transformer-xl(片段级递归机制+相对位置编码)(wikitext-103 语言模型)
文章目录
- transformer-xl(片段级递归机制+相对位置编码)
- 一、文件目录
- 二、语料集
- 三、数据处理(data_utils.py)(vocabulary.py)
- 四、模型(mem_transformer.py)
- 五、训练(train.py)
- 六、计算loss值(proj_adaptive_softmax.py)
- 实验结果
transformer-xl(片段级递归机制+相对位置编码)
片段级递归机制:
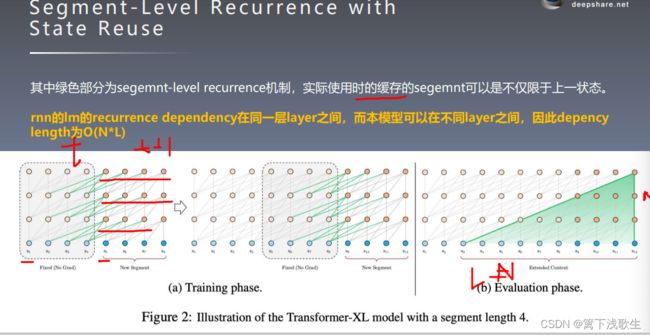
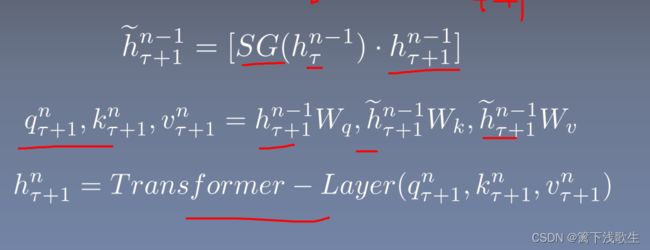
相对位置编码:




一、文件目录

二、语料集
wikitext-103
三、数据处理(data_utils.py)(vocabulary.py)
data_utils.py
import os, sys
import glob
from collections import Counter, OrderedDict
import numpy as np
import torch
from utils.vocabulary import Vocab
# 生成bach
# 函数调用:data_iter = LMOrderedIterator(self.train, *args, **kwargs)
class LMOrderedIterator(object):
def __init__(self, data, bsz, bptt, device='cpu', ext_len=None):
"""
data -- LongTensor -- the LongTensor is strictly ordered
"""
# bsz=60
self.bsz = bsz
# bptt=150
self.bptt = bptt
# ext_len=0
self.ext_len = ext_len if ext_len is not None else 0
self.device = device
# n_step=1720450 表示需要多少步操作1亿个token向量除以bsz
# Work out how cleanly we can divide the dataset into bsz parts.
self.n_step = data.size(0) // bsz
# 修剪掉多余部分(剩余部分)
# Trim off any extra elements that wouldn't cleanly fit (remainders).
data = data.narrow(0, 0, self.n_step * bsz)
#在bsz批处理中均匀分配数据 [1720450,60]
# Evenly divide the data across the bsz batches.
self.data = data.view(bsz, -1).t().contiguous().to(device)
# Number of mini-batches
self.n_batch = (self.n_step + self.bptt - 1) // self.bptt
def get_batch(self, i, bptt=None):
if bptt is None: bptt = self.bptt
# seq_len=152/148
seq_len = min(bptt, self.data.size(0) - 1 - i)
# end_idx=152/300
end_idx = i + seq_len
# beg_idx=0/152
beg_idx = max(0, i - self.ext_len)
# data = [0:152][60] [152:300][60]
data = self.data[beg_idx:end_idx]
# target = [1:153][60] [153:301][60]
target = self.data[i+1:i+1+seq_len]
return data, target, seq_len
def get_fixlen_iter(self, start=0):
for i in range(start, self.data.size(0) - 1, self.bptt):
yield self.get_batch(i)
def get_varlen_iter(self, start=0, std=5, min_len=5, max_deviation=3):
# max_len = 150+3*5=165
max_len = self.bptt + max_deviation * std
i = start
while True:
# bptt=150
bptt = self.bptt if np.random.random() < 0.95 else self.bptt / 2.
# bptt=152/148/146
bptt = min(max_len, max(min_len, int(np.random.normal(bptt, std))))
data, target, seq_len = self.get_batch(i, bptt)
i += seq_len
yield data, target, seq_len
# if i >= self.data.size(0) - 2:
if i >= 1000:
break
def __iter__(self):
return self.get_fixlen_iter()
class LMShuffledIterator(object):
def __init__(self, data, bsz, bptt, device='cpu', ext_len=None, shuffle=False):
"""
data -- list[LongTensor] -- there is no order among the LongTensors
"""
self.data = data
self.bsz = bsz
self.bptt = bptt
self.ext_len = ext_len if ext_len is not None else 0
self.device = device
self.shuffle = shuffle
def get_sent_stream(self):
# index iterator
epoch_indices = np.random.permutation(len(self.data)) if self.shuffle \
else np.array(range(len(self.data)))
# sentence iterator
for idx in epoch_indices:
yield self.data[idx]
def stream_iterator(self, sent_stream):
# streams for each data in the batch
streams = [None] * self.bsz
data = torch.LongTensor(self.bptt, self.bsz)
target = torch.LongTensor(self.bptt, self.bsz)
n_retain = 0
while True:
# data : [n_retain+bptt x bsz]
# target : [bptt x bsz]
data[n_retain:].fill_(-1)
target.fill_(-1)
valid_batch = True
for i in range(self.bsz):
n_filled = 0
try:
while n_filled < self.bptt:
if streams[i] is None or len(streams[i]) <= 1:
streams[i] = next(sent_stream)
# number of new tokens to fill in
n_new = min(len(streams[i]) - 1, self.bptt - n_filled)
# first n_retain tokens are retained from last batch
data[n_retain+n_filled:n_retain+n_filled+n_new, i] = \
streams[i][:n_new]
target[n_filled:n_filled+n_new, i] = \
streams[i][1:n_new+1]
streams[i] = streams[i][n_new:]
n_filled += n_new
except StopIteration:
valid_batch = False
break
if not valid_batch:
return
data = data.to(self.device)
target = target.to(self.device)
yield data, target, self.bptt
n_retain = min(data.size(0), self.ext_len)
if n_retain > 0:
data[:n_retain] = data[-n_retain:]
data.resize_(n_retain + self.bptt, data.size(1))
def __iter__(self):
# sent_stream is an iterator
sent_stream = self.get_sent_stream()
for batch in self.stream_iterator(sent_stream):
yield batch
class LMMultiFileIterator(LMShuffledIterator):
def __init__(self, paths, vocab, bsz, bptt, device='cpu', ext_len=None,
shuffle=False):
self.paths = paths
self.vocab = vocab
self.bsz = bsz
self.bptt = bptt
self.ext_len = ext_len if ext_len is not None else 0
self.device = device
self.shuffle = shuffle
def get_sent_stream(self, path):
sents = self.vocab.encode_file(path, add_double_eos=True)
if self.shuffle:
np.random.shuffle(sents)
sent_stream = iter(sents)
return sent_stream
def __iter__(self):
if self.shuffle:
np.random.shuffle(self.paths)
for path in self.paths:
# sent_stream is an iterator
sent_stream = self.get_sent_stream(path)
for batch in self.stream_iterator(sent_stream):
yield batch
# 数据处理:1.读取语料 2.构建词表 3.将token转换成index
# 函数调用: corpus = Corpus(datadir, dataset, **kwargs)
class Corpus(object):
def __init__(self, path, dataset, *args, **kwargs):
self.dataset = dataset
self.vocab = Vocab(*args, **kwargs)# *args表示它是一个可变数组
if self.dataset in ['ptb', 'wt2', 'enwik8', 'text8']:
self.vocab.count_file(os.path.join(path, 'train.txt'))
self.vocab.count_file(os.path.join(path, 'valid.txt'))
self.vocab.count_file(os.path.join(path, 'test.txt'))
elif self.dataset == 'wt103':
# 读取语料,转成token
self.vocab.count_file(os.path.join(path, 'train.txt'))
elif self.dataset == 'lm1b':
train_path_pattern = os.path.join(
path, '1-billion-word-language-modeling-benchmark-r13output',
'training-monolingual.tokenized.shuffled', 'news.en-*')
train_paths = glob.glob(train_path_pattern)
# the vocab will load from file when build_vocab() is called
# 构建词表
self.vocab.build_vocab()
if self.dataset in ['ptb', 'wt2', 'wt103']:
# 将token转换成index
self.train = self.vocab.encode_file(
os.path.join(path, 'train.txt'), ordered=True)
self.valid = self.vocab.encode_file(
os.path.join(path, 'valid.txt'), ordered=True)
self.test = self.vocab.encode_file(
os.path.join(path, 'test.txt'), ordered=True)
elif self.dataset in ['enwik8', 'text8']:
self.train = self.vocab.encode_file(
os.path.join(path, 'train.txt'), ordered=True, add_eos=False)
self.valid = self.vocab.encode_file(
os.path.join(path, 'valid.txt'), ordered=True, add_eos=False)
self.test = self.vocab.encode_file(
os.path.join(path, 'test.txt'), ordered=True, add_eos=False)
elif self.dataset == 'lm1b':
self.train = train_paths
self.valid = self.vocab.encode_file(
os.path.join(path, 'valid.txt'), ordered=False, add_double_eos=True)
self.test = self.vocab.encode_file(
os.path.join(path, 'test.txt'), ordered=False, add_double_eos=True)
# 调用:tr_iter = corpus.get_iterator('train', args.batch_size, args.tgt_len,device=device, ext_len=args.ext_len)
def get_iterator(self, split, *args, **kwargs):
if split == 'train':
if self.dataset in ['ptb', 'wt2', 'wt103', 'enwik8', 'text8']:
data_iter = LMOrderedIterator(self.train, *args, **kwargs)
elif self.dataset == 'lm1b':
kwargs['shuffle'] = True
data_iter = LMMultiFileIterator(self.train, self.vocab, *args, **kwargs)
elif split in ['valid', 'test']:
data = self.valid if split == 'valid' else self.test
if self.dataset in ['ptb', 'wt2', 'wt103', 'enwik8', 'text8']:
data_iter = LMOrderedIterator(data, *args, **kwargs)
elif self.dataset == 'lm1b':
data_iter = LMShuffledIterator(data, *args, **kwargs)
return data_iter
# 数据处理:1.读取语料 2.构建词表 3.将token转换成index
# 函数调用:corpus = get_lm_corpus(args.datadir, args.dataset)
def get_lm_corpus(datadir, dataset):
fn = os.path.join(datadir, 'cache.pt')
# 如果已存在cache.pt,就直接下载
if os.path.exists(fn):
print('Loading cached dataset...')
corpus = torch.load(fn)
else:
print('Producing dataset {}...'.format(dataset))
kwargs = {}
if dataset in ['wt103', 'wt2']:
kwargs['special'] = ['' ]
kwargs['lower_case'] = False
elif dataset == 'ptb':
kwargs['special'] = ['' ]
kwargs['lower_case'] = True
elif dataset == 'lm1b':
kwargs['special'] = []
kwargs['lower_case'] = False
kwargs['vocab_file'] = os.path.join(datadir, '1b_word_vocab.txt')
elif dataset in ['enwik8', 'text8']:
pass
# 数据处理:1.读取语料 2.构建词表 3.将token转换成index
corpus = Corpus(datadir, dataset, **kwargs)# **kwargs表示它是一个可变字典
torch.save(corpus, fn)
return corpus
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser(description='unit test')
parser.add_argument('--datadir', type=str, default='../data/wt103',
help='location of the data corpus')
parser.add_argument('--dataset', type=str, default='text8',
choices=['ptb', 'wt2', 'wt103', 'lm1b', 'enwik8', 'text8'],
help='dataset name')
args = parser.parse_args()
corpus = get_lm_corpus(args.datadir, args.dataset)
print('Vocab size : {}'.format(len(corpus.vocab.idx2sym)))
vocabulary.py
import os
from collections import Counter, OrderedDict
import torch
# 函数调用:self.vocab = Vocab(*args, **kwargs)
class Vocab(object):
def __init__(self, special=[], min_freq=0, max_size=None, lower_case=True,
delimiter=None, vocab_file=None):
self.counter = Counter()
self.special = special
self.min_freq = min_freq
self.max_size = max_size
self.lower_case = lower_case
self.delimiter = delimiter #分隔符
self.vocab_file = vocab_file #词表路径
# <---------对句子进行token split并且添加---->
# 函数调用:symbols = self.tokenize(line, add_eos=add_eos)
def tokenize(self, line, add_eos=False, add_double_eos=False):
line = line.strip()
# convert to lower case
if self.lower_case:
line = line.lower()
# empty delimiter '' will evaluate False
if self.delimiter == '':
symbols = line
else:
symbols = line.split(self.delimiter)
if add_double_eos: # lm1b
return [''] + symbols + ['']
elif add_eos:
return symbols + ['' ]
else:
return symbols
# <---------读取语料---->
# 函数调用:self.vocab.count_file(os.path.join(path, 'train.txt'))
def count_file(self, path, verbose=False, add_eos=False):
if verbose: print('counting file {} ...'.format(path))
assert os.path.exists(path)
sents = []
with open(path, 'r', encoding='utf-8') as f:
for idx, line in enumerate(f):
if verbose and idx > 0 and idx % 500000 == 0:
print(' line {}'.format(idx))
#对句子进行token split并且添加' ]
# <---------构建vocab---->
# <词典个数267735>
# 函数调用:self.vocab.build_vocab()
def build_vocab(self):
if self.vocab_file:
print('building vocab from {}'.format(self.vocab_file))
self._build_from_file(self.vocab_file)
print('final vocab size {}'.format(len(self)))
else:
print('building vocab with min_freq={}, max_size={}'.format(
self.min_freq, self.max_size))
self.idx2sym = []
self.sym2idx = OrderedDict()
for sym in self.special:
self.add_special(sym)
for sym, cnt in self.counter.most_common(self.max_size):
if cnt < self.min_freq: break
self.add_symbol(sym)
print('final vocab size {} from {} unique tokens'.format(
len(self), len(self.counter)))
# <---------将token转换成index---->
# <1801349句>
# 函数调用: self.train = self.vocab.encode_file(os.path.join(path, 'train.txt'), ordered=True)
def encode_file(self, path, ordered=False, verbose=False, add_eos=True,
add_double_eos=False):
if verbose: print('encoding file {} ...'.format(path))
assert os.path.exists(path)
encoded = []
with open(path, 'r', encoding='utf-8') as f:
for idx, line in enumerate(f):
if verbose and idx > 0 and idx % 500000 == 0:
print(' line {}'.format(idx))
symbols = self.tokenize(line, add_eos=add_eos,
add_double_eos=add_double_eos)
encoded.append(self.convert_to_tensor(symbols))
# [1,2,3,4]*[2,3,4,5]=[1,2,3,4,2,3,4,5]
if ordered:
encoded = torch.cat(encoded)
return encoded
def encode_sents(self, sents, ordered=False, verbose=False):
if verbose: print('encoding {} sents ...'.format(len(sents)))
encoded = []
for idx, symbols in enumerate(sents):
if verbose and idx > 0 and idx % 500000 == 0:
print(' line {}'.format(idx))
encoded.append(self.convert_to_tensor(symbols))
if ordered:
encoded = torch.cat(encoded)
return encoded
def add_special(self, sym):
if sym not in self.sym2idx:
self.idx2sym.append(sym)
self.sym2idx[sym] = len(self.idx2sym) - 1
setattr(self, '{}_idx'.format(sym.strip('<>')), self.sym2idx[sym])
def add_symbol(self, sym):
if sym not in self.sym2idx:
self.idx2sym.append(sym)
self.sym2idx[sym] = len(self.idx2sym) - 1
def get_sym(self, idx):
assert 0 <= idx < len(self), 'Index {} out of range'.format(idx)
return self.idx2sym[idx]
def get_idx(self, sym):
if sym in self.sym2idx:
return self.sym2idx[sym]
else:
# print('encounter unk {}'.format(sym))
assert '' not in sym
assert hasattr(self, 'unk_idx')
return self.sym2idx.get(sym, self.unk_idx)
def get_symbols(self, indices):
return [self.get_sym(idx) for idx in indices]
def get_indices(self, symbols):
return [self.get_idx(sym) for sym in symbols]
def convert_to_tensor(self, symbols):
return torch.LongTensor(self.get_indices(symbols))
def convert_to_sent(self, indices, exclude=None):
if exclude is None:
return ' '.join([self.get_sym(idx) for idx in indices])
else:
return ' '.join([self.get_sym(idx) for idx in indices if idx not in exclude])
def __len__(self):
return len(self.idx2sym)
四、模型(mem_transformer.py)
import sys
import math
import functools
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
#sys.path.append('utils')
from utils.proj_adaptive_softmax import ProjectedAdaptiveLogSoftmax
from utils.log_uniform_sampler import LogUniformSampler,sample_logits
#from proj_adaptive_softmax import ProjectedAdaptiveLogSoftmax
#from log_uniform_sampler import LogUniformSampler, sample_logits
# PositionalEmbedding
# 函数调用:self.pos_emb = PositionalEmbedding(self.d_model)
class PositionalEmbedding(nn.Module):
def __init__(self, demb):
super(PositionalEmbedding, self).__init__()
self.demb = demb
inv_freq = 1 / (10000 ** (torch.arange(0.0, demb, 2.0) / demb))
self.register_buffer('inv_freq', inv_freq)
def forward(self, pos_seq, bsz=None):
sinusoid_inp = torch.ger(pos_seq, self.inv_freq)
pos_emb = torch.cat([sinusoid_inp.sin(), sinusoid_inp.cos()], dim=-1)
if bsz is not None:
return pos_emb[:,None,:].expand(-1, bsz, -1)
else:
return pos_emb[:,None,:]
# feed-forward network
# 函数调用:self.pos_ff = PositionwiseFF(d_model, d_inner, dropout, pre_lnorm=kwargs.get('pre_lnorm'))
class PositionwiseFF(nn.Module):
def __init__(self, d_model, d_inner, dropout, pre_lnorm=False):
super(PositionwiseFF, self).__init__()
self.d_model = d_model
self.d_inner = d_inner
self.dropout = dropout
self.CoreNet = nn.Sequential(
nn.Linear(d_model, d_inner), nn.ReLU(inplace=True),
nn.Dropout(dropout),
nn.Linear(d_inner, d_model),
nn.Dropout(dropout),
)
self.layer_norm = nn.LayerNorm(d_model)
self.pre_lnorm = pre_lnorm
def forward(self, inp):
if self.pre_lnorm:
##### layer normalization + positionwise feed-forward
core_out = self.CoreNet(self.layer_norm(inp))
##### residual connection
output = core_out + inp
else:
##### positionwise feed-forward
core_out = self.CoreNet(inp)
##### residual connection + layer normalization
output = self.layer_norm(inp + core_out)
return output
class MultiHeadAttn(nn.Module):
def __init__(self, n_head, d_model, d_head, dropout, dropatt=0,
pre_lnorm=False):
super(MultiHeadAttn, self).__init__()
self.n_head = n_head
self.d_model = d_model
self.d_head = d_head
self.dropout = dropout
self.q_net = nn.Linear(d_model, n_head * d_head, bias=False)
self.kv_net = nn.Linear(d_model, 2 * n_head * d_head, bias=False)
self.drop = nn.Dropout(dropout)
self.dropatt = nn.Dropout(dropatt)
self.o_net = nn.Linear(n_head * d_head, d_model, bias=False)
self.layer_norm = nn.LayerNorm(d_model)
self.scale = 1 / (d_head ** 0.5)
self.pre_lnorm = pre_lnorm
def forward(self, h, attn_mask=None, mems=None):
##### multihead attention
# [hlen x bsz x n_head x d_head]
if mems is not None:
c = torch.cat([mems, h], 0)
else:
c = h
if self.pre_lnorm:
##### layer normalization
c = self.layer_norm(c)
head_q = self.q_net(h)
head_k, head_v = torch.chunk(self.kv_net(c), 2, -1)
head_q = head_q.view(h.size(0), h.size(1), self.n_head, self.d_head)
head_k = head_k.view(c.size(0), c.size(1), self.n_head, self.d_head)
head_v = head_v.view(c.size(0), c.size(1), self.n_head, self.d_head)
# [qlen x klen x bsz x n_head]
attn_score = torch.einsum('ibnd,jbnd->ijbn', (head_q, head_k))
attn_score.mul_(self.scale)
if attn_mask is not None and attn_mask.any().item():
if attn_mask.dim() == 2:
attn_score.masked_fill_(attn_mask[None,:,:,None], -float('inf'))
elif attn_mask.dim() == 3:
attn_score.masked_fill_(attn_mask[:,:,:,None], -float('inf'))
# [qlen x klen x bsz x n_head]
attn_prob = F.softmax(attn_score, dim=1)
attn_prob = self.dropatt(attn_prob)
# [qlen x klen x bsz x n_head] + [klen x bsz x n_head x d_head] -> [qlen x bsz x n_head x d_head]
attn_vec = torch.einsum('ijbn,jbnd->ibnd', (attn_prob, head_v))
attn_vec = attn_vec.contiguous().view(
attn_vec.size(0), attn_vec.size(1), self.n_head * self.d_head)
##### linear projection
attn_out = self.o_net(attn_vec)
attn_out = self.drop(attn_out)
if self.pre_lnorm:
##### residual connection
output = h + attn_out
else:
##### residual connection + layer normalization
output = self.layer_norm(h + attn_out)
return output
# self-attention 继承这个类
class RelMultiHeadAttn(nn.Module):
def __init__(self, n_head, d_model, d_head, dropout, dropatt=0,
tgt_len=None, ext_len=None, mem_len=None, pre_lnorm=False):
super(RelMultiHeadAttn, self).__init__()
self.n_head = n_head
self.d_model = d_model
self.d_head = d_head
self.dropout = dropout
# 初始化q,k,v=[146,60,41*10]
# embedding * Q ,embedding * k,embedding * V
self.qkv_net = nn.Linear(d_model, 3 * n_head * d_head, bias=False)
self.drop = nn.Dropout(dropout)
self.dropatt = nn.Dropout(dropatt)
self.o_net = nn.Linear(n_head * d_head, d_model, bias=False)
self.layer_norm = nn.LayerNorm(d_model)
self.scale = 1 / (d_head ** 0.5)
self.pre_lnorm = pre_lnorm
def _parallelogram_mask(self, h, w, left=False):
mask = torch.ones((h, w)).byte()
m = min(h, w)
mask[:m,:m] = torch.triu(mask[:m,:m])
mask[-m:,-m:] = torch.tril(mask[-m:,-m:])
if left:
return mask
else:
return mask.flip(0)
def _shift(self, x, qlen, klen, mask, left=False):
if qlen > 1:
zero_pad = torch.zeros((x.size(0), qlen-1, x.size(2), x.size(3)),
device=x.device, dtype=x.dtype)
else:
zero_pad = torch.zeros(0, device=x.device, dtype=x.dtype)
if left:
mask = mask.flip(1)
x_padded = torch.cat([zero_pad, x], dim=1).expand(qlen, -1, -1, -1)
else:
x_padded = torch.cat([x, zero_pad], dim=1).expand(qlen, -1, -1, -1)
x = x_padded.masked_select(mask[:,:,None,None]) \
.view(qlen, klen, x.size(2), x.size(3))
return x
# 函数调用:BD = self._rel_shift(BD)
# 小trick real-shift
def _rel_shift(self, x, zero_triu=False):
# x:[qlen , rlen , bsz , n_head]=[146,296,60,10]
# 0矩阵:[146,1,60,10]
zero_pad = torch.zeros((x.size(0), 1, *x.size()[2:]),
device=x.device, dtype=x.dtype)
# x_padded:[146,297,60,10]
x_padded = torch.cat([zero_pad, x], dim=1)
# x_padded:[297,146,60,10]
x_padded = x_padded.view(x.size(1) + 1, x.size(0), *x.size()[2:])
# x:[146, 296, 60, 10] rel_shift
x = x_padded[1:].view_as(x)
# zero_triu=False
if zero_triu:
ones = torch.ones((x.size(0), x.size(1)))
x = x * torch.tril(ones, x.size(1) - x.size(0))[:,:,None,None]
return x
def forward(self, w, r, attn_mask=None, mems=None):
raise NotImplementedError
# self-attention层 相对位置编码
# 函数调用:self.dec_attn = RelPartialLearnableMultiHeadAttn(n_head, d_model,d_head, dropout, **kwargs)
class RelPartialLearnableMultiHeadAttn(RelMultiHeadAttn):
def __init__(self, *args, **kwargs):
super(RelPartialLearnableMultiHeadAttn, self).__init__(*args, **kwargs)
# 初始化( pistional encoding) r_head_k = [164,60,41*10]
self.r_net = nn.Linear(self.d_model, self.n_head * self.d_head, bias=False)
def forward(self, w, r, r_w_bias, r_r_bias, attn_mask=None, mems=None):
# w表示embedding,r表示pistional encoding
# w:[146,60,410] r:[146,1,60]
# qlen=146 rlen=146/296 bsz=60
qlen, rlen, bsz = w.size(0), r.size(0), w.size(1)
# 初始化q,k,v=[146,60,41*10]
# 初始化( pistional encoding) r_head_k = [164,60,41*10]
if mems is not None:
cat = torch.cat([mems, w], 0)
if self.pre_lnorm:
w_heads = self.qkv_net(self.layer_norm(cat))
else:
w_heads = self.qkv_net(cat)
r_head_k = self.r_net(r)
w_head_q, w_head_k, w_head_v = torch.chunk(w_heads, 3, dim=-1)
w_head_q = w_head_q[-qlen:]
else:
# pre_lnorm=False
if self.pre_lnorm:
w_heads = self.qkv_net(self.layer_norm(w))
else:
w_heads = self.qkv_net(w)
r_head_k = self.r_net(r)
w_head_q, w_head_k, w_head_v = torch.chunk(w_heads, 3, dim=-1)
klen = w_head_k.size(0)
# multihead的操作
# w_head_q=w_head_k=w_head_v:[146,60,10,41]
w_head_q = w_head_q.view(qlen, bsz, self.n_head, self.d_head) # qlen x bsz x n_head x d_head
w_head_k = w_head_k.view(klen, bsz, self.n_head, self.d_head) # klen x bsz x n_head x d_head
w_head_v = w_head_v.view(klen, bsz, self.n_head, self.d_head) # klen x bsz x n_head x d_head
# r_head_k:[146,10,41]
r_head_k = r_head_k.view(rlen, self.n_head, self.d_head) # rlen x n_head x d_head
# w_head_q=q r_w_bias=Ut w_head_k=k
# (w_head_q+r_w_bias)*w_head_k=qk+k*Ut
#### compute attention score
rw_head_q = w_head_q + r_w_bias # qlen x bsz x n_head x d_head
#AC=[146,146/296,60,10]
AC = torch.einsum('ibnd,jbnd->ijbn', (rw_head_q, w_head_k)) # qlen x klen x bsz x n_head
# w_head_q=q r_r_bias=Ri-j
# (w_head_q+r_r_bias)*r_head_k=(q+Vt)*WRi-j
rr_head_q = w_head_q + r_r_bias # qlen x bsz x n_head x d_head
#BD=[146,146/296,60,10]
BD = torch.einsum('ibnd,jnd->ijbn', (rr_head_q, r_head_k)) # qlen x rlen x bsz x n_head
# 小trick real-shift
BD = self._rel_shift(BD)
# [qlen x klen x bsz x n_head]
attn_score = AC + BD
# 除根号dk
attn_score.mul_(self.scale)
#### compute attention probability
# attn_mask.dim() == 3:
if attn_mask is not None and attn_mask.any().item():
if attn_mask.dim() == 2:
attn_score = attn_score.float().masked_fill(
attn_mask[None,:,:,None], -float('inf')).type_as(attn_score)
elif attn_mask.dim() == 3:
# 极小值填充
attn_score = attn_score.float().masked_fill(
attn_mask[:,:,:,None], -float('inf')).type_as(attn_score)
# softmax
# [qlen x klen x bsz x n_head]
attn_prob = F.softmax(attn_score, dim=1)
attn_prob = self.dropatt(attn_prob)
# softmax * v
attn_vec = torch.einsum('ijbn,jbnd->ibnd', (attn_prob, w_head_v))
# [qlen x bsz x n_head x d_head]
attn_vec = attn_vec.contiguous().view(
attn_vec.size(0), attn_vec.size(1), self.n_head * self.d_head)
##### linear projection
# a * Wo
attn_out = self.o_net(attn_vec)
attn_out = self.drop(attn_out)
# pre_lnorm = False
if self.pre_lnorm:
##### residual connection
output = w + attn_out
else:
##### residual connection + layer normalization
output = self.layer_norm(w + attn_out)
return output
class RelLearnableMultiHeadAttn(RelMultiHeadAttn):
def __init__(self, *args, **kwargs):
super(RelLearnableMultiHeadAttn, self).__init__(*args, **kwargs)
def forward(self, w, r_emb, r_w_bias, r_bias, attn_mask=None, mems=None):
# r_emb: [klen, n_head, d_head], used for term B
# r_w_bias: [n_head, d_head], used for term C
# r_bias: [klen, n_head], used for term D
qlen, bsz = w.size(0), w.size(1)
if mems is not None:
cat = torch.cat([mems, w], 0)
if self.pre_lnorm:
w_heads = self.qkv_net(self.layer_norm(cat))
else:
w_heads = self.qkv_net(cat)
w_head_q, w_head_k, w_head_v = torch.chunk(w_heads, 3, dim=-1)
w_head_q = w_head_q[-qlen:]
else:
if self.pre_lnorm:
w_heads = self.qkv_net(self.layer_norm(w))
else:
w_heads = self.qkv_net(w)
w_head_q, w_head_k, w_head_v = torch.chunk(w_heads, 3, dim=-1)
klen = w_head_k.size(0)
w_head_q = w_head_q.view(qlen, bsz, self.n_head, self.d_head)
w_head_k = w_head_k.view(klen, bsz, self.n_head, self.d_head)
w_head_v = w_head_v.view(klen, bsz, self.n_head, self.d_head)
if klen > r_emb.size(0):
r_emb_pad = r_emb[0:1].expand(klen-r_emb.size(0), -1, -1)
r_emb = torch.cat([r_emb_pad, r_emb], 0)
r_bias_pad = r_bias[0:1].expand(klen-r_bias.size(0), -1)
r_bias = torch.cat([r_bias_pad, r_bias], 0)
else:
r_emb = r_emb[-klen:]
r_bias = r_bias[-klen:]
#### compute attention score
rw_head_q = w_head_q + r_w_bias[None] # qlen x bsz x n_head x d_head
AC = torch.einsum('ibnd,jbnd->ijbn', (rw_head_q, w_head_k)) # qlen x klen x bsz x n_head
B_ = torch.einsum('ibnd,jnd->ijbn', (w_head_q, r_emb)) # qlen x klen x bsz x n_head
D_ = r_bias[None, :, None] # 1 x klen x 1 x n_head
BD = self._rel_shift(B_ + D_)
# [qlen x klen x bsz x n_head]
attn_score = AC + BD
attn_score.mul_(self.scale)
#### compute attention probability
if attn_mask is not None and attn_mask.any().item():
if attn_mask.dim() == 2:
attn_score.masked_fill_(attn_mask[None,:,:,None], -float('inf'))
elif attn_mask.dim() == 3:
attn_score.masked_fill_(attn_mask[:,:,:,None], -float('inf'))
# [qlen x klen x bsz x n_head]
attn_prob = F.softmax(attn_score, dim=1)
attn_prob = self.dropatt(attn_prob)
#### compute attention vector
attn_vec = torch.einsum('ijbn,jbnd->ibnd', (attn_prob, w_head_v))
# [qlen x bsz x n_head x d_head]
attn_vec = attn_vec.contiguous().view(
attn_vec.size(0), attn_vec.size(1), self.n_head * self.d_head)
##### linear projection
attn_out = self.o_net(attn_vec)
attn_out = self.drop(attn_out)
if self.pre_lnorm:
##### residual connection
output = w + attn_out
else:
##### residual connection + layer normalization
output = self.layer_norm(w + attn_out)
return output
class DecoderLayer(nn.Module):
def __init__(self, n_head, d_model, d_head, d_inner, dropout, **kwargs):
super(DecoderLayer, self).__init__()
self.dec_attn = MultiHeadAttn(n_head, d_model, d_head, dropout, **kwargs)
self.pos_ff = PositionwiseFF(d_model, d_inner, dropout,
pre_lnorm=kwargs.get('pre_lnorm'))
def forward(self, dec_inp, dec_attn_mask=None, mems=None):
output = self.dec_attn(dec_inp, attn_mask=dec_attn_mask,
mems=mems)
output = self.pos_ff(output)
return output
class RelLearnableDecoderLayer(nn.Module):
def __init__(self, n_head, d_model, d_head, d_inner, dropout,
**kwargs):
super(RelLearnableDecoderLayer, self).__init__()
self.dec_attn = RelLearnableMultiHeadAttn(n_head, d_model, d_head, dropout,
**kwargs)
self.pos_ff = PositionwiseFF(d_model, d_inner, dropout,
pre_lnorm=kwargs.get('pre_lnorm'))
def forward(self, dec_inp, r_emb, r_w_bias, r_bias, dec_attn_mask=None, mems=None):
output = self.dec_attn(dec_inp, r_emb, r_w_bias, r_bias,
attn_mask=dec_attn_mask,
mems=mems)
output = self.pos_ff(output)
return output
# 对每层定义sublayer: self-attention , feed-forward network
# 函数调用:RelPartialLearnableDecoderLayer(
# n_head, d_model, d_head, d_inner, dropout,
# tgt_len=tgt_len, ext_len=ext_len, mem_len=mem_len,
# dropatt=dropatt, pre_lnorm=pre_lnorm)
class RelPartialLearnableDecoderLayer(nn.Module):
def __init__(self, n_head, d_model, d_head, d_inner, dropout,
**kwargs):
super(RelPartialLearnableDecoderLayer, self).__init__()
# # self-attention层 相对位置编码
self.dec_attn = RelPartialLearnableMultiHeadAttn(n_head, d_model,
d_head, dropout, **kwargs)
self.pos_ff = PositionwiseFF(d_model, d_inner, dropout,
pre_lnorm=kwargs.get('pre_lnorm'))
def forward(self, dec_inp, r, r_w_bias, r_r_bias, dec_attn_mask=None, mems=None):
output = self.dec_attn(dec_inp, r, r_w_bias, r_r_bias,
attn_mask=dec_attn_mask,
mems=mems)
output = self.pos_ff(output)
return output
# 函数调用:self.word_emb = AdaptiveEmbedding(n_token, d_embed, d_model, cutoffs,div_val=div_val)
class AdaptiveEmbedding(nn.Module):
def __init__(self, n_token, d_embed, d_proj, cutoffs, div_val=1,
sample_softmax=False):
super(AdaptiveEmbedding, self).__init__()
self.n_token = n_token
self.d_embed = d_embed
self.cutoffs = cutoffs + [n_token]
self.div_val = div_val
self.d_proj = d_proj
self.emb_scale = d_proj ** 0.5
self.cutoff_ends = [0] + self.cutoffs
self.emb_layers = nn.ModuleList()
self.emb_projs = nn.ParameterList()
if div_val == 1:
self.emb_layers.append(
nn.Embedding(n_token, d_embed, sparse=sample_softmax>0)
)
if d_proj != d_embed:
self.emb_projs.append(nn.Parameter(torch.Tensor(d_proj, d_embed)))
else:
for i in range(len(self.cutoffs)):
l_idx, r_idx = self.cutoff_ends[i], self.cutoff_ends[i+1]
d_emb_i = d_embed // (div_val ** i)
self.emb_layers.append(nn.Embedding(r_idx-l_idx, d_emb_i))
self.emb_projs.append(nn.Parameter(torch.Tensor(d_proj, d_emb_i)))
def forward(self, inp):
if self.div_val == 1:
embed = self.emb_layers[0](inp)
if self.d_proj != self.d_embed:
embed = F.linear(embed, self.emb_projs[0])
else:
param = next(self.parameters())
inp_flat = inp.view(-1)
emb_flat = torch.zeros([inp_flat.size(0), self.d_proj],
dtype=param.dtype, device=param.device)
for i in range(len(self.cutoffs)):
l_idx, r_idx = self.cutoff_ends[i], self.cutoff_ends[i + 1]
mask_i = (inp_flat >= l_idx) & (inp_flat < r_idx)
indices_i = mask_i.nonzero().squeeze()
if indices_i.numel() == 0:
continue
inp_i = inp_flat.index_select(0, indices_i) - l_idx
emb_i = self.emb_layers[i](inp_i)
emb_i = F.linear(emb_i, self.emb_projs[i])
emb_flat.index_copy_(0, indices_i, emb_i)
embed = emb_flat.view(*inp.size(), self.d_proj)
embed.mul_(self.emb_scale)
return embed
# transformer-xl模型: self-attention , feed-forward network,Relative Positional Embedding
# 函数调用: model = MemTransformerLM(ntokens, args.n_layer, args.n_head, args.d_model,
# args.d_head, args.d_inner, args.dropout, args.dropatt,
# tie_weight=args.tied, d_embed=args.d_embed, div_val=args.div_val,
# tie_projs=tie_projs, pre_lnorm=args.pre_lnorm, tgt_len=args.tgt_len,
# ext_len=args.ext_len, mem_len=args.mem_len, cutoffs=cutoffs,
# same_length=args.same_length, attn_type=args.attn_type,
# clamp_len=args.clamp_len, sample_softmax=args.sample_softmax)
class MemTransformerLM(nn.Module):
def __init__(self, n_token, n_layer, n_head, d_model, d_head, d_inner,
dropout, dropatt, tie_weight=True, d_embed=None,
div_val=1, tie_projs=[False], pre_lnorm=False,
tgt_len=None, ext_len=None, mem_len=None,
cutoffs=[], adapt_inp=False,
same_length=False, attn_type=0, clamp_len=-1,
sample_softmax=-1):
super(MemTransformerLM, self).__init__()
self.n_token = n_token
# d_embed=410
d_embed = d_model if d_embed is None else d_embed
self.d_embed = d_embed
# d_model=410
self.d_model = d_model
# n_head=10
self.n_head = n_head
# d_head=41
self.d_head = d_head
self.word_emb = AdaptiveEmbedding(n_token, d_embed, d_model, cutoffs,
div_val=div_val)
self.drop = nn.Dropout(dropout)
# n_layer=16
self.n_layer = n_layer
# tgt_len=150 需要predict的token数目
self.tgt_len = tgt_len
# mem_len=150 memory的长度
self.mem_len = mem_len
# ext_len=0 是extended content的长度
self.ext_len = ext_len
self.max_klen = tgt_len + ext_len + mem_len
#定义模型的类型 0代表transfoemer-xl
self.attn_type = attn_type
# 对每层定义sublayer self-attention , feed-forward network
self.layers = nn.ModuleList()
if attn_type == 0: # the default attention
for i in range(n_layer):
self.layers.append(
RelPartialLearnableDecoderLayer(
n_head, d_model, d_head, d_inner, dropout,
tgt_len=tgt_len, ext_len=ext_len, mem_len=mem_len,
dropatt=dropatt, pre_lnorm=pre_lnorm)
)
elif attn_type == 1: # learnable embeddings
for i in range(n_layer):
self.layers.append(
RelLearnableDecoderLayer(
n_head, d_model, d_head, d_inner, dropout,
tgt_len=tgt_len, ext_len=ext_len, mem_len=mem_len,
dropatt=dropatt, pre_lnorm=pre_lnorm)
)
elif attn_type in [2, 3]: # absolute embeddings
for i in range(n_layer):
self.layers.append(
DecoderLayer(
n_head, d_model, d_head, d_inner, dropout,
dropatt=dropatt, pre_lnorm=pre_lnorm)
)
# sample_softmax=-1
self.sample_softmax = sample_softmax
# use sampled softmax
if sample_softmax > 0:
self.out_layer = nn.Linear(d_model, n_token)
if tie_weight:
self.out_layer.weight = self.word_emb.weight
self.tie_weight = tie_weight
self.sampler = LogUniformSampler(n_token, sample_softmax)
# use adaptive softmax (including standard softmax)
else:
# 计算loss AdaptiveSoftmax
self.crit = ProjectedAdaptiveLogSoftmax(n_token, d_embed, d_model,
cutoffs, div_val=div_val)
# tie_weight=True
if tie_weight:
for i in range(len(self.crit.out_layers)):
self.crit.out_layers[i].weight = self.word_emb.emb_layers[i].weight
# tie_projs=[False]
if tie_projs:
for i, tie_proj in enumerate(tie_projs):
if tie_proj and div_val == 1 and d_model != d_embed:
self.crit.out_projs[i] = self.word_emb.emb_projs[0]
elif tie_proj and div_val != 1:
self.crit.out_projs[i] = self.word_emb.emb_projs[i]
# same_length=False
self.same_length = same_length
# clamp_len=-1
self.clamp_len = clamp_len
# 得到 Relative Positional Embedding
self._create_params()
def backward_compatible(self):
self.sample_softmax = -1
# 得到 Relative Positional Embedding
# 函数调用:self._create_params()
def _create_params(self):
# attn_type=0,代表transfoemer-xl
if self.attn_type == 0: # default attention
# PositionalEmbedding
self.pos_emb = PositionalEmbedding(self.d_model)
self.r_w_bias = nn.Parameter(torch.Tensor(self.n_head, self.d_head))
self.r_r_bias = nn.Parameter(torch.Tensor(self.n_head, self.d_head))
elif self.attn_type == 1: # learnable
self.r_emb = nn.Parameter(torch.Tensor(
self.n_layer, self.max_klen, self.n_head, self.d_head))
self.r_w_bias = nn.Parameter(torch.Tensor(
self.n_layer, self.n_head, self.d_head))
self.r_bias = nn.Parameter(torch.Tensor(
self.n_layer, self.max_klen, self.n_head))
elif self.attn_type == 2: # absolute standard
self.pos_emb = PositionalEmbedding(self.d_model)
elif self.attn_type == 3: # absolute deeper SA
self.r_emb = nn.Parameter(torch.Tensor(
self.n_layer, self.max_klen, self.n_head, self.d_head))
def reset_length(self, tgt_len, ext_len, mem_len):
self.tgt_len = tgt_len
self.mem_len = mem_len
self.ext_len = ext_len
def init_mems(self):
if self.mem_len > 0:
mems = []
param = next(self.parameters())
for i in range(self.n_layer+1):
empty = torch.empty(0, dtype=param.dtype, device=param.device)
mems.append(empty)
return mems
else:
return None
# 更新 mems
# 函数调用:new_mems = self._update_mems(hids, mems, mlen, qlen)
def _update_mems(self, hids, mems, qlen, mlen):
# does not deal with None
if mems is None: return None
# mems is not None
assert len(hids) == len(mems), 'len(hids) != len(mems)'
# There are `mlen + qlen` steps that can be cached into mems
# For the next step, the last `ext_len` of the `qlen` tokens
# will be used as the extended context. Hence, we only cache
# the tokens from `mlen + qlen - self.ext_len - self.mem_len`
# to `mlen + qlen - self.ext_len`.
with torch.no_grad():
new_mems = []
# mlen=146,qlen=0
# end_idx=146+max(0,0-0)=146
# end_idx=146+max(0,150)=296
end_idx = mlen + max(0, qlen - 0 - self.ext_len)
# beg_idx=max(0,146-150)=-4
# beg_idx=max(0,296-150)=146
beg_idx = max(0, end_idx - self.mem_len)
# hids:[146,60,410]
for i in range(len(hids)):
cat = torch.cat([mems[i], hids[i]], dim=0)
new_mems.append(cat[beg_idx:end_idx].detach())
return new_mems
# self-attention , feed-forward network
# 函数调用: hidden, new_mems = self._forward(data, mems=mems)
def _forward(self, dec_inp, mems=None):
# qlen=146, bsz=60
qlen, bsz = dec_inp.size()#qlen:max_len
# word_emb:[146,60,410]
word_emb = self.word_emb(dec_inp)
# mlen=0
mlen = mems[0].size(0) if mems is not None else 0
# klen=0+146=146
# klen=146+150=296
klen = mlen + qlen#总的长度
# same_length=True
if self.same_length:
# word_emb置1
all_ones = word_emb.new_ones(qlen, klen)
# mask_len=146
mask_len = klen - self.mem_len
if mask_len > 0:
# mask_shift_len=146-146=0
mask_shift_len = qlen - mask_len
else:
mask_shift_len = qlen
# 形成下三角矩阵
dec_attn_mask = (torch.triu(all_ones, 1+mlen)
+ torch.tril(all_ones, -mask_shift_len)).byte()[:, :, None] # -1
else:
dec_attn_mask = torch.triu(
word_emb.new_ones(qlen, klen), diagonal=1+mlen).byte()[:,:,None]
hids = []
# attn_type=0
if self.attn_type == 0: # default
#生成向量,维度等于word embedding
pos_seq = torch.arange(klen-1, -1, -1.0, device=word_emb.device,
dtype=word_emb.dtype)
# clamp_len=-1
if self.clamp_len > 0:
pos_seq.clamp_(max=self.clamp_len)
# pos_emb:[146,1,410]
pos_emb = self.pos_emb(pos_seq)
# core_out:[146,60,410]
core_out = self.drop(word_emb)
pos_emb = self.drop(pos_emb)
hids.append(core_out)
# 进入网络层:16层sublayer: self-attention , feed-forward network
for i, layer in enumerate(self.layers):
mems_i = None if mems is None else mems[i]
core_out = layer(core_out, pos_emb, self.r_w_bias,
self.r_r_bias, dec_attn_mask=dec_attn_mask, mems=mems_i)
hids.append(core_out)
elif self.attn_type == 1: # learnable
core_out = self.drop(word_emb)
hids.append(core_out)
for i, layer in enumerate(self.layers):
if self.clamp_len > 0:
r_emb = self.r_emb[i][-self.clamp_len :]
r_bias = self.r_bias[i][-self.clamp_len :]
else:
r_emb, r_bias = self.r_emb[i], self.r_bias[i]
mems_i = None if mems is None else mems[i]
core_out = layer(core_out, r_emb, self.r_w_bias[i],
r_bias, dec_attn_mask=dec_attn_mask, mems=mems_i)
hids.append(core_out)
elif self.attn_type == 2: # absolute
pos_seq = torch.arange(klen - 1, -1, -1.0, device=word_emb.device,
dtype=word_emb.dtype)
if self.clamp_len > 0:
pos_seq.clamp_(max=self.clamp_len)
pos_emb = self.pos_emb(pos_seq)
core_out = self.drop(word_emb + pos_emb[-qlen:])
hids.append(core_out)
for i, layer in enumerate(self.layers):
mems_i = None if mems is None else mems[i]
if mems_i is not None and i == 0:
mems_i += pos_emb[:mlen]
core_out = layer(core_out, dec_attn_mask=dec_attn_mask,
mems=mems_i)
hids.append(core_out)
elif self.attn_type == 3:
core_out = self.drop(word_emb)
hids.append(core_out)
for i, layer in enumerate(self.layers):
mems_i = None if mems is None else mems[i]
if mems_i is not None and mlen > 0:
cur_emb = self.r_emb[i][:-qlen]
cur_size = cur_emb.size(0)
if cur_size < mlen:
cur_emb_pad = cur_emb[0:1].expand(mlen-cur_size, -1, -1)
cur_emb = torch.cat([cur_emb_pad, cur_emb], 0)
else:
cur_emb = cur_emb[-mlen:]
mems_i += cur_emb.view(mlen, 1, -1)
core_out += self.r_emb[i][-qlen:].view(qlen, 1, -1)
core_out = layer(core_out, dec_attn_mask=dec_attn_mask,
mems=mems_i)
hids.append(core_out)
core_out = self.drop(core_out)
# 更新 mens
new_mems = self._update_mems(hids, mems, mlen, qlen)
return core_out, new_mems
def forward(self, data, target, *mems):
# mems初始化
if not mems: mems = self.init_mems()
# data, target:[146,60]
#tgt_len=146
tgt_len = target.size(0)
# 训练模型:self-attention feed-forward network
hidden, new_mems = self._forward(data, mems=mems)
pred_hid = hidden[-tgt_len:]
# sample_softmax=-1
if self.sample_softmax > 0 and self.training:
assert self.tie_weight
logit = sample_logits(self.word_emb,
self.out_layer.bias, target, pred_hid, self.sampler)
loss = -F.log_softmax(logit, -1)[:, :, 0]
else:
# 计算loss
loss = self.crit(pred_hid.view(-1, pred_hid.size(-1)), target.view(-1))
loss = loss.view(tgt_len, -1)
if new_mems is None:
return [loss]
else:
return [loss] + new_mems
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser(description='unit test')
parser.add_argument('--n_layer', type=int, default=4, help='')
parser.add_argument('--n_rel_layer', type=int, default=4, help='')
parser.add_argument('--n_head', type=int, default=2, help='')
parser.add_argument('--d_head', type=int, default=2, help='')
parser.add_argument('--d_model', type=int, default=200, help='')
parser.add_argument('--d_embed', type=int, default=200, help='')
parser.add_argument('--d_inner', type=int, default=200, help='')
parser.add_argument('--dropout', type=float, default=0.0, help='')
parser.add_argument('--cuda', action='store_true', help='')
parser.add_argument('--seed', type=int, default=1111, help='')
parser.add_argument('--multi_gpu', action='store_true', help='')
args = parser.parse_args()
device = torch.device("cuda" if args.cuda else "cpu")
B = 4
tgt_len, mem_len, ext_len = 36, 36, 0
data_len = tgt_len * 20
args.n_token = 10000
import data_utils
data = torch.LongTensor(data_len*B).random_(0, args.n_token).to(device)
diter = data_utils.LMOrderedIterator(data, B, tgt_len, device=device, ext_len=ext_len)
cutoffs = [args.n_token // 2]
tie_projs = [False] + [True] * len(cutoffs)
for div_val in [1, 2]:
for d_embed in [200, 100]:
model = MemTransformerLM(args.n_token, args.n_layer, args.n_head,
args.d_model, args.d_head, args.d_inner, args.dropout,
dropatt=args.dropout, tie_weight=True,
d_embed=d_embed, div_val=div_val,
tie_projs=tie_projs, pre_lnorm=True,
tgt_len=tgt_len, ext_len=ext_len, mem_len=mem_len,
cutoffs=cutoffs, attn_type=0).to(device)
print(sum(p.numel() for p in model.parameters()))
mems = tuple()
for idx, (inp, tgt, seqlen) in enumerate(diter):
print('batch {}'.format(idx))
out = model(inp, tgt, *mems)
mems = out[1:]
五、训练(train.py)
# coding: utf-8
import argparse
import time
import math
import os, sys
import itertools
import args as args
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from data_utils import get_lm_corpus
from mem_transformer import MemTransformerLM
from utils.exp_utils import create_exp_dir
from utils.data_parallel import BalancedDataParallel
parser = argparse.ArgumentParser(description='PyTorch Transformer Language Model')
parser.add_argument('--data', type=str, default='../data/wikitext-103',
help='location of the data corpus')
parser.add_argument('--dataset', type=str, default='wt103',
choices=['wt103', 'lm1b', 'enwik8', 'text8'],
help='dataset name')
parser.add_argument('--n_layer', type=int, default=12,
help='number of total layers')
parser.add_argument('--n_head', type=int, default=10,
help='number of heads')
parser.add_argument('--d_head', type=int, default=50,
help='head dimension')
parser.add_argument('--d_embed', type=int, default=-1,
help='embedding dimension')
parser.add_argument('--d_model', type=int, default=500,
help='model dimension')
parser.add_argument('--d_inner', type=int, default=1000,
help='inner dimension in FF')
parser.add_argument('--dropout', type=float, default=0.0,
help='global dropout rate')
parser.add_argument('--dropatt', type=float, default=0.0,
help='attention probability dropout rate')
parser.add_argument('--init', default='normal', type=str,
help='parameter initializer to use.')
parser.add_argument('--emb_init', default='normal', type=str,
help='parameter initializer to use.')
parser.add_argument('--init_range', type=float, default=0.1,
help='parameters initialized by U(-init_range, init_range)')
parser.add_argument('--emb_init_range', type=float, default=0.01,
help='parameters initialized by U(-init_range, init_range)')
parser.add_argument('--init_std', type=float, default=0.02,
help='parameters initialized by N(0, init_std)')
parser.add_argument('--proj_init_std', type=float, default=0.01,
help='parameters initialized by N(0, init_std)')
parser.add_argument('--optim', default='adam', type=str,
choices=['adam', 'sgd', 'adagrad'],
help='optimizer to use.')
parser.add_argument('--lr', type=float, default=0.00025,
help='initial learning rate (0.00025|5 for adam|sgd)')
parser.add_argument('--mom', type=float, default=0.0,
help='momentum for sgd')
parser.add_argument('--scheduler', default='cosine', type=str,
choices=['cosine', 'inv_sqrt', 'dev_perf', 'constant'],
help='lr scheduler to use.')
parser.add_argument('--warmup_step', type=int, default=0,
help='upper epoch limit')
parser.add_argument('--decay_rate', type=float, default=0.5,
help='decay factor when ReduceLROnPlateau is used')
parser.add_argument('--lr_min', type=float, default=0.0,
help='minimum learning rate during annealing')
parser.add_argument('--clip', type=float, default=0.25,
help='gradient clipping')
parser.add_argument('--clip_nonemb', action='store_true',
help='only clip the gradient of non-embedding params')
parser.add_argument('--max_step', type=int, default=100000,
help='upper epoch limit')
parser.add_argument('--batch_size', type=int, default=60,
help='batch size')
parser.add_argument('--batch_chunk', type=int, default=1,
help='split batch into chunks to save memory')
parser.add_argument('--tgt_len', type=int, default=70,
help='number of tokens to predict')
parser.add_argument('--eval_tgt_len', type=int, default=50,
help='number of tokens to predict for evaluation')
parser.add_argument('--ext_len', type=int, default=0,
help='length of the extended context')
parser.add_argument('--mem_len', type=int, default=0,
help='length of the retained previous heads')
parser.add_argument('--not_tied', action='store_true',
help='do not tie the word embedding and softmax weights')
parser.add_argument('--seed', type=int, default=1111,
help='random seed')
parser.add_argument('--cuda', action='store_true',
help='use CUDA')
parser.add_argument('--adaptive', action='store_true',
help='use adaptive softmax')
parser.add_argument('--div_val', type=int, default=1,
help='divident value for adapative input and softmax')
parser.add_argument('--pre_lnorm', action='store_true',
help='apply LayerNorm to the input instead of the output')
parser.add_argument('--varlen', action='store_true',
help='use variable length')
parser.add_argument('--multi_gpu', action='store_true',
help='use multiple GPU')
parser.add_argument('--log-interval', type=int, default=200,
help='report interval')
parser.add_argument('--eval-interval', type=int, default=4000,
help='evaluation interval')
parser.add_argument('--work_dir', default='LM-TFM', type=str,
help='experiment directory.')
parser.add_argument('--restart', action='store_true',
help='restart training from the saved checkpoint')
parser.add_argument('--restart_dir', type=str, default='',
help='restart dir')
parser.add_argument('--debug', action='store_true',
help='run in debug mode (do not create exp dir)')
parser.add_argument('--same_length', action='store_true',
help='use the same attn length for all tokens')
parser.add_argument('--attn_type', type=int, default=0,
help='attention type. 0 for ours, 1 for Shaw et al,'
'2 for Vaswani et al, 3 for Al Rfou et al.')
parser.add_argument('--clamp_len', type=int, default=-1,
help='use the same pos embeddings after clamp_len')
parser.add_argument('--eta_min', type=float, default=0.0,
help='min learning rate for cosine scheduler')
parser.add_argument('--gpu0_bsz', type=int, default=-1,
help='batch size on gpu 0')
parser.add_argument('--max_eval_steps', type=int, default=-1,
help='max eval steps')
parser.add_argument('--sample_softmax', type=int, default=-1,
help='number of samples in sampled softmax')
parser.add_argument('--patience', type=int, default=0,
help='patience')
parser.add_argument('--finetune_v2', action='store_true',
help='finetune v2')
parser.add_argument('--finetune_v3', action='store_true',
help='finetune v3')
parser.add_argument('--fp16', action='store_true',
help='Run in pseudo-fp16 mode (fp16 storage fp32 math).')
parser.add_argument('--static-loss-scale', type=float, default=1,
help='Static loss scale, positive power of 2 values can '
'improve fp16 convergence.')
parser.add_argument('--dynamic-loss-scale', action='store_true',
help='Use dynamic loss scaling. If supplied, this argument'
' supersedes --static-loss-scale.')
# args = parser.parse_args()
args.tied = False
# if args.d_embed < 0:
args.d_embed = args.d_model
# assert args.ext_len >= 0, 'extended context length must be non-negative'
# assert args.batch_size % args.batch_chunk == 0
args.work_dir="LM-TFM"
args.work_dir = '{}-{}'.format(args.work_dir, args.dataset)
args.work_dir = os.path.join(args.work_dir, time.strftime('%Y%m%d-%H%M%S'))
##########打印日志#############
logging = create_exp_dir(args.work_dir,
scripts_to_save=['train.py', 'mem_transformer.py'], debug=True)
# Set the random seed manually for reproducibility.
args.seed=1111
args.cuda=True
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if torch.cuda.is_available():
if not args.cuda:
print('WARNING: You have a CUDA device, so you should probably run with --cuda')
else:
torch.cuda.manual_seed_all(args.seed)
# Validate `--fp16` option
args.fp16=True
if args.fp16:
if not args.cuda:
print('WARNING: --fp16 requires --cuda, ignoring --fp16 option')
args.fp16 = False
else:
try:
from apex.fp16_utils import FP16_Optimizer
except:
print('WARNING: apex not installed, ignoring --fp16 option')
args.fp16 = False
device = torch.device('cuda' if args.cuda else 'cpu')
###############################################################################
# Load data
###############################################################################
# 数据处理:1.读取语料 2.构建词表 3.将token转换成index
corpus = get_lm_corpus(args.data, args.dataset)
ntokens = len(corpus.vocab)
args.n_token = ntokens
eval_batch_size = 10
args.ext_len=0
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 生成bach,分批训练
tr_iter = corpus.get_iterator('train', args.batch_size, args.tgt_len,
device=device, ext_len=args.ext_len)
va_iter = corpus.get_iterator('valid', eval_batch_size, args.eval_tgt_len,
device=device, ext_len=args.ext_len)
te_iter = corpus.get_iterator('test', eval_batch_size, args.eval_tgt_len,
device=device, ext_len=args.ext_len)
# 自适应softmax/嵌入
# adaptive softmax / embedding
cutoffs, tie_projs = [], [False]
args.adaptive=True
if args.adaptive:
assert args.dataset in ['wt103', 'lm1b']
if args.dataset == 'wt103':
cutoffs = [20000, 40000, 200000]
tie_projs += [True] * len(cutoffs)
elif args.dataset == 'lm1b':
cutoffs = [60000, 100000, 640000]
tie_projs += [False] * len(cutoffs)
###############################################################################
# Build the model
###############################################################################
args.init='normal'
args.init_std=0.02
def init_weight(weight):
if args.init == 'uniform':
nn.init.uniform_(weight, -args.init_range, args.init_range)
elif args.init == 'normal':
nn.init.normal_(weight, 0.0, args.init_std)
def init_bias(bias):
nn.init.constant_(bias, 0.0)
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Linear') != -1:
if hasattr(m, 'weight') and m.weight is not None:
init_weight(m.weight)
if hasattr(m, 'bias') and m.bias is not None:
init_bias(m.bias)
elif classname.find('AdaptiveEmbedding') != -1:
if hasattr(m, 'emb_projs'):
for i in range(len(m.emb_projs)):
if m.emb_projs[i] is not None:
nn.init.normal_(m.emb_projs[i], 0.0, args.proj_init_std)
elif classname.find('Embedding') != -1:
if hasattr(m, 'weight'):
init_weight(m.weight)
elif classname.find('ProjectedAdaptiveLogSoftmax') != -1:
if hasattr(m, 'cluster_weight') and m.cluster_weight is not None:
init_weight(m.cluster_weight)
if hasattr(m, 'cluster_bias') and m.cluster_bias is not None:
init_bias(m.cluster_bias)
if hasattr(m, 'out_projs'):
for i in range(len(m.out_projs)):
if m.out_projs[i] is not None:
nn.init.normal_(m.out_projs[i], 0.0, args.proj_init_std)
elif classname.find('LayerNorm') != -1:
if hasattr(m, 'weight'):
nn.init.normal_(m.weight, 1.0, args.init_std)
if hasattr(m, 'bias') and m.bias is not None:
init_bias(m.bias)
elif classname.find('TransformerLM') != -1:
if hasattr(m, 'r_emb'):
init_weight(m.r_emb)
if hasattr(m, 'r_w_bias'):
init_weight(m.r_w_bias)
if hasattr(m, 'r_r_bias'):
init_weight(m.r_r_bias)
if hasattr(m, 'r_bias'):
init_bias(m.r_bias)
def update_dropout(m):
classname = m.__class__.__name__
if classname.find('Dropout') != -1:
if hasattr(m, 'p'):
m.p = args.dropout
def update_dropatt(m):
if hasattr(m, 'dropatt'):
m.dropatt.p = args.dropatt
args.restart=False
args.dropatt=0.0
args.div_val=1
args.pre_lnorm=True
args.same_length=True
args.attn_type=0
args.clamp_len=-1
args.sample_softmax=-1
if args.restart:
with open(os.path.join(args.restart_dir, 'model.pt'), 'rb') as f:
model = torch.load(f)
if not args.fp16:
model = model.float()
model.apply(update_dropout)
model.apply(update_dropatt)
else:
# 创建transformer-xl模型: self-attention , feed-forward network,Relative Positional Embedding
model = MemTransformerLM(ntokens, args.n_layer, args.n_head, args.d_model,
args.d_head, args.d_inner, args.dropout, args.dropatt,
tie_weight=args.tied, d_embed=args.d_embed, div_val=args.div_val,
tie_projs=tie_projs, pre_lnorm=args.pre_lnorm, tgt_len=args.tgt_len,
ext_len=args.ext_len, mem_len=args.mem_len, cutoffs=cutoffs,
same_length=args.same_length, attn_type=args.attn_type,
clamp_len=args.clamp_len, sample_softmax=args.sample_softmax)
model.apply(weights_init)
model.word_emb.apply(weights_init) # 在权重共享的情况下,确保嵌入init不被out_层覆盖
# 优化器
args.n_all_param = sum([p.nelement() for p in model.parameters()])
args.n_nonemb_param = sum([p.nelement() for p in model.layers.parameters()])
if args.fp16:
model = model.half()
args.multi_gpu=False
# args.multi_gpu=False
if args.multi_gpu:
model = model.to(device)
if args.gpu0_bsz >= 0:
para_model = BalancedDataParallel(args.gpu0_bsz // args.batch_chunk,
model, dim=1).to(device)
else:
para_model = nn.DataParallel(model, dim=1).to(device)
else:
# model来源: model = MemTransformerLM()
para_model = model.to(device)
args.optim='adam'
#### optimizer
if args.optim.lower() == 'sgd':
if args.sample_softmax > 0:
dense_params, sparse_params = [], []
for param in model.parameters():
if param.size() == model.word_emb.weight.size():
sparse_params.append(param)
else:
dense_params.append(param)
optimizer_sparse = optim.SGD(sparse_params, lr=args.lr * 2)
optimizer = optim.SGD(dense_params, lr=args.lr, momentum=args.mom)
else:
optimizer = optim.SGD(model.parameters(), lr=args.lr,
momentum=args.mom)
elif args.optim.lower() == 'adam':
if args.sample_softmax > 0:
dense_params, sparse_params = [], []
for param in model.parameters():
if param.size() == model.word_emb.weight.size():
sparse_params.append(param)
else:
dense_params.append(param)
optimizer_sparse = optim.SparseAdam(sparse_params, lr=args.lr)
optimizer = optim.Adam(dense_params, lr=args.lr)
else:
optimizer = optim.Adam(model.parameters(), lr=args.lr)
elif args.optim.lower() == 'adagrad':
optimizer = optim.Adagrad(model.parameters(), lr=args.lr)
args.scheduler = 'cosine'
args.eta_min=0.0
#### scheduler
if args.scheduler == 'cosine':
# here we do not set eta_min to lr_min to be backward compatible
# because in previous versions eta_min is default to 0
# rather than the default value of lr_min 1e-6
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer,
args.max_step, eta_min=args.eta_min) # should use eta_min arg
if args.sample_softmax > 0:
scheduler_sparse = optim.lr_scheduler.CosineAnnealingLR(optimizer_sparse,
args.max_step, eta_min=args.eta_min) # should use eta_min arg
elif args.scheduler == 'inv_sqrt':
# originally used for Transformer (in Attention is all you need)
def lr_lambda(step):
# return a multiplier instead of a learning rate
if step == 0 and args.warmup_step == 0:
return 1.
else:
return 1. / (step ** 0.5) if step > args.warmup_step \
else step / (args.warmup_step ** 1.5)
scheduler = optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lr_lambda)
elif args.scheduler == 'dev_perf':
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer,
factor=args.decay_rate, patience=args.patience, min_lr=args.lr_min)
if args.sample_softmax > 0:
scheduler_sparse = optim.lr_scheduler.ReduceLROnPlateau(optimizer_sparse,
factor=args.decay_rate, patience=args.patience, min_lr=args.lr_min)
elif args.scheduler == 'constant':
pass
if args.cuda and args.fp16:
# If args.dynamic_loss_scale is False, static_loss_scale will be used.
# If args.dynamic_loss_scale is True, it will take precedence over static_loss_scale.
optimizer = FP16_Optimizer(optimizer,
static_loss_scale = args.static_loss_scale,
dynamic_loss_scale = args.dynamic_loss_scale,
dynamic_loss_args = {'init_scale': 2 ** 16})
if args.restart:
if os.path.exists(os.path.join(args.restart_dir, 'optimizer.pt')):
with open(os.path.join(args.restart_dir, 'optimizer.pt'), 'rb') as f:
opt_state_dict = torch.load(f)
optimizer.load_state_dict(opt_state_dict)
else:
print('Optimizer was not saved. Start from scratch.')
logging('=' * 100)
for k, v in args.__dict__.items():
logging(' - {} : {}'.format(k, v))
logging('=' * 100)
logging('#params = {}'.format(args.n_all_param))
logging('#non emb params = {}'.format(args.n_nonemb_param))
###############################################################################
# Training code
###############################################################################
def evaluate(eval_iter):
# Turn on evaluation mode which disables dropout.
model.eval()
# If the model does not use memory at all, make the ext_len longer.
# Otherwise, make the mem_len longer and keep the ext_len the same.
if args.mem_len == 0:
model.reset_length(args.eval_tgt_len,
args.ext_len+args.tgt_len-args.eval_tgt_len, args.mem_len)
else:
model.reset_length(args.eval_tgt_len,
args.ext_len, args.mem_len+args.tgt_len-args.eval_tgt_len)
# Evaluation
total_len, total_loss = 0, 0.
with torch.no_grad():
mems = tuple()
for i, (data, target, seq_len) in enumerate(eval_iter):
if args.max_eval_steps > 0 and i >= args.max_eval_steps:
break
ret = model(data, target, *mems)
loss, mems = ret[0], ret[1:]
loss = loss.mean()
total_loss += seq_len * loss.float().item()
total_len += seq_len
# Switch back to the training mode
model.reset_length(args.tgt_len, args.ext_len, args.mem_len)
model.train()
return total_loss / total_len
args.batch_chunk=1
args.varlen=True
args.clip=0.25
args.log_interval=200
args.eval_interval=4000
# 模型训练
def train():
# Turn on training mode which enables dropout.
global train_step, train_loss, best_val_loss, eval_start_time, log_start_time
model.train()
# args.batch_chunk=1
if args.batch_chunk > 1:
mems = [tuple() for _ in range(args.batch_chunk)]
else:
mems = tuple()
# 数据处理:1.读取语料 2.构建词表 3.将token转换成index
# 生成bach,分批训练
train_iter = tr_iter.get_varlen_iter() if args.varlen else tr_iter
for batch, (data, target, seq_len) in enumerate(train_iter):
model.zero_grad()
# args.batch_chunk=1
if args.batch_chunk > 1:
data_chunks = torch.chunk(data, args.batch_chunk, 1)
target_chunks = torch.chunk(target, args.batch_chunk, 1)
for i in range(args.batch_chunk):
data_i = data_chunks[i].contiguous()
target_i = target_chunks[i].contiguous()
ret = para_model(data_i, target_i, *mems[i])
loss, mems[i] = ret[0], ret[1:]
loss = loss.float().mean().type_as(loss) / args.batch_chunk
if args.fp16:
optimizer.backward(loss)
else:
loss.backward()
train_loss += loss.float().item()
# para_model来源: para_model = BalancedDataParallel(args.gpu0_bsz // args.batch_chunk,model, dim=1).to(device)
else:
# 模型
ret = para_model(data, target, *mems)
# 获得loss 和 mems
loss, mems = ret[0], ret[1:]
loss = loss.float().mean().type_as(loss)
if args.fp16:
optimizer.backward(loss)
else:
loss.backward()
train_loss += loss.float().item()
if args.fp16:
optimizer.clip_master_grads(args.clip)
else:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip)
optimizer.step()
if args.sample_softmax > 0:
optimizer_sparse.step()
# step-wise learning rate annealing
train_step += 1
if args.scheduler in ['cosine', 'constant', 'dev_perf']:
# linear warmup stage
if train_step < args.warmup_step:
curr_lr = args.lr * train_step / args.warmup_step
optimizer.param_groups[0]['lr'] = curr_lr
if args.sample_softmax > 0:
optimizer_sparse.param_groups[0]['lr'] = curr_lr * 2
else:
if args.scheduler == 'cosine':
scheduler.step(train_step)
if args.sample_softmax > 0:
scheduler_sparse.step(train_step)
elif args.scheduler == 'inv_sqrt':
scheduler.step(train_step)
if train_step % args.log_interval == 0:
cur_loss = train_loss / args.log_interval
elapsed = time.time() - log_start_time
log_str = '| epoch {:3d} step {:>8d} | {:>6d} batches | lr {:.3g} ' \
'| ms/batch {:5.2f} | loss {:5.2f}'.format(
epoch, train_step, batch+1, optimizer.param_groups[0]['lr'],
elapsed * 1000 / args.log_interval, cur_loss)
if args.dataset in ['enwik8', 'text8']:
log_str += ' | bpc {:9.5f}'.format(cur_loss / math.log(2))
else:
log_str += ' | ppl {:9.3f}'.format(math.exp(cur_loss))
logging(log_str)
train_loss = 0
log_start_time = time.time()
if train_step % args.eval_interval == 0:
val_loss = evaluate(va_iter)
logging('-' * 100)
log_str = '| Eval {:3d} at step {:>8d} | time: {:5.2f}s ' \
'| valid loss {:5.2f}'.format(
train_step // args.eval_interval, train_step,
(time.time() - eval_start_time), val_loss)
if args.dataset in ['enwik8', 'text8']:
log_str += ' | bpc {:9.5f}'.format(val_loss / math.log(2))
else:
log_str += ' | valid ppl {:9.3f}'.format(math.exp(val_loss))
logging(log_str)
logging('-' * 100)
# Save the model if the validation loss is the best we've seen so far.
if not best_val_loss or val_loss < best_val_loss:
if not args.debug:
with open(os.path.join(args.work_dir, 'model.pt'), 'wb') as f:
torch.save(model, f)
with open(os.path.join(args.work_dir, 'optimizer.pt'), 'wb') as f:
torch.save(optimizer.state_dict(), f)
best_val_loss = val_loss
# dev-performance based learning rate annealing
if args.scheduler == 'dev_perf':
scheduler.step(val_loss)
if args.sample_softmax > 0:
scheduler_sparse.step(val_loss)
eval_start_time = time.time()
if train_step == args.max_step:
break
# Loop over epochs.
train_step = 0
train_loss = 0
best_val_loss = None
log_start_time = time.time()
eval_start_time = time.time()
# At any point you can hit Ctrl + C to break out of training early.
try:
for epoch in itertools.count(start=1):
train()
if train_step == args.max_step:
logging('-' * 100)
logging('End of training')
break
except KeyboardInterrupt:
logging('-' * 100)
logging('Exiting from training early')
# Load the best saved model.
with open(os.path.join(args.work_dir, 'model.pt'), 'rb') as f:
model = torch.load(f)
para_model = model.to(device)
# Run on test data.
test_loss = evaluate(te_iter)
logging('=' * 100)
if args.dataset in ['enwik8', 'text8']:
logging('| End of training | test loss {:5.2f} | test bpc {:9.5f}'.format(
test_loss, test_loss / math.log(2)))
else:
logging('| End of training | test loss {:5.2f} | test ppl {:9.3f}'.format(
test_loss, math.exp(test_loss)))
logging('=' * 100)
六、计算loss值(proj_adaptive_softmax.py)
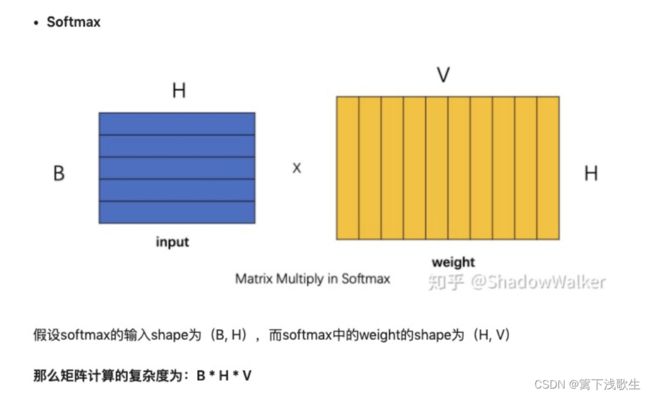
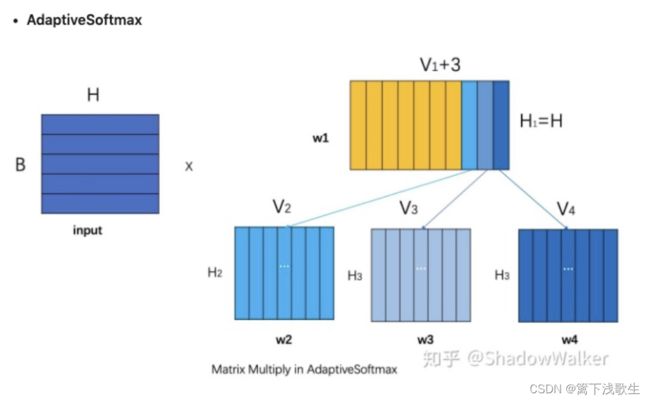

from collections import defaultdict
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
# CUDA_MAJOR = int(torch.version.cuda.split('.')[0])
# CUDA_MINOR = int(torch.version.cuda.split('.')[1])
# 函数调用:self.crit = ProjectedAdaptiveLogSoftmax(n_token, d_embed, d_model, cutoffs, div_val=div_val)
class ProjectedAdaptiveLogSoftmax(nn.Module):
def __init__(self, n_token, d_embed, d_proj, cutoffs, div_val=1,
keep_order=False):
super(ProjectedAdaptiveLogSoftmax, self).__init__()
# n_token 代表词典里的词语个数
self.n_token = n_token
# embedding维度 410
self.d_embed = d_embed
# 线性层:410
self.d_proj = d_proj
# v1,v2,v3,v4:[20000, 40000, 200000,267735]
self.cutoffs = cutoffs + [n_token]
# [0,20000, 40000, 200000,267735]
self.cutoff_ends = [0] + self.cutoffs
# div_val=1
self.div_val = div_val
# 20000
self.shortlist_size = self.cutoffs[0]
# 3
self.n_clusters = len(self.cutoffs) - 1
# 20003
self.head_size = self.shortlist_size + self.n_clusters
# self.n_clusters=3
if self.n_clusters > 0:
self.cluster_weight = nn.Parameter(torch.zeros(self.n_clusters, self.d_embed))
self.cluster_bias = nn.Parameter(torch.zeros(self.n_clusters))
# 初始化 out_projs,out_layers
self.out_layers = nn.ModuleList()
self.out_projs = nn.ParameterList()
# 定义 out_projs:4层 ,out_layers:线性层[d_embed, n_token]
# div_val=1
if div_val == 1:
# out_projs : 4层
for i in range(len(self.cutoffs)):
if d_proj != d_embed:
self.out_projs.append(
nn.Parameter(torch.Tensor(d_proj, d_embed))
)
else:
self.out_projs.append(None)
# out_layers : 线性层[d_embed, n_token]
self.out_layers.append(nn.Linear(d_embed, n_token))
else:
for i in range(len(self.cutoffs)):
l_idx, r_idx = self.cutoff_ends[i], self.cutoff_ends[i+1]
d_emb_i = d_embed // (div_val ** i)
self.out_projs.append(
nn.Parameter(torch.Tensor(d_proj, d_emb_i))
)
self.out_layers.append(nn.Linear(d_emb_i, r_idx-l_idx))
self.keep_order = keep_order
# 进入线性层
# 函数调用: head_logit = self._compute_logit(hidden, head_weight, head_bias, head_proj)
def _compute_logit(self, hidden, weight, bias, proj):
#映射成前面矩阵
if proj is None:
logit = F.linear(hidden, weight, bias=bias)
else:
# if CUDA_MAJOR <= 9 and CUDA_MINOR <= 1:
proj_hid = F.linear(hidden, proj.t().contiguous())
logit = F.linear(proj_hid, weight, bias=bias)
# else:
# logit = torch.einsum('bd,de,ev->bv', (hidden, proj, weight.t()))
# if bias is not None:
# logit = logit + bias
return logit
def forward(self, hidden, target, keep_order=False):
'''
hidden :: [len*bsz x d_proj]
target :: [len*bsz]
'''
if hidden.size(0) != target.size(0):
raise RuntimeError('Input and target should have the same size '
'in the batch dimension.')
# n_clusters=3
if self.n_clusters == 0:
logit = self._compute_logit(hidden, self.out_layers[0].weight,
self.out_layers[0].bias, self.out_projs[0])
nll = -F.log_softmax(logit, dim=-1) \
.gather(1, target.unsqueeze(1)).squeeze(1)
else:
# construct weights and biases
weights, biases = [], []
# v1,v2,v3,v4:[20000, 40000, 200000,267735]
for i in range(len(self.cutoffs)):
# div_val=1
if self.div_val == 1:
# 截取对应的weight和bias
l_idx, r_idx = self.cutoff_ends[i], self.cutoff_ends[i + 1]
weight_i = self.out_layers[0].weight[l_idx:r_idx]
bias_i = self.out_layers[0].bias[l_idx:r_idx]
else:
weight_i = self.out_layers[i].weight
bias_i = self.out_layers[i].bias
if i == 0:
weight_i = torch.cat(
[weight_i, self.cluster_weight], dim=0)
bias_i = torch.cat(
[bias_i, self.cluster_bias], dim=0)
# 将4个weight和bias放入weights和biases
weights.append(weight_i)
biases.append(bias_i)
head_weight, head_bias, head_proj = weights[0], biases[0], self.out_projs[0]
# hidden对应于预测[148*60,410] [len*bsz , d_proj]
# head_logit [148*60,20003]
head_logit = self._compute_logit(hidden, head_weight, head_bias, head_proj)
head_logprob = F.log_softmax(head_logit, dim=1)
# 初始换0矩阵:[148*60] len*bsz]
nll = torch.zeros_like(target,
dtype=hidden.dtype, device=hidden.device)
offset = 0
# [0,20000, 40000, 200000,267735]
cutoff_values = [0] + self.cutoffs
for i in range(len(cutoff_values) - 1):
# 0,20000
l_idx, r_idx = cutoff_values[i], cutoff_values[i + 1]
mask_i = (target >= l_idx) & (target < r_idx)
indices_i = mask_i.nonzero().squeeze()
#取出当前区间范围的index
if indices_i.numel() == 0:
continue
# target对应148*60=8880 target_i 对应的是8309
target_i = target.index_select(0, indices_i) - l_idx
head_logprob_i = head_logprob.index_select(0, indices_i)
if i == 0:
# target_i[:,None]=[8800,1]
# 取出对应的target位置的logprob
logprob_i = head_logprob_i.gather(1, target_i[:,None]).squeeze(1)
else:
weight_i, bias_i, proj_i = weights[i], biases[i], self.out_projs[i]
# 对应于低频的词,先直接计算hidden在这个区间位置的hidden_i
hidden_i = hidden.index_select(0, indices_i)
# 然后计算logprob
tail_logit_i = self._compute_logit(hidden_i, weight_i, bias_i, proj_i)
tail_logprob_i = F.log_softmax(tail_logit_i, dim=1)
# head_logprob_i的倒数第i列
logprob_i = head_logprob_i[:, -i] \
+ tail_logprob_i.gather(1, target_i[:,None]).squeeze(1)
if (hasattr(self, 'keep_order') and self.keep_order) or keep_order:
nll.index_copy_(0, indices_i, -logprob_i)
else:
nll[offset:offset+logprob_i.size(0)].copy_(-logprob_i)
offset += logprob_i.size(0)
return nll
实验结果
得到loss值