mahout之旅---分布式推荐算法ALS-MR
Mahout分布式推荐系统——基于矩阵分解的协同过滤系统
1.实例环境
Mahout版本:mahout-0.9;
Hadoop版本:hadoop-1.2.1;
Jdk版本:java1.7.0_13
分布式系统:centos;
集群规模:master 、slavex、slavey、slavez
2.实例脚本
目前技术博文对mahout0.9版本的简介的也是不忍直视。这里系列博客对mahout0.9版本自带的基于矩阵分解的协同过滤系统算法的讲解。一个首先不管怎么样,先把程序跑起来,mahout自带了本例运行的脚本(factorize-movielens-1M.sh)核心内容分为五个部分操作。如下:
| #1.把原始数据转换成所需格式,注意在此之前还有一步就是上传原始数据到/user/yxb/mhadoop/data文件夹下。 原始数据格式如下,其结构为UserID::MovieID::Rating::Timestamp 1::1193::5::978300760 1::661::3::978302109 1::914::3::978301968 1::3408::4::978300275 1::2355::5::978824291 1::1197::3::978302268 1::1287::5::978302039 1::2804::5::978300719 1::594::4::978302268 1::919::4::978301368 cat /user/yxb/mhadoop/data/ratings.dat |sed -e s/::/,/g| cut -d, -f1,2,3 > /user/yxb/mhadoop/data/ratings.csv 经转换后的数据格式如下。其结构为UserID,MovieID,Rating。 1,1193,5 1,661,3 1,914,3 1,3408,4 1,2355,5 1,1197,3 1,1287,5 1,2804,5 1,594,4 1,919,4
#2.将数据集分成训练数据和测试数据:基本原理就是mapper函数产生合适的key值进行数据分裂。测试集(10%)和训练集(90%) mahout splitDataset -i /user/yxb/mhadoop/input/ratings.csv -o /user/yxb/mhadoop/dataset –t 0.9 –p 0.1 #3.并行ALS,进行矩阵分解 # run distributed ALS-WR to factorize the rating matrix defined by the training set mahout parallelALS -i /user/yxb/mhadoop/dataset/trainingSet/ -o /user/yxb/mhadoop/out --numFeatures 20 --numIterations 10 --lambda 0.065 #4.评价算法模型:使用的mahout命令是evaluateFactorization。可以在HDFS的 output/ rmse/rmse.txt文件中查看到均方根误差为:0.8548619405669956 # compute predictions against the probe set, measure the error mahout evaluateFactorization -i /user/yxb/mhadoop/dataset/probeSet/ -o /user/yxb/mhadoop/out/rmse/ --userFeatures /user/yxb/mhadoop/out/U/ --itemFeatures /user/yxb/mhadoop/out/M/ #5.推荐。为目标用户最多推荐6部电影 # compute recommendations mahout recommendfactorized -i /user/yxb/mhadoop/out/userRatings/ -o /user/yxb/mhadoop/recommendations/ --userFeatures /user/yxb/mhadoop/out/U/ --itemFeatures /user/yxb/mhadoop/out/M/ --numRecommendations 6 --maxRating 5 |
最终的推荐结果在/user/yxb/mhadoop/recommendations下:

源码分析
SplitDataset
其中splitDataset对应的mahout中的源java文件是:org.apache.mahout.cf.taste.
hadoop.als.DatasetSplitter.java 文件,打开这个文件,可以看到这个类是继承了AbstractJob的,所以需要覆写其run方法。run方法中含有所有的操作。Run方法里面有3个job。
| //数据集随机分裂(90%的训练集,10%的测试集) Job markPreferences = prepareJob(getInputPath(), markedPrefs, TextInputFormat.class,MarkPreferencesMapper.class,Text.class, Text.class, SequenceFileOutputFormat.class); //创建训练集 Job createTrainingSet = prepareJob(markedPrefs, trainingSetPath, SequenceFileInputFo rmat.class,WritePrefsMapper.class, NullWritable.class, Text.class, TextOutputFormat.class); //创建测试集 Job createProbeSet = prepareJob(markedPrefs, probeSetPath, SequenceFileInputFormat.class,WritePrefsMapper.class, NullWritable.class, Text.class, TextOutputFormat.class); |
Ø 第一个job
分裂数据集,job任务没有reducer,只有一个mapper,跟踪mapper就知道随机分裂的过程。其一是setup,其二是map。Setup通过random产生集合分布的[0,1]的随机数,因此通过控制阈值就可以将数据分成9:1,训练集边界trainingBound=0.9,randomValue<0.9时,打上T的标签作为key值,如此产生的90%的数据集就是训练集,剩下的打上P的标签作为测试数据集。
| private Random random; private double trainingBound; private doubleprobeBound; protected void setup(Context ctx) throws IOException, InterruptedException { random = RandomUtils.getRandom(); trainingBound = Double.parseDouble(ctx.getConfiguration().get( TRAINING_PERCENTAGE)); probeBound = trainingBound + Double.parseDouble(ctx.getConfiguration().get( PROBE_PERCENTAGE)); } @Override protected void map(LongWritable key, Text text, Context ctx) throws IOException, InterruptedException { double randomValue = random.nextDouble(); // trainingBound=0.9 probeBound=1.0 if (randomValue <= trainingBound) { ctx.write(INTO_TRAINING_SET, text); // T } else { ctx.write(INTO_PROBE_SET, text); // P } } |
Ø 第二个job
第二、三个任务,比较这两个任务,可以看到它们的不同之处只是在输入路径和输出路径,以及一些参数不同而已。而且也只是使用mapper,并没有使用reducer,那么打开WritePrefsMapper来看,这个mapper同样含有setup和map函数,setup函数则主要是获取是对T还是对P来进行处理。(任务2是创建训练集,因此标签是T)。
| private String partToUse; @Override protected void setup(Context ctx) throws IOException, InterruptedException { partToUse = ctx.getConfiguration().get(PART_TO_USE); // partToUse=T }
@Override protected void map(Text key, Text text,Context ctx) throws IOException, InterruptedException { if (partToUse.equals(key.toString())) { ctx.write(NullWritable.get(), text); } } |
Ø 第三个job(同上)
parallelALS
parallelALS对应的源文件是:org.apache.mahout.cf.taste.hadoop.als.ParallelA
LSFactorizationJob.java文件。Run方法里面的准备工作主要包括三个job,分别是itemRatings Job、userRatings Job和averageRatings Job。
首先来分析itemRatings Job,调用的语句分别是:
| Job itemRatings = prepareJob(getInputPath(), pathToItemRatings(), TextInputFormat.class, ItemRatingVectorsMapper.class, IntWritable.class, VectorWritable.class, VectorSumReducer.class,IntWritable.class, VectorWritable.class, SequenceFileOutputFormat.class); itemRatings.setCombinerClass(VectorSumCombiner.class); itemRatings.getConfiguration().set(USES_LONG_IDS, String.valueOf(usesLongIDs)); boolean succeeded = itemRatings.waitForCompletion(true); if (!succeeded) { return -1; } |
可以看出该job主要有一个mapper(ItemRatingVectorsMapper.class)和一个reducer(VectorSumReducer.class)构成。先来看看mapper类吧。
Mapper类的里面的map函数:提取用户ID和物品ID以及相应打分。
| protected void map(LongWritable offset, Text line, Context ctx) throws IOException, InterruptedException { String[] tokens = TasteHadoopUtils.splitPrefTokens(line.toString()); int userID = TasteHadoopUtils.readID(tokens[TasteHadoopUtils.USER_ID_POS], usesLongIDs); // userID int itemID = TasteHadoopUtils.readID(tokens[TasteHadoopUtils.ITEM_ID_POS], usesLongIDs); // itemID float rating = Float.parseFloat(tokens[2]); // rating ratings.setQuick(userID, rating); itemIDWritable.set(itemID); ratingsWritable.set(ratings); // String key=String.valueOf(itemID); // String sum = String.valueOf(ratings); // sysoutt(logpath+"log.txt", key,sum); ctx.write(itemIDWritable, ratingsWritable); // prepare instance for reuse ratings.setQuick(userID, 0.0d); } |
最后操作输出
| protected void reduce(WritableComparable key, Iterable throws IOException, InterruptedException { Vector sum = Vectors.sum(values.iterator()); result.set(new SequentialAccessSparseVector(sum)); ctx.write(key, result); } |
以《mahout实战》示例来说,这个job完成的就是如下所示:

接下来就是userRatings Job
| Job userRatings = prepareJob(pathToItemRatings(), pathToUserRatings(), TransposeMapper.class, IntWritable.class, VectorWritable.class, MergeUserVectorsReducer.class, IntWritable.class, VectorWritable.class); userRatings.setCombinerClass(MergeVectorsCombiner.class); succeeded = userRatings.waitForCompletion(true); if (!succeeded) { return -1; } |
他和itemRatings job工作方式差不多,经过mapreduce之后得到的示例效果就是:

准备工作的最后一个job,这个很重要,因为要用这个结果去构成一次迭代的M矩阵。这个就是averageItemRatingsjob,他是对itemRatings的每一个key对应的value值求平均值。
| Job averageItemRatings = prepareJob(pathToItemRatings(), getTempPath("averageRatings"), AverageRatingMapper.class, IntWritable.class, VectorWritable.class, MergeVectorsReducer.class, IntWritable.class, VectorWritable.class); averageItemRatings.setCombinerClass(MergeVectorsCombiner.class); succeeded = averageItemRatings.waitForCompletion(true); if (!succeeded) { return -1; } |
具体的mapreduce代码自行去查看吧,最后的效果如下:
![]()
接下里才是算法的开始。初始化M和for循环的交替迭代。M代表物品特征矩阵,U代表用户特征矩阵。For循环里面包含连个job,其功能就是通过固定的M求逼近的U,然后又通过这个U去求M,如此循环下去。最后满足for条件就退出。
接下来具体谈谈算法的实现过程:
初始化的M的核心代码就下面一点,如果你的java代码阅读功底还好的话应该就能看懂下面一段代码。初次形成的文件是M—1的文件。
| Vector row = new DenseVector(numFeatures); row.setQuick(0, e.get()); for (int m = 1; m < numFeatures; m++) { row.setQuick(m, random.nextDouble()); } index.set(e.index()); featureVector.set(row); writer.append(index, featureVector); |
看不懂也没关系,先贴出M—1的内容,估计就明白了。

是的,就是把averageRatings的内容作为第一列,然后用random函数生成(numFeatures-1)列的[0,1]随机数。简单吧!
接下来就是通过初始化的M求出U了,于是就进入了for循环,代码我看的吐了好几天了,再贴代码我又要吐了。这个算法不像网上说的那样什么QR分解。SVD算法是基于奇异值分解的算法。参考文献3里面就指出ASL算法比SVD算法更适合稀疏矩阵。
下面先通过一个示例来领略一下ALS的魅力所在吧。如下图,先随机初始化一个V,然后通过V求U,为了方便理解U也先给了一个初始化的值。这样不靠谱的做法,你会发现与真实的稀疏矩阵之间还是存在很大的差距。
当然会存在很大的差距,如果也能得到很小的rmse的话,那你可以去买彩票了。好了闲话不扯了,所以还是得求出U比较靠谱。算法的核心就是求出UV使得最大限度的逼近R,那么就好说了,就是求最小二乘解(做数据分析,矩阵论一定要学好,不然像我这样的学渣就痛苦了)。不好意思字差了一点,本人喜欢在纸上打草稿的形式推导公式。
![]()
通过一些推导就得到如下式:
![]()
如果不嫌字丑的话,这个推导式在后面还有。反正不管怎样通过上面一个这样的式子能够使预测矩阵与真实稀疏矩阵更接近,如下图求出V。
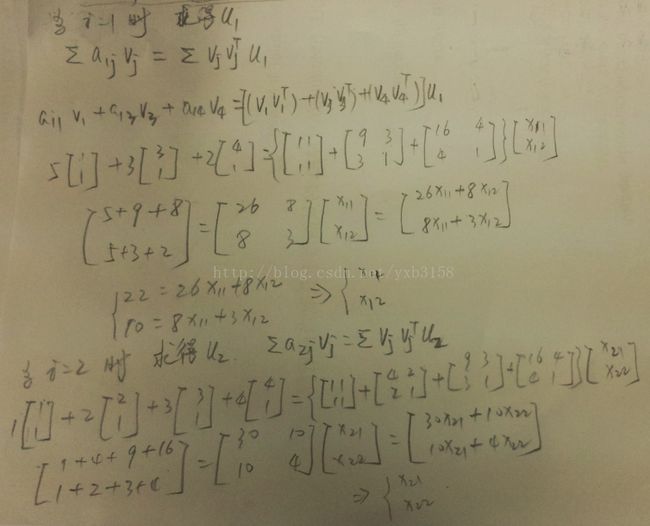
如果上图看懂了的话,那么这个算法你也基本上入门了。下面是一些原理性的数学公式。

这样求得的U是不是比随机取的要合理一点,但是追求完美的我们还是对结果不满意。那我们再固定U用同样的方法求M吧。现在问题来了,你会发现求出的M值没变。
接下来是算法升华的地方,ALS-WR算法全称是基于正则化的交替最小二乘法协同过滤算法。是不是一下豁达了,我们还有正则化没有考虑。上面的问题就是拟合不足造成的误差。如下图就是添加正则化后的修正函数。这里不再推导了,因为文献3已经做了这一步工作(字也比这个好看)。

如果你已经头大了的话,那就通过上面的示例来理解这个结论吧。
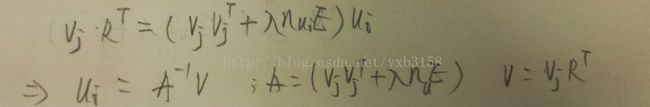
到这里paralleALS也基本上结束了。For循环里面有两个结构相同的job,那就是通过固定的M求U,然后又通过U来求更逼近的M。如果这里理解了是不是可以自己把代码写出来呢?
说实在的我对这个高大上的算法也是醉了,很好理解。但是很难实现,查看了很多技术博客基本上都是fansy1990的博文转载,并且里面对算法的讲解也是有迷惑性的,不过还是要特别感谢fansy1990,他的总体框架相当好,有大局观,给了我相当大的启发。基于此,痛苦了几天终于把它搞明白了。并且借鉴《互联网大规模数据挖掘与分布式处理》书里的方法写了一个示例来加深对算法的理解。
evaluator
好了,你说你已经得到了一对最逼近的用户特征矩阵U和物品特征矩阵M,那么到底有多接近呢?这个需要对算法进行评价。评估结果当然还是rmse(均方根误差)。在mahout中评价的文件是org.apache.mahout.cf.taste.hadoop.als.FactorizationEvaluator,文件中run方法只有一个predictRatings函数。
| Job predictRatings = prepareJob(getInputPath(), errors,TextInputFormat.class, PredictRatingsMapper.class,DoubleWritable.class, NullWritable.class, SequenceFileOutputFormat.class); |
Job里面只有一个map类,PredictRatingsMapper.class。PredictRatingsMapper可以看到它有setup和map函数,setup函数主要是把路径U和M中的数据load到一个变量里面,map的核心源码如下(矩阵的乘积):
| if (U.containsKey(userID) && M.containsKey(itemID)) { double estimate = U.get(userID).dot(M.get(itemID)); error.set(rating - estimate); ctx.write(error, NullWritable.get()); } |
Recommender
最后来到推荐部分,推荐使用的源码是在:org.apache.mahout.cf.taste.hadoop.als.RecommenderJob
run方法下只有一个prepareJob的job,里面包含mapper(MultithreadedSharingMapper.class)类。核心代码如下。
| public class PredictionMapper extends SharingMapper Pair<OpenIntObjectHashMap
private int recommendationsPerUser; private float maxRating;
private boolean usesLongIDs; private OpenIntLongHashMap userIDIndex; private OpenIntLongHashMap itemIDIndex;
private final LongWritable userIDWritable = new LongWritable(); private final RecommendedItemsWritable recommendations = new RecommendedItemsWritable();
@Override Pair<OpenIntObjectHashMap Configuration conf = ctx.getConfiguration(); Path pathToU = new Path(conf.get(RecommenderJob.USER_FEATURES_PATH)); Path pathToM = new Path(conf.get(RecommenderJob.ITEM_FEATURES_PATH));
OpenIntObjectHashMap OpenIntObjectHashMap
return new Pair<OpenIntObjectHashMap }
@Override protected void setup(Context ctx) throws IOException, InterruptedException { Configuration conf = ctx.getConfiguration(); recommendationsPerUser = conf.getInt(RecommenderJob.NUM_RECOMMENDATIONS, RecommenderJob.DEFAULT_NUM_RECOMMENDATIONS); maxRating = Float.parseFloat(conf.get(RecommenderJob.MAX_RATING));
usesLongIDs = conf.getBoolean(ParallelALSFactorizationJob.USES_LONG_IDS, false); if (usesLongIDs) { userIDIndex = TasteHadoopUtils.readIDIndexMap(conf.get(RecommenderJob.USER_INDEX_PATH), conf); itemIDIndex = TasteHadoopUtils.readIDIndexMap(conf.get(RecommenderJob.ITEM_INDEX_PATH), conf); } }
@Override protected void map(IntWritable userIndexWritable, VectorWritable ratingsWritable, Context ctx) throws IOException, InterruptedException {
Pair<OpenIntObjectHashMap OpenIntObjectHashMap OpenIntObjectHashMap
Vector ratings = ratingsWritable.get(); int userIndex = userIndexWritable.get(); final OpenIntHashSet alreadyRatedItems = new OpenIntHashSet(ratings.getNumNondefaultElements());
for (Vector.Element e : ratings.nonZeroes()) { alreadyRatedItems.add(e.index()); }
final TopItemsQueue topItemsQueue = new TopItemsQueue(recommendationsPerUser); final Vector userFeatures = U.get(userIndex);
M.forEachPair(new IntObjectProcedure @Override public boolean apply(int itemID, Vector itemFeatures) { if (!alreadyRatedItems.contains(itemID)) { double predictedRating = userFeatures.dot(itemFeatures);
MutableRecommendedItem top = topItemsQueue.top(); if (predictedRating > top.getValue()) { top.set(itemID, (float) predictedRating); topItemsQueue.updateTop(); } } return true; } });
List
if (!recommendedItems.isEmpty()) {
// cap predictions to maxRating for (RecommendedItem topItem : recommendedItems) { ((MutableRecommendedItem) topItem).capToMaxValue(maxRating); }
if (usesLongIDs) { long userID = userIDIndex.get(userIndex); userIDWritable.set(userID);
for (RecommendedItem topItem : recommendedItems) { // remap item IDs long itemID = itemIDIndex.get((int) topItem.getItemID()); ((MutableRecommendedItem) topItem).setItemID(itemID); }
} else { userIDWritable.set(userIndex); }
recommendations.set(recommendedItems); ctx.write(userIDWritable, recommendations); } } |
你不是很吝啬的贴代码吗?为什么现在贴这多,对,因为我也不想去分析了,头大了。。
参考文献
1.http://hijiangtao.github.io/2014/04/08/MahoutRecommendationExample/
2.http://jp.51studyit.com/article/details/98864.htm
3.http://m.blog.csdn.net/blog/ddjj131313/12586209