DataX初入门
目录
关系型数据库拉取到Hive:
mongo到hive
Sqoop存在局限性,只能在关系型数据库到hadoop(Hive)之间导数据,如果有noSql的场景怎么解决?
我们用阿里开源的产品DataX来解决。目前开源版本为dataX3。
进入阿里github仓库拉取源码进行编译:注意匹配java和python版本问题。
我这里快速入门以官方给好的tar为例进行阐述。-->前面的页面找到quick Start点进去。
嫌麻烦-点我直接下载dataX.tar.gz
关系型数据库拉取到Hive:
1-首先:在Hive中创建一张表(目标表)
CREATE TABLE shop_dt0329 (
`date` varchar(10),
`room_id` int,
`fanself_pay_amount` bigint
)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'='\t',
'line.delim'='\n',
'serialization.format'='\t');注意,上面指定了列分隔符,行分隔符,在等会的Json文件中要体现出来。
2-创建mysql中的表:
CREATE DATABASE IF NOT EXISTS fordatax;
USE fordatax;
CREATE TABLE IF NOT EXISTS shop_dt0701(`date` VARCHAR(10),room_id INT,fanself_pay_amount INT);
INSERT INTO `fordatax`.`shop_dt0701`(`date`,`room_id`,`fanself_pay_amount`) VALUES ( '2019-07-01','45','45');
insert into `fordatax`.`shop_dt0701`(`date`,`room_id`,`fanself_pay_amount`) values ( '2019-07-01','34','233');
insert into `fordatax`.`shop_dt0701`(`date`,`room_id`,`fanself_pay_amount`) values ( '2019-07-01','34','85');
3-编写Json配置文件fortest.json:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"*"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://spark01:3306/fordatax"
],
"table": [
"shop_dt0701"
]
}
],
"password": "hive",
"username": "hive"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "date",
"type": "VARCHAR"
},
{
"name": "room_id",
"type": "INT"
},
{
"name": "fanself_pay_amount",
"type": "INT"
}
],
"compress": "gzip",
"defaultFS": "hdfs://spark01",
"fieldDelimiter": "\t",
"fileName": "shop_dt0701",
"fileType": "text",
"path": "/user/hive/warehouse/test.db/shop_dt0701",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "2"
}
}
}
}
4,开始执行任务
python ${DATAX_HOME}/datax.py fortest.json
建议首次解压之后,进入bin目录下,执行以下命令已检查datax
python bin/datax.py job/job.json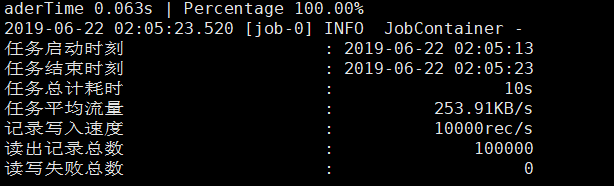
以上参考
BabyFish13的DataX安装部署及小试
mongo到hive
同上面,先创建hive表,在创建mogodb的数据库和collecrtion。上面关系型数据库的列,对应着mongodb里面collection的field。不重复造轮子了。量化投资的文章。
DataX的执行流程参考-简书网友晴天哥_374的文章-https://www.jianshu.com/p/b10fbdee7e56
感谢阿里开源的DataX~