Python程序设计 作业1
作业1
- 1. 矩阵:
- 2. 信用卡号码:
- 3. 分析名著:
- 4. 字符匹配
- 心得与体会:
1. 矩阵:
在Python 中,我们可以使用列表的列表 (a list of lists) 来存储矩阵, 每个内部列表代表矩阵一行。例如,我们可以用
M = [ [5, 6, 7],
[0, -3, 5] ]
来存储矩阵 [ 5 6 7 0 − 3 5 ] \begin{bmatrix} 5&6&7\\ 0&-3&5\\ \end{bmatrix} [506−375]
我们可以使用M[1]来访问矩阵的第二行(即[0, -3, 4]),也可以使用M[1][2]来访问矩阵的第二行的第三项(即 5)。
(1)编写函数 matrix_dim(M),该函数输入上面格式的矩阵 M,返回矩阵 M 的维度。例如, matrix_dim([[1,2],[3,4],[5,6] ]) 返回 [3, 2]。
通过len函数获取行数以及列数即可:
# 定义获取维度函数
def matrix_dim(M):
return [len(M), len(M[0])]
测试输出:
![]()
(2)编写函数mult_M_v(M, v), 返回n×m矩阵M 和m×1向量v的乘积。
①首先通过len函数分别获取矩阵的维度和向量的维度对数据有效性进行检验
②然后通过循环遍历乘积并求和求出对应的结果矩阵的值
# 定义矩阵乘向量函数
def mult_M_v(M, v):
# 判断输入合法性
if len(M[0]) == len(v):
# 设置结果矩阵
res = [[0] for i in range(len(M))]
# 依次循环进行计算
for i in range(len(M)):
for k in range(len(v)):
res[i][0] += (M[i][k] * v[k][0])
return res
return ('invalid input')
测试输出:
①非法数据:
![]()
②合法数据:
![]()
(3)编写函数transpose(M), 返回矩阵的转置。
通过zip函数实现对各个行的正向收集将其转置为元组。并通过遍历将元组重新转回列表即可。
# 定义矩阵转置函数
def transose(M):
temp = list(zip(*M))
res = []
for i in temp:
res.append(list(i))
return res
测试输出:
![]()
(4)编写函数largest_col_sum(M), 寻找矩阵 M 中元素总和最大的列,如上面矩阵中第三列元素的总和最大,则返回 12(7+5=12)。
通过两层循环依次遍历整个矩阵,内层循环遍历每列求出每列的和,外层循环遍历每列的和求出和的最大值。
# 定义求总合最大列函数
def largest_col_sum(M):
# 定义结果
res = 0
for x in range(len(M[0])):
# 定义每列的结果
temp = 0
# 对每列进行遍历
for y in range(len(M)):
temp += M[y][x]
# 取最大值
res = max(res, temp)
return res
测试输出:
![]()
(5)编写函数switch_columns(M, i, j), 交换矩阵 M 的第 i 列和第 j 列,返回新的矩阵 M。
先将矩阵转置,转置后所交换的i,j列即变为i,j行,只需交换对应列表即可。交换完毕后再转置回结果矩阵并返回。
# 定义交换列函数
def switch_columns(M, i, j):
# 先对矩阵进行转置,将列变为行,方便交换
res = transose(M)
# 交换对应行
res[i], res[j] = res[j], res[i]
# 转置回结果矩阵
res = transose(res)
return res
测试输出:
![]()
(6)把以上函数(a-e)写进模块matrix.py。编写 test_matrix.py 调用模块 matrix并测试函数(a-e)。
我们将所有函数都放在matrix.py中,并在test_matrix.py中进行调用测试。测试效果如下:
我们使用如下的矩阵和向量进行测试:
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ] \begin{bmatrix} 1&2&3&4&5\\ 6&7&8&9&10\\ 11&12&13&14&15\\ 16&17&18&19&20\\ \end{bmatrix} ⎣⎢⎢⎡1611162712173813184914195101520⎦⎥⎥⎤
[ 1 2 3 4 5 ] \begin{bmatrix} 1\\ 2\\ 3\\ 4\\ 5\\ \end{bmatrix} ⎣⎢⎢⎢⎢⎡12345⎦⎥⎥⎥⎥⎤
输出结果如下:

2. 信用卡号码:
我们知道信用卡的号码非常长,但是仔细研究会其中也有规律,例如
(1)American Express 使用 15 位数字,MasterCard 使用 16 位数字,Visa 使用 13 位或 16 位数字。
(2)American Express 号码以 34 或 37 开头;MasterCard 号码以 51、52、53、54 或 55 开头;Visa 号码以 4 开头。
(3)信用卡号码有一个内置的“数学关系”。
对于这个“数学关系”,大多数信用卡都使用 IBM 的 Hans-Peter Luhn 发明算法。根据 Luhn 的算法,我们可以确定信用卡号是否有效。方法如下
(1)从倒数第二个数字开始,每隔一个数字乘以 2;然后将得到的所有乘积的各个数位相加(注意不是乘积本身相加),得到结果 sum1;
(2)对于在(1)中没有乘上 2 的数字,直接相加得到结果 sum2;
(3)把(1)的结果和(2)的结果相加,即 sum3=sum1+sum2。若 sum3 的最后一位数字是 0,则信用卡号码有效。
例如有一个号码是4003600000000014,在第一步中,我们把标红色的数字乘以 2 然后相加,得到
1*2+0*2+0*2+0*2+0*2+6*2+0*2+4*2 = 2+12+8
将所得的所有乘积的各个数位相加,得到
sum1 = 2+1+2+8 = 13
在第二步中,我们把标黑色的数字直接相加,得到
sum2 = 4+0+0+0+0+0+3+0 = 7
最后第三步 sum3 = sum1+sum2 = 20,因为 20 的最后一位是 0,那么这个信用卡卡号是有效的。
任务:
编写函数 validCredit(cardNum),检查输入信用卡号码 cardNum 是否有效;若有效,则输出该卡的发行公司(American Express,Mastercard,Visa)。
例子:
validCredit(4003600000000014) # 输出:Valid,Visa
validCredit(6177292929) # 输出:Invalid
参考的有效的信用卡号码:
| Type | Number |
|---|---|
| American Express | 378282246310005 |
| American Express | 371449635398431 |
| MasterCard | 5555555555554444 |
| Visa | 4111111111111111 |
| Visa | 4012888888881881 |
| Visa | 4222222222222 |
大致思路:
①长度与开头检验:
首先通过len函数获取每个卡号的长度,并使用startswith函数对比各个卡号的长度以及开头前几位字符。如果符合,则修改标志变量的值为对应键值。如果不符合,则直接输出“Invalid”并直接返回。
②Luhn检验:
通过for循环对整个卡号进行逆序遍历。对于sum1,可以求出十位和个位的值进行计算。对于sum2直接累加即可。当sum1和sum2累加完毕后,加和并对10取余,若余数为0则为有效卡,调用类型字典输出卡类型。如果余数不为零,则直接输出“Invalid”。
源代码:
# 定义卡号有效性检测函数
def validCredit(cardNum):
# 定义信用卡种类字典
typeDic = {1: 'American Express', 2: 'MasterCard', 3: 'Visa'}
# 首先对卡号长度与开头进行检验并区分卡的类型
flag = -1
if len(cardNum) == 15 and (cardNum.startswith('34') or cardNum.startswith('37')):
flag = 1 # 如果是American Express
elif len(cardNum) == 16 and (cardNum[0] == '5') and (1 <= int(cardNum[1]) <= 5):
flag = 2 # 如果是MasterCard
elif (len(cardNum) == 13 or len(cardNum) == 16) and (cardNum[0] == '4'):
flag = 3 # 如果是Visa
else:
print('Invalid')
return
# 通过Luhn算法进行有效性检验
sum1 = 0
sum2 = 0
# 计算sum1
for i in range(len(cardNum)-2, -1, -2):
# 获取十位
sum1 += int(int(cardNum[i])*2/10)
# 获取个位
sum1 += int(cardNum[i])*2 % 10
# 计算sum2
for i in range(len(cardNum)-1, -1, -2):
sum2 += int(cardNum[i])
# 最终有效性检验
if (sum1+sum2) % 10 == 0:
print('Valid, '+typeDic[flag])
else:
print('Invalid')
# 获取输入进行测试
cardNum = input('Please input a card to check: ')
print('Card Number:'+cardNum)
validCredit(cardNum)
代码解释:
L5定义信用卡类型字典,便于输出信用卡类型。
L9-L17:对信用卡长度和开头字符进行检验,如果满足对应类型,则修改标志变量进行存储;如果不满足任何类型,则输出“Invalid”
L23-L27:对sum1进行求和并检验。易知,乘以二之后的值一定为两位数,则可以拆开两个数位进行求和获取sum1。
L29-L30:对sum2进行累加获取
L33-L36:最终的有效性检验并分类输出信用卡类型
L40-L42:获取输入对程序进行测试
代码测试:
①Visa卡检验:

②American Express卡检验

③MasterCard卡检验:

④非法卡号检验:
![]()
3. 分析名著:
编写程序,通过统计名著中使用的 20 个最常用单词来分析两位作家的写作风格。我们分析的名著和作家如下:
- The Strange Case of Dr. Jekyl and Mr. Hyde, Robert Louis Stevenson (hyde.txt)
- Treasure Island, Robert Louis Stevenson (treasure.txt)
- War and Peace, Leo Tolstoy (war.txt)
我们定义单词是连续的字母序列(小写或大写)。单词紧靠前的字符,以及紧随其后的字符是一个非字母。比如,缩写 we’re,我们把它看成两个单词 we 和 re。本次作业无需考虑诸如 we’re,other’的单词。
任务和步骤:
(1)编写函数 parse(string),接受字符串参数 string,并返回一个列表。列表包含 string 中所有长度至少为 4 个字母的单词,且所有单词都为小写。例如 string 为
“Shenzhen’s big, beautiful and rich place”
则返回
[“Shenzhen”, “beautiful”, “rich”, “place”]
(2)编写函数 mostFrequentWords(filenames),接受参数 filenames,表示从文件filenames 中读取数据,函数返回类型不限制。
(3)统计两位作家最常用的 20 个单词。注意三部名著中有两部是 Robert Louis Stevenson 的,需要综合考虑此作家的两部名著,给出他最常用的 20 个单词。
大致思路:
①单词切分:
首先利用str.replace()函数将所有非法符号(标点符号,换行以及数字)转换成空格,便于接下来进行处理。完成空格替换后,使用str.split()函数以空格为界对单词进行切分。完成切分后遍历整个单词列表,丢弃换行,空单词以及长度不足4的单词。对于每个合法单词,将其转换成对应小写。
②频率统计:
首先按行获取文件读入到EOF结束,当读入是空行时直接忽略直到合法输入。对于非空行首先调用单词切分函数并获取返回的结果列表。遍历结果列表,如果在字典中可以找到,则对应值加一;若不能找到,则创建以单词字符串为键值的键值对,并赋值为1。遍历完全部输入流文件后即完成读入操作并关闭输入流。
③频率排序:
完成单词频率统计后,获取单词频率字典。为了便于以频率进行排序,首先遍历整个字典,然后以值为第一个元素,字典键值为第二个元素,构建元组,并以“单词——频率”元组构建列表。调用库函数sort()对列表进行升序后调用reverse()进行翻转成降序列表。此时列表即为以单词出现频率为降序的列表。
④输出结果:
完成前面的操作后,已经获得了有序的频率列表。只需遍历列表前20个元素,并进行依次输出即可。
源代码:
本题下,将分块依次展示源代码并进行讲解:
①引入string库:
import string
②定义切分单词函数:
# 定义切分单词函数
def parse(sentence):
# 去除标点符号换行以及数字
for ch in sentence:
if ch in string.punctuation or ch == '\n' or '0' <= ch <= '9':
sentence = sentence.replace(ch, " ")
# 利用空格完成切分
temp = sentence.split(' ')
# 倒序查找空列表或仅有换行列表并丢弃
for i in range(len(temp)-1, -1, -1):
# 丢弃空单词以及和长度不足4的单词
if len(temp[i]) < 4:
del temp[i]
continue
# 判换行
if temp[i] == '\n':
del temp[i]
continue
temp[i] = temp[i].lower()
return temp
L4-L6:遍历整个字符串,将非法字符替换为空格便于切分单词
L8:利用库函数split以空格为分界将单词切分存入列表中
L10-L20:遍历单词列表,首先剔除长度小于4的单词(L12-L14),其次去除空行(L16-L18)。最后将单词全部转换为小写(L19)。处理完后返回结果列表。
③定义单词频率字典:
# 定义单词频率字典
word_dic = {}
④定义读取数据函数:
# 定义读取数据函数
def mostFrequentWords(filenames):
inputFile = open(filenames, "r")
# 循环进行处理
while True:
# 按行读入
line = inputFile.readline()
# 如果为EOF则结束读入
if not line:
break
# 如果是空行则忽略
if line == '\n':
continue
# 对非空行进行处理
wordlist = parse(line)
# 使用字典保存频率
for temp in wordlist:
if temp in word_dic.keys():
word_dic[temp] += 1
else:
word_dic[temp] = 1
inputFile.close()
L3:获取输入流文件,对文章进行读入。
L5:通过循环对单词进行频率统计。
L7:获取输入流。
L9-L11:如果读入完成,则结束输入
L12-L14:如果是空行,则忽略
L16-L17:如果不是空行,则调用切分函数对单词进行切分并获得返回的结果列表
L20-L24:遍历结果列表中每个单词,如果能在字典中找到,则值加一;如果不能找到则以单词为键值,创建对应键值对。
⑤获取输入:
# 进行测试
# 首先读入对应的txt文件
mostFrequentWords('treasure.txt')
mostFrequentWords('hyde.txt')
⑥进行排序统计:
# 定义结果列表,便于进行排序
res = []
# 将字典转为元组列表,便于排序
for temp in word_dic:
tuple_temp = (word_dic[temp], temp)
res.append(tuple_temp)
# 进行排序
res.sort()
res.reverse()
L2:定义空列表方便对单词频率进行保存
L5-L7:以值和键值构建元组,并将元组存入列表,便于排序
L10-L11:进行降序排序
⑦结果输出:
# 输出结果
print("Result:")
for i in range(20):
print("Frequency:"+str(res[i][0])+" Word: "+str(res[i][1]))
遍历结果列表中前20个元素,并进行输出。
代码测试:
①通过《The Strange Case of Dr. Jekyl and Mr. Hyde》和《Treasure Island》两篇文章分析Robert Louis Stevenson的写作风格:
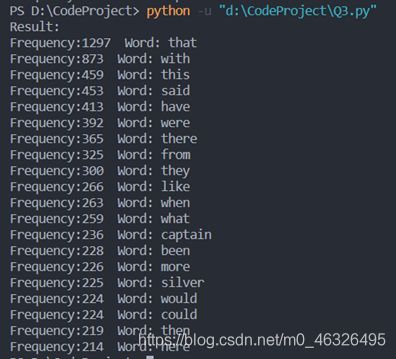
②通过《War and Peace》分析Leo Tolstoy的写作风格:
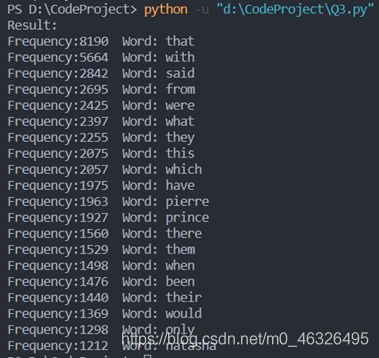
4. 字符匹配
生活中很多例子都涉及到字符串的“接近”问题。比如我们搜索 Pytho,搜索引擎会回答“您是指 Python 吗?”又如,科学家检查一些核苷酸序列,想知道基因序列 AGTCGTC 和 TAGTCGT 有多匹配,或者说有多接近。
本题要探讨的一个大问题是:什么时候我们可以认为一个字符串与另一个字符串接近?或者说,我们什么时候可以将一个字符串视为另一个字符串的“邻居”?这里的“邻居”有三种可能的定义:
- 如果两个字符串除了在一个位置上不一样,其他位置都一样,如“abc”和“abe”;
- 如果可以通过交换一个字符串中的两个相邻字符来获得另外一个字符串, 如“abc”和“acb”;
- 如果从一个字符串中删除一个字符可以生成另一个字符串,如 “abc”和“abxc”。
任务和步骤:
(1)编写函数 offByOne(str1,str2),输入参数为两个非空的字符串 str1 和str2。仅当 str1 和 str2 具有相同的长度并且只在一个位置上不同时,返回True。例如:
| str1 | str2 | return |
|---|---|---|
| “read” | “rexd” | True |
| “read” | “xexd” | False |
| “read” | “readx” | False |
| “read” | “eadx” | False |
| “a” | “x” | True |
| “a” | “a” | False |
| “a” | “A” | True |
(2)编写函数 offBySwap(str1,str2),输入参数为两个非空的字符串 str1 和str2。仅当 str1 不等于 str2,且可以将 str1 中任意两个相邻字符交换可以得到 str2 时,返回 True。 例如:
| str1 | str2 | return |
|---|---|---|
| “read” | “raed” | True |
| “read” | “erad” | True |
| “reaxd” | “read” | False |
| “read” | “erda” | False |
| “read” | “erbx” | False |
| “x” | “Y” | False |
| “aaa” | “aaa” | False |
(3)编写函数 offByExtra(str1,str2),输入参数为两个非空的字符串 str1 和str2。仅当从 str1 中删除一个字符可以得到 str2,或者从 str2 中删除一个字符可以得到 str1 时,返回 True。 例如
| str1 | str2 | return |
|---|---|---|
| “abcd” | “abxcd” | True |
| “abxcd” | “abcd” | True |
| “abcda” | “abcd” | True |
| “abcd” | “bcda” | False |
| “abcd” | “abcdef” | False |
| “abcd” | “abcd” | False |
(4)我们定义两个字符串 str1 和 str2 是邻居,仅当 str1 和 str2 不是同一个字符串, 并且三个函数 offByOne(str1,str2) , offBySwap(str1,str2) , offByExtra(str1,str2)中任意一个为 True。
按照上述定义,编写函数 ListOfNeighbors(str,L),输入参数 str 为字符串(要求全小写),L为字符串列表(见英文单词表 EnglishWords.txt),返回一个列表,为 L 中所有的str的邻居。
大致思路:
①offByOne(str1,str2)函数:
首先判断非法情况(两字符串相等,两字符串不等长,存在空字符串),对于非法情况直接返回False。对于合法情况,设定计数器,并对字符串进行遍历检查,记录下字符不同的数量并进行判断,如果计数器大于1则直接返回False。待字符串遍历完后,如果计数器的值为1,则返回True。
②offBySwap(str1,str2)函数:
首先判断非法情况(两字符串相等,两字符串不等长,存在空字符串),对于非法情况直接返回False。对于合法情况,如果进行暴力穷举,将花费更多时间,因此可以采用检测并尝试交换的方法将时间复杂度降至线性。设定标志变量列表,遍历字符串记录下不同字符的位置。当遍历结束后,如果标志变量列表的长度不为2,则直接返回False。判断交互字符是否对应相等,如果相等则返回True,否则返回False。
③offByExtra(str1,str2)函数:
首先判断非法情况(两字符串长度绝对值之差不等于1,两字符串不等长,存在空字符串),对于非法情况直接返回False。对于合法情况,定义变量记录不同字符的位置,遍历长度短的字符串进行比较并记录不同字符的位置。如果遍历完字符串后,标志变量仍为初始值,则说明仅有长字符串最后一个字符多余,则返回True;若标志变量不为初始值,则删去标志变量对应字符串的字符,并进行比较。如果相同则返回True,不相同返回False。
④统计结果并输出:
首先从输入中获取待判断的单词,并通过输入流加载整个EnglishWords.txt文件。并对文件进行预处理,将 文件按行读入列表后,去除列表元素中的空格以及换行。调用ListOfNeighbors函数进行判断,对于每个EnglishWords.txt文件中的单词,如果满足三个函数中的任意一个,则将其存入结果列表。处理完整个文件后返回结果列表。统计长度后进行输出。
源代码:
本题下,将分块依次展示源代码并进行讲解:
①offByOne(str1,str2)函数:
# 定义只有一个位置不同判定函数
def offByOne(str1, str2):
# 直接去除非法情况(两字符串不等长,存在空字符串,两字符串相等)
if len(str1) != len(str2) or str1 == str2 or len(str1) == 0 or len(str2) == 0:
return False
# 利用计数器进行计数,如果不一样的字符大于1则直接返回False
count = 0
for i in range(len(str1)):
if str1[i] != str2[i]:
count += 1
if count > 1:
return False
return True
L4:对非法情况进行特判处理
L8-L13:定义计数器对不同字符进行判断,当出现两个及两个以上不同字符时,直接返回False。
L14:若只有一个不同的字符,则返回True
②offBySwap(str1,str2)函数:
# 定义判断交换判定函数
def offBySwap(str1, str2):
# 直接去除非法情况(两字符串不等长,存在空字符串,两字符串相等)
if len(str1) != len(str2) or str1 == str2 or len(str1) <= 1 or len(str2) <= 1:
return False
# 定义标志变量列表
flag = []
# 遍历进行查找
for i in range(len(str1)):
if str1[i] != str2[i]:
flag.append(i)
# 如果存在大于2个不同,则返回False
if len(flag) > 2:
return False
# 如果不同的数量不为2,则返回False
if len(flag) != 2:
return False
# 判断并返回结果
return str1[flag[0]] == str2[flag[1]] and str2[flag[0]] == str1[flag[1]]
L4:对非法情况进行特判处理
L8-L18:设置标志变量并进行查找,遍历字符串并记录不同字符的下标存入标志变量列表中,并检测标志变量列表的大小,当大小大于2时,直接返回False。遍历完字符串后再检测标志变量列表的大小,如果不为2也返回False。
L21:最后判断交换的对应字符是否相等,如果相等返回True,否则返回False。
③offByExtra(str1,str2)函数:
# 定义删去一个判定函数
def offByExtra(str1, str2):
# 直接去除非法情况(两字符串长度差的绝对值不等于1,存在空字符串,两字符串相等)
if abs(len(str1)-len(str2)) != 1 or str1 == str2 or len(str1) == 0 or len(str2) == 0:
return False
# 记录不同字符位置
misIndex = -1
# 使str1为短字符串,方便后续处理
if len(str1) > len(str2):
str1, str2 = str2, str1
# 遍历进行查找,并记录不同字符位置
for i in range(len(str1)):
if str1[i] != str2[i]:
misIndex = i
break
# 如果除了最后一个字符都相同,则返回True
if misIndex == -1:
return True
# 利用字符切片,切去待删除字符
str2 = str2[:misIndex]+str2[misIndex+1:]
# 进行判断并返回结果
return str1 == str2
L4:对非法情况进行特判处理
L10-L11:将str1变成较短字符串方便处理
L14-L17:遍历短字符串依次查找并记录不同字符位置。
L20-L21:特判最后一个字符相同的情况
L24-L27:删除对应不同字符,判断两字符串是否相等如果相等返回True,如果不相等则返回False
代码测试:
①测试‘leap’的邻居:

②测试‘abcd’的邻居:

③测试‘apple’的邻居:
![]()
④测试‘ban’的邻居:

⑤测试‘python’的邻居:
![]()
心得与体会:
①Python编程过程中要善于使用系统库函数,可以方便高效快捷正确的完成一些操作。
例如:第一题中,借助了zip对矩阵元素进行正向收集,高效的完成了矩阵转置操作。
②对于一些需要进行检测出现频率的过程,可以选用“字典”结构进行高效快捷地完成。
例如:第三题中,借助字典完成了频率判断的操作,方便又快捷。
③算法的优化是不可忽视的。
在第四题中,由于输入数据比较大,因此需要尽量降低运行时间。对于offBySwap函数,可以通过线性检测的方式时间复杂度降低为线性,从而避免暴力的平方型时间复杂度。
④数据特判是解决特殊数据的好手段
在第四题中,对一些不符合情况的数据进行特判,可以提高程序的容错率,并且一定程度上提高程序运行效率,降低运行所需时间。
此外,在本次实验过程中,所有代码中均有很详细的注释,方便理解代码的逻辑。