Datax入门使用
DataX入门使用
一、简介
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。Datax将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
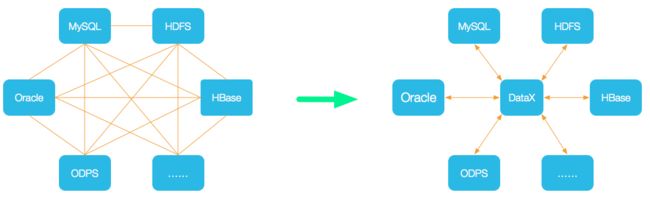
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。

Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图,详情请点击:DataX数据源参考指南
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | √ | 读 、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| Phoenix5.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Hive | √ | √ | 读 、写 | |
| Cassandra | √ | √ | 读 、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| TSDB | √ | √ | 读 、写 |
二、DataX核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。
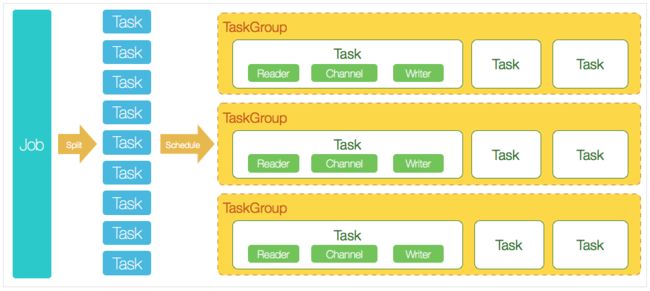
核心模块介绍:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
三、DataX的使用
3.1、下载datax
-
方法一、直接下载DataX工具包:DataX下载地址
下载后解压至本地某个目录,进入bin目录,即可运行同步作业:
$ cd {YOUR_DATAX_HOME}/bin $ python datax.py {YOUR_JOB.json} -
方法二、下载DataX源码,自己编译:DataX源码
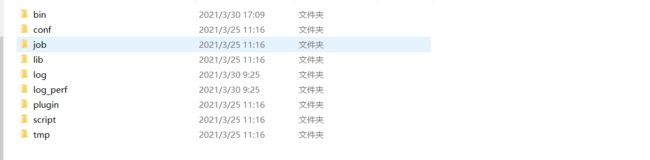
3.2、datax的目录结构
-
bin目录下是pytho脚本文件,主要用来执行job文件(默认需要依赖Python2的环境,也可以修改为Python3)
-
conf目录存放一些配置文件
-
job目录下存放了一个job测试文件(我们通过datax-web生成的临时job文件不会放在这里,而是在data-web里边自己配置存放目录)
-
lib是依赖的一些jar包
-
log目录存放job文件的执行日志
-
plugin目录存放的是对不同数据源读取(Reader)和写入(Writer)的插件支持
如果没有在plugin目录下发现自己需要的Reader或者Writer则需要自己手动安装(比如ES的Reader和Writer)。
四、使用Datax执行job文件
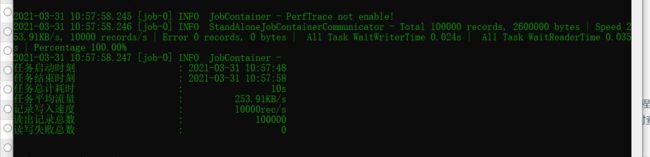
job文件是一个JSON格式的文件,每一个job文件都代表一个同步任务,执行job文件需要使用bin目录datax.py脚本。执行命令如下命令执行job任务:
python datax.py job文件
如果出现控制台乱码在控制台输入:CHCP 65001,再次执行就不会乱码
![]()
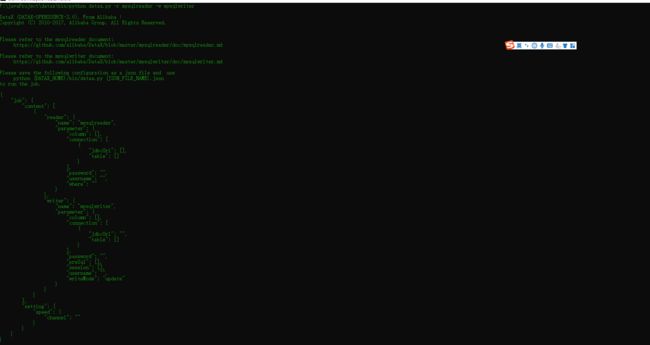
一个Json格式的Job文件模板如下(Mysql为例):
{
"job": {
"setting": {
"speed": {
"channel": 3,
"byte": 1048576
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "yRjwDFuoPKlqya9h9H2Amg==",
"password": "6YrK4y3NaUxccEgnoAz8yA==",
"column": [
"`id`",
"`course_id`",
"`chapter_id`",
"`title`",
"`video_source_id`",
"`video_original_name`",
"`sort`",
"`play_count`",
"`is_free`",
"`duration`",
"`status`",
"`size`",
"`version`",
"`gmt_create`",
"`gmt_modified`"
],
"where": "gmt_modified >= ${lastTime} and gmt_modified < ${currentTime}",
"splitPk": "",
"connection": [
{
"table": [
"edu_video"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/education_edu?serverTimezone=Asia/Shanghai&useLegacyDatetimeCode=false&useSSL=false&nullNamePatternMatchesAll=true&useUnicode=true"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"username": "yRjwDFuoPKlqya9h9H2Amg==",
"password": "6YrK4y3NaUxccEgnoAz8yA==",
"writeMode": "update",
"column": [
"`id`",
"`course_id`",
"`chapter_id`",
"`title`",
"`video_source_id`",
"`video_original_name`",
"`sort`",
"`play_count`",
"`is_free`",
"`duration`",
"`status`",
"`size`",
"`version`",
"`gmt_create`",
"`gmt_modified`"
],
"connection": [
{
"table": [
"edu_video"
],
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/datax_web?serverTimezone=Asia/Shanghai&useLegacyDatetimeCode=false&useSSL=false&nullNamePatternMatchesAll=true&useUnicode=true"
}
]
}
}
}
]
}
}
主要包括三部分
settingreaderwriter
如要查看不同数据源的reader和writer的写法可以参照官网或者执行以下命令
# 查看mysql的reader和writer的写法
python datax.py -r mysqlreader -w mysqlwriter
五、DataX-Web
DataX Web是在DataX之上开发的分布式数据同步工具,提供简单易用的操作界面,降低用户使用DataX的学习成本,缩短任务配置时间,避免配置过程中出错。用户可通过页面选择数据源即可创建数据同步任务,RDBMS数据源可批量创建数据同步任务,支持实时查看数据同步进度及日志并提供终止同步功能,集成并二次开发xxl-job可根据时间、自增主键增量同步数据。
任务"执行器"支持集群部署,支持执行器多节点路由策略选择,支持超时控制、失败重试、失败告警、任务依赖,执行器CPU.内存.负载的监控等等。后续还将提供更多的数据源支持、数据转换UDF、表结构同步、数据同步血缘等更为复杂的业务场景。
System Requirements
- Language: Java 8(jdk版本建议1.8.201以上)
Python2.7(支持Python3需要修改替换datax/bin下面的三个python文件,替换文件在doc/datax-web/datax-python3下) - Environment: MacOS, Windows,Linux
- Database: Mysql5.7
六、Datax-web结构
- bin目录下是Linux上的一些执行安装脚本和datax-web需要的sql脚本
- doc目录下是官方文档
- datax-admin项目和datax-executor项目使我们需要启动的项目。
七、启动Datax-web项目
7.1、执行sql脚本
在mysql数据库创建项目运行所必需要的数据库文件,sql脚本在bin/db目录下
7.2、修改datax_admin下resources/application.yml文件
# 端口号
server:
port: 8080
spring:
#数据源,目前仅仅支持Mysql
datasource:
username: root
password: 'root'
url: jdbc:mysql://127.0.0.1:3306/datax_web?serverTimezone=Asia/Shanghai&useLegacyDatetimeCode=false&useSSL=false&nullNamePatternMatchesAll=true&useUnicode=true&characterEncoding=UTF-8
driver-class-name: com.mysql.jdbc.Driver
# 数据库连接池配置
hikari:
## 最小空闲连接数量
minimum-idle: 5
## 空闲连接存活最大时间,默认600000(10分钟)
idle-timeout: 180000
## 连接池最大连接数,默认是10
maximum-pool-size: 10
## 数据库连接超时时间,默认30秒,即30000
connection-timeout: 30000
connection-test-query: SELECT 1
##此属性控制池中连接的最长生命周期,值0表示无限生命周期,默认1800000即30分钟
max-lifetime: 1800000
# datax-web email 不需要可以不用配置
mail:
host: smtp.qq.com
port: 25
username: [email protected]
password: opfmjdcwbnlhefee
properties:
mail:
smtp:
auth: true
starttls:
enable: true
required: true
socketFactory:
class: javax.net.ssl.SSLSocketFactory
management:
health:
mail:
enabled: false
server:
servlet:
context-path: /actuator
mybatis-plus:
# mapper.xml文件扫描
mapper-locations: classpath*:/mybatis-mapper/*Mapper.xml
# 实体扫描,多个package用逗号或者分号分隔
#typeAliasesPackage: com.yibo.essyncclient.*.entity
global-config:
# 数据库相关配置
db-config:
# 主键类型 AUTO:"数据库ID自增", INPUT:"用户输入ID", ID_WORKER:"全局唯一ID (数字类型唯一ID)", UUID:"全局唯一ID UUID";
id-type: AUTO
# 字段策略 IGNORED:"忽略判断",NOT_NULL:"非 NULL 判断"),NOT_EMPTY:"非空判断"
field-strategy: NOT_NULL
# 驼峰下划线转换
column-underline: true
# 逻辑删除
logic-delete-value: 0
logic-not-delete-value: 1
# 数据库类型
db-type: mysql
banner: false
# mybatis原生配置
configuration:
map-underscore-to-camel-case: true
cache-enabled: false
call-setters-on-nulls: true
jdbc-type-for-null: 'null'
type-handlers-package: com.wugui.datax.admin.core.handler
# 配置mybatis-plus打印sql日志
logging:
level:
com.wugui.datax.admin.mapper: error
path: ./data/applogs/admin
#datax-job, access token
datax:
job:
accessToken:
#i18n (default empty as chinese, "en" as english)
i18n:
## triggerpool max size
triggerpool:
fast:
max: 200
slow:
max: 100
### log retention days
logretentiondays: 30
datasource:
aes:
key: AD42F6697B035B75
主要修改数据源的配置
7.3修改datax_executor下resources/application.yml文件
# web port
server:
#port: ${server.port}
port: 8081
# 日志路径
logging:
config: classpath:logback.xml
path: ./data/applogs/executor/jobhandler
datax:
job:
admin:
### datax admin address list, http://address01,http://address02",data-admin的地址
addresses: http://127.0.0.1:8080
executor:
appname: datax-executor # 创建执行器时的AppName需要和这里保持一致
ip:
port: 9999 # 执行器端口号
### job log path job文件的执行日志
logpath: ./data/applogs/executor/jobhandler
### job log retention days
logretentiondays: 30
### job, access token
accessToken:
executor:
# datax json临时文件保存路径
jsonpath: F:\javaProject\datax-web-v-2.1.2\temp\executor
#jsonpath: ${json.path}
# Datax执行文件datax.py的地址
pypath: F:\javaProject\datax\bin\datax.py
#pypath: ${python.path}
datax.job配置
- admin.addresses datax_admin部署地址,如调度中心集群部署存在多个地址则用逗号分隔,执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";
- executor.appname 执行器AppName,每个执行器机器集群的唯一标示,执行器心跳注册分组依据;
- executor.ip 默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 “执行器注册” 和 “调度中心请求并触发任务”;
- executor.port 执行器Server端口号,默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
- executor.logpath 执行器运行日志文件存储磁盘路径,需要对该路径拥有读写权限;
- executor.logretentiondays 执行器日志文件保存天数,过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
- executor.jsonpath datax json临时文件保存路径
- pypath DataX启动脚本地址,例如:xxx/datax/bin/datax.py 如果系统配置DataX环境变量(DATAX_HOME),logpath、jsonpath、pypath可不配,log文件和临时json存放在环境变量路径下。
上述准备工作做好后,运行datax_admin下 的DataXAdminApplication和运行datax_executor下 的DataXExecutorApplication
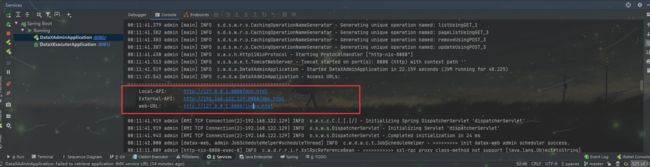
admin启动成功后日志会输出三个地址,两个接口文档地址,一个前端页面地址
注意:windows下如果控制台报错需要hadoop啥的则需要先安装hadoop的环境变量,下载地址:https://github.com/srccodes/hadoop-common-2.2.0-bin,下载成功后解压配置环境变量
如果不配置hadoop环境变量,不能生成.json格式的job任务文件

八、在web页面创建同步任务
1.执行器配置(使用开源项目xxl-job)

- 1、"调度中心OnLine:"右侧显示在线的"调度中心"列表, 任务执行结束后, 将会以failover的模式进行回调调度中心通知执行结果, 避免回调的单点风险;
- 2、“执行器列表” 中显示在线的执行器列表, 可通过"OnLine 机器"查看对应执行器的集群机器;
执行器属性说明
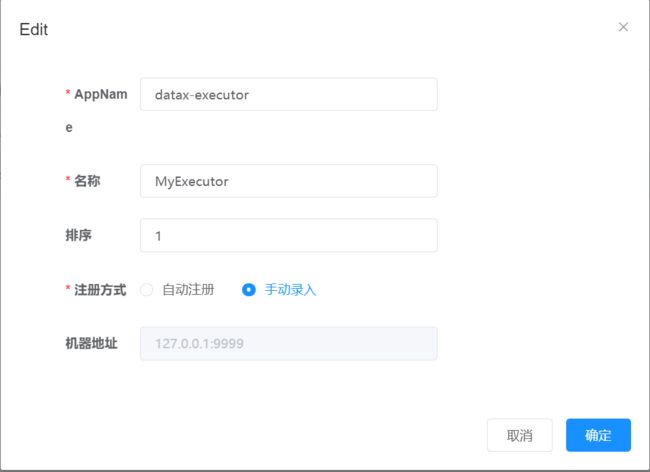
1、AppName: (与datax-executor中application.yml的datax.job.executor.appname保持一致)
每个执行器集群的唯一标示AppName, 执行器会周期性以AppName为对象进行自动注册。可通过该配置自动发现注册成功的执行器, 供任务调度时使用;
2、名称: 执行器的名称, 因为AppName限制字母数字等组成,可读性不强, 名称为了提高执行器的可读性;
3、排序: 执行器的排序, 系统中需要执行器的地方,如任务新增, 将会按照该排序读取可用的执行器列表;
4、注册方式:调度中心获取执行器地址的方式;
自动注册:执行器自动进行执行器注册,调度中心通过底层注册表可以动态发现执行器机器地址;
手动录入:人工手动录入执行器的地址信息,多地址逗号分隔,供调度中心使用;
5、机器地址:"注册方式"为"手动录入"时有效,支持人工维护执行器的地址信息;
2.创建数据源
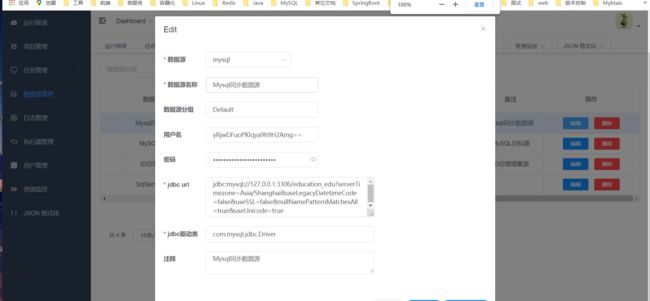
数据源就是数据库的一些连接信息
3.创建项目
4.创建任务模版
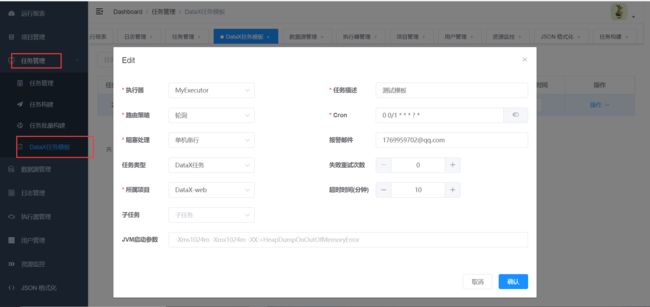
我们稍后创建的同步任务都是依据任务模板创建的,模板主要配置任务的执行器,路由策略、定时任务等,同一个模板下的任务属于同一个项目。
5. 构建JSON脚本
- 1.步骤一,步骤二,选择第二步中创建的数据源,JSON构建目前支持的数据源有hive,mysql,oracle,postgresql,sqlserver,hbase,mongodb,clickhouse 其它数据源的JSON构建正在开发中,暂时需要手动编写。

切分字段splitPk
-
描述:MysqlReader进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能。
推荐splitPk用户使用表主键,因为表主键通常情况下比较均匀,因此切分出来的分片也不容易出现数据热点。
目前splitPk仅支持整形数据切分,不支持浮点、字符串、日期等其他类型。如果用户指定其他非支持类型,MysqlReader将报错!
如果splitPk不填写,包括不提供splitPk或者splitPk值为空,DataX视作使用单通道同步该表数据。
- 2.字段映射
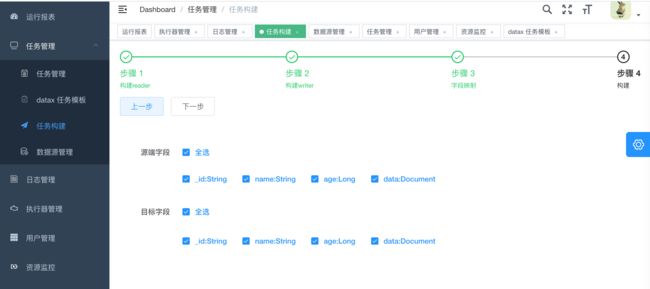
**注意:**在选择字段映射时,源端表字段的选择顺序要和目的端表字段的选择顺序一致
- 3.点击构建,生成json,此时可以选择复制json然后创建任务,选择datax任务,将json粘贴到文本框。也可以点击选择模版,直接生成任务。
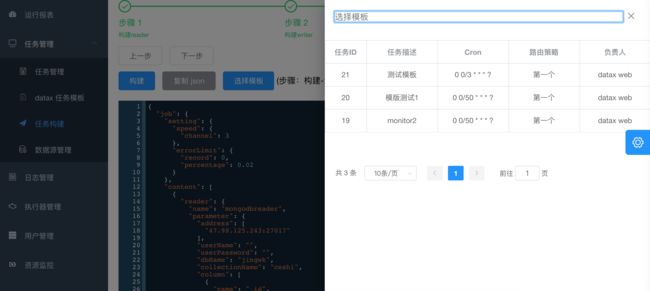
6.批量创建任务


注意:批量构建任务时,源端表和目的端表的数量要一致,需要同步的表勾选的顺序也要一致。
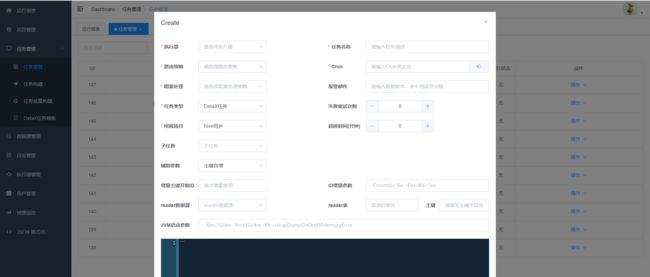
7.任务创建介绍(关联模版创建任务不再介绍,具体参考5构建JSON脚本)
DataX任务
Shell任务
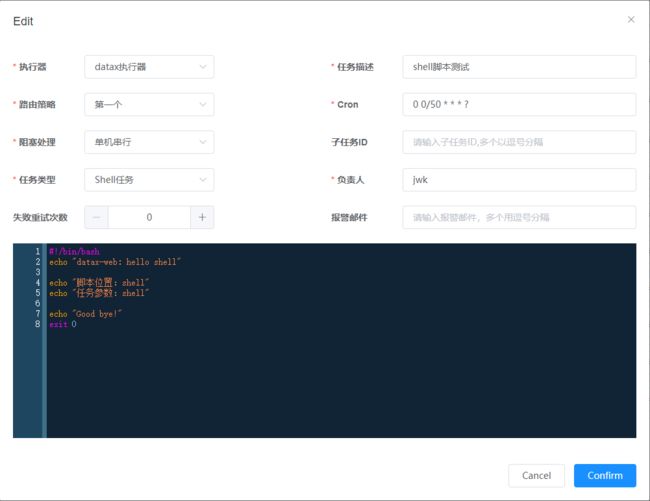
Python任务

PowerShell任务
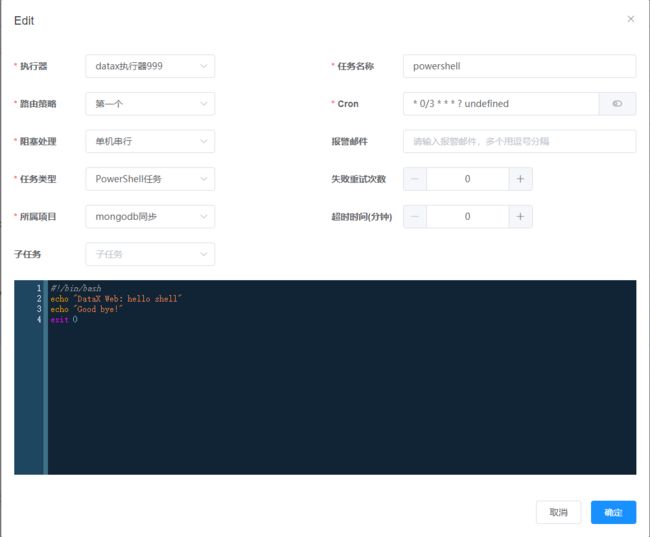
- 任务类型:目前支持DataX任务、Shell任务、Python任务、PowerShell任务;
- 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
- 单机串行:调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
- 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
- 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
- 增量增新建议将阻塞策略设置为丢弃后续调度或者单机串行
- 设置单机串行时应该注意合理设置重试次数(失败重试的次数*每次执行时间<任务的调度周期),重试的次数如果设置的过多会导致数据重复,例如任务30秒执行一次,每次执行时间需要20秒,设置重试三次,如果任务失败了,第一个重试的时间段为1577755680-1577756680,重试任务没结束,新任务又开启,那新任务的时间段会是1577755680-1577758680
8.增量更新JSON脚本任务
一、根据日期进行增量数据抽取
按下图中5个步骤进行配置

- 1.任务类型选DataX任务
- 2.辅助参数选择时间自增
- 3.增量开始时间选择,即sql中查询时间的开始时间,用户使用此选项方便第一次的全量同步。第一次同步完成后,该时间被更新为上一次的任务触发时间,任务失败不更新。增量的区间为两个时间之间的所有数据
- 4.增量时间字段,-DlastTime=‘%s’ -DcurrentTime=‘%s’ 先来解析下这段字符串
1.-D是DataX参数的标识符,必配
2.-D后面的lastTime和currentTime是DataX json中where条件的时间字段标识符,必须和json中的变量名称保持一致
3.='%s'是项目用来去替换时间的占位符,比配并且格式要完全一致
4.注意-DlastTime='%s'和-DcurrentTime='%s'中间有一个空格,空格必须保留并且是一个空格
- 5.时间格式,可以选择自己数据库中时间的格式,也可以通过json中配置sql时间转换函数来处理
一个时间增量的Json例子如下
{
"job": {
"setting": {
"speed": {
"channel": 3,
"byte": 1048576
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "yRjwDFuoPKlqya9h9H2Amg==",
"password": "6YrK4y3NaUxccEgnoAz8yA==",
"splitPk": "",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/education_edu?serverTimezone=Asia/Shanghai&useLegacyDatetimeCode=false&useSSL=false&nullNamePatternMatchesAll=true&useUnicode=true"
],
"querySql": [
"select * from edu_teacher_copy1 where gmt_modified >= ${lastTime} and gmt_modified < ${currentTime}"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"username": "yRjwDFuoPKlqya9h9H2Amg==",
"password": "6YrK4y3NaUxccEgnoAz8yA==",
"column": [
"`id`",
"`name`",
"`intro`",
"`career`",
"`level`",
"`avatar`",
"`sort`",
"`join_date`",
"`is_deleted`",
"`gmt_create`",
"`gmt_modified`"
],
"connection": [
{
"table": [
"edu_teacher_copy1"
],
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/datax_web?serverTimezone=Asia/Shanghai&useLegacyDatetimeCode=false&useSSL=false&nullNamePatternMatchesAll=true&useUnicode=true"
}
]
}
}
}
]
}
}
querySql解析
select * from edu_teacher_copy1 where gmt_modified >= ${lastTime} and gmt_modified < ${currentTime}"
- 1.此处的关键点在 l a s t T i m e , {lastTime}, lastTime,{currentTime},${}是DataX动态参数的固定格式,lastTime,currentTime就是我们页面配置中 -DlastTime=‘%s’ -DcurrentTime='%s’中的lastTime,currentTime,注意字段一定要一致。
- 2.如果任务配置页面,时间类型选择为时间戳但是数据库时间格式不是时间戳,例如是:2019-11-26 11:40:57 此时可以用FROM_UNIXTIME(${lastTime})进行转换。
select * from test_list where operationDate >= FROM_UNIXTIME(${lastTime}) and operationDate < FROM_UNIXTIME(${currentTime})
此处还有两点需要注意:
-
配置增量需要我们创建任务后,在任务管理编辑任务设置
辅助参数为时间自增,并且手动的给json文件Reader–>parameter加上querySql,也就是reader增量查询的sql,当然,简单一点可以不写querySql而直接在reader的parameter加一个where条件"where": "gmt_modified >= ${lastTime} and gmt_modified < ${currentTime}",如果使用querySql的方式需要删除掉Reader的column属性和table属性,因为我们的sql中已经指明了我们需要的字段和表
-
对于Writer我们需要设置parameter–>“writeMode”: “update”,写入模式修改为update过后,datax会对增量的数据依照主键进行判断如果目标表中已经有这条数据就是更新操作,目标表没有这条数据就是新增。默认情况下写入模式是新增和不是update,我们可以手动改Json文件也可以对源码进行修改。
writeModel控制写入数据到目标表采用
insert into或者replace into或者ON DUPLICATE KEY UPDATE语句。- insert:将数据源表的数据直接写的到目的表,主要用于全量的导入。实现原理是直接采用
insert into; - replace和update:如果目标表中包含待写入的数据则更新该行数据,主要用于增量导入。实现原理:在mysql中用
ON DUPLICATE KEY UPDATE语句,其他数据库中用replace into.
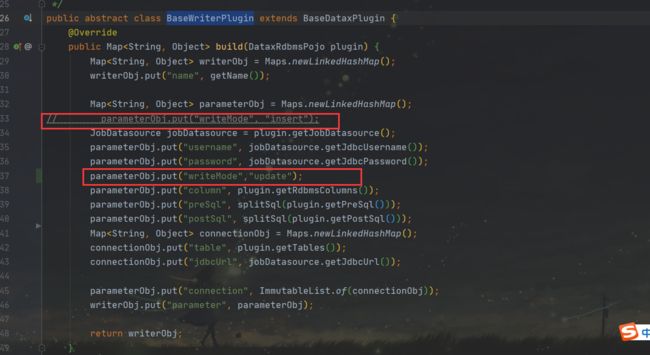
- insert:将数据源表的数据直接写的到目的表,主要用于全量的导入。实现原理是直接采用
关于ID自增增量参照官网
- 增量参数设置
- 分区参数设置
9. 任务列表
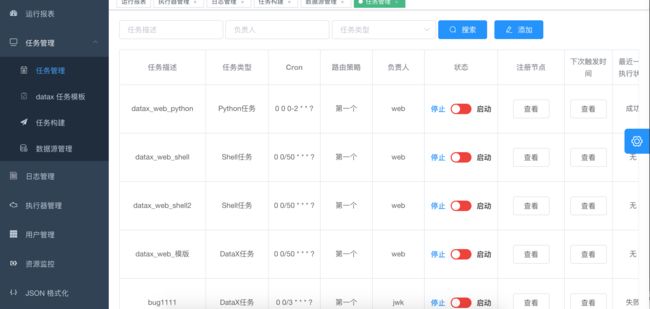
10. 可以点击查看日志,实时获取日志信息,终止正在执行的datax进程
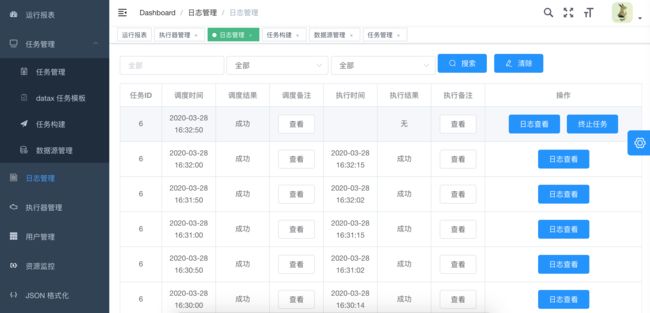
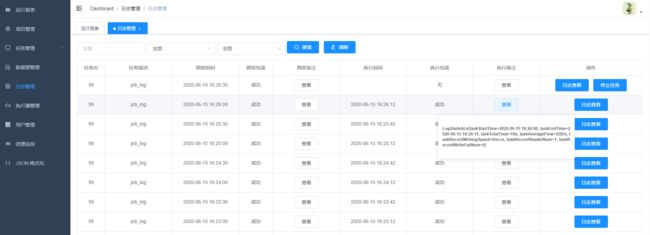
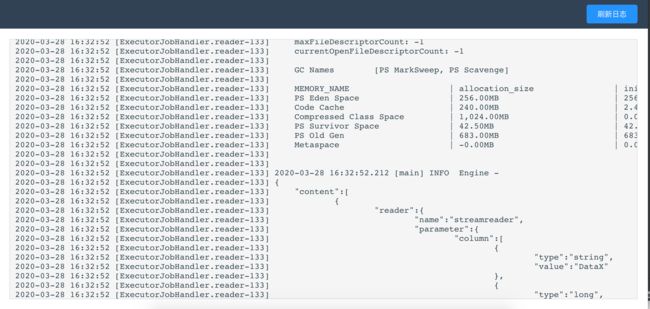
11.任务资源监控
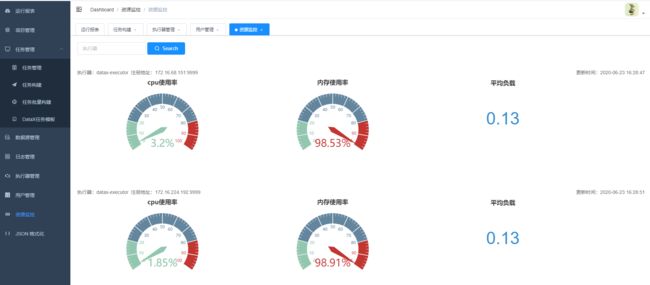
12. admin可以创建用户,编辑用户信息

关于更详细文档可以参照官网或者doc目录下的文档