python图灵智能语音聊天机器人
第一次写AI,写得不怎么样,还望大佬们能赏脸看看,不足的地方,请多多指教!!
实现目的:借助百度AI的语音识别和语音合成,以及图灵机器人来实现智能语音聊天机器人
文章目录
-
- 1.图灵机器人的创建
- 2.录音功能的实现
- 3.百度AI接口创建
- 4.语音合成技术的实现
- 5.如何将合成的语音在python环境中播放出来
- 6.语音识别技术的实现
- 7.图灵API自动回复
- 8.代码汇总
- 9.结果显示
- 10.总结
1.图灵机器人的创建
图灵机器人
创建属于自己的图灵机器人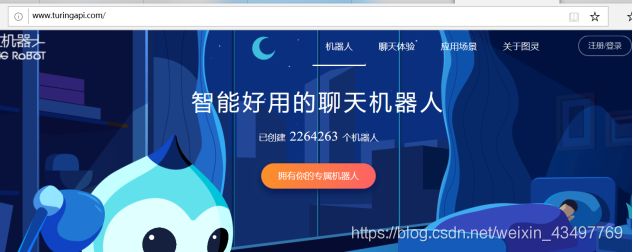
注意:密钥一定要关闭,不然结果会出现加密方式错误!!!!!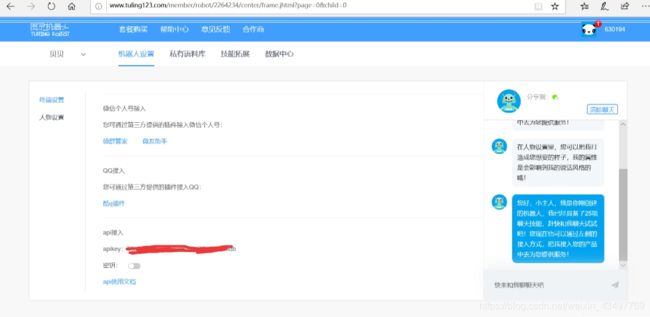
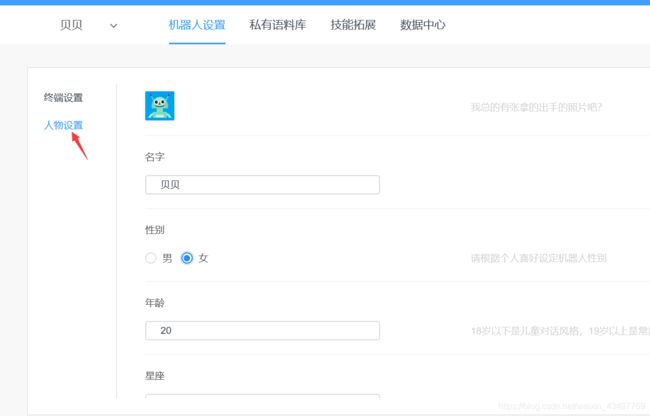
在这里,我们可以对它进行人物设置,把它打造成我们想要的机器人……
2.录音功能的实现
在百度AI中语音合成比语音识别技术要简单些,因为语音识别会有一些噪音的干扰等,无法识别,所以我们就要对噪音进行处理,处理方法在录音功能中实现
import pyaudio
import wave
def record(seconds,filename):
RATE=8000#采样率
CHANNELS=2#采样管道数
FORMAT=pyaudio.paInt16#量化位数
SECONDS=seconds#录音时长
p = pyaudio.PyAudio()
stream=p.open(rate=RATE,channels=CHANNELS,format=FORMAT,input=True)
frames=[]#存储所有读取到的数据
print("录音开始,还有",seconds,"秒")
data=stream.read(RATE*SECONDS)
frames.append(data)
stream.stop_stream()
print("录音结束!!!")
stream.close()
p.terminate() #关闭会话
wf=wave.open(filename,"wb")
wf.setnchannels(CHANNELS)
wf.setframerate(RATE)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.writeframes(b''.join(frames))
wf.close()
return filename
record(5,'F:\\auido.wav')3.百度AI接口创建
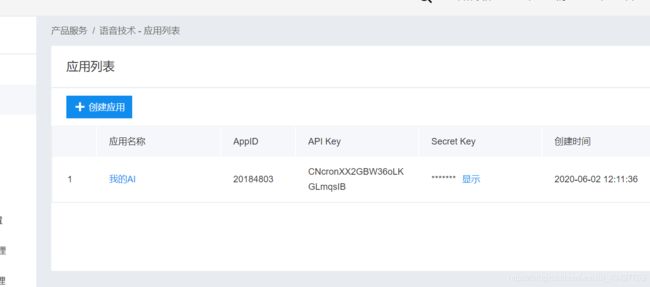
百度AI官网


然后创建应用,获取想要的API和密码
4.语音合成技术的实现
在使用百度AI的时候要学会看技术文档
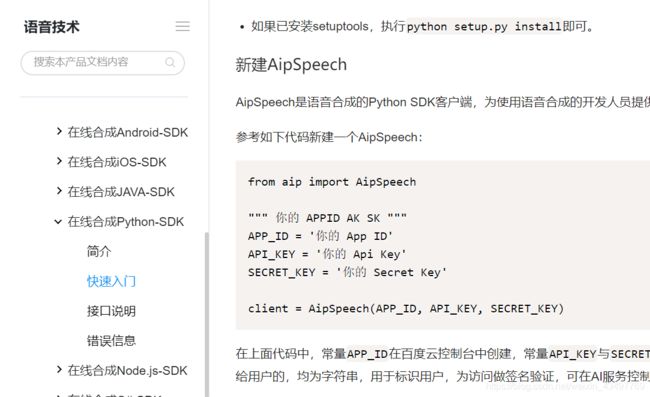
""" 你的 APPID AK SK """
APP_ID = '您的APP_ID'
API_KEY = '您的API_KEY'
SECRET_KEY = '您的SECRET_KEY'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
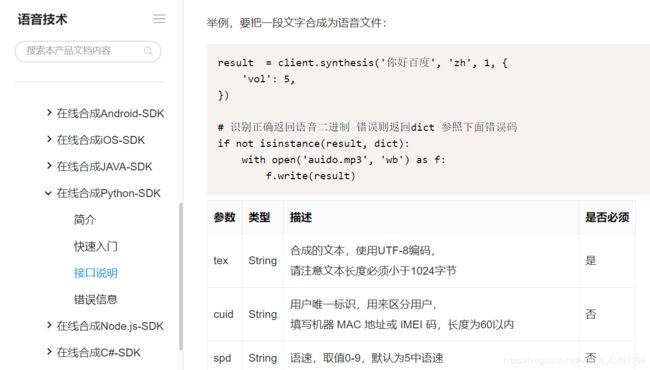
result = client.synthesis(mm, 'zh', 1, {
'vol': 5, 'spd':4, 'per':1
})
if not isinstance(result, dict):
with open('F:\\auido.mp3', 'wb') as f:
f.write(result)5.如何将合成的语音在python环境中播放出来
首先需要导入pygame模块,用pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pygame来下载速度会快些
import pygame
import time
filename="F:\\auido.mp3"
pygame.mixer.init()
pygame.mixer.music.load(filename)
pygame.mixer.music.play()
time.sleep(5)6.语音识别技术的实现
from aip import AipSpeech
import pyaudio
import wave
import time
def record(seconds,filename):
RATE=8000#采样率
CHANNELS=2#采样管道数
FORMAT=pyaudio.paInt16#量化位数
SECONDS=seconds#录音时长
p = pyaudio.PyAudio()
stream=p.open(rate=RATE,channels=CHANNELS,format=FORMAT,input=True)
frames=[]#存储所有读取到的数据
print("录音开始,还有",seconds,"秒")
data=stream.read(RATE*SECONDS)
frames.append(data)
stream.stop_stream()
print("录音结束!!!")
stream.close()
p.terminate() #关闭会话
wf=wave.open(filename,"wb")
wf.setnchannels(CHANNELS)
wf.setframerate(RATE)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.writeframes(b''.join(frames))
wf.close()
return filename
record(5,'F:\\auido.wav')
""" 你的 APPID AK SK """
APP_ID = '20178217'
API_KEY = 'DXpGC2WesUxvGpzcqFuk55de'
SECRET_KEY = 'ILPB25e9GSOAnxlokVSu4yWVVik2qtz9'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 语音识别
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
# 识别本地文件
result=client.asr(get_file_content('F:\\auido.wav'), 'wav', 16000, {
'dev_pid': 1537,
})
mm=result['result'][0]7.图灵API自动回复
urls = 'http://openapi.tuling123.com/openapi/api/v2' # 图灵接口的url
api_key = "输入您的apiKey"
# 回复
def Turing(data,n):
data_dict = {
"reqType": 0,
"perception": {
"inputText": {
"text": data
},
},
"userInfo": {
"apiKey": api_key,
"userId": "输入用户ID"
}
}
result = requests.post(urls, json=data_dict)
content = result.text
# print(content)
ans = json.loads(content)
text = ans['results'][0]['values']['text']
print('Niubility:',text) # 机器人取名就叫Niubility8.代码汇总
import requests
import json
from aip import AipSpeech
import wave
import pyaudio
import pygame
import time
urls = 'http://openapi.tuling123.com/openapi/api/v2' # 图灵接口的url
api_key = "38a0a09b87424c948d5ad92e7964e3db"
count = 1 # 用来计数输入的次数
def record(seconds,filename):
RATE=8000#采样率
CHANNELS=2#采样管道数
FORMAT=pyaudio.paInt16#量化位数
SECONDS=seconds#录音时长
#第一步:创建PyAudio的实例对象
p = pyaudio.PyAudio()
#第二步:调用PyAudio实例对象的open方法创建流Stream
stream=p.open(rate=RATE,channels=CHANNELS,format=FORMAT,input=True)
frames=[]#存储所有读取到的数据
print("录音开始,还有",seconds,"秒")
#第三步:根据需求,调用Stream的write或者read方法
data=stream.read(RATE*SECONDS)
frames.append(data)
#第四步:调用Stream的stop方法停止播放音频或者是录制音频
stream.stop_stream()
print("录音结束!!!")
#第五步:调用Stream的close方法,关闭流
stream.close()
#第六步:调用pyaudio.PyAudio.terminate() 关闭会话
p.terminate()
#写入到wav文件里面
wf=wave.open(filename,"wb")
wf.setnchannels(CHANNELS)
wf.setframerate(RATE)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.writeframes(b''.join(frames))
wf.close()
return filename
""" 你的 APPID AK SK """
APP_ID = '20178217'
API_KEY = 'DXpGC2WesUxvGpzcqFuk55de'
SECRET_KEY = 'ILPB25e9GSOAnxlokVSu4yWVVik2qtz9'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 语音识别
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
# 回复
def Turing(data,n):
data_dict = {
"reqType": 0,
"perception": {
"inputText": {
"text": data
},
},
"userInfo": {
"apiKey": api_key,
"userId": "630194"
}
}
result = requests.post(urls, json=data_dict)
content = result.text
# print(content)
ans = json.loads(content)
text = ans['results'][0]['values']['text']
print('Niubility:',text) # 机器人取名就叫Niubility
result2 = client.synthesis(text, 'zh', 1, {
'vol': 5, 'spd': 4, 'per': 1
})
# 识别正确返回语音二进制 错误则返回dict 参照下面错误码
if not isinstance(result2, dict):
with open('F:\\auido{}.mp3'.format(n), 'wb') as f:
f.write(result2)
pygame.mixer.init()
pygame.mixer.music.load("F:\\auido{}.mp3".format(n))
pygame.mixer.music.play()
time.sleep(10)
f.close()
if __name__ == "__main__":
print("Niubility:主人您好,我是Niubility,爱你哦~")
for n in range(1,51):
record(5,'F:\\auido.wav')
result = client.asr(get_file_content('F:\\auido.wav'), 'wav', 16000, {
'dev_pid': 1537,
})
mm = result['result'][0]
data = input('{}//你:'.format(count)+mm) # 输入对话内容
Turing(mm,n)
count+=19.结果显示
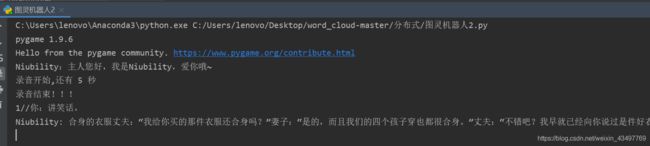
10.总结
做实验遇到的问题:
(1)结果出现错误信息:加密方式不正确,解决:把密钥关闭,再次运行
(2)出现[Errno 13] Permission denied: ‘audio.mp3’……解决:写入到不同的mp3文件
简单的智能聊天机器人终于做出来了,心里还是有点小激动哈哈哈哈哈