中文文本多标签文本分类(python tensorflow2实现 )
NLP(中文文本多标签文本分类)
本文主要是说明中文文本多标签分类的具体流程,结果不理想暂不考虑,后续再进行优化(刚接触NLP)。
先来说说多标签分类和二分类,多分类的区别。二分类,多分类的标签只有一个,换句话说就是只属于一个类别,多标签分类则是属于多个类别。
数据集采用的是头条新闻的数据(处理起来有点坑。。。)头条新闻的数据
总体流程分为主要是三个步骤:
1.数据预处理。(删除缺失值,删除非中文字符,文本划分)
2.文本向量化。(one-hot,tf_idf,word2vec等)
3.采用机器学习的方法(主要是神经网络)
上述理论知识不再介绍。
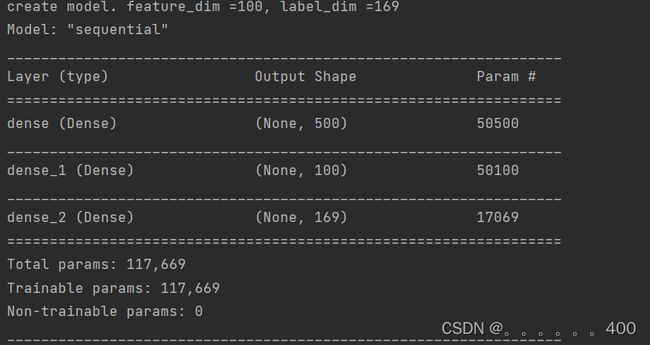
神经网络模型参数:
import pandas as pd
import re
import numpy as np
from sklearn.preprocessing import MultiLabelBinarizer
import jieba
from sklearn.model_selection import train_test_split
from gensim.models import Word2Vec
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
filepath = 'G:\\Alops\DataSet\\toutiao-multilevel-text-classfication-dataset-master\\mlc_dataset_part_aa'
cloNames = ['newsId', 'newsClass', 'newsTitle', 'newsFeatures', 'newsLabel', 'other']
stopWord_filepath = "G:\\Alops\DataSet\\toutiao-multilevel-text-classfication-dataset-master\\stopWord.json"
def readFile(filepath):
f = open(filepath, encoding='utf-8')
text_list = []
line = f.readline().strip()
while line:
text_list.append(line)
line = f.readline().strip()
f.close()
result = []
for list in text_list:
result.append(list.split('|,|'))
return result
# 删除缺失值
def drop_null(data_use):
index1 = data_use[data_use.isnull().T.any()]
index2 = list(index1.index)
data_drop_null = data_use.drop(index2)
return data_drop_null
def clear_character(sentence):
pattern1 = '[a-zA-Z0-9]'
pattern2 = re.compile(u'[^\s1234567890' + '\u4e00-\u9fa5]+')
pattern3 = '[’!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~]+【】'
line1 = re.sub(pattern1, '', sentence)
line2 = re.sub(pattern2, '', line1)
line3 = re.sub(pattern3, '', line2)
new_Sentence = ''.join(line3.split())
return new_Sentence
def content_split(content):
seg = list(jieba.cut(content))
return seg
def read_stopWord(stopWord_filepath):
with open(stopWord_filepath, encoding="utf_8") as f:
stopWord_list = f.read().split('\n')
return stopWord_list
def rm_stop_word(wordList):
filtered_words = [word for word in wordList if word not in stopWords]
return filtered_words
data = readFile(filepath)
data = pd.DataFrame(data, columns=cloNames)
data_use = data[["newsTitle", "newsClass"]]
# print(data_drop_null['newsTitle'].isnull().sum()) #130
# print(data_drop_null['newsClass'].isna().sum()) #8
# print(data_drop_null['newsClass'].isnull().sum()) #8
#只采用前10000条数据(加快训练速度)
data_use = data_use[0:10000]
# 删除缺失值
data_drop_null = drop_null(data_use)
# print(data_drop_null['newsClass'].isna().sum()) #0
# print(data_drop_null['newsClass'].isnull().sum()) #0
# 去除非中文字符并划分文本
data_drop_null['titleClear'] = data_drop_null['newsTitle'].apply(clear_character)
data_drop_null['titleClear'] = data_drop_null['titleClear'].apply(content_split)
data_drop_null['class_progress'] = [da.split(',') for da in data_drop_null['newsClass']]
print(data_drop_null['class_progress'].head())
# 去除停用词
stopWords = read_stopWord(stopWord_filepath)
data_drop_null['title_progress'] = data_drop_null['titleClear'].apply(rm_stop_word)
# 划分训练集和测试集
x_data = data_drop_null['title_progress']
y_data = data_drop_null['class_progress']
x_train_data, x_test_data, y_train_data, y_test_data = train_test_split(x_data, y_data, random_state=300)
# 词向量化
'''
sg=1 是 skip-gram 算法,对低频词敏感;默认 sg=0 为 CBOW 算法。
size 是输出词向量的维数,值太小会导致词映射因为冲突而影响结果,值太大则会耗内存并使算法计算变慢,一般值取为100到200之间。
window 是句子中当前词与目标词之间的最大距离,3表示在目标词前看3-b 个词,后面看 b 个词(b 在0-3之间随机)。
min_count 是对词进行过滤,频率小于 min-count 的单词则会被忽视,默认值为5。
negative 和 sample 可根据训练结果进行微调,sample 表示更高频率的词被随机下采样到所设置的阈值,默认值为 1e-3。
hs=1 表示层级 softmax 将会被使用,默认 hs=0 且 negative 不为0,则负采样将会被选择使用。
'''
def train_word2vec():
# 训练模型
model = Word2Vec(x_data, sg=1, size=100, window=5, min_count=2, negative=1, sample=0.01, workers=4)
#模型保存
model.save('./word2vec')
# 获取词汇
words = model.wv.index2word
# 获取词向量
vectors = model.wv.vectors
# 根据指定词获取该词的向量
# vec = model.wv['互联网']
# print(vec)
# 判断词之间的相似度
# print(model.similarity('互联网','互联网')) #1.0
def get_word2vec(data):
model = Word2Vec.load('./word2vec')
result = []
for li in data:
co = np.zeros(100)
count = 0
for i in li:
if i in model.wv.index2word:
co += model.wv[i]
count += 1
if count > 0:
co /= count
result.append(co)
return np.array(result)
# train_word2vec()(没有word2vec,应该先训练。)
# 获得词向量
word2vec_train = get_word2vec(x_train_data)
word2vec_test = get_word2vec(x_test_data)
# print(word2vec_train.shape, word2vec_test.shape)
# 标签向量化
Mutil = MultiLabelBinarizer()
y_train_data = Mutil.fit_transform(y_train_data)
y_test_data = Mutil.transform(y_test_data)
print(y_train_data.shape) # (7488, 169)
print(y_test_data.shape) # (2496, 169)
# 神经网络搭建
def deep_model(feature_dim, label_dim):
model = Sequential()
print("create model. feature_dim ={}, label_dim ={}".format(feature_dim, label_dim))
model.add(Dense(500, activation='relu', input_dim=feature_dim))
model.add(Dense(100, activation='relu'))
model.add(Dense(label_dim, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
return model
def train_deep(x_train, y_train, x_test, y_test):
feature_dim = x_train.shape[1]
label_dim = y_train.shape[1]
model = deep_model(feature_dim, label_dim)
model.summary()
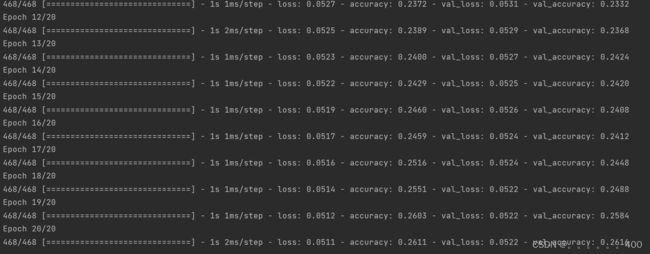
model.fit(x_train, y_train, batch_size=16, epochs=20, validation_data=(x_test, y_test))
train_deep(word2vec_train, y_train_data, word2vec_test, y_test_data)
部分结果截图
优化方向暂时有一下几点。
1.采用别的文本向量化方法:例如Glove,预训练向量,BERT向量。
2.神经网络的选择上应该选择循环神经网络模型。例如LSTM,GRU,可以加上注意力机制等。
3.数据方面只采用了数据的前一万条数据,数据量有点少。