PERFECT MATCH: IMPROVED CROSS-MODAL EMBEDDINGS FOR AUDIO-VISUAL
SYNCHRONISATION
超匹配:改进了用于音频-视频合成的跨地带调制
摘要:
本文提出了一种学习音频到视频同步的强大跨模态嵌入的新策略。在这里,我们将问题设置为跨模态检索,其中目标是找到给定短视频剪辑的最相关的音频片段。该方法建立在跨模态自我监督学习表示的最新进展的基础上。主要的贡献论文如下:(1)我们提出了一种新的学习策略,其中嵌入是通过多路匹配问题来学习的,而不是二进制分类(匹配或不匹配)。正如最近的论文所提出的那样;(2)我们证明了这种方法的性能远远超过了同步任务上现有的基线;(3)我们使用学习嵌入来进行视觉语音重新处理。自我监督中的认知,并表明绩效与所学的表示相匹配,以完全监督的方式端到端。
1,介绍
对自我监督学习的兴趣越来越大,这比过去几年流行的完全监督方法有很大的优势,因为这种方法可以c在互联网上免费提供的大量数据上,不需要人工注释。
这种想法的早期适应之一是关于自动编码器的工作[1];最近有一些关于通过数据估算来学习表示的工作,例如通过绘画[2]或RGB来预测上下文。只有灰度图像的图像[3]。最近,使用跨模式的自我监督被证明是特别流行的,其中监督来自于两个或两个以上的纳图之间的对应关系。集会共同发生的溪流,如声音和图像。
以前的工作特别相关的是[4],它使用一个称为SyncNet的卷积神经网络(CNN)模型来学习人脸图像序列和相应音频信号的联合嵌入。IP同步。该方法学习强大的视听功能,是有效的主动扬声器检测和唇读。[5]已经证明SyncNet的功能也可以用来实现语音和视频序列之间的动态时间对齐,用于将重新录制的语音片段与预先录制的视频同步。
最近的(并发)论文提出了使用双流结构进行源定位[6,7],交叉模态检索[6],AV同步的音频和视频表示的共同训练方法一般领域的视频中的发音和动作识别[8,9]。所有这些训练两个流网络来预测音频和视频输入是否匹配。模型是经过训练的具有对比损失[8]或作为二元分类[6,7,9]。类似的策略也被用于人脸和声音之间的交叉模态生物特征匹配[10,11]。尽管这些世界在跨模式学习任务上,KS表现出很大的前景,问题仍然是这些目标是否适合于所提出的应用,如识别和检索。
在本文中,我们提出了一种新的跨模态学习训练策略,其中我们通过多路匹配任务学习强大的跨模态嵌入..特别是,我们结合了相似之处基于y的方法(例如。L2距离损失)用于学习跨模式的联合嵌入,具有多类交叉熵损失;这样,训练目标自然适合于交叉模态检索,其中任务是在一个域中找到与另一个模态中的查询最相关的示例。我们提出了一种新的训练策略,其中网络被训练为多路匹配。没有明确的类标签的g任务,同时仍然受益于交叉熵损失的有利学习特性。
这种解决方案的有效性被证明是用于视听同步,其中的目标是找到最相关的音频片段给定一个短视频剪辑。接受过培训的模特多路匹配能够产生强大的表示听觉和视觉信息,可以应用于其他任务-我们还证明了学习嵌入显示更好的pe。与通过成对目标学习的表示相比,视觉语音识别任务的性能。
2.结构和训练
在本节中,我们描述了视听匹配任务的体系结构和训练策略,并将其与现有的最先进的视听通信方法进行了比较,包括保存网络[6]和SyncNet[4]。
2.1 主干结构
本节描述了音频和视频流的体系结构。输入和层配置与SyncNet[4]相同,因此使用新的训练s的性能。可以与现有的方法进行比较。网络摄取0.2秒的音频和视频输入片段
音频流。
音频流的输入是13维Mel频率倒谱系数(M FCCs),每10ms提取一次,帧长为25ms。因为音频数据是从视频中提取出来的,这里有自然环境因素,如背景噪声和语音失真。输入大小在时间方向为20帧,在另一个方向为13个反向系数(所以TH)。输入图像为13×20像素)。网络基于VGG-M[12]CNN模型,但滤波器大小被修改为音频输入大小,如图1(A)所示。
视频流
视觉流的输入是一个裁剪的脸的视频,分辨率为224×224,帧速率为25fps。网络同时摄取5个堆叠的RGB帧,包含视觉信息在0.2秒的时间框架内。视觉流也是基于VGG-M[12],但第一层具有5×7×7的滤波器大小,而不是常规VGG-M的7×7,以便捕获5帧上的运动信息。图1(b)中描述了详细的视觉流。
图1.音频和视觉流的主干架构
2.2.训练策略
目的是利用自我监督学习音频和视觉信息的跨模态嵌入。这两个基线被训练为一个成对的对应任务,而拟议的则是方法设置为多路匹配任务。
基线-SyncNet
最初的SyncNet[4]是用一个对比损失来训练的,这是为了最大限度地扩大非匹配输入对的特征之间的距离,并最小化匹配对的距离。.非匹配对的音频和视频是从同一个人脸轨道采样的,但来自不同的时间点。该方法需要手动调整裕度超参数。
基线-AVE-Net
为跨模态检索而设计的视听嵌入网络(AVE-Net)[6]也将音频和视频网络的输出作为输入。输入向量被归一化,然后在通过一个完全连接层和一个Softmax层之前,计算了两个归一化嵌入之间的欧式距离。完全连接的层本质上学习th保留的距离,上面的特征被认为是不对应的。
提出----多途径分类
与以往使用成对损失的方法不同,所提出的嵌入是通过多路匹配任务在这里学习的。由于成对损失只用于二进制匹配,所以它们不使用context信息。然而,多路匹配策略不仅控制着对之间的距离,而且还利用序列数据之间的相关信息来训练模型。学习的呼声从视觉流中获取一个输入特性和从音频流中获取多个特性。这可以设置为任何N路特征匹配任务..音频和视频之间的欧几里得距离特征被计算,导致N个距离。然后,在经过一个softmax层后,对网络进行交叉熵损失训练,使其相似性为间匹配对大于非匹配对。图2概述了这里描述的培训战略。
所有的N个音频帧都是从与视频剪辑相同的人脸轨道采样的,但只有一个与视频剪辑及时对应。这是为了迫使网络学习正在说的内容,而不是身份或其他话语特征。采样策略如图3所示。
3.实验
在本节中,我们将所提出的系统的性能与现有的唇同步方法和相关的视听应用进行了比较。
图2.现有培训战略与拟议培训战略的比较。
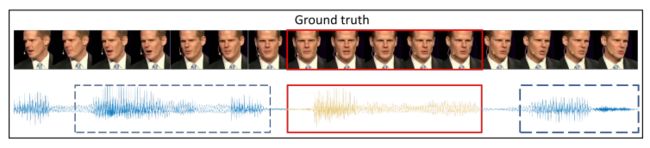
图3.自我监督学习的抽样策略。红色矩形突出显示与上面的谈话面相对应的音频段,蓝色虚线矩形显示不匹配的音频片段.
3.1.影音同步
音频到视频同步可以看作是一个跨模式的检索任务,其中时间偏移是通过从一个集合中选择一个音频段来找到的,给定一个视频段..这是由computi完成的学习视频功能(从5帧窗口)和一组音频功能之间的距离。我们假设当特征之间的距离最小时,这两个流是同步的。H然而,正如[4]所表明的,一个视觉特征可能不足以确定正确的偏移,因为并不是所有的样本都包含鉴别信息-例如,可能有一些5帧视频。没有说什么的片段。因此,我们还对超过5个视频帧的上下文窗口进行了实验,在这种情况下,我们平均跨越多个视频样本的距离(wi)。时间步长为1帧)。
数据集
该网络是在LIP阅读句子2(LRS2)[13]数据集的训练前集上训练的。该LRS2数据集包含96,318个用于培训的剪辑和1,243个用于测试。在t之间有一个折衷由于训练网络需要较长的视频剪辑,所以需要N个课程(或候选音频功能)的数量和可供训练的视频剪辑的数量具有较大的N(候选音频剪辑被采样,没有重叠)。为了找到最优值,我们进行了不同N值的实验,并报告了Avai的精度和数量。图4中的视频剪辑。

图4.按N的同步化精度
评估协议
任务是在±15帧窗口内确定正确的同步,如果预测的偏移量在地面真相的1个视频帧内,则确定同步是正确的.因此,随机预测的准确率为9.7%。由于存在非信息帧,我们还使用平均distan计算不同数量的输入视觉帧上的同步偏移输入长度K>5的特征之间的CES。

表1.同步精度。#帧:平均距离的视觉帧数。

图5.结构的TC-5唇读网络..
结果
实验结果是用表1中N=40训练的网络,所提出的方法的性能远远超过了以成对目标训练的基线。特别是,对于#帧=5(即。没有超越接受领域的语境),有一个意义同步性能从75.8%提高到89.5%。
3.2.视觉语音识别
网络学习输入视频中包含的视觉信息的强大嵌入。本实验的目的是证明匹配网络所学的嵌入是有效的适用于其他应用,在这种情况下,视觉语音识别。这是在一个字级识别任务上演示的,我们比较了使用所提出的嵌入学习的性能。自我监督的方法对网络进行训练,端到端有充分的监督。
数据集
我们在Wild(L RW)[14]数据集上训练和评估模型,该数据集由从英国电视中提取的单词级语音和视频片段组成。数据集有一个voca规模为500,包含超过500,000个话语,其中25,000是预留测试。
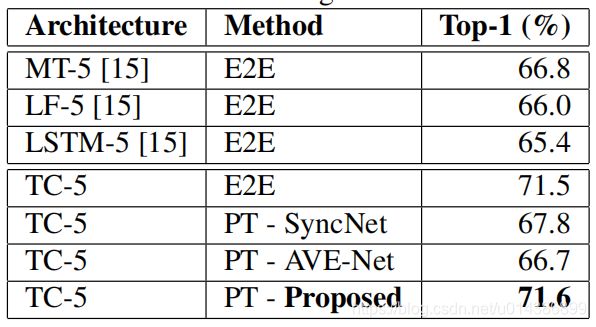
表2使用各种体系结构和训练方法进行视觉语音识别的单词精度。
架构
前端架构取自2.1节中描述的网络的可视流..我们提出了一个2层时间卷积后端,然后是500路Softmax分类la耶。这种网络结构在图5中进行了总结,并在表2中称为TC-5。“5”是指特征提取器在时间维度上的接收场,与在[15]中对网络的命名约定。当训练端到端(E2E)时,TC-5模型的性能超过了[15]中提出的网络设计。视觉特征是预先提取出来的在“预训练”实验(P T)中,只有后端层被训练为500路分类任务-特征提取器没有在充分监督下进行微调。
结果
我们在表2中报告了视觉语音识别任务的结果。将结果与现有的基于VGG-M基结构的唇读网络进行了比较,并与具有id的模型进行了比较。诱人的TC-5体系结构在大规模LRW数据集上进行了端到端的培训,并进行了全面的监控..值得注意的是,特征提取器的性能是由自我监督的metho训练的匹配端到端训练的网络,没有任何微调。
4.结论
我们提出了一种新的跨模式匹配和检索训练策略,它使网络能够在没有明确的类标签的情况下进行匹配训练,同时受益于有利的学习交叉熵损失的特征。实验结果表明,与现有的最新技术相比,在视听同步任务上表现出更好的性能。拟议的嵌入在视觉语音识别任务上,G策略也给出了显著的改进,并且性能与具有相同体系结构的完全监督方法相匹配。方法也应如此适用于其他跨模式任务。

