09_Python算法+数据结构笔记-分数背包-数字拼接-活动选择-动态规划-钢条切割
b站视频:路飞IT学城
https://www.bilibili.com/video/BV1mp4y1D7UP
文章目录
- #81 分数背包
- #82 分数背包实现
- #83 数字拼接问题
- #84 数字拼接问题实现
- #85 活动选择问题
- #86 活动选择问题实现
- #87 贪心算法总结
- #88 动态规划介绍
- #89 钢条切割问题
- #90 钢条切割问题:自顶向下实现
个人博客
https://blog.csdn.net/cPen_web
#81 分数背包
###### 背包问题
# 一个小偷在某个商店发现有N个商品,第i个商品价值Vi元,重Wi千克。他希望拿走的价值尽量高,但他的背包最多只能容纳W千克的东西。他应该拿走哪些商品?
#注:背包问题 往下细分 有2种不太一样的问题:0-1背包 和 分数背包
# ·0-1背包:对于一个商品,小偷要么把它完整拿走,要么留下。不能只拿走一部分,或把一个商品拿走多次。(商品为金条)
# ·分数背包:对于一个商品,小偷可以拿走其中任意一部分。(商品为金砂)
### 举例
# 商品 1:V1=60 W1=10 1千克 6块钱
# 商品 2:V2=100 W2=20 1千克 5块钱
# 商品 3:V3=120 W3=30 1千克 4块钱 降序
# 背包容量:W=50
# 对于0-1背包和分数背包,贪心算法是否都能得到最优解?为什么?
#注:怎么贪心?算单位重量的商品 分别值多少钱,先把单位重量的 更贵的 先拿走,然后如果包里还有地方 拿剩下的
#注:这个贪心算法 对于 分数背包 一定是 最优的 ,生活常识。包一定是满的,一点都不剩
#注:对于0-1背包,贪心的来做,拿走的价值是 160 (商品1和商品2 都拿走),是最好的吗?不是最好的,比如 只拿商品1和商品2
#注:显然 0-1背包,不能用贪心算法来做。因为 分数背包装的时候,最后肯定是满的,但是 0-1背包不一定,按贪心算法来拿 最后可能剩下很多容量
#82 分数背包实现
goods = [(60, 10), (100, 20), (120, 30)] # 每个商品元组表示 (价格,重量)
goods.sort(key=lambda x: x[0] / x[1], reverse=True) # 按照单位价格降序排列
def fractional_backpack(goods, w): # 参数 商品、w背包重量
# 贪心拿商品,拿单位重量更值钱的商品,所以先对goods进行排序
m = [0 for _ in range(len(goods))] # m表示每个商品拿多少,存结果的
total_v =0 # 存结果的 拿走的总价值
for i, (price,weight) in enumerate(goods):
if w >= weight:
m[i] = 1 # 这个商品拿多少。拿1整个,或者小数
total_v += price # 更新拿走的 价值
w -= weight # 并更新w的值 (背包重量)
else:
m[i] = w / weight
total_v += m[i] * price # 更新拿走的 价值
w = 0 # 背包满了
break
return total_v, m # 最后返回 存结果的m、total_v
print(fractional_backpack(goods, 50))
#结果为
# (240.0, [1, 1, 0.6666666666666666])
#注:背包问题,贪心算法,先拿单位重量里最值钱的
#83 数字拼接问题
###### 拼接最大数字问题 (面试经常问)
# 切有N个非负整数,将其按照字符串拼接的方式拼接为一个整数。 如何拼接可以使得得到的整数最大?
# 例:32,94,128,1286,6,71可以拼接的最大整数为 94716321286128
#注:按照字符串比较的方式 来排序(先比首位,首位大的最大,首位一样的 再往后走……直到有一个最大,那个最大;或者直到有 一个有 一个没有,没有的最大)
# (整数比较:32和6,32大;字符串比较:32和6,6大)
#注:128 和 1286 怎么排?(2个数拼接)
# 1286128 1281286,1286128大
# 7286728 7287286,7287286大
#注:这个问题怎么解决?贪心的去做,贪头位。但是一个串长、一个串短,并且短串还是长串的子串 (128\1286) 怎么办?
#------------------------------
a = "96" # a和b长度一样时,表达式没问题
b = "87"
a + b if a>b else b + a
#------------------------------
a = "128"
b = "1286"
a + b = "1281286" # 长度一样
b + a = "1286128" # b + a 大
a + b if a+b>b+a else b+a # 这样写
#---------
a = "728"
b = "7286"
a + b = "7287286"
b + a = "7286728"
#------------------------------
#84 数字拼接问题实现
from functools import cmp_to_key # 传一个老式的cmp函数,转换成1个key函数
li = [32, 94, 128, 1286, 6, 71]
# Python2的cmp函数 传2个参数的一个函数,然后根据比较函数返回它们的比较结果 (xy返回1)
def xy_cmp(x, y): # 写的cmp函数
if x+y < y+x:
return 1 # x>y 让大的去前面 x和y交换,因为默认小数在前面
elif x+y > y+x:
return -1
else:
return 0
def number_join(li):
li = list(map(str, li)) # 把数字变成字符串
# 接下来 对li 进行一个排序(2个值对比 做交换) 94在最前面
# li.sort(cmp=lambda x,y: ) # Python2的cmp函数 传2个参数的一个函数,然后根据比较函数返回它们的比较结果 (xy返回1)
li.sort(key=cmp_to_key(xy_cmp)) # 执行后 li已经是排好序的了
return "".join(li) # 返回字符串
print(number_join(li))
# 结果为 94716321286128
#注:li.sort(key=cmp_to_key(xy_cmp)) 看不懂的话,可以写个快排或者冒泡,冒泡:看2个元素是否交换,看a+b>b+a 还是 a+b#85 活动选择问题
###### 活动选择问题 (贪心算法)
# ·假设有n个活动,这些活动要占用同一片场地,而场地在某时刻只能供一个活动使用。
# ·每个活动都有一个开始时间Si和结束时间fi(题目中时间以整数表示),表示活动在[Si, Fi)区间占用场地。 #注:Fi这一刻 它不占用,避免问题
# ·问:安排哪些活动能够使该场地举办的活动的个数最多?

#注:11个活动,
# Si 开始时间,
# fi 结束时间,
# 怎么安排?贪心的问题
### 贪心结论:最先结束的活动一定是最优解的一部分。 贪最早的点,接下来在剩下的 贪 最早的点……
#注:第一个结束的活动,一定在最优解里面
#注:最早结束,后面剩的时间越长
### 证明:假设a是所有活动中最先结束的活动,b是最优解中最先结束的活动。
# 如果a=b,结论成⽴。
# 如果a≠b,则b的结束时间⼀定晚于a的结束时间,则此时用a替换掉最优解中的b,a⼀定不与最优解中的其他活动时间重叠,因此替换后的解也是最优解。
#注:为什么 a⼀定不与最优解中的其他活动时间重叠? 因为a比b结束的早 那些活动都在b后面,所以不重叠
#86 活动选择问题实现
activities = [(1,4), (3,5), (0,6), (5,7), (3,9), (5,9), (6,10), (8,11), (8,12), (2,14), (12,16)] # 活动,1个元组表示1个活动.开始时间、结束时间
# 保证活动是按照结束时间排好序的。 因为 贪心 是贪 最早结束的活动,排好序后 直接选第一个
activities.sort(key=lambda x:x[1]) # 按结束时间排序
def activity_selection(a): # 传参a 活动
res = [a[0]] # 最后返回的结果,一开始肯定有a[0]活动,a[0]是最早结束的
#接下来 按照结束时间往后看,是否与前面时间冲突,不冲突 加进去
for i in range(1,len(a)): # 从1 开始,因为a[0] 已经进去了
# 如果a[i]活动的开始时间>=res最后一个活动的结束时间
if a[i][0] >= res[-1][1]: # 当前活动的开始时间大于等于最后一个入选活动的结束时间
# 不冲突
res.append(a[i])
return res
print(activity_selection(activities))
#结果为 [(1, 4), (5, 7), (8, 11), (12, 16)] 4个活动,一定是最大的
活动选择问题 -- 精简代码
activities = [(1,4), (3,5), (0,6), (5,7), (3,9), (5,9), (6,10), (8,11), (8,12), (2,14), (12,16)]
# 保证活动是按照结束时间排好序的
activities.sort(key=lambda x:x[1])
def activity_selection(a):
res = [a[0]]
for i in range(1, len(a)):
if a[i][0] >= res[-1][1]: # 当前活动的开始时间小于等于最后一个入选活动的结束时间
# 不冲突
res.append(a[i])
return res
print(activity_selection(activities))
#结果为 [(1, 4), (5, 7), (8, 11), (12, 16)]
#87 贪心算法总结
#贪心算法4个例子:找零问题、背包问题、拼接数字、活动选择
#注:知道按什么来贪心
#注:4个问题 公共特点:
# 首选 都是 最优化问题 (什么什么什么 最多、最少、最大、最小)
# 不是所有最优化问题,都能用贪心算法来做, 比如背包问题中的0-1背包,贪心 不是最优的,这类问题 可以用动态规划做
#注:贪心算法 代码比较好写,思路比较简单,速度比较快
#注:比如活动选择问题,不用贪心,穷举所有情况,需要穷举很多情况 ,n个活动 要看2**n 种方案。但是贪心算法 代码复杂度 O(n)级别,很快
#88 动态规划介绍
#注:动态规划 是种思想,在各个算法领域都有深入研究:基因测序、基因比对、序列的相似程度、hmm……,很多问题 都可以用动态规划解决
###### 从斐波那契数列看动态规划
# ·斐波那契数列:Fn = Fn-1 + Fn-2 #注:递推式
# ·练习:使用递归和非递归的方法来求解斐波那契数列的第n项
#注:斐波拉契数列:后一项是前2项的和
#注:递归写法
# 子问题的重复计算
def fibnacci(n):
if n == 1 or n == 2: # 终止条件
return 1
else:
return fibnacci(n-1) + fibnacci(n-2) # 递归条件
print(fibnacci(10))
#结果为 第5项斐波拉契数列
# 55
#注:第100项斐波拉契数列 用递归写法 时间很长很长。数不大,但是计算机很慢,为什么?
#原因:子问题的重复计算,递归执行效率低
# f(6) = f(5) + f(4)
# f(5) = f(4) + f(3)
# f(4) = f(3) + f2)
# f(4) = f(3) + f(2)
# ………… #注:相同的问题算了很多遍
# f(3) = f(2) + f(1)
# f(3) = f(2) + f(1)
# f(2) = 1
非递归方法, 动态规划(DP)的思想 = 最优子结构(递推式) + 重复子问题
def fibnacci_no_recurision(n):
f = [0,1,1] # 下标是1的第一项是1,下标是2的第二项是1
if n > 2:
for i in range(n-2): # 求第n项,往里追加,追加n-2次 (求n=3,追加1次;求n=4,追加2次)
num = f[-1] + f[-2] # 算这个数,再append到f里去。这个数 = f最后一项 + f倒数第2项
f.append(num)
return f[n] # 因为按照下标来的 所以第n项就是f[n]
print(fibnacci_no_recurision(100))
#结果为 354224848179261915075
#注:虽然这个数很大,但是运算很快
#注:为什么递归方法很慢?
#注:因为递归执行效率低。为什么递归执行效率低?
#注:子问题的重复计算
#注:为什么 不用递归 算的比递归快
#注:因为把之算过的问题 存到了列表里,只需要调用就行了 加一次。
#注:因为 不递归的 写法里 ,避免 子问题的重复计算,所以效率比 递归写法 高一点
#注:不是说 所有的递归 慢问题 都是因为 子问题的重复计算
#注:DP思想 = 最优子结构(递推式) + 重复子问题
#注:不想用递归来做,所以用循环方式,把需要的子问题 存起来,只算一遍,后边的值从列表里取这个值
#Python里 取巧方法,递归函数前加装饰器 @lru_cache,就能自动缓存重复子问题的
@functools.lru_cache
精简代码
# 子问题的重复计算 #注:递归写法
def fibnacci(n):
if n == 1 or n == 2:
return 1
else:
return fibnacci(n-1) + fibnacci(n-2)
# 动态规划(DP)的思想 = 递推式 + 重复子问题
def fibnacci_no_recurision(n): #注:DP思想
f = [0,1,1]
if n > 2:
for i in range(n-2):
num = f[-1] + f[-2]
f.append(num)
return f[n]
print(fibnacci_no_recurision(100))
#结果为
# 354224848179261915075
#89 钢条切割问题
###### 钢条切割问题
# ·某公司出售钢条,出售价格与钢条长度之间的关系如下表:

#注:一般来说,长的钢条贵点,而且和长度不是倍数关系
# ·问题:现有一段长度为n的钢条和上面的价格表,求切割钢条方案,使得总收益最大。#注:即 卖出去的钱最多
# ·长度为4的钢条的所有切割方案如下:(c方案最优)

# ·思考:长度为n的钢条的不同切割方案有几种?
#注:2**(n-1) (2的(n-1)次方)种方案。长度为n的钢条,有n-1个切割的位置,可以切可以不切,每个位置2种选择,所以2**(n-1)种可能
#注:如果相同的结果位置不同 看成同一种方案,那么问题很难,在组合数学里叫做整数切割问题
#注:一个一个列出来 不太合理
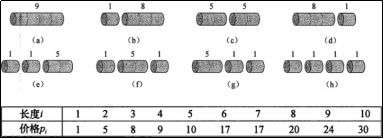
#注:r[i] 最优解,最优解,最优的情况下 能拿到多少钱
![]()
#注:长度为2时 5、1+1
#注:长度为3 8、6 不切 8块;切1刀变成2和1或1和2 但不考虑 2不管切不切 最多能卖5块钱,所以6块钱
#注:长度为4 9、10 不切 9块;切1刀 3和1 不管3切不切这个问题 给个3价格是8,所以9块;切成2和2 ,2价格是5,所以 10
# ………………
#注:长度为9 不切 24块;切1刀,1和8,1+22=23 不用管8切不切;切2刀,2和7,5+18=23 不用管7切不切;3和6,17+8=25;4和5,23;5和4…………
#注:所以最后 3和6 最大,17+8=25,所以 9 最大值是25
#注:动态规划 需要 1个递推式 (即 最优子结构)
###### 钢条切割问题 -- 递椎式
# ·设⻓度为n的钢条切割后最优收益值为rn,可以得出递推式:
![]()
# ·第⼀个参数Pn表示不切割
# ·其他n-1个参数分别表示另外n-1种不同切割方案,对方案i=1,2,...,n-1
# ·将钢条切割为⻓度为i和n-i两段
# ·⽅案i的收益为切割两段的最优收益之和
#注:比如说长度为9。9 、1+8 、2+7 、……、8+1 ,这些所有情况 要一个最大值 max
# ·考察所有的i,选择其中收益最大的方案
#注:切一刀 (n-1)种方案 和 不切,每一个方案的 收益 是多少。n-1种方案的收益 和不切割的 收益 做对比,选最大值 就是结果
#注:为什么 这是对的? 最优子结构
###### 钢条切割冋题 -- 最优子结构
# 可以将求解规模为n的原问题,划分为规模更小的子问题:完成⼀次切割后,可以将产生的两段钢条看成两个独⽴的钢条切割问题。
# 组合两个子问题的最优解,并在所有可能的两段切割⽅案中选取组合收益最⼤的,构成原问题的最优解。
# 钢条切割满足最优子结构:问题的最优解由相关⼦问题的最优解组合而成,这些子问题可以独⽴求解。
#注:最优子结构:子问题的最优解 能够算大的问题的最优解
#注:切1刀,只要算 2部分的最优解,不管这2部分 怎么切的,所有方案中,取最大值max,就是最优解
#注:最优子结构 就是一个 递推式,DP中 最重要
###### 钢条切割问题 -- 最优子结构
# 钢条切割问题还存在更简单的⽅法
# 从钢条的左边切割下⻓度为i的⼀段,只对右边剩下的⼀段继续进⾏切割,左边的不再切割
# 递推式简化为
![]()
# 不做切割的⽅案就可以描述为:左边⼀段⻓度为n,收益为Pn,剩余⼀段⻓度为0,收益为r0=0。
#注:切1刀,但是左边不切了,只切右边。把右边r n-1 换成P n-1
#注:即 如果长度为9,9不切 24; 1+8 1不切的价格 + 8最优解22; 2+7 2不切的价格 + 7最优解17……
#注:左边不切,右边继续切 即左边原价,右边选择最优解
#注:为什么可以这样算?为什么这样做最简单? (即p + r)
#注:假如说 9 ,切成2 3 2 2 价格最大。
#注:在原来的 递推式里 可以看成 5 + 4 价格最大
#注:左边 5 再切成 2和3,右边 4 再切成 2和2
#注:但是 这个问题 也可以看成 2 3 2 2 ,切成 2 和 7,在 7 里面再接着切
#注:所以 递推式 看成一边切、一边不切 相当于看成 一边是左边一段,右边 可以接着切,没有漏的情况
#注:而 之前的 递推式 可能会算重复行为。如果 9 切成 2 3 2 2 最优,那么 看成 5 + 4 最优,2 + 7 最优,重复了
#注:第2个递推式,看成2 部分 ,只对 右边的 进行切割,左边不切
#90 钢条切割问题:自顶向下实现
写法1 递推式
![]()
写法2 递推式
![]()
import time
def cal_time(func):
def wrapper(*args, **kwargs):
t1 = time.time()
result = func(*args, **kwargs)
t2 = time.time()
print("%s running time: %s secs." % (func.__name__, t2 - t1))
return result
return wrapper
# 写法1
# 价格表 长度1 卖1块钱;长度2 卖5块钱
p = [0, 1, 5, 8, 9, 10, 17, 17, 20, 24, 30]
def cut_rod_recurision_1(p, n): # 参数n 钢条长度 ; p 价格表
if n == 0: # 递归 终止项 (长度0 卖 0块钱)
return 0
else: # 接下来 学会看公式
res = p[n]
for i in range(1, n): # 从1 到 n-1 的 n-1 种情况
res = max(res, cut_rod_recurision_1(p, i) + cut_rod_recurision_1(p, n-i)) # 函数是求r n 的,递归
# 每次循环 都是res自己跟另一个取最大,取完了n-1次方案,res就是所有方案中最大的那个数
return res
#注:没有问题 因为每次循环的时候 res已经取了最大值
print(cut_rod_recurision_1(p, 9))
#结果为 25
#注:第一种写法 肯定很慢:重复计算 ,而且重复计算两
# 写法2 还是递归来写,左边不切割 右边切割的式子
def cut_rod_recurision_2(p, n):
if n == 0: # 终止条件,= 0时返回0元
return 0
else:
res = 0
for i in range(1, n+1): # 递推式下标告诉了范围 从1到n
res = max(res,p[i] + cut_rod_recurision_2(p, n-i)) #p[i] 代表左边 不切割的部分,r n-i 这个函数就是求r的
# for循环完了 res就是最大值
return res
print(cut_rod_recurision_2(p, 9))
#结果为 25
#注:给递归函数 加 装饰器 ,会递归的装饰
#注:解决方法:套一层马甲 return 原函数
#注:方法1比方法2慢,因为方法1递归了2次,而且n需要算 比n小的所有子问题,子问题都会重复计算。这2个 算法 实际上复杂度很高,慢
#注:方法2 只算1个,还是会 重复子问题,最后问题会越来越细
#注:递归算法的问题 自顶向下的递归实现,会出现效率差的问题
###### 钢条切割问题 -- 自顶向下递归实现
# 为何⾃顶向下递归实现的效率会这么差?
# 时间复杂度 O(2**n)
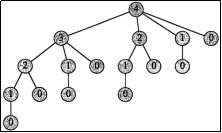
#注:那怎么办?答:动态规划的解法
###### 钢条切割问题 -- 动态规划解法
# 递归算法由于重复求解相同子问题,效率极低
# 动态规划的思想:
# 每个子问题只求解一次,保存求解结果段之后需要此问题时,只需查找保存的结果
#注:动态规划需要2点:1、最优子结构(递推式) 2、重复子问题
#注:自底向上的算 ,就不会重复求解;而 递归是 直接来r(n)来算,不好。
# 算r(1),算完存到列表里不需要重复算,算r(2)……
#注:这就是 不用递归,用 循环、迭代、动态规划的思想 解决问题
递归写法 精简代码
写法1 递推式
![]()
写法2 递推式
![]()
def cut_rod_recurision_1(p, n):
if n == 0:
return 0
else:
res = p[n]
for i in range(1, n):
res = max(res, cut_rod_recurision_1(p, i) + cut_rod_recurision_1(p, n-i))
return res
def cut_rod_recurision_2(p, n):
if n == 0:
return 0
else:
res = 0
for i in range(1, n+1):
res = max(res, p[i] + cut_rod_recurision_2(p, n-i))
return res