计算机网络大杂烩
文章目录
- 计算机网络的5层结构
-
- 个人理解的5层模型的作用
- 应用层
-
- http协议
-
- 请求报文格式
-
- 请求行
- 请求头
- 请求体
- 响应报文格式
-
- 响应行
- 响应头
- 响应体
- http服务器编写实践
-
- Server
- client
- 结果
- DNS协议
-
- 域名服务器
- DNS查找方式
- https协议
-
- 密码学
-
- 对称加密
-
- 什么是对称加密
- 对称加密的工作过程
- 对称加密的优点
- 对称加密的不足
- 凯撒加密算法(最简单的对称加密)
- 非对称加密
-
- 特点
- RSA算法
- https过程概述
- 常用的网络io模型
-
- 阻塞 IO
- 非阻塞 IO
-
- 方案1
- 方案2
- IO 多路复用
-
- select
- poll
- epoll
- 传输层
-
- udp协议
-
- 协议报文
- udp编程
- tcp协议
-
- 3次握手4次挥手
- ICMP协议
计算机网络的5层结构
- 应用层(http,ftp)
- 传输层(tcp,udp)
- 网络层(ip协议)
- 数据链路层(交换机)
- 物理层(中继器,集线器)
下层协议提供服务给上层协议,如tcp提供稳定可靠的服务给到http协议。这些协议是一种通用的约定,当然你想自己创造协议是可以的,只不过造出来的服务器不认,要自己写对应协议的服务器。
个人理解的5层模型的作用
- 应用层:运输层确定了发送消息的机器(源ip),发送消息的应用(源port),接受消息的机器(目的ip),接受消息的应用(目的port)之后,我要给他什么样的消息呢?这一层定义具体数据类型
- 运输层:网络层确定了发送消息的机器(源ip),接受消息的机器(目的ip),源port和目的port是啥呢,也就是哪两个应用之间进行通信?是否需要可靠的稳定的传输?
- 网络层:我要给哪台机器通信?也就是确定源ip和目的ip,要怎么拆报文到达指定机器
- 数据链路层:
- 物理层:
应用层
主要分为cs、bs架构以及p2p架构,所有应用都是基于操作系统给与的socket系统调用实现。以下介绍常用的应用层协议。
http协议
http协议是最常用的应用层协议,是构建web应用的基石。是基于tcp协议之上实现的。
请求报文格式
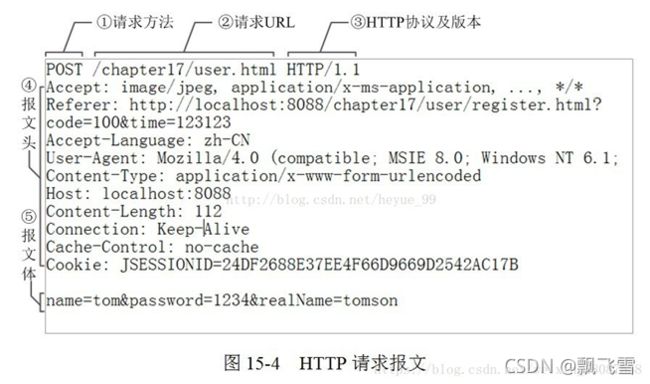
请求行
首先是http的请求行,包含3个信息:
- 请求方法:常用的为GET, POST 和 HEAD
- GET:一般用于资源的查询
- POST:一般用于增删改功能的接口
- HEAD:只返回头部信息,不反悔报文体的数据
那么GET,POST有啥区别,最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数,但是本质上他们是没有什么区别,只是协议的一个字段而已,上面的表象只是一种人为的约定,你想在GET请求的request body中塞入数据也是可以的。
-
url:定义访问路径,web服务器解析该字段确定了走哪一串代码对数据进行处理
-
http版本:有http1.0,http1.1,http2.0
- http1.0:不支持长连接,过程为tcp3次握手,客户端发起http请求,服务器http响应,4次挥手断开tcp连接。
- http1.1:和http1.0最大的突破就是支持进行长连接,只要在头部加一个 Connection: keep-alive,就能进行长连接,一个TCP连接现在可以传送多个回应,头部增加了Content-Length字段声明本次回应的数据长度,防止tcp粘包。
- http2.0:http2.0功能有了很大的丰富,主要是二进制分帧,多路复用,头信息压缩,服务器推送,具体可以看下面文章https://blog.csdn.net/yexudengzhidao/article/details/98207149
请求头
常用的请求头
| 协议头 | 说明 | 示意 |
|---|---|---|
| Connection | 客户端(浏览器)想要优先使用的连接类型 | Connection: keep-alive |
| Cookie | 客户端目前保存的cookie消息 | Cookie: $Version=1; Skin=new |
| Content-Type | 请求体的MIME类型 (用于POST和PUT请求中) | Content-Type: application/x-www-form-urlencoded |
| Content-Length | 以8进制表示的请求体的长度 | Content-Length: 348 |
更多见: https://blog.csdn.net/qq_30553235/article/details/79282113
请求体
存放请求数据,常见的有json格式数据,xml格式数据等等。
响应报文格式

响应行
常见的响应码:
100~199:表示成功接收请求,要求客户端继续提交下一次请求才能完成整个处理过程。
200~299:表示成功接收请求并已完成整个处理过程。常用200
300~399:为完成请求,客户需进一步细化请求。例如:请求的资源已经移动一个新地址、常用302(意味着你请求我,我让你去找别人),307和304(我不给你这个资源,自己拿缓存)
400~499:客户端的请求有错误,常用404(意味着你请求的资源在web服务器中没有)403(服务器拒绝访问,权限不够)
500~599:服务器端出现错误,常用500
具体地址:https://blog.csdn.net/csgarten/article/details/80600799
响应头
| 协议头 | 说明 | 示意 |
|---|---|---|
| Set-Cookie | 想要客户端保存的cookie消息 | Set-Cookie: $Version=1; Skin=new |
| Content-Type | 响应体的类型 | Content-Type: application/x-www-form-urlencoded |
| Content-Length | 响应体的长度 | Content-Length: 348 |
更多见: https://blog.csdn.net/qq_30553235/article/details/79282113
响应体
报文内容,一般网页是html数据,json数据等等
http服务器编写实践
上面也说了http协议基于tcp协议完成的,也就是说都是基于操作系统socket系统调用实现的,web服务器做的内容就是解析http协议,根据不同的uri也好头部也好,body也好进行一系列操作后返回给客户端想要的消息。
这边实现了一个最简单的http服务器,使用的是阻塞io实现,5中io模型以及实现会在下面文章中体现。
Server
import socket
class HttpRequest:
def __init__(self, data):
self.parse_data(data) # 解析http协议
def parse_data(self, data):
http_lines = data.splitlines()
# 第一行请求行
qq_line = http_lines[0].split()
self.method = qq_line[0]
self.uri = qq_line[1]
self.http_version = qq_line[2]
# 请求头
self.headers = {}
index = 1
for i in http_lines[1:]:
if i == '':
# 说明请求头部分完结
break
header = i.split(": ")
self.headers[header[0]] = header[1]
index += 1
self.body_data = ''.join(http_lines[index:])
def __str__(self):
return str(self.__dict__)
class HttpRespond:
@staticmethod
def make_resp(code, msg, headers, data):
# 制作响应行行
qq_line = " ".join(["HTTP/1.1", str(code), str(msg)])
# 制作响应头
headers_lines = []
for k, v in headers.items():
headers_lines.append(k + ": " + v)
data_lines = data
return (qq_line + "\r\n".join(headers_lines) + "\r\n\r\n" + data_lines).encode("utf-8")
def test(request):
resp = HttpRespond.make_resp(200, "OK", {'Content-Type': 'application/json'},
"The server receives the client message:%s" % (request.body_data))
return resp
route = {
"/test": {
"method": ["POST"], # 对应什么方法
"func": "test" # 对应uri访问什么函数
}
}
def begin_server(host="0.0.0.0", port=8080, buff_size=1024):
# 创建一个TCP套接字
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定ip端口号
server.bind((host, port))
print("服务器启动")
# 最多可以连接多少个客户端,排队个数
server.listen(5)
while 1:
# 阻塞等待,创建连接
con, address = server.accept() # 在这个位置进行等待,监听端口号
print("%s用户tcp连接建立" % str(address))
msg = con.recv(buff_size)
print("接收到用户请求:%s" % (msg))
try:
http_request = HttpRequest(msg.decode('utf-8'))
if route.get(http_request.uri) and http_request.method in route[http_request.uri]["method"]:
resp = eval("%s(http_request)" % (route[http_request.uri]["func"]))
else:
resp = HttpRespond.make_resp(404, "Not Found", {}, "404Not Found")
except Exception as e:
resp = HttpRespond.make_resp(500, "HTTP-Internal Server Error", {}, str(e))
print("服务器处理后响应信息:%s" % (resp))
con.send(resp)
con.close()
print("%s用户tcp连接断开" % str(address))
if __name__ == '__main__':
begin_server()
client
import requests
import json
headers = {
"Content-Type": "application/json"
}
url = "http://127.0.0.1:8080/test"
data = {
"msg": "http测试"
}
resp = requests.post(url=url, headers=headers, data=json.dumps(data))
print(resp.text)
url = "http://127.0.0.1:8080/test_2"
resp = requests.post(url=url, headers=headers, data=json.dumps(data))
print(resp.text)
结果
服务端:
服务器启动
('127.0.0.1', 12535)用户tcp连接建立
接收到用户请求:b'POST /test HTTP/1.1\r\nHost: 127.0.0.1:8080\r\nUser-Agent: python-requests/2.22.0\r\nAccept-Encoding: gzip, deflate\r\nAccept: */*\r\nConnection: keep-alive\r\nContent-Type: application/json\r\nContent-Length: 20\r\n\r\n{"msg": "http test"}'
服务器处理后响应信息:b'HTTP/1.1 200 OK\r\nContent-Type: application/json\r\n\r\nThe server receives the client message:{"msg": "http test"}'
('127.0.0.1', 12535)用户tcp连接断开
('127.0.0.1', 12536)用户tcp连接建立
接收到用户请求:b'POST /test_2 HTTP/1.1\r\nHost: 127.0.0.1:8080\r\nUser-Agent: python-requests/2.22.0\r\nAccept-Encoding: gzip, deflate\r\nAccept: */*\r\nConnection: keep-alive\r\nContent-Type: application/json\r\nContent-Length: 20\r\n\r\n{"msg": "http test"}'
服务器处理后响应信息:b'HTTP/1.1 404 Not Found\r\n\r\n\r\n404'
('127.0.0.1', 12536)用户tcp连接断开
客户端:
200 The server receives the client message:{"msg": "http test"}
404 404Not Found
这个是极简版本的而且性能最差的,很多http的功能都没有实现比如长连接Connection: keep-alive,状态码也不全只有200,404和500,只能算一个demo。
DNS协议
DNS协议是用来将域名转换为IP地址。 IP地址对于用户来说不方便记忆,但域名便于用户使用,例如www.baidu.com这是百度的域名,域名服务主要是基于UDP实现的,服务器的端口号为53。

eg :我们熟悉的,www.baidu.com
- com: 一级域名. 表示这是一个企业域名。同级的还有 “net”(网络提供商), “org”(⾮非盈利组织) 等。
- baidu: 二级域名,指公司名。
- www: 只是一种习惯用法。
域名服务器
| 分类 | |
|---|---|
| 根域名服务器 | 最高层次的域名服务器,本地域名服务器解析不了的域名就会向其求助 |
| 顶级域名服务器 | 负责管理在该顶级域名服务器下注册的二级域名 |
| 权限域名服务器 | 负责一个区的域名解析工作 |
| 本地域名服务器 | 当一个主机发出DNS查询请求时,这个查询请求首先发给本地域名服务器 |
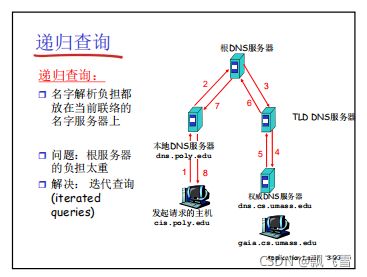
DNS查找方式
个本地DNS服务器,也称为“默认名字服务器”, 当一个主机发起一个DNS查询时,查询被送到其本地DNS服务器
起着缓存和代理的作用,将查询转发到层次结构中。

https协议
https协议在http协议之下封装了ssl协议(Secure Sockets Layer)
密码学
对称加密
什么是对称加密
对称加密就是指,加密和解密使用同一个密钥的加密方式。
对称加密的工作过程
发送方使用密钥将明文数据加密成密文,然后发送出去,接收方收到密文后,使用同一个密钥将密文解密成明文读取。
对称加密的优点
加密计算量小、速度块,适合对大量数据进行加密的场景。
对称加密的不足
- 密钥传输问题:如上所说,由于对称加密的加密和解密使用的是同一个密钥,所以对称加密的安全性就不仅仅取决于加密算法本身的强度,更取决于密钥是否被安全的保管,因此加密者如何把密钥安全的传递到解密者手里,就成了对称加密面临的关键问题。
- 密钥管理问题:再者随着密钥数量的增多,密钥的管理问题会逐渐显现出来。比如我们在加密用户的信息时,不可能所有用户都用同一个密钥加密解密吧,这样的话,一旦密钥泄漏,就相当于泄露了所有用户的信息,因此需要为每一个用户单独的生成一个密钥并且管理,这样密钥管理的代价也会非常大。
凯撒加密算法(最简单的对称加密)
凯撒算法是最简单的对称加密算法,该算法的思路是打乱26个英文字母的映射关系
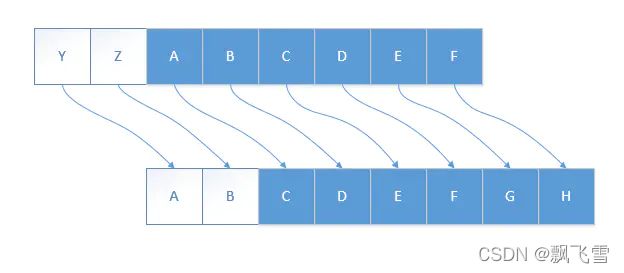
原文:abc
加密后:cde
解密后:abc
凯撒加密算法的密钥就是新的26个英文字母的映射关系
非对称加密
特点
私钥加密公钥解密或公钥加密,私钥解密。
Alice想要与Bob通信,此时Alice有自己的私钥(private_key1)并将公钥(public_key1)公布于众,Bob也有自己的私钥(private_key2)并将公钥(public_key2)公布于众。此时Alice想与Bob通信。
- Alice有一段信息message想发送给Bob,此时,他获得Bob的公钥public_key2将信息加密得到密文ciphertext。发送给Bob。
- Bob得到密文ciphertext,使用私钥private_key2获得明文。Bob此时要回信息,使用Alice的公钥public_key1加密返回信息message2为ciphertext2。
- Alice获得message2,使用私钥private_key1解密ciphertext2获取明文message2这样两边就取得了一次通信。
RSA算法
https://www.bilibili.com/video/BV14y4y1272w/?spm_id_from=autoNext
生成公钥和私钥
- 随意选择两个大的素数p和q,p不等于q,计算n = pq.
- 根据欧拉函数,求得r=φ(n)=φ§φ(q)=(p-1)(q-1).
- 选择一个小于r的整数e,且e与r互素;并求得e关于r的模反元素,命名为d.(模反元素存在,当且仅当e与r互质; 求d令ed≡1(mod r))
其中(n,e)是公钥,(n,d)是私钥
加密与解密
加密
假设A要向B发送加密信息m,他就要用B的公钥(n,e)对m进行加密,但m必须是整数且m必须小于n. 所谓加密就是计算下式的c:
m^e ≡ c (mod n)
解密
此时c就是密文,B收到密文后需要使用私钥(n,d)对其进行解密
c^d ≡ m (mod n)
因为模运算的存在,RSA算法几乎不可以进行逆向破解的,因为运算量巨大。
https过程概述
HTTPS,从字面上看,即在HTTP协议下加上一层SSL(安全套接字层 secure socket layer),对于上层应用来看,原来的发送接收数据的流程不变,这便很好的兼容了HTTP协议。
具体过程看:
https://www.bilibili.com/video/BV1M44y1175D?from=search&seid=15235278373853118737&spm_id_from=333.337.0.0
常用的网络io模型
参考:https://www.zhihu.com/question/59975081/answer/1932776593
对于计算机网络应用,最基本的功能就是处理网络请求。最典型的应用就是http框架,如java有srpingboot,python有flask。这些框架的底层原理是什么呢?这就需要聊到网络的几种常见的io模型。
我们知道所有应用层协议,都是依赖传输层协议,如tcp协议完成,思想相同,实现方法却是多种多样,这就产生了io模型,他们各有利弊,下面聊一聊最常见的3种网络io模型:
- 阻塞 IO
- 非阻塞 IO
- IO 多路复用
阻塞 IO
服务器
import socket
import threading
def deal_with_request(request):
return "ok"
def server():
print("服务端开启")
# 创建套接字
mySocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 设置IP和端口
host = '127.0.0.1'
port = 3333
# bind绑定该端口
mySocket.bind((host, port))
# 监听
mySocket.listen()
mySocket.setblocking(True)
while True:
# 接收客户端连接
print("等待连接....")
client, address = mySocket.accept()
print("新连接")
print("IP is %s" % address[0])
print("port is %d\n" % address[1])
while True:
try:
# 获取客户端得到的消息
data = client.recv(1024)
print("客户端收到消息:", data)
# 对数据进行处理,如常用的http框架会对http进行解包,然后进行业务逻辑处理如增删改查,然后将结果返回,这里使用deal_with_request函数进行处理
ret = deal_with_request(data)
# 对返回内容进行响应
client.send(ret.encode(encoding='utf-8'))
print("响应发送完成")
except Exception as e:
print(e)
break
if __name__ == '__main__':
server()
客户端
import socket
print("客户端开启")
# 创建套接字
mySocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 设置ip和端口
# host = socket.gethostname()
host = '127.0.0.1'
port = 3333
mySocket.connect((host, port)) ##连接到服务器
print("连接到服务器")
mySocket.send("hello".encode("utf-8"))
ret = mySocket.recv(1024)
print("服务器返回内容", ret)
mySocket.close()
服务器输出
服务端开启
等待连接....
新连接
IP is 127.0.0.1
port is 63530
客户端收到消息: b'hello'
响应发送完成
等待连接....
客户端输出
客户端开启
连接到服务器
服务器返回内容 b'ok'
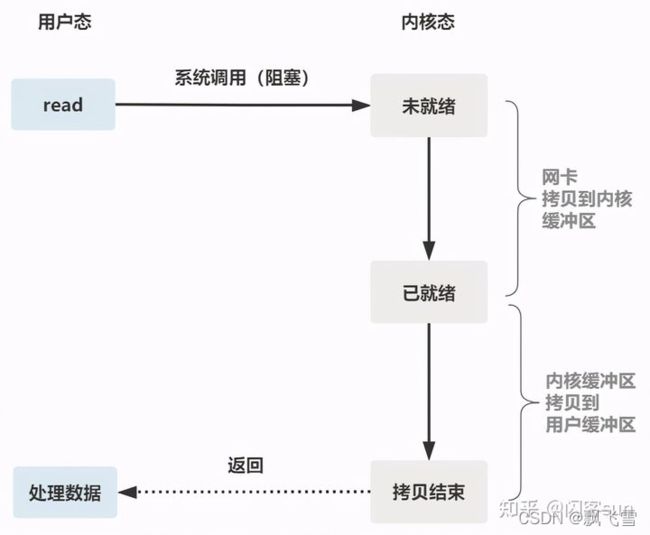
可以看到服务器调用socket.socket(socket.AF_INET, socket.SOCK_STREAM)方法,是创建tcp连接,监听本机3333端口,最外面一层while True循环监听连接,accept()函数底层是系统调用,如果没有客户端连接进来,就会阻塞,一旦有连接,就会进入第二个While True循环,这层循环是处理客户端请求的,如常用的http框架会对http进行解包,然后进行业务逻辑处理如增删改查,然后将结果返回,这里使用deal_with_request函数模拟这些处理。
然而,这种处理方式是存在缺陷的,我们可以看到任何一个开源框架基本不会使用这种io模型,为什么?想象一个场景,当前有100个http请求同时打到这台服务器,每个http请求需要有1秒的处理时间,因为是串行处理,那么最坏的情况是其中一个http请求需要等100秒才能返回结果,这显然是不可接受的。此时非阻塞io可以解决这一问题。
非阻塞 IO
方案1
其实非阻塞也是个系统调用,在python中使用mySocket.setblocking(True)函数后,就会开启非阻塞模式,该模式下如果mySocket.accept()没有接收到连接,就会抛出异常。同样client.recv(1024)如果没有收到消息也会抛出异常。于是就有了以下代码:
import socket
def deal_with_request(request):
return "ok"
def server():
print("服务端开启")
# 创建套接字
mySocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 设置IP和端口
host = '127.0.0.1'
port = 3333
# bind绑定该端口
mySocket.bind((host, port))
# 监听
mySocket.listen()
mySocket.setblocking(False)
client_list = []
while True:
# 接收客户端连接
client = None
try:
client, address = mySocket.accept()
except:
pass
if client and client not in client_list:
print("新连接")
print("IP is %s" % address[0])
print("port is %d\n" % address[1])
client_list.append(client)
for client in client_list:
try:
# 获取客户端得到的消息
data = client.recv(1024)
print("客户端收到消息:", data)
# 对数据进行处理,如常用的http框架会对http进行解包,然后进行业务逻辑处理如增删改查,然后将结果返回,这里使用deal_with_request函数进行处理
ret = deal_with_request(data)
# 对返回内容进行响应
client.send(ret.encode(encoding='utf-8'))
print("响应发送完成")
except Exception as e:
continue
if __name__ == '__main__':
server()
这里创建了client_list 存储连接请求,每次遍历连接响应来实现并发。
方案2
对于每个请求,创建一个线程对请求进行处理,代码如下
import socket
import threading
def deal_with_request(request):
return "ok"
def do(client):
while True:
# 获取客户端得到的消息
data = client.recv(1024)
if not data:
break
print("客户端收到消息:", data)
# 对数据进行处理,如常用的http框架会对http进行解包,然后进行业务逻辑处理如增删改查,然后将结果返回,这里使用deal_with_request函数进行处理
ret = deal_with_request(data)
# 对返回内容进行响应
client.send(ret.encode(encoding='utf-8'))
print("响应发送完成")
def server():
print("服务端开启")
# 创建套接字
mySocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 设置IP和端口
host = '127.0.0.1'
port = 3333
# bind绑定该端口
mySocket.bind((host, port))
# 监听
mySocket.listen()
while True:
# 接收客户端连接
print("等待连接....")
client, address = mySocket.accept()
print("新连接")
print("IP is %s" % address[0])
print("port is %d\n" % address[1])
t = threading.Thread(target=do, args=(client,))
t.start()
if __name__ == '__main__':
server()
客户端代码不变
服务器输出
服务端开启
等待连接....
新连接
IP is 127.0.0.1
port is 63530
客户端收到消息: b'hello'
响应发送完成
等待连接....
客户端输出
客户端开启
连接到服务器
服务器返回内容 b'ok'
这里少了删除连接的逻辑,后面可以加进来
IO 多路复用
非阻塞io并发量可以说相较于阻塞io有了质的飞跃,但是,同时也存在着资源损耗的问题
- 方案1:不断调用accep()和recv()方法进行系统调用导致资源浪费
- 方案2:不断创建线程,消耗资源
基于以上缺点,IO 多路复用既可以解决资源浪费问题,又可以实现并发,目前大部分主流框架都是采用这种方法进行并发的。
select
对于方案1,我们能不能减少系统调用的次数呢,select系统调用就是解决这个问题的,select系统调用输入的是所有连接列表,输出的是有返回值的连接列表,这样只需要遍历有返回值的连接列表进行请求处理,减少了不必要的系统调用。
import socket
import select
def deal_with_request(request):
return "ok"
def server():
print("服务端开启")
# 创建套接字
mySocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 设置IP和端口
host = '127.0.0.1'
port = 3333
# bind绑定该端口
mySocket.bind((host, port))
# 监听
mySocket.listen()
mySocket.setblocking(False)
readable_list = [mySocket]
while 1:
rlist, wlist, xlist = select.select(readable_list, [], [], 5)
for i in rlist:
if i is mySocket:
# 如果ss准备就绪,那么说明ss就可以接受连接了,当ss接受到连接
# 那么把连接返回readlist
conn, addr = i.accept()
readable_list.append(conn)
continue
try:
data = i.recv(1024)
print("客户端收到消息:", data)
# 对数据进行处理,如常用的http框架会对http进行解包,然后进行业务逻辑处理如增删改查,然后将结果返回,这里使用deal_with_request函数进行处理
ret = deal_with_request(data)
# 对返回内容进行响应
i.send(ret.encode(encoding='utf-8'))
print("响应发送完成")
except:
continue
if __name__ == '__main__':
server()
poll
它和 select 的主要区别就是,去掉了 select 只能监听 1024 个文件描述符的限制。
epoll
- select 调用需要传入 fd 数组,需要拷贝一份到内核,高并发场景下这样的拷贝消耗的资源是惊人的。(可优化为不复制)
- select 在内核层仍然是通过遍历的方式检查文件描述符的就绪状态,是个同步过程,只不过无系统调用切换上下文的开销。(内核层可优化为异步事件通知)
- select 仅仅返回可读文件描述符的个数,具体哪个可读还是要用户自己遍历。(可优化为只返回给用户就绪的文件描述符,无需用户做无效的遍历)
所以 epoll 主要就是针对这三点进行了改进。
- 内核中保存一份文件描述符集合,无需用户每次都重新传入,只需告诉内核修改的部分即可。
- 内核不再通过轮询的方式找到就绪的文件描述符,而是通过异步 IO 事件唤醒。
- 内核仅会将有 IO 事件的文件描述符返回给用户,用户也无需遍历整个文件描述符集合。具体,操作系统提供了这三个函数。
作者:闪客sun
链接:https://www.zhihu.com/question/59975081/answer/1932776593
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
传输层
传输层协议提供一种端到端的服务,即应用进程之间的通信。网络层协议提供不可靠、无连接和尽力投递的服务,因此,如果对于可靠性要求很高的上层协议,就需要在传输层实现可靠性的保障。
udp协议
UDP协议提供不可靠服务,是无连接的
参考:https://blog.csdn.net/aa1928992772/article/details/85240358
协议报文

1.源端口: 源端口号,需要对方回信时选用,不需要时全部置0.
2.目的端口:目的端口号,在终点交付报文的时候需要用到。
3.长度:UDP的数据报的长度(包括首部和数据)其最小值为8(只有首部)
4.校验和:检测UDP数据报在传输中是否有错,有错则丢弃。
该字段是可选的,当源主机不想计算校验和,则直接令该字段全为0.
udp编程
服务器
import socket
BUFSIZE = 1024
ip_port = ('127.0.0.1', 9999)
server = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # udp协议
server.bind(ip_port)
while True:
data, client_addr = server.recvfrom(BUFSIZE)
print('server收到的数据', data)
server.sendto(data.upper(), client_addr)
客户端
import socket
BUFSIZE = 1024
client = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
msg = "hello"
ip_port = ('127.0.0.1', 9999)
client.sendto(msg.encode('utf-8'), ip_port)
data, server_addr = client.recvfrom(BUFSIZE)
print('客户端recvfrom ', data, server_addr)
client.close()
tcp协议

3次握手4次挥手
过程
https://blog.csdn.net/qq_38950316/article/details/81087809
ICMP协议
icmp是基于ip协议完成的一个协议,主要作用有2个
- ping命令就是基于icmp协议实现的
- 当报文因为某些情况被路由丢弃了,就会回传icmp报文
- 当报文达到MTU时候需要分片,此时会回传一个icmp报文