复旦大学李孝男博士:结合词典的中文命名实体识别
⬆⬆⬆ 点击蓝字
关注我们
AI TIME欢迎每一位AI爱好者的加入!
近年来,将词典信息加入模型被证明对中文命名实体识别任务很有效。但是结合词典的方法通常会使输入变为一个动态的结构,模型需要在运行时动态改变结构来表征输入,导致无法有效利用GPU的并行计算,运行速度缓慢。而FLAT模型,在Transformer的基础上,采用了一个特殊的位置编码表征输入结构,不需要在运行时改变结构来表征输入,且实验结果显示模型在识别实体的正确率以及运行速度上均有良好的表现。
本期AI TIME PhD直播间,我们有幸邀请到了复旦大学计算机学院的博士生李孝男以“结合词典的中文命名实体识别”为题进行了分享,详细介绍了NER任务的定义 、深度学习框架下比较通用的NER的模型架构 、中文NER的难点 、和两大类中文NER加入词典信息的方法,并且主要介绍了讲者本人参与的一个又快又好的中文NER模型,FLAT。

李孝男,复旦大学,复旦大学计算机学院学院博士生,导师为邱锡鹏教授。主要研究方向为自然语言处理。

一、命名实体识别NER
1.
NER是什么?
命名实体识别,Named Entity Recognition (NER),即从句子中抽取出一些具有特定含义的实体,比如组织名,地名,人名等。举例来说“红十字会邀请香港的梁朝伟进行义演”,其中含有“红十字会”这个组织名,“香港”这个地名以及“梁朝伟”这个人名。NER要求从句子中把这些实体抽取出来并给定正确的分类。
NER是NLP中一个比较基础的上游任务,它对许多任务来说很有帮助,也非常关键。比如信息检索,比如帮助抽取知识图谱的三元组。总之NER算是一个比较重要且实用的任务。
2.
NER具体怎么做?
目前NER一般会被当序列标注来做,即句子的实体信息会被转换为一个对应的标签序列,这个序列中的每个标签都对应了一个位置。如果标签的第一部分是O,就代表对应位置不是一个实体,反之代表属于一个实体,B代表实体的开始,I代表实体的中间或者结尾。标签的第二部分代表位置对应的实体种类,比如PER、ORG、LOC,分别代表了人名、组织名、地名。比如“香港”的“香”,处于“香港“这个词的开头,且”香港“是一个地名,那么”香“这个字的标签就是B-LOC。在模型训练完毕后,就能根据输入的句子来输出对应的标签序列,从而将标签序列转化为对应的实体信息,用于后续的性能评测及应用。
二、深度学习框架下比较通用的NER的模型架构
深度学习框架下的NER模型一般可以拆解为三个部分:输入表示层,上下文编码器,标签解码器。
输入表示层(Input Layer)的作用是将构成句子的离散记号映射到一个连续空间以方便之后的计算。比较常见的输入表示层有Word Embedding(Glove / Word2Vec / Random Init),即通过词的ID直接为这个词找到向量表示。英文中Character embedding也经常使用,即用序列编码模型(RNN/CNN/Transformer based char-level representation)编码这个词的字符序列,得到词的字符级别表示。

图1:序列编码模型RNN
另一种常用的输入表示层是Pretrained Contextual Embedding,比如说ELMo和BERT,它们生成的表示会根据上下文产生变化。最后一种Other features,比如POS/gazetteers/linguistic dependency。不同的输入表示层经常搭配在一起使用,这样既能够良好的建模,也能够表示词内部的特征,这对NER来说是比较重要的。
上下文编码器(Context Encoder)的作用是建模词在句子中的语义。一个词在不同的句子中可能有不同的意思,而上下文编码器就负责通过上下文来为此得到一个更好的表示。比较经典的模型有Recurrent Neural Network (RNN) 循环神经网络,它能够较好的建模词之间的依赖,同时性能稳定,但由于它的循环结构会导致运行速度较慢。另外一种是Convolutional Neural Network (CNN) 卷积神经网络,由于它在句子级别上并行运行,所以速度较快,但由于局部建模的特性,所以比较难以建立长距离的依赖。Transformer (Encoder) 相对来说是比较新的模型,由于计算简单且并行所以跑起来比较快,同时也能够直接建立长距离的依赖,但由于它本身的一些特性,在小数据集上的表现不是很好。
标签解码器(Tag Decoder)主要有两种,第一种是MLP + Softmax,我们在得到每个词的表示后,直接用一个线性层来得到该词所对应的各个标签的分数。第二种是Conditional Random Field (CRF) 条件随机场,它可以建模标签序列内部的依赖,比如说B-PER后面是不能跟I-ORG的,条件随机场能够在训练的时候逐渐学会这种标签间的依赖,从而避免一些错误发生。
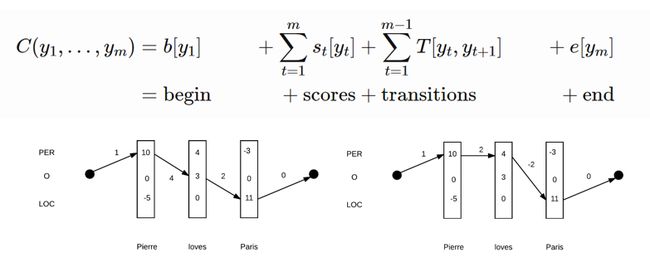
图2:MLP + Softmax

图3:CRF条件随机场
三、中文NER的难点
由于英文和中文不同的语言特性,中文没有空格且基本单元是字,所以中文NER要比英文NER困难一点。比如,“货拉拉拉拉布拉多吗?”,如果我们想从字级别来理解这个句子会非常困难,但如果分好词,”货拉拉 / 拉 / 拉布拉多 / 吗 / ?“,这个句子的意思就更容易理解了。
所以分词对于中文NLP比较重要。但如果用先分词后NER的pipeline方法是有些问题的,比如, “南京市长江大桥”,假如分词工具错分成了“南京市长/江大桥”,那之后再怎么序列标注都不能把正确的实体抽取出来。那么能不能不分词直接在字级别的句子上做NER?理论上是可以的,但还可以改善,因为这么做并没有利用中文的词信息,即分词的边界信息和词义信息。边界信息就是指如何断句,词义信息就是指中文的某些词意不能由组成它的字来推断得到,比如“沙发”这个词和构成它的两个字“沙”和“发”都没有意思上的直接联系。
那么,在先分词后做NER的pipeline方法和字级别的NER方法都有缺陷的情况下,一个关键的问题就冒了出来:如何在不分词的情况下向字级别的序列中加入词信息?
四、中文NER加入词典信息的方法
近年来的中文NER的paper大多采用了词典匹配(Lexicon matching)的方式,向字级别的句子中加入词信息。我们可以用一个字词Lattice结构直观的表明,每匹配到一个词就为这个词形成一个新的节点,然后根据它横跨的范围来进行连边。比如“重“”庆”匹配到了“重庆”这个词,就会形成一个新节点,根据它横跨的范围从“重”这个字前面连条入边到“重庆”上,再连条出边到“人”字前面。

图4:字词Lattice结构
同时,我们需要修改模型的一小部分使它能够兼容这个结构。思路一是为每个词的节点形成一个新的向量表示,并和字向量一起送给上下文编码器,并相应的修改上下文编码器使它能编码这个结构。思路二是把词典匹配的信息加入到向量表示中,相当于修改了输入表示层。
接下来,这张图片根据方法的不同对近年来中文NER的paper做了大致的分类。

图5:中文NER的paper分类
第一大类是Dynamic Architecture,输入的结构会动态的改变,上下文编码器也需要动态的修改结构来表征输入的结构。对应刚才的思路一。
第二大类是Adapt Embedding ,修改输入表示层,对应刚才的思路二。
五、第一大类——修改上下文编码器
Chinese NER Using Lattice LSTM,这篇文章对LSTM做了一些改动使它能够接受Lattice为输入。对于Lattice中的字序列, Lattice LSTM的更新路径是类似于LSTM的,而对于额外的词节点,Lattice LSTM会在更新路径加额外的跳边。比如“人和药店”这个词的跳边是从“人”开始到“店”,每个字可能会有大于一个的前驱,“店”的前驱有“药”字,以及“人和药店”和“药店”这两个词。所以Lattice LSTM采用了类似注意力机制的方法,对前驱的状态进行融合并更新状态,从而得到当前位置的表示。“店”这个字对“人和药店”这个词的注意力分数特别高,说明模型认为“人和药店”在这个句子中应该是一个词。相对于普通的LSTM,效果提升很明显,但是它也存在一些缺点,第一个缺点是运行速度较慢,Batch运行效率较低。第二个缺点是,词内部的字无法接收到这个词的信息。
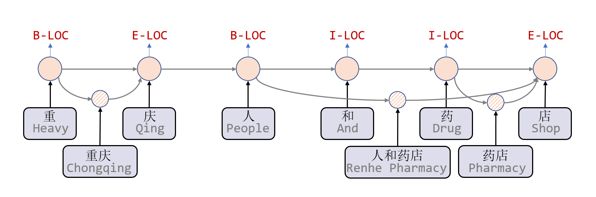
图6:Lattice LSTM
CNN-Based Chinese NER with Lexicon Rethinking,这篇文章是通过修改CNN,使它能够接受Lattice为输入。普通CNN是通过在文本上不断卷积,不断获得更强的N-Gram表示,以建模更好的上下文信息。这篇文章是通过在匹配到的词汇与对应长度的N-Gram中进行一次soft的选择,从而更好的编码词信息。比如,现在有一个长度为2的词“广州“,“广”和“州”这两个字一次卷积后得到的结果就是它们的Bigram表示,然后在Bigram表示和“广州”的直接词义表示中进行一次soft的选择,如果选择 “广州”的直接词义表示,模型就能获得更好的词信息。相较上篇文章,这篇文章采用的底层编码器是CNN,并采用rethinking机制加强信息传输能力,所以性能和速度都有所提升。但是由于CNN局部建模的特性,模型难以建模长距离依赖,并且如果编码长词则需要比较深的CNN,会在模型结构设计上有所限制。
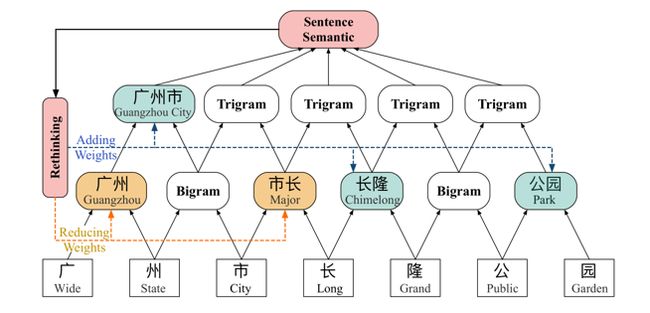
图7:CNN-Based Chinese NER with Lexicon Rethinking
除了上面介绍的两种,还有基于图网络的方法(GNN-Based Methods)的两篇文章:A Lexicon-Based Graph Neural Network for Chinese NER和Leverage Lexical Knowledge for Chinese Named Entity Recognition via Collaborative Graph Network,方法是用词典匹配的信息构建图,用优秀的图神经网络来编码这个图,以获得更好的信息传输能力和结构编码能力。这类方法的不足是,序列和图之间的gap较大,通常需要一个RNN作为底层编码器,这会使模型复杂,运行速度下降。
六、FLAT模型
接下来,为大家介绍一下FLAT: Chinese NER Using Flat-LAttice Transformer。这篇文章将Transformer改造了一下,使它能够接受Lattice为输入。
1.
简单的介绍一下Transformer吧?
Transformer的第一个优点是能直接建模任意两个节点之间的依赖,在输入是Lattice的场景下,每个字或词都能接收到所有词和字的信息。第二个优点是Transformer的计算过程是静态的,不管输入的Lattice结构怎么变,计算过程都不变。Transformer简单来说有三个模块,其中两个是Self-Attenion和Feed Forward,这两个模块的计算输入与位置无关,比如,“货拉拉拉拉布拉多吗”这个句子,如果直接把句子的字向量送到Self-Attenion和Feed Forward里,得到的几个“拉”字的表示是相同的。这时,Transformer的第三个模块就能解决这个问题,字向量或词向量输入到Self-Attenion之前,会被加上对应的位置编码,就像涂上了不同的颜色,整体的模型就能够感知到位置了。

图8:对应的位置编码像涂上了不同颜色
2.
FLAT具体是怎么实现命名实体识别的?
这篇文章中,我们提出了一种新的针对Lattice的位置编码方式。
首先,我们将Lattice结构转换为Flat-Lattice。给每个字一个位置标签,然后给每个词两个位置标签,分别为头和尾。比如说“人和药店”的头和尾是“人”和“店”的位置标签,也就是3和6。这样我们就能将Lattice结构转化为一个三元组的集合,每个三元组包括了字或者词,头和尾。我们就称这个集合为Flat-Lattice。且Flat-Lattice可以还原为原来的Lattice结构,所以如果Transformer良好的编码了Flat-Lattice,就相当于编码了原来的Lattice结构。

图9:Lattice Position Index
然后,我们把所有字和词给到Transformer,利用头和尾的信息计算出每2个节点之间的4个相对距离,利用多层全连接对4个相对距离进行信息融合,用相对位置编码的方式将融合信息给到Self-Attenion。相对位置编码的方式能使得节点对其他节点进行更好的关注,从而对整个结构更好的编码。举例来说,“重”和“重庆“的4个相对距离是0011,我们就能判断出”重“这个字在”重庆“这个词里面,那么模型就能根据包含的关系,使”重“对”重庆“这个词多加关注,从而更好的识别实体的边界。

图10:FLAT整体模型架构
最后,在Transformer编码完这些信息后,利用条件随机场解码出标签序列,实现命名实体识别。
3.
FLAT的评估结果怎么样?
性能上,FLAT超过了baseline模型和其它结合词典的模型,且在大数据集上的性能提升尤为明显。
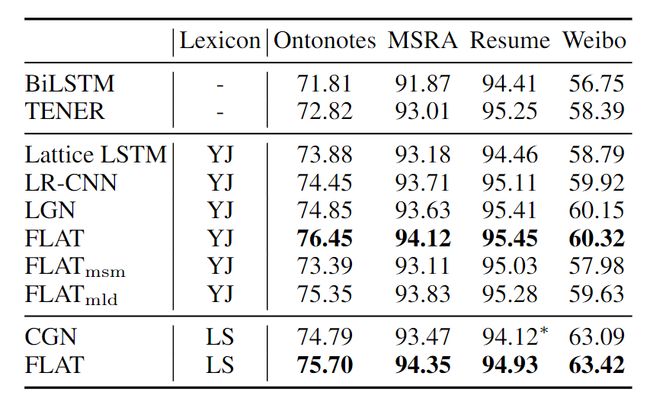
图11:FLAT性能比较
运行速度上,第一,基于图网络的模型跑的比Lattice LSTM和LR-CNN快。第二,FLAT跑的比其它结合词典的模型快。这是因为我们模型不需要动态修改模型结构来表征输入的结构,而是通过特定设计的位置编码。第三,FLAT从Batch并行化中获得的加速比较高。

图12:FLAT运行速度比较
我们也进行了几个分析实验来分析FLAT的性能提升来源。
第一个分析实验发现,利用词典资源和使用特定于Lattice的位置编码,能够提升模型在定位实体和分类设计上的能力。
第二个分析实验发现,FLAT相比于Lattice LSTM会带来性能提升的原因是:词内部的字能够接收到词信息,FLAT能直接建模长距离依赖。
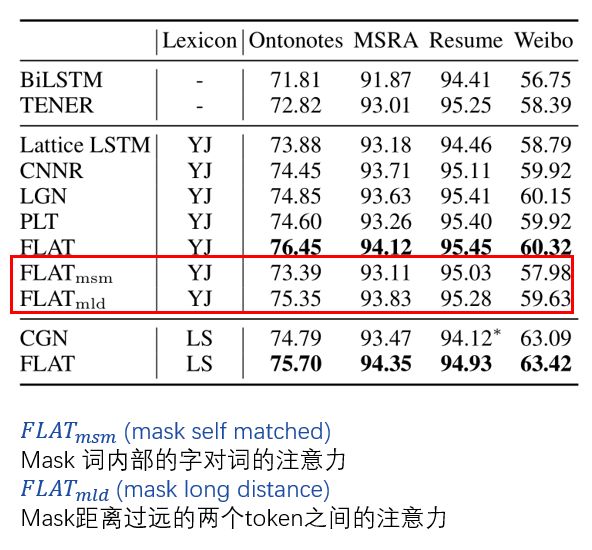
图13:FLAT相比于Lattice LSTM的优势
第三个分析实验探究了FLAT与BERT的兼容性。对于大数据集,BERT+FLAT显著超过只使用BERT的模型,而对于小数据集,BERT+FLAT的提升不是很大。这可能是由于BERT+FLAT组合的参数量过大,容易在小数据集上过拟合。

图14:与BERT的兼容性
七、第二大类——修改输入表示层

图15:Adapt Embedding类paper
Soft-Word是一种可以将分词信息转化为标签序列的方法。比如“明”这个字是“李明”这个词的最后一个字,那么就用E(nd)标签就代表它的分词状态,还有3种标签分别是B代表Begin, M代表这个字处于词的内部,S代表这个字是单独的词。之后Soft-Word再把代表分词标签信息的向量序列与自向量拼接加入输入表示层,这样输入表示层就拥有了分词的边界信息。

图16:Soft-Word
在Adapt Embedding类paper中,Simplify the Usage of Lexicon in Chinese NER这篇不仅将分词的边界信息加入了输入表示层,又将词义信息加入了输入表示层。

图17:Simplify the Usage of Lexicon in Chinese NER
从这张模型结构图中,我们可以看到具体步骤。第一步是把句子与词典进行匹配。比如“中国语言学”匹配到了“中国语言”、“语言学”等词。第二步是找到包含每个字的所有词,然后把这些词分类,分组映射到向量中。比如“语”这个字,“语言”和“语言学”这两个词是以它为开头的,就把它分到Begin类,"中国语言"这个词是包含这个字的,就把它分到M类。第三步是将这个字的表示和4种对应类别的词的表示,拼接后送到输入表示层中。这样输入表示层既拥有了分词的边界信息,又拥有了词的语义信息。在这之后,用一些通用的上下文编码器编码输入,最后用标签解码器解码出标签序列,从而实现命名实体识别。
Q&A环节

请问您的团队是借用预训练词向量编码吗?如果是的话,预训练词向量影响怎么样?如果没有用,您们是自己基于刚才的4个样本集做的吗?

是的,用了杨杰博士提供的预训练向量。

请问您有比较过BERT经过fine-tune的NER方法,以及字+词的BERT的NER方法之间的效果吗?
有的,用了BERT会比不用BERT厉害。
谢谢您,预训练向量本身不同语料带来不同的信息进入整体NER模型,感觉BERT模型本身可能也带入不确定性影响。
论文原文和链接:
Li, Xiaonan, et al. "FLAT: Chinese NER Using Flat-Lattice Transformer." arXiv preprint arXiv:2004.11795 (2020).
https://arxiv.org/abs/2004.11795
Reference:
Zhang, Y., and J. Yang. "Chinese ner using lattice lstm. arXiv 2018." arXiv preprint arXiv:1805.02023 (2020).
Gui, Tao, et al. "CNN-Based Chinese NER with Lexicon Rethinking." IJCAI. 2019.
Gui, Tao, et al. "A lexicon-based graph neural network for chinese ner." Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019.
Sui, Dianbo, et al. "Leverage lexical knowledge for chinese named entity recognition via collaborative graph network." Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019.
Ding, Ruixue, et al. "A neural multi-digraph model for Chinese NER with gazetteers." Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019.
Peng, Minlong, et al. "Simplify the Usage of Lexicon in Chinese NER." arXiv preprint arXiv:1908.05969 (2019).
Liu, Wei, et al. "An Encoding Strategy Based Word-Character LSTM for Chinese NER." Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019.
本文所引用的图片均来自讲者李孝男的PPT.
整理:李嘉琪
审稿:李孝男
排版:田雨晴
本周直播预告:


AI Time欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你,请将简历等信息发至[email protected]!
微信联系:AITIME_HY

AI Time是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注
(点击“阅读原文”下载本次报告ppt)
(直播回放:https://b23.tv/0l8agl)