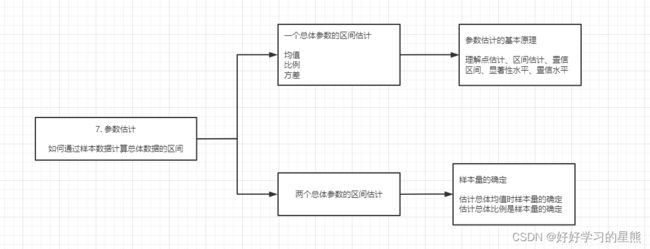
如何根据样本估计总体的均值、比例与方差?如何进行参数估计及选择对应公式?
本章内容:
- 相关专业名词解释
- 如何估计一个总体参数的范围,及如何选择对应的公式?
- 如何估计两个总体参数的范围,及如何选择对应的公式?
- 如何确定总体估计时需要的样本量?
7.1 涉及的专业名词解释
7.1.1 估计量与估计值_名词解释
参数估计
用样本统计量去估计总体的参数。
估计量
用来估计总体参数的统计量称为估计量,用 θ ^ \hat{\theta} θ^表示。样本均值、样本比例、样本方差都可以是一个估计量。
估计值
根据一个具体的样本计算出来的估计量的数值,称为估计值。比如用样本量计算出来的平均值作为总体的平均值,那么这个平均值在这时就称为估计值。
7.1.2 点估计与区间估计
excel中计算指定概率对应的面积公式:=normsinv(指定的概率)
例:当显著性为5%时, Z α / 2 = n o r m s i n v ( 1 − 5 % 2 ) = n o r m s i n v ( 0.975 ) Z_{\alpha/2}=normsinv(1-\frac{5\%}{2})=normsinv(0.975) Zα/2=normsinv(1−25%)=normsinv(0.975)
点估计
用样本统计量 θ ^ \hat{\theta} θ^的某个取值直接作为总体参数 θ \theta θ的估计值。比如用样本均值 x ˉ \bar{x} xˉ,作为总体均值 μ \mu μ的估计值。
在重复抽样条件下,点估计的均值可望等于总体真值。
由于样本是随机的,抽出一个具体的样本得到的估计值很可能不同于总体真值,所以在使用点估计代表总体参数值时,需要给出点估计值的可靠性,即说明点估计值与总体参数的真实值的接近程度。
由于点估计值的可靠性由抽样标准误差衡量,所以具体的点估计值无法给出估计可靠性的度量,故需要围绕点估计值构造总体参数的一个区间,这是区间估计。
区间估计
给出总体参数估计的一个区间范围,该区间通常由样本统计量加减估计误差得到。
与点估计不同,区间估计时,根据样本统计量的抽样分布可以对样本统计量与总体参数的接近程度给出一个概率度量。
置信区间
样本统计量所构成的总体参数的估计区间称为置信区间,其中区间的最小值称为置信下限,最大值称为置信上限。
可以理解为假设在需要估计GMV,估计的正确率需要达到95%,在95%的概率下计算出来GMV处于[100,101],得出的这个区间就是置信区间。
置信水平
置信区间中包含总体参数真值的次数所占的比例称为置信水平,也称为置信度,表示为 1 − α 1-\alpha 1−α,其中 α \alpha α表示错误率,也称为显著性水平。
可以理解为参数估计的正确率,如上述GMV例子中的95%。
样本量、置信水平与置信区间的关系
当样本量给定时,置信区间的宽度随着置信水平的增大而增大;
当置信水平固定时,置信区间的宽度随着样本量的增大而减小,即较大的样本所提供的有关总体的信息更多。
对置信区间的理解,有3点需注意:
-
怎么理解置信水平为95%的置信区间?
如果用某种方法构造的所有区间中有95%的区间包含总体样本的真值,5%的区间不包含总体参数的真值,那么用该方法构造的区间称为置信水平为95%的置信区间。 -
置信区间会因为样本不同而不同;
总体参数的真值是固定的、未知的,而样本构造的区间是不固定的。所以置信区间是一个随机区间,会因为样本的不同而不同,而且不是所有的区间都包含总体参数的真值。 -
置信水平是针对随机区域而言的;
不是用来描述某个特定区间包含总体参数真值的可能性。
比如某班级学生平均考试成绩置信水平为95%的置信区间为[60,80],不能说60~80分以95%的概率包含全班学生平均考试的真值。我们只知道在多次抽样中,95%的样本得到的区间包含全班学生平均考试成绩的真值。
7.1.3 评价估计量的标准
无偏性
样本期望与总体参数无偏,即估计量抽样分布的数学期望等于被估计量总体参数;
设总体参数为 θ \theta θ,样本的估计量为 θ ^ \hat{\theta} θ^,如果 E ( θ ^ ) = θ E(\hat{\theta})=\theta E(θ^)=θ,则称 θ ^ \hat{\theta} θ^为 θ \theta θ的无偏估计。
当样本均值的期望值等于总体均值,样本比例的期望值等于总体比例,那么样本方差的期望值等于总体误差。
有效性
更小标准差的估计量更有效;对同一总体参数的两个无偏估计量,有更小标准差的估计量更有效。
一致性
估计量与总体一致;随着样本量的增大,估计量的值越来越接近被估总体的参数,即样本量越大,标准差应该越小
7.2 如何估计一个总体参数的范围,及如何选择对应的分布公式?
总体思路:
根据样本和总体数据集的情况,以及需要求的参数是什么,来选择不同的分布公式。将指标带入公式计算,则得到总体的参数估计量。
比如:想通过样本数据集,求总体的均值是多少。如果样本数据集是大样本,则选择Z分布的公式;如果是小样本,则需要看总体的方差是否已知,如果总体方差不可得,则选择t分布的公式。
☑️ 对不同的参数进行估计,对应选择的不同分布
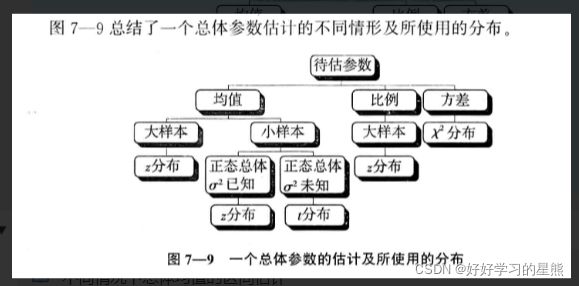
7.2.1 如何对总体均值的区间进行估计?
不同情况下总体均值的区间估计公式

z分布区间计算的excel公式:
=avg(样本值)±normsinv(1-$\alpha/ 2 ) ∗ 标 准 差 / 2)*标准差/ 2)∗标准差/\sqrt{样本数量}$
估计总体均值,等于样本均值±给定显著性水平下的面积*标准差/样本数量开平方。即样本均值±均值估计误差
excel中,t分布的临界值公式:=tinv(a,df),其中a为对应与双尾t分布的概率,df为自由度。
例如求 t α / 2 t_{\alpha/2} tα/2,其中a=0.05,则公式为:=tinv(0.05,20)
☑️ 总体均值区间估计的考虑因素:
- 总体是否为正态分布
- 总体方差是否已知
- 估计量的样本是大样本(n≥30)还是小样本(n<30)
情况一: 正态分布, σ 2 \sigma^2 σ2已知;总体不是正态分布,大样本
样本均值 x ˉ \bar{x} xˉ的抽样分布均为正态分布, E ( x ˉ ) = μ E(\bar{x})=\mu E(xˉ)=μ, D ( x ˉ ) = σ 2 n D(\bar{x})=\frac{\sigma^2}{n} D(xˉ)=nσ2,样本经过标准化以后的随机变量服从标准正态分布:
z = x ˉ − μ σ / n ∼ N ( 0 , 1 ) z=\frac{\bar{x}-\mu}{\sigma/\sqrt{n}}\sim{N(0,1)} z=σ/nxˉ−μ∼N(0,1)
根据以上条件,再加上正态分布的性质,可以得出总体均值 μ \mu μ在 1 − α 1-\alpha 1−α置信水平下的置信区间为:
x ˉ ± z α / 2 σ n \bar{x}\pm z_{\alpha/2}\frac{\sigma}{\sqrt{n}} xˉ±zα/2nσ
α \alpha α称为显著性水平,也就是错误率;
1 − α 1-\alpha 1−α称为置信水平;
z α / 2 z_{\alpha/2} zα/2是当显著性水平为 α / 2 \alpha/2 α/2时的总体面积;
σ n \frac{\sigma}{\sqrt{n}} nσ是总体标准误差;
z α / 2 σ n z_{\alpha/2}\frac{\sigma}{\sqrt{n}} zα/2nσ是估计总体均值时的估计误差;
情况二: 正态分布, ∗ ∗ σ 2 **\sigma^2 ∗∗σ2未知;总体不是正态分布,大样本**
样本均值 x ˉ \bar{x} xˉ的抽样分布均为正态分布, E ( x ˉ ) = μ E(\bar{x})=\mu E(xˉ)=μ,使用样本方差 s 2 s^2 s2代替总体方差 σ 2 \sigma^2 σ2,样本经过标准化以后的随机变量服从标准正态分布:
z = x ˉ − μ s / n ∼ N ( 0 , 1 ) z=\frac{\bar{x}-\mu}{s/\sqrt{n}}\sim{N(0,1)} z=s/nxˉ−μ∼N(0,1)
根据以上条件,再加上正态分布的性质,可以得出总体均值 μ \mu μ在 1 − α 1-\alpha 1−α置信水平下的置信区间为:
x ˉ ± z α / 2 s n \bar{x}\pm z_{\alpha/2}\frac{s}{\sqrt{n}} xˉ±zα/2ns
α \alpha α称为显著性水平,也就是错误率;
1 − α 1-\alpha 1−α称为置信水平;
z α / 2 s n z_{\alpha/2}\frac{s}{\sqrt{n}} zα/2ns是估计总体均值时的估计误差;
情况三: 正态分布, σ 2 \sigma^2 σ2未知,小样本
样本均值 x ˉ \bar{x} xˉ的抽样分布均为正态分布, E ( x ˉ ) = μ E(\bar{x})=\mu E(xˉ)=μ,样本均值经过标准化以后的随机变量则服从自由度为(n-1)的t分布:
t = x ˉ − μ s / n ∼ t ( n − 1 ) t=\frac{\bar{x}-\mu}{s/\sqrt{n}}\sim{t(n-1)} t=s/nxˉ−μ∼t(n−1)
根据以上条件,再加上正态分布的性质,可以得出总体均值 μ \mu μ在 1 − α 1-\alpha 1−α置信水平下的置信区间为:
x ˉ ± t α / 2 s n \bar{x}\pm t_{\alpha/2}\frac{s}{\sqrt{n}} xˉ±tα/2ns
α \alpha α称为显著性水平,也就是错误率;
1 − α 1-\alpha 1−α称为置信水平;
t α / 2 t_{\alpha/2} tα/2是自由度为(n-1)时,t分布中右侧面积为 α / 2 \alpha/2 α/2时的t值;
t分布
类似正态分布的一种对称分布,通常比正态分布平坦和分散,一个特定的t分布依赖于称之为自由度的参数。随着自由度的增大,t分布逐渐趋于正态分布。
7.2.2 如何对总体比例的区间进行估计?
本章内容的前提条件:
此节只讨论大样本情况的总体比例的估计问题。
对于总体比例的估计,确定样本是否足够大的一般经验规则是:
区间 p ± 2 p ( 1 − p ) / 2 p\pm2\sqrt{p(1-p)/2} p±2p(1−p)/2中不包含0或1,或者要求np≥5和n(1-p)≥5
总体比例 π \pi π 已知时:
由样本比例p的抽样分布可知,当样本量足够大时,样本比例p的抽样分布可用正态分布近似。p的数学期望为 E ( p ) = π E(p)=\pi E(p)=π;p的方差为 σ p 2 = π ( 1 − π ) n \sigma_p^2=\frac{\pi(1-\pi)}{n} σp2=nπ(1−π)。
样本比例经标准化后的随机变量服从标准正态分布,公式如下:
z = p − π π ( 1 − π ) / n ∼ N ( 0 , 1 ) z=\frac{p-\pi}{\sqrt{\pi(1-\pi)/n}}\sim{N(0,1)} z=π(1−π)/np−π∼N(0,1)
总体比例 π \pi π在 1 − α 1-\alpha 1−α置信水平下的置信区间为:
p ± z α / 2 π ( 1 − π ) n p\pm z_{\alpha/2}\sqrt{\frac{\pi(1-\pi)}{n}} p±zα/2nπ(1−π)
总体比例 π \pi π 未知时:
如果 π \pi π未知,需要用样本比例p来代替 π \pi π,这时置信区间为:
p ± z α / 2 p ( 1 − p ) n p\pm z_{\alpha/2}\sqrt{\frac{p(1-p)}{n}} p±zα/2np(1−p)
案例:估算总体比例的置信区间

7.2.3 如何对总体方差的区间进行估计?
本节内容前提条件
此节只讨论正态总体方差的估计问题。
excel中, χ 2 \chi^2 χ2分布概率计算公式为:=chiinv(概率,自由度)
χ 2 \chi^2 χ2分布与总体方差区间估计公式
根据样本方差的抽样分布可知,样本方差服从自由度为n-1的 χ 2 \chi^2 χ2分布。
在给定显著性水平 α \alpha α, χ 2 \chi^2 χ2分布构造的总体方差 σ 2 \sigma^2 σ2的置信区间如下图所示:
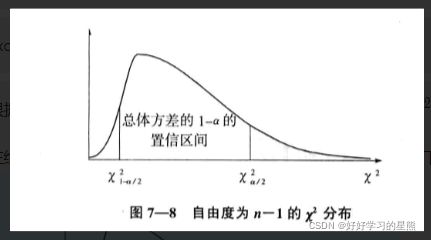
由于 ( n − 1 ) s 2 σ 2 ∼ χ 2 ( n − 1 ) \frac{(n-1)s^2}{\sigma^2}\sim{\chi^2(n-1)} σ2(n−1)s2∼χ2(n−1),故可得:
χ 1 − α / 2 2 ≤ ( n − 1 ) s 2 σ 2 ≤ χ α / 2 2 \chi_{1-\alpha/2}^2\le{\frac{(n-1)s^2}{\sigma^2}}\le{\chi_{\alpha/2}^2} χ1−α/22≤σ2(n−1)s2≤χα/22
从而推导出总体方差的置信区间为:
( n − 1 ) s 2 χ α / 2 2 ≤ σ 2 ≤ ( n − 1 ) s 2 χ 1 − α / 2 2 \frac{(n-1)s^2}{\chi_{\alpha/2}^2}\le{\sigma^2}\le{\frac{(n-1)s^2}{\chi_{1-\alpha/2}^2}} χα/22(n−1)s2≤σ2≤χ1−α/22(n−1)s2
7.3 如何估计两个总体参数的区间范围,及如何选择对应的分布公式?
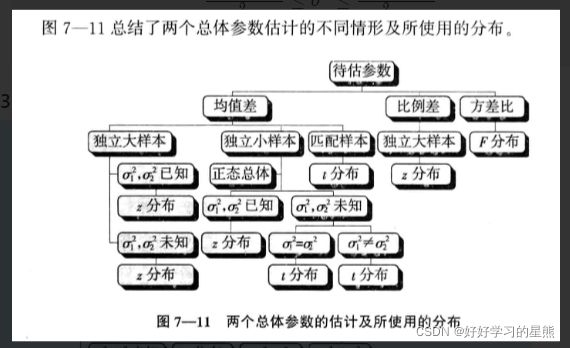
7.3.1 如何估计两个总体的均值之差的区间范围?
情况一:独立大样本时
如果两个样本是从两个总体中独立抽取,且两个总体都为正态分布;或两个总体不服从正态分布,但两个样本都是大样本(n≥30)。
其中总体均值为 μ 1 \mu_1 μ1、 μ 2 \mu_2 μ2;样本均值为 x ˉ 1 \bar{x}_1 xˉ1、 x ˉ 2 \bar{x}_2 xˉ2。
那么两个样本均值之差 x ˉ 1 − x ˉ 2 \bar{x}_1-\bar{x}_2 xˉ1−xˉ2的抽样分布服从期望值为 ( μ 1 − μ 2 ) (\mu_1-\mu_2) (μ1−μ2)、方差为 ( σ 1 2 n 1 + σ 2 2 n 2 ) (\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}) (n1σ12+n2σ22)的正态分布。
两个样本均值之差经标准化后服从标准正态分布,即
z = ( x ˉ 1 − x ˉ 2 ) − ( μ 1 − μ 2 ) σ 1 2 n 1 + σ 2 2 n 2 ∼ N ( 0 , 1 ) z=\frac {(\bar{x}_1-\bar{x}_2)-(\mu_1-\mu_2)} {\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}} \sim{N(0,1)} z=n1σ12+n2σ22(xˉ1−xˉ2)−(μ1−μ2)∼N(0,1)
当两个总体的方差 σ 1 2 \sigma_1^2 σ12、 σ 2 2 \sigma_2^2 σ22已知时,两个总体均值之差在 1 − α 1-\alpha 1−α的置信水平下,置信区间为:
( x ˉ 1 − x ˉ 2 ) ± z α / 2 σ 1 2 n 1 + σ 2 2 n 2 (\bar{x}_1-\bar{x}_2)\pm z_{\alpha/2}{\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}} (xˉ1−xˉ2)±zα/2n1σ12+n2σ22
当两个总体的方差 σ 1 2 \sigma_1^2 σ12、 σ 2 2 \sigma_2^2 σ22未知时,可用样本方差 s 1 2 s_1^2 s12、 s 2 2 s_2^2 s22来代替,两个总体均值之差在 1 − α 1-\alpha 1−α的置信水平下,置信区间为:
( x ˉ 1 − x ˉ 2 ) ± z α / 2 s 1 2 n 1 + s 2 2 n 2 (\bar{x}_1-\bar{x}_2)\pm z_{\alpha/2}{\sqrt{\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2}}} (xˉ1−xˉ2)±zα/2n1s12+n2s22
情况二:独立小样本时
当样本都为小样本时,需要假定:
1) 两个总体都服从正态分布
2) 两个随机样本独立地分别抽自两个总体
当两个总体方差未知但相等时,即 σ 1 2 = σ 2 2 \sigma_1^2=\sigma_2^2 σ12=σ22,可以将两个样本的数据组合在一起,给出总体方差的合并估计量 s p 2 s_p^2 sp2,公式为
s p 2 = ( n 1 − 1 ) s 1 2 + ( n 2 − 1 ) s 2 2 n 1 + n 2 − 2 s_p^2=\frac{(n_1-1)s_1^2+(n_2-1)s_2^2} {n_1+n_2-2} sp2=n1+n2−2(n1−1)s12+(n2−1)s22
这时,两个样本均值之差标准化后服从自由度为 ( n 1 + n 2 − 2 ) (n_1+n_2-2) (n1+n2−2)的t分布,公式为:
t = ( x ˉ 1 − x ˉ 2 ) − ( μ 1 − μ 2 ) s p 1 n 1 + 1 n 2 ∼ t ( n 1 + n 2 − 2 ) t=\frac{(\bar{x}_1-\bar{x}_2)-(\mu_1-\mu_2)} {s_p\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}} \sim{t(n_1+n_2-2)} t=spn11+n21(xˉ1−xˉ2)−(μ1−μ2)∼t(n1+n2−2)
两个总体均值之差在 1 − α 1-\alpha 1−α的置信水平下的置信区间为:
( x ˉ 1 − x ˉ 2 ) ± t α / 2 ( n 1 + n 2 − 2 ) s p 2 ( 1 n 1 + 1 n 2 ) (\bar{x}_1-\bar{x}_2)\pm t_{\alpha/2}(n_1+n_2-2) \sqrt{ s_p^2(\frac{1}{n_1}+\frac{1}{n_2}) } (xˉ1−xˉ2)±tα/2(n1+n2−2)sp2(n11+n21)
当两个总体方差未知且不相等时,两个样本均值之差经标准化后近似服从自由度为 v v v的t分布,自由度 v v v的计算公式为:
v = ( s 1 2 n 1 + s 2 2 n 2 ) 2 ( s 1 2 / n 1 ) 2 n 1 − 1 + ( s 2 2 / n 2 ) 2 n 2 − 1 v=\frac{ (\frac{s_1^2}{n_1} +\frac{s_2^2}{n_2})^2 }{ \frac{(s_1^2/n_1)^2}{n_1-1} +\frac{(s_2^2/n_2)^2}{n_2-1} } v=n1−1(s12/n1)2+n2−1(s22/n2)2(n1s12+n2s22)2
两个总体均值之差在 1 − α 1-\alpha 1−α的置信水平下的置信区间为:
( x ˉ 1 − x ˉ 2 ) ± t α / 2 ( v ) s 1 2 n 1 + s 2 2 n 2 (\bar{x}_1-\bar{x}_2)\pm t_{\alpha/2}(v) \sqrt{ \frac{s_1^2}{n_1} +\frac{s_2^2}{n_2} } (xˉ1−xˉ2)±tα/2(v)n1s12+n2s22
情况三:匹配样本时
由于独立样本的潜在弊端,可以使用匹配样本,即一个样本中的数据与另一个样本中的数据相对应。
举例:
独立样本时,每种方法随机指派12个工人,可能会将技术较差的12个工人指定给方法1,技术较好的工人指定给方法2,这种不公平的指派可能会掩盖两种方法组装产品所需时间的真正差异。
匹配样本时,先指定12个工人用第一种方法,然后再让这12个工人用第二种方法,这样得到的数据就是匹配数据。
匹配样本可以消除由样本指定的不公平造成的两种方法组装时间上的差异。
大样本条件下,均值之差 μ d = μ 1 − μ 2 \mu_d=\mu_1-\mu_2 μd=μ1−μ2,在 1 − α 1-\alpha 1−α置信水平下的置信区间为:
d ˉ ± z α / 2 σ d n \bar{d}\pm {z_{\alpha/2}\frac{\sigma_d}{\sqrt{n}}} dˉ±zα/2nσd
d表示两个匹配样本对应数据的差值, d ˉ \bar{d} dˉ表示各个差值的均值;
σ d \sigma_d σd表示各差值的标准差。
当 σ d \sigma_d σd未知时,可用样本差值的标准差 s d s_d sd来代替。
小样本条件下,假定总体各观察值的配对差服从正态分布。
在 1 − α 1-\alpha 1−α置信水平下的置信区间为:
d ˉ ± t α / 2 ( n − 1 ) s d n \bar{d}\pm {t_{\alpha/2}(n-1)\frac{s_d}{\sqrt{n}}} dˉ±tα/2(n−1)nsd
7.3.2 如何估计两个总体比例之差的区间范围?
由样本比例的抽样分布可知,从两个二项总体中抽出两个独立的样本,该样本比例之差的抽样分布服从正态分布。
两个样本的比例之差经标准化后服从标准正态分布,公式为:
Z = ( p 1 − p 2 ) − ( π 1 − π 2 ) π 1 ( 1 − π 1 ) n 1 + π 2 ( 1 − π 2 ) n 2 ∼ N ( 0 , 1 ) Z=\frac{ (p_1-p_2)-(\pi_1-\pi_2) }{ \sqrt{ \frac{\pi_1(1-\pi_1)}{n_1} +\frac{\pi_2(1-\pi_2)}{n_2} }} \sim{ N(0,1) } Z=n1π1(1−π1)+n2π2(1−π2)(p1−p2)−(π1−π2)∼N(0,1)
当两个总体比例 π 1 \pi_1 π1, π 2 \pi_2 π2未知时,可用样本比例 p 1 p_1 p1, p 2 p_2 p2代替。
即两个总体比例之差 π 1 − π 2 \pi_1-\pi_2 π1−π2在 1 − α 1-\alpha 1−α置信水平下的置信区间为:
( p 1 − p 2 ) ± z α / 2 p 1 ( 1 − p 1 ) n 1 + p 2 ( 1 − p 2 ) n 2 (p_1-p_2)\pm z_{\alpha/2} \sqrt{ \frac{p_1(1-p_1)}{n_1}+\frac{p_2(1-p_2)}{n_2} } (p1−p2)±zα/2n1p1(1−p1)+n2p2(1−p2)
7.3.3 如何估计两个总体方差比的区间范围?
方差比的F分布
由于两个样本方差比的抽样分布服从 F ( n 1 − 1 , n 2 − 2 ) F(n_1-1,n_2-2) F(n1−1,n2−2)分布,因此可以用F分布来构造两个总体方差比 σ 1 2 / σ 2 2 \sigma_1^2/\sigma_2^2 σ12/σ22的置信区间。图示如下:
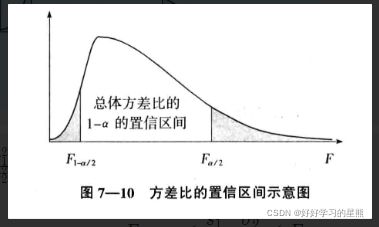
由于 s 1 2 s 2 2 ⋅ σ 2 2 σ 1 2 ∼ F ( n 1 − 1 , n 2 − 1 ) \frac{s_1^2}{s_2^2}\cdot\frac{\sigma_2^2}{\sigma_1^2} \sim{F(n_1-1,n_2-1)} s22s12⋅σ12σ22∼F(n1−1,n2−1),故可以用它来代替F,公式为:
F 1 − α / 2 ≤ s 1 2 s 2 2 ⋅ σ 2 2 σ 1 2 ≤ F α / 2 F_{1-\alpha/2} \le{\frac{s_1^2}{s_2^2}\cdot\frac{\sigma_2^2}{\sigma_1^2}} \le{F_{\alpha/2}} F1−α/2≤s22s12⋅σ12σ22≤Fα/2
由上式可得,两个总体方差比在 1 − α 1-\alpha 1−α置信水平下的置信区间为:
s 1 2 / s 2 2 F α / 2 ≤ σ 1 2 σ 2 2 ≤ s 1 2 / s 2 2 F 1 − α / 2 \frac{s_1^2/s_2^2}{F_{\alpha/2}} \le{\frac{\sigma_1^2}{\sigma_2^2}} \le{\frac{s_1^2/s_2^2}{F_{1-\alpha/2}}} Fα/2s12/s22≤σ22σ12≤F1−α/2s12/s22
其中, F α / 2 F_{\alpha/2} Fα/2和 F 1 − α / 2 F_{1-\alpha/2} F1−α/2是分子自由度为 ( n 1 − 1 ) (n_1-1) (n1−1)和分母自由度为 ( n 2 − 1 ) (n_2-1) (n2−1)的F分布的右侧面积为 α / 2 \alpha/2 α/2和 1 − α / 2 1-\alpha/2 1−α/2的分位数。
可以利用F分布求得 F 1 − α / 2 F_{1-\alpha/2} F1−α/2,公式为:
F 1 − α / 2 ( n 1 , n 2 ) = 1 F α ( n 2 , n 1 ) F_{1-\alpha/2}(n_1,n_2)=\frac{1}{F_{\alpha}(n_2,n_1)} F1−α/2(n1,n2)=Fα(n2,n1)1
n 1 n_1 n1表示分子自由度; n 2 n_2 n2表示分母自由度
7.4 如何确定总体估计时需要的样本量?
7.4.1 估计总体均值时样本量的确定
总体均值的置信区间由样本均值和估计误差两部分组成。
在重复抽样,或无限总体抽样条件下,估计误差为 z α / 2 σ n z_{\alpha/2}\frac{\sigma}{\sqrt{n}} zα/2nσ。
其中 z α / 2 z_{\alpha/2} zα/2的值和样本量n共同确定了估计误差的大小。
当确定 1 − α 1-\alpha 1−α时, z α / 2 z_{\alpha/2} zα/2就可以确定。
如果给定 z α / 2 z_{\alpha/2} zα/2和总体标准差 σ \sigma σ,就可以求得任一指定估计误差所需要的样本量,公式如下:
n = ( z α / 2 ) 2 σ 2 E 2 n=\frac{ (z_{\alpha/2})^2\sigma^2 }{ E^2 } n=E2(zα/2)2σ2
其中E代表所希望达到的估计误差。
如果 σ \sigma σ未知,可以用样本的标准差来代替;也可以用试验调查的办法,选择一个初始样本,以该样本的标准差作为 σ \sigma σ的估计值。
样本量与置信水平成正比,置信水平越大,所需的样本量也就越大;
样本量与总体方差成正比,总体的差异越大,要求的样本量也越大;
样本量与估计误差的平方成反比,即可以接受的估计误差的平方越大,所需的样本量越小。
根据公式计算出来的样本数为非整数时,通常取成较大的整数,即样本量的圆整法则。
7.4.2 估计总体比例时样本量的确定
总体均值的置信区间由样本均值和估计误差两部分组成。
在重复抽样,或无限总体抽样条件下,估计误差为 z α / 2 π ( 1 − π ) n z_{\alpha/2} \sqrt{ \frac{\pi(1-\pi)}{n} } zα/2nπ(1−π)。
其中 z α / 2 z_{\alpha/2} zα/2的值、总体比例 π \pi π、样本量n共同确定了估计误差的大小。
当确定 1 − α 1-\alpha 1−α时, z α / 2 z_{\alpha/2} zα/2就可以确定。
总体比例的值是固定的,所以估计误差由样本来确定,样本量越大,估计误差就越小,估计的精度越好。
如果给定 z α / 2 z_{\alpha/2} zα/2和总体标准差 σ \sigma σ,就可以求得任一指定估计误差所需要的样本量,公式如下:
n = ( z α / 2 ) 2 π ( 1 − π ) E 2 n=\frac{ (z_{\alpha/2})^2\pi(1-\pi) }{ E^2 } n=E2(zα/2)2π(1−π)
其中E代表所希望达到的估计误差,大多数情况下,E<0.10
如果 π \pi π未知,可以用类似样本的比例来代替;也可以用试验调查的办法,选择一个初始样本,以该样本的比例作 π \pi π的估计值。
当 π \pi π无法知道时,通常取使 π ( 1 − π ) \pi(1-\pi) π(1−π)最大时的0.5。
书籍:《统计学(第六版)》
书籍作者:贾俊平
思维导图