-course IBM Advanced Data Science Specialization.
尽管课程的名称起初听起来令人生畏,但并不难遵循。 但是,在课程的后半部分将很容易掌握统计学和微积分的先验知识。 该课程由IBM首席数据科学家Romeo Kienzler和Nickolay Manchev提供,Coursera作为4门课程IBM Advanced Data Science Specialization的一部分提供 。
The course is structured into 4 weeks, whereby Week 1 to Week 3 covers machine learning concepts and algorithms. On Week 4, the signal processing part is covered and we are shown how to integrate signal processing and machine learning.
该课程分为四个星期,第1周至第3周涵盖了机器学习的概念和算法。 在第4周,介绍了信号处理部分,并向我们展示了如何集成信号处理和机器学习。
第一周 (Week 1)
This week sets the stage for the upcoming weeks and we started off exploring linear algebra used in machine learning. We are first introduced to different data objects: scalar, vector, matrix, and tensor; as well as the mathematical operations that can be applied to them (dot product, vector-matrix multiplication).
牛逼了为期一周设置舞台为即将到来的星期,我们开始了探索机器学习使用线性代数。 首先介绍不同的数据对象:标量,向量,矩阵和张量; 以及可以应用于它们的数学运算(点积,向量矩阵乘法)。
Data objectsA scalar is one dimensional and can be any integer, ie:
数据对象标量是一维的,可以是任何整数,即:
1, 5, -18A vector is a group of scalars and can only contain one datatype, ie:
向量是一组标量,并且只能包含一个数据类型,即:
(0,11,135)A tuple is similar to a vector, but it can contain multiple data types, ie:
元组类似于向量,但是它可以包含多种数据类型,即:
(0,1,7.8) #notice the integer and float datatypesMatrices are a list of equal-sized vectors and tensors are matrixes in 3 or higher dimensions. Tensors are useful for image processing (for example, 1 dimension is used for width, another for color, and another for height).
矩阵是等长向量的列表,张量是3维或更高维的矩阵。 张量对于图像处理很有用(例如,一维用于宽度,另一维用于颜色,另一维用于高度)。
We then learned about higher-dimensional vector spaces and the intuition to picture and split them.
然后,我们了解了高维向量空间以及图片的直观认识并对其进行了拆分。
- To split in 1-dimension, we use a point. 要分割成一维,我们使用一个点。
- To split in 2-dimensions, we use a line. 要分成二维,我们使用一条线。
- To split in 3-dimensions, we use a plane. 为了分成3维,我们使用一个平面。
- To split higher than 3-dimensions, we use a hyperplane. 为了分割高于3维的图像,我们使用一个超平面。
There are 2 types of machine learning:
机器学习有两种类型:
Supervised Learning: Trained on datasets with output labels, i.e. a flag is assigned to a data point. The algorithm aims to solve the Y = f(x) equation by predicting what Y will be when we change x. Supervised learning is broken down into:
监督学习:在带有输出标签的数据集上进行训练,即将标志分配给数据点。 该算法旨在解决Y = F(X)的预测,当我们改变X Y是什么方程。 监督学习可分为:
Classification — predicts a discrete value i.e.: “True/False”
分类 -预测离散值,即:“ True / False”
Regression — predicts a continuous value ie: “Price of mobile phones in the future”
回归 -预测一个连续的值,即:“未来手机的价格”
2. Unsupervised Learning: Trained on datasets without output labels. The algorithm attempts to discover patterns from the input data by grouping similar data together. An example of unsupervised learning is Clustering where data are segregated into clusters (More on this during Week 3).
2. 无监督学习:对没有输出标签的数据集进行训练。 该算法尝试通过将相似数据分组在一起来从输入数据中发现模式。 无监督学习的一个示例是“ 聚类” ,其中将数据隔离到聚类中(第3周中有更多相关内容)。

PySpark allows us to modularize data pipelines. By using the Spark libraries of StringIndexer, OneHotEncoder, VectorAssembler, and Normalizer, we can ensure all the pre-processing is fully aligned and taken care of before the ML model takes place. The idea is to condense these pre-processing parts into “Pipelines” and take advantage of this flexibility to quickly switch between different training parameters to optimize for the best machine learning model.
PySpark允许我们对数据管道进行模块化。 通过使用StringIndexer星火库,OneHotEncoder,VectorAssembler 和 规范化器,我们可以确保在ML模型发生之前,所有预处理均已完全对齐并得到妥善处理。 想法是将这些预处理部分压缩为“管道”,并利用这种灵活性在不同的训练参数之间快速切换,以优化最佳的机器学习模型。

from pyspark.ml import Pipeline
pipeline = Pipeline(stages = (string_indexer, encoder, vectorAssembler, normaliser))model = pipeline.fit(df)
prediction = model.transform(df)All the coding assignments are completed in IBM Watson Studio and this week’s hands-on approach builds the foundation for the steps required to set up and run a machine learning project.
所有编码任务均在IBM Watson Studio中完成,本周的动手方法为设置和运行机器学习项目所需的步骤奠定了基础。
第二周 (Week 2)
Common machine learning models and concepts are presented this week and the lectures are a mixture of explaining theories and demonstrating how to use an algorithm with Apache SparkML. The course presenters did a great job to explain the following concepts that are crucial for a solid machine learning foundation.
çommon机器学习模型和概念本周介绍和讲座是解释理论和演示如何使用与Apache SparkML的算法的混合物。 课程演示者出色地解释了以下对于扎实的机器学习基础至关重要的概念。
Linear Regression and Batch Gradient Descent A Linear Regression model is a model based on supervised learning and can be described by the following function:
线性回归和批次梯度下降线性回归模型是基于监督学习的模型,可以通过以下函数进行描述:
y = w₀ + w₁x₁ + w₂x₂ +w₃x₃...+wₙxₙ ; whereby w is the feature weightIts main function is to predict a dependent variable (y) based on the independent variables (x) that are supplied. Its counterpart, Logistic Regression is used to predict a discrete value. The feature weights are determined using the Gradient Descent strategy and Batch Gradient Descent happens to be one of these optimization strategies.
它的主要功能是根据提供的自变量(x)预测因变量(y)。 它的对应项Logistic回归用于预测离散值。 使用权重下降策略确定特征权重,而批次梯度下降恰好是这些优化策略之一。

Batch Gradient Descent is guaranteed to find the global minimum of the cost function — given there is enough time and the learning rate is not too high. (imagine trying to reach the bottom of a valley). It is slow over a large dataset as the model is only updated after evaluating the error for every sample in the dataset.
保证有足够的时间并且学习率不太高,可以保证批次梯度下降找到成本函数的全局最小值。 (想象一下要到达山谷的底部)。 在大型数据集上速度较慢,因为仅在评估数据集中每个样本的误差后才更新模型。
We then briefly learned about splitting our dataset into training and validation datasets, as well as the method to evaluate if the prediction results are underfitting or overfitting.
然后,我们简要了解了将我们的数据集分为训练和验证数据集以及评估预测结果是拟合不足还是拟合的方法。
The Naive Bayes TheoremEven though this topic is challenging, Nickolay managed to summarize it into a digestible yet, in-depth manner. We were shown the intuitions and mathematics behind the Naive Bayes theorem such as:
朴素贝叶斯定理即使这个话题具有挑战性,尼克利仍然设法将其概括为易于理解但深入的方式。 我们看到了朴素贝叶斯定理背后的直觉和数学,例如:
- Sum Rule and Product Rule — allows us to solve most probabilities problems 求和规则和乘积规则-使我们能够解决大多数概率问题
- The Gaussian Distribution, or more commonly known as the Normal Distribution — data that is symmetrically distributed by the mean. 高斯分布,或更通常称为正态分布-通过均值对称分布的数据。
- The Central Limit Theorem — all the means of a sufficiently large enough sample will end up in a Gaussian Distribution 中心极限定理-足够大样本的所有均值将最终达到高斯分布
- The Bayesian Interference — the probability of a hypothesis is updated as new evidence becomes available 贝叶斯干扰-假设的概率随着新证据的出现而更新
Up until this point, there is already a lot of information for Week 2, but we’re not quite done yet!
到目前为止,第二周已经有很多信息,但是我们还没有完成!
Support Vector MachinesWe moved on to a quick introduction of Support Vector Machines (SVMs) and learned how they lost ground to Gradient Boosting in terms of popularity. SVMs are linear classifiers and to turn them into a non-linear classifier, the “kernel” method can be deployed. This method, or “trick” that Romeo calls it, transforms training data onto the “feature” space and allows a hyperplane to cleanly separate data points. The examples in this part of the course were intuitive, beginner-friendly, and easy to remember.
支持向量机我们继续快速介绍了支持向量机(SVM),并了解了它们如何在普及度方面不及Gradient Boosting。 SVM是线性分类器,为了将它们变成非线性分类器,可以部署“内核”方法。 罗密欧称之为“特技”的这种方法将训练数据转换为“特征”空间,并允许超平面干净地分离数据点。 本部分课程的示例直观,对初学者友好且易于记忆。
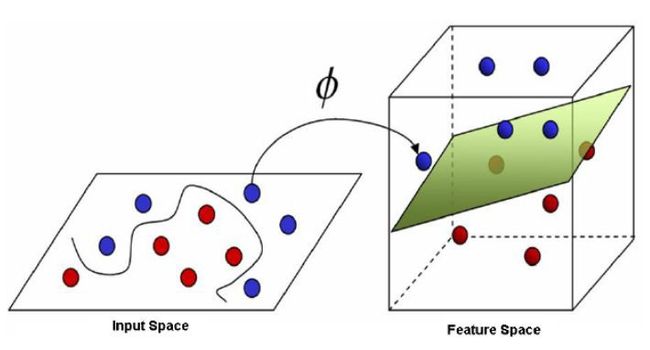
This week was nicely wrapped up with Decision Trees, RandomForests, and Gradient Boosted Trees. We were shown the methods of sampling and the pros and cons of each model. There is also a coding exercise that ties up what we learned in Week 1 and Week 2 which demonstrates the application and prediction accuracy of a GBTClassifier using SparkML.
本周的决策树,RandomForests和梯度增强树非常好。 我们获得了抽样方法以及每种模型的利弊。 还有一个编码练习与我们在第1周和第2周中学到的内容联系在一起,它演示了使用SparkML的GBTClassifier的应用和预测准确性。
第三周 (Week 3)
Ifelt stretched the most this week with the introduction of more advanced topics such as Clustering and Principal Component Analysis (PCA). We learn about unsupervised machine learning where we try to fathom the distances between point clouds. There are various methods to measure distance i.e. subtracting between 2 points; Pythagoras’ Theorem, Euclidean Distance, and Manhattan Distance.
在本周, 我感到最紧张的是引入了更高级的主题,例如聚类和主成分分析(PCA) 。 我们了解了无监督的机器学习,我们试图了解点云之间的距离。 有多种测量距离的方法,即在2个点之间减去。 毕达哥拉斯定理,欧几里得距离和曼哈顿距离。
We learned about clustering using K-means algorithm (the ‘Hello World’ clustering algorithm) and the Hierarchical algorithm. K-means works in a way that we specify the number of expected clusters, then the algorithm will draw a hypersphere in the 3D space and tries to group each data point from the point clouds into clusters based on the nearest center.
我们了解了使用K-means算法 (“ Hello World”聚类算法)和Hierarchical算法进行聚类的知识。 K-means的工作方式是指定期望的簇数,然后该算法将在3D空间中绘制一个超球面,并尝试根据最近的中心将点云中的每个数据点分组为簇。

The Curse of Dimensionality We often have to choose the trade-off between having faster computing time and having more dimensions (features) while maintaining a certain level of accuracy. The number of samples becomes increasingly sparse as we add more dimensions and distances between the data points lose meaning. To solve this problem, PCA is used to reduce the number of dimensions while maintaining the distances between the original data points as much as possible. These distances are crucial in classification as they allow us to predict data-points into different classes.
维数的诅咒我们通常必须在保持更快的计算速度和拥有更多维数(特征)之间进行权衡,同时保持一定的准确性。 随着我们添加更多维度和数据点之间的距离失去意义,样本数量变得越来越稀疏。 为了解决此问题,PCA用于减少维数,同时尽可能保持原始数据点之间的距离。 这些距离对于分类至关重要,因为它们使我们能够将数据点预测为不同的类别。
There are a couple of quizzes this week, but they are sufficient to test my understanding of the material. Similar to the previous weeks, there is a coding exercise to consolidate the material learned so far.
这周有几个测验,但足以测试我对这些材料的理解。 与前几周相似,我们进行了编码练习,以巩固到目前为止所学的材料。
第四周 (Week 4)
I was looking forward to this week the most as we finally cover the signal processing part — a topic that I am very keen to explore.
我最期待本周的内容,因为我们最终将介绍信号处理部分,这是我非常想探索的话题。
SignalsThere are 3 variables to describe a signal: 1. Frequency — how many occurrences of the signal2. Amplitude — the strength of the signal 3. Phase shift — how much horizontal offset a signal moved from its original position.
信号有3个变量来描述信号:1.频率-信号2的出现次数。 幅度-信号的强度3.相移-信号从其原始位置移动了多少水平偏移。

Most signals can be generated or described using the following formula:
可以使用以下公式生成或描述大多数信号:
y(t) = Asin(2*pi*ft + φ) whereby, A = amplitude, f = frequency, t = time, φ = phase shiftFourier transform Fourier Transform allows us to decompose a complex signal — be they music, speech, or an image into their constituent signals via a series of sinusoids.
傅立叶变换傅立叶变换使我们可以通过一系列正弦波将复杂的信号(无论是音乐,语音还是图像)分解为它们的组成信号。
In terms of images, we can decompose an image’s colors into its RGB constituents.
在图像方面,我们可以将图像的颜色分解为RGB成分。


Nickolay used the example of a piano chord to identify its individual notes using Fourier transform. Sound waves are generated when vibrations travel across a medium. When we have different levels of vibrations, we will obtain different waveform amplitudes. These amplitudes can be summed, or superpositioned to obtain the net response of each individual amplitude.
尼古拉(Nickolay)以钢琴和弦为例,通过傅立叶变换来识别其各个音符。 振动在介质上传播时会产生声波。 当我们有不同程度的振动时,我们将获得不同的波形幅度。 可以将这些幅度相加或叠加以获得每个单独幅度的净响应。
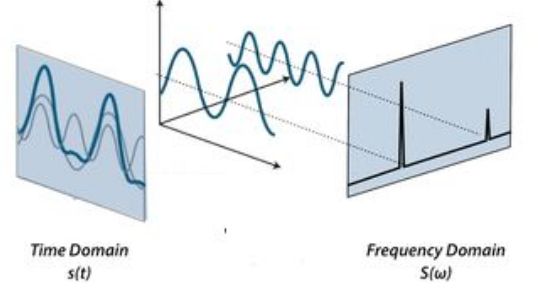
We can study waveforms from two domains —the time domain and the frequency domain. Fourier Transform and Inverse Fourier Transform translates between these domains. (The former from time to frequency domain and the latter from frequency to time domain).
我们可以从两个域( 时域和频域)研究波形。 傅立叶变换和逆傅立叶变换在这些域之间转换。 (前者从时域到频域,后者从时域到频域)。
The chapter is concluded by linking signal processing and machine learning through the Wavelets topic. Fourier Transform works well on stationary signals but in real life, we constantly work with non-stationary signals. Fourier transform cannot provide information on when specific frequencies occur in these signals. Hence, wavelet transform is required to overcome this limitation using a scaleogram, which is a visual representation of a wavelet transform. To fully understand wavelet and Fourier transform, Nickolay explained the maths behind them.
通过小波主题将信号处理和机器学习联系起来,结束本章。 傅立叶变换在固定信号上效果很好,但在现实生活中,我们一直在处理非固定信号。 傅立叶变换无法提供有关这些信号何时出现特定频率的信息。 因此,需要小波变换以使用比例图克服此限制,比例图是小波变换的视觉表示。 为了完全理解小波和傅立叶变换,尼克拉伊解释了它们背后的数学原理。
The final programming assignment is an exercise on how to classify a signal using machine learning. For someone looking into how sensor data and machine learning works, the topics and exercises for this week are truly fascinating and interesting.
最终的编程任务是关于如何使用机器学习对信号进行分类的练习。 对于那些研究传感器数据和机器学习如何工作的人来说,本周的主题和练习确实令人着迷且有趣。
结论 (Conclusion)
I find the products I am working on are getting smarter and fitted with more sensors. Often, having multi-disciplinary skills is advantageous to deliver a project. This course “kills 2 birds” for me by providing some of the important topics of signal processing and machine learning.
我发现我正在研究的产品越来越智能,并配备了更多的传感器。 通常,具有多学科技能对于交付项目是有利的。 通过提供一些信号处理和机器学习的重要主题,本课程为我“杀了两只鸟”。
The delivery pace is good, and the explanations are decent enough for a professional or a curious casual learner. For some of the topics that are taught — especially the Bayesian theorem, PCA, and Wavelet transform parts — further study and research are important to gain a deeper understanding.
交付速度很好,而且对于专业人士或好奇的临时学习者来说,解释也足够不错。 对于所讲授的某些主题,尤其是贝叶斯定理,PCA和小波变换部分,进行深入的研究和研究对于加深理解至关重要。
There are other courses that cover more in-depth about machine learning and signal processing but what I truly enjoyed about this course was the connection and ‘blending’ of these 2 topics that are so interrelated to each other.
还有其他课程涵盖了机器学习和信号处理方面的更深入信息,但是我真正喜欢这门课程的是这两个主题之间的联系和“融合”,这两个主题相互关联。
With IBM Watson Studio being used in the assignments of this course, there is another added advantage to be exposed to IBM’s cloud tools and services. The course seems to be providing the learner to choose their own difficulty for the assignments. It is not challenging to pass the assignments as there is a lot of hand-holding and guidance. But there is always an option to really understand the code that is shown and that takes time for beginner programmers.
由于本课程的作业中使用了IBM Watson Studio,因此使用IBM的云工具和服务还有另一个附加的优势。 该课程似乎为学习者提供了自己选择作业的难度。 通过作业并不困难,因为需要大量的指导和指导。 但是总有一个选项可以真正理解所显示的代码,这对于初学者来说很费时间。
I am looking forward to applying what I learned from this course and I hope by writing this summary, I solidify my learning and you have learned something as well.
我期待着应用从本课程中学到的知识,并希望通过撰写此摘要,巩固我的学习经验,并且您也学到了一些东西。
翻译自: https://towardsdatascience.com/how-do-machine-learning-and-signal-processing-blend-4f48afbb6dce
信号处理深度学习机器学习