何以动摇Fine-tune?一文综述Prompt Tuning发展
【专栏:前沿进展】2021年,Prompt Tuning已经成为NLP领域一大重点研究方向。不久前,CMU博士刘鹏飞发表了相关综述文章,在业界引起讨论。清华大学副教授刘知远认为:「Prompt Tuning也许会是深度学习时代的Feature Engineering问题,如何给各大任务设计合理的Prompts将会是很有意思的科学问题」。
本文是针对Prompt Tuning领域发展的综述介绍,包括其原理和内涵、构建Prompts的方法,Prompt Tuning的优势,以及为何其会动摇Fine-Tuning的原因。本文观点来源于刘鹏飞的报告。
整理:牛梦琳
审编:刘鹏飞、戴一鸣

在传统自然语言处理(NLP)任务中,完全监督学习长期扮演着核心角色,但随着预训练语言模型(PLM)的发展,这种完全监督的范式发挥的作用越来越小,“Pre-train + Fine-tune”逐渐成为新的研究模式。
自2018年以来,预训练模型的体量不断增大,如T5、GPT-3、悟道等,大模型成为NLP领域一项非常重要的技术突破。同时,预训练模型Fine-tune过程中所需的硬件和数据需求也在不断增长,丰富的下游任务也使得预训练和微调阶段的设计更为复杂。
如何在“大模型”的时代快速高效地进行研究,就成为我们面临的新问题。近来,Prompt Tuning的新型范式正在成为新的技术趋势。
01
什么是Prompt
前段时间,CMU的刘鹏飞等人发表了一篇关于Prompting的综述(原文链接:https://arxiv.org/pdf/2107.13586.pdf)。在这篇论文中,原本的“Pre-train + Fine-tune”范式,被“Pre-train, Prompt, and Predict”范式所取代。原本需要预训练模型根据下游任务调整的形式,被替换成了调整下游任务以适应预训练模型的方法,成为一种预训练-精调的新形式。
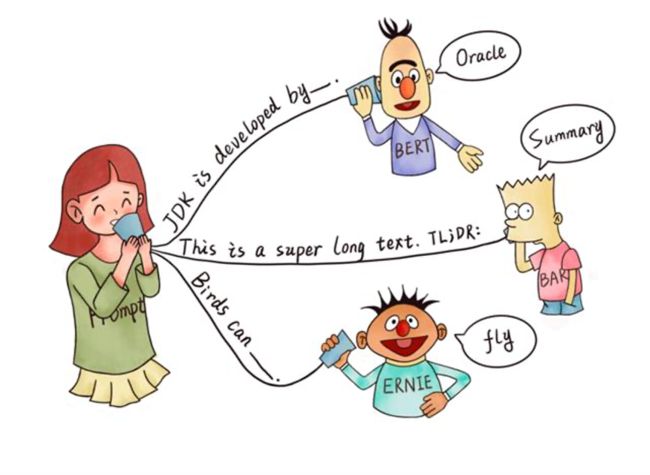
在NLP领域,“Prompt”是将人为的规则给到预训练模型,使模型可以更好地理解人的指令的一项技术,可以简单理解为给任务的输入加入补充文本,以便更好地利用预训练模型。
例如,在文本情感分类任务中,输入为"I love this movie.",希望输出的是"positive/negative"中的一个标签。可以设置一个Prompt,形如:"The movie is ___",然后让模型用来表示情感状态的答案(label),如“fantastic”、“boring”等,将空补全,最后再将答案转化成情感分类的标签(positive/negative)作为输出。
这样,通过设置合适的Prompt,我们可以控制模型预测输出,一个完全无监督训练的预训练模型可以被用来解决各种各样的下游任务。
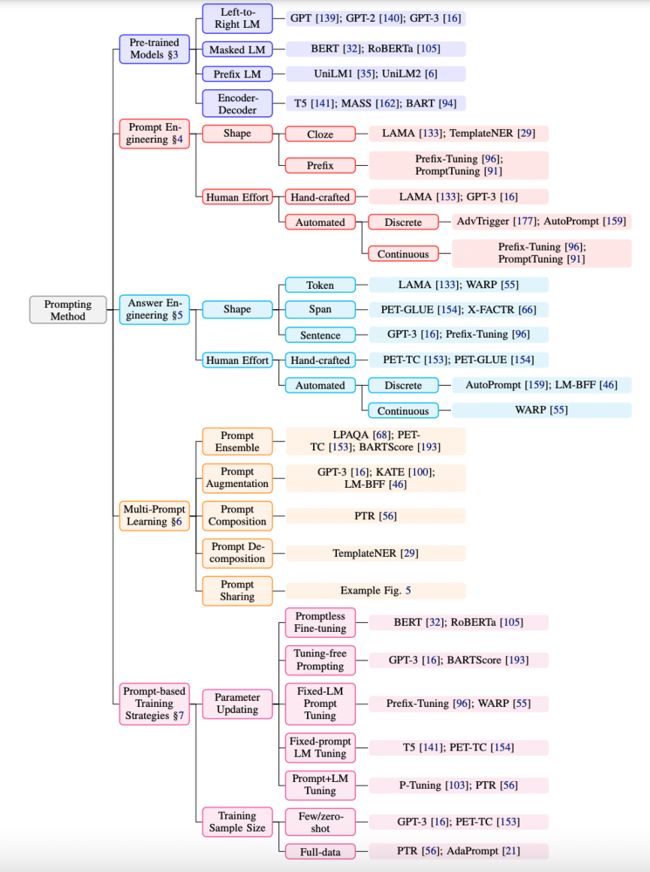
图注:Prompting方法一览
02
使用Prompt Tuning解决问题的流程
1. 构建Prompt
代入前文所述的例子,x = "I love this movie."。首先,设计一个Prompt模板(Prompt Template): Overall it was a [z] movie,在实际研究中,[z]是需要模型进行填充的空位,[z]的位置和数量决定了Prompt的类型。例如,根据[z]位置的不同,可以将prompt分为cloze prompt([z]在句中)和prefix prompt([z]在句末)。具体选择哪一种则取决于任务形式和模型类别。
至于Prompt模板的选择,大致可以分为手工设计模板和自动学习模板两大类。自动学习类别下又包含离散Prompt和连续Prompt两类。离散Prompt主要包括:Prompt Mining、Prompt Paraphrasing、Gradient-based Search、Prompt Generation、LM Scoring;连续Prompt包括Prefix Tuning和Hybrid Tuning。
2. 构建Answer
所谓的Answer,指的是表示情感的答案。在上述案例中,可以是“fantastic”、“boring”等。构建答案空间(Answer Space)能够重新定义任务的目标,使任务从输出“positive”或“negative”标签转变成选择恰当的词汇填空,使情感分类任务转变为语言模型构建任务。此时的关键在于如何定义标签空间(Label Space)与答案空间(Answer Space)之间的映射。
构建答案空间同样需要选择合适的形式和方法。在Prompt Learning中,答案有Token、Span、Sent三种形式;从答案空间是否有边界的角度,又可分为bounded和unbounded两种;在选择方法上,同样可以分为人工选择和自动学习两种方式。
3. 预测Answer
要进行预测,首先需要预先选择预训练语言模型。在实际应用中,可以根据现有的预训练模型的不同特点进行适配,不同类型的预训练模型适配不同的prompt,比如Left-to-right LM适合搭配prefix-prompt等。
当模型选择好之后,为了使当前的Prompt框架(framework)能够支撑更多的下游任务,可以考虑进行范式的拓展,例如,将之前的Single-Prompt设计拓展成Multi-Prompt,使模型能够更加灵活地解决更多的下游任务。
4. 匹配答案与标签
最后,为了得到最终的输出(output),还需要根据之前定义好的映射,将预测到的Answer与实际任务中的Label匹配。
根据应用场景的不同,还需要从数据和参数的角度对整体策略进行调整。从数据角度,需要考虑到应用场景是zero-shot、few-shot还是Full-data;从参数角度,则需要考虑不同的Tuning策略,包括对模型参数的处理,对Prompt参数的处理等等,来匹配相应的场景。
03
Prompt Tuning的优势有哪些
1. Prompt Tuning本身的优势
首先,Prompt Tuning使得几乎所有NLP任务都可以被看作语言模型任务而不是生成任务。这可以更好地利用预训练模型,使不同的任务之间都有所联系,实现更深层次的参数共享;其次,几乎所有NLP任务都能够放在zero-shot情境下处理,不再需要训练样本;同时,目前不少研究表明Prompt在few-shot情景下的性能也更好。
2. Prompting vs. Fine-Tuning

实际上,Prompting可以细分出许多不同的Tuning策略,比如根据应用场景的不同,决定是否需要Prompting、Prompting是否存在参数、参数是否可调等等。
与一般的Fine-Tuning相比,Prompt Tuning将Prompt加入到微调过程中,并且可以做到只对Prompt部分的参数进行训练,同时保证整个预训练模型的参数固定不变,这种灵活性是一般的Fine-tuning无法做到的。所以后来不少学者开始进行“Adaptor Tuning”的研究,这也是对传统Fine-tuning的一个补充。
正如前文所说,Fine-tuning是预训练模型“迁就”下游任务,而Prompt Learning可以让任务改变,反而“迁就”预训练模型。模型因此能够完成更多不同类型的下游任务,极大地提升了预训练的效率。
3. 对现代NLP发展的贡献
引用刘鹏飞博士的观点,Prompt Tuning“剧透”了NLP发展的规律。
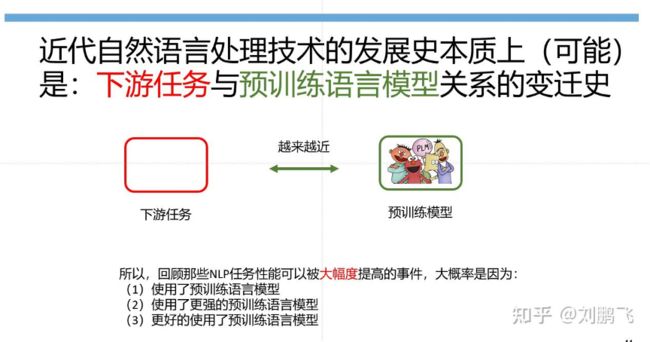
纵观近代NLP技术发展历史,不难总结出四个范式:特征挖掘、架构挖掘、目标挖掘和Prompt挖掘。在这个过程中,下游任务与预训练模型之间是越来越接近的。在传统的监督学习中,没有预训练语言模型的概念;随着神经网络技术的发展,出现了预训练模型,能够承担的任务也越来越多,越来越深入;直到Prompt技术的出现,预训练模型可以承担起更多深层次的任务,甚至包括输出层任务。
04
Prompt Tuning发展面临的挑战与未来展望
1. Prompt的设计问题
目前,由于Prompt设计上的复杂性,现有的大多数基于Prompt的工作都还围绕着文本分类或生成任务,而在信息提取和文本结构化分析任务中的应用相对较少;而设计Answer时,对于Label较多的任务,很难合理地定义二者之间的映射;并且,如何同时构建一对最佳的Prompt和Answer也是一个具有挑战性的问题。
2. Prompt的理论和实证分析
尽管Prompt方法在很多场景中取得了成功,但是目前关于Prompt-based Learning的理论分析和保证的研究成果很少,Prompt取得成果的可解释性较差;而在选择Tuning的策略上,对于选择Prompt以及调整Prompt与预训练模型参数的方法缺少可解释的权衡方式。
3. NLP研究之外贡献
Prompt Learning以自然语言为桥接,理论上可以将不同模态的信号进行连接。同时,Prompt Learning启发了人们对数据的标注、存储、检索的新思路。
作者介绍
牛梦琳,巴黎大学数学建模与机器学习方向硕士,主修傅里叶分析、高级概率论、泛函分析等。
欢迎点击阅读原文参与文章讨论。