Pytorch搭建CNN进行图像分类
PyTorch是一个开源的Python机器学习库,2017年1月,由Facebook人工智能研究院(FAIR)基于Torch推出。最近抽出时间来亲身实践一下用PyTorch搭建一个简单的卷积神经网络进行图像分类。
全流程主要分为数据读取与处理、网络设计、训练和测试四个部分。
数据集处理
数据集我采用的是UCMerced数据集,这是一个用于遥感图像分类的数据集,共21类,包含农场、飞机等,每类有100张图像,图像尺寸大小为256*256。
我们按照训练集:测试集=3:1的比例对数据集进行分割,得到训练集图片1575张,测试集525张。然后分别对训练和测试数据的路径信息生成了txt文本。
整理完后的数据集长这样:

然后下面定义一个类用于数据的读取,然后按照比较固定的模式,在类中定义三个方法:
class ClsDataset(data_utils.Dataset):
def __init__(self):
pass
def __getitem__(self, item):
pass
def __len__(self):
pass
init方法主要是用于初始化一些类自有的属性,getitem方法主要用于读到数据集中的图片和其对应的标签,并将其转化为可输入CNN的格式,len方法就是返回数据集的大小。
首先来看init方法,我们需要在这个表示数据集的类中初始化哪些属性呢?最重要的肯定是我们得能找到输入CNN的图片都在哪,也就是我们要获得路径信息。这个路径信息在前面我们已经都放到txt文件里了,打开训练用的train.txt文件看一下格式:

很明显这是缺少根目录的,因此我们不仅要把这个txt文件中的路径信息导入,还需要加上一个根目录来让程序能在我们自己的电脑里找到这些图片。
因此,init可写为:
def __init__(self,root_path,data_file):
self.data_files=np.loadtxt(data_file,dtype=np.str)
self.root_path=root_path
这里我们之间用了numpy里面的方法去读取txt文件,而且让每一行都采用string类型。
除了读到图片以外,我们还需要知道这个数据集里都有哪些标签,这个标签的获取我们采用的是获取根目录下train文件夹中每个子文件夹名字的方式,需要用到os库:
def __init__(self,root_path,data_file,img_size=256):
self.data_files=np.loadtxt(data_file,dtype=np.str)
self.root_path=root_path
self.class_list=os.listdir(
os.path.join(root_path,'train')
)
处理到这目前我们能想到的需要定义的初始属性就差不多了,后面随写代码随需要再往里面添加即可。
写完init方法之后len方法就很好写了,它直接返回训练集或测试集的大小即可:
def __len__(self):
return len(self.data_files)
然后来看这个getitem方法。这个方法主要用于导入图片和标签,首先我们要先找到每张图片的路径并且把图片打开。这里输入的item参数就是用来确定在那个包含路径的txt文件里的第几张图片被打开。以训练的txt为例,上面图片中我们已经看到这个路径是不完整的,他缺少根目录,因此我们就需要把txt中的路径和根路径拼在一起。
def __getitem__(self, item):
data_file=self.data_files[item]
data_file=os.path.join(self.root_path,data_file)
img=Image.open(data_file)
打开了图片之后我们还需要获取图片的标签,还是回到上面那个训练的txt,我们观察到这张图片的上一级文件夹名字就是他的标签名,那么我们只需要找到其上一级文件夹即可。我们知道文件路径中的每一级都是由\或者/分开的,所以我们先统一这个分隔符,然后再按照统一后的分割符把这个路径分开,最后取倒数第二个作为标签。取到标签以后我们还得把他转成0,1,2,3等等这样的一个数,这个数我们就取之前定义的属性class_list中对应标签名字对应的索引(也就是在class_list里的位置):
data_file=data_file.replace('/','\\')
tmp=data_file.split('\\')
label_name=tmp[-2]
label=self.class_list.index(label_name)
最后完成我们还得把图片和标签都转化为pytorch能用的格式,也就是转成tensor类型。这里我比较倾向于在init中再定义一连串专门用于图像预处理的操作,举个例子虽然对于这个数据集我们可以确定已经提前将图片转化为了256*256的尺寸,但是可能有些数据集他的尺寸不是完全处理好的,因此我们如果提前再init中定义一连串的预处理操作,就可以直接在getitem中方便的调用即可。因此在init中添加:
self.transforms=torchvision.transforms.Compose(
[
torchvision.transforms.Resize((img_size,img_size)),
torchvision.transforms.ToTensor()
]
)
在getitem中就可以直接这样写:
img=self.transforms(img)
label=torch.tensor(label)
最后return图片和标签即可。
整个类完整代码如下:
class ClassifyDataset(data_utils.Dataset):
def __init__(self,root_path,data_file,img_size=256):
self.data_files=np.loadtxt(data_file,dtype=np.str)
self.root_path=root_path
self.class_list=os.listdir(
os.path.join(root_path,'train')
)
self.transforms=torchvision.transforms.Compose(
[
torchvision.transforms.Resize((img_size,img_size)),
torchvision.transforms.ToTensor()
]
)
def __getitem__(self, item):
data_file=self.data_files[item]
data_file=os.path.join(self.root_path,data_file)
img=Image.open(data_file)
data_file=data_file.replace('/','\\')
tmp=data_file.split('\\')
label_name=tmp[-2]
label=self.class_list.index(label_name)
img=self.transforms(img)
label=torch.tensor(label)
return img,label
def __len__(self):
return len(self.data_files)
网络定义
数据集处理完了我们就需要来设计网络结构,这里我们搭建了一个非常简单CNN:五个卷积层每层后面跟一个池化层,最后用全连接层做分类预测。我们先定义我们需要用到的各个层以及一些操作:
class CNet(nn.Module):
def __init__(self,num_classes=21):
super(CNet,self).__init__()
self.conv1=nn.Sequential(
nn.Conv2d(3,32,3,1,padding=1),
nn.BatchNorm2d(32),
nn.ReLU()
)
self.conv2 = nn.Sequential(
nn.Conv2d(32, 64, 3, 1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.conv3 = nn.Sequential(
nn.Conv2d(64, 128, 3, 1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.conv4 = nn.Sequential(
nn.Conv2d(128, 256, 3, 1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.conv5 = nn.Sequential(
nn.Conv2d(256, 512, 3, 1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU()
)
self.pool = nn.AvgPool2d(2, 2)
self.fclayer=nn.Sequential(
nn.Linear(512,1024),
nn.ReLU(),
nn.Linear(1024,num_classes)
)
self.avg_pool=nn.AdaptiveAvgPool2d((1,1))
self.softmax=nn.Softmax(dim=1)
注意init方法中super(CNet,self).__init__()这句话一定要有,这句话相当于提前找到我们定义的CNet类的父类nn.Module并初始化,如果不写就会报错。
对于这个网络我们在卷积层里做了如下操作:先33卷积然后再加一个BN最后再激活(通常来讲加BN效果会好一点)。nn.Conv2d里面的参数依次为:输入通道,输出通道,卷积核大小,步长,padding。
然后池化层就简单的转为22,且用的是平均池化。
最后分类的时候用的两个全连接层,输入512输出1024,过激活函数后,再由1024转为对应类别的通道数。
然后我们定义forward方法用于网络的前向传播:
def forward(self,x):
x = self.conv1(x)
x = self.pool(x)
x = self.conv2(x)
x = self.pool(x)
x = self.conv3(x)
x = self.pool(x)
x = self.conv4(x)
x = self.pool(x)
x = self.conv5(x)
x = self.pool(x)
x = self.avg_pool(x)
x = torch.flatten(x,1)
logits=self.fclayer(x)
prob=self.softmax(logits)
return logits,prob
这一部分只要清楚CNN的构造和逻辑就非常好写,由于本文重在实战,因此CNN的理论部分就不再赘述了。
训练
下面来写训练部分。训练和测试部分我没有封装直接放到主函数里了。
首先我们先定义一些训练可能会用到的参数:
root_path = r'自己的路径'
train_data_file= r'自己的路径\train.txt'
test_data_file=r'自己的路径\test.txt'
batch_size=8
lr=0.01
device='cuda:0'
前三个没什么好说的,batch_size这里我设置成8了,因为我的设备不允许再大了。lr即是学习率,这个自己可以根据情况设置。最后一行是指把训练放到GPU上进行,需要确保自己的电脑上有独显+显卡驱动与cuda、cudnn都下载好且匹配+安装好了适配本机cuda的gpu版本的pytorch。可以用下面语句检查可否使用:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
之后我们需要导入模型并把模型放到gpu上:
model=CNet()
model.to(device)
之后导入数据:
train_dataset=ClassifyDataset(root_path,train_data_file)
train_dataloader=data_utils.DataLoader(train_dataset,batch_size,shuffle=True,num_workers=0)
这个dataloader就是用来输入图片的,这里表示从train_daraset里以batch_size张为一组输入,shuffle代表是不是随机选图片,True就表示随机导入图片,numwork是一个多线程操作参数,这里先不用多线程。
然后定义损失函数和优化器,损失函数因为是分类采用交叉熵函数,优化器就简单用Adam:
criterion=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(model.parameters(),lr=lr)
model.parameters()代表优化全部参数。
随后设置训练的epoch,这里可以先设为10测试一下。
然后我这里还想可视化一下训练的loss,而且采用的是每一个epoch平均loss的形式取代替这个epoch,因此还要设置一个能放下每一epoch的loss的列表:
epoch_num=10
total_loss=[]
到这里我们的准备工作就已经完成了,然后进行训练部分的代码逻辑编写。
训练部分的逻辑是两层循环外层循环控制每一epoch,内层循环控制每一个dataloader。
我们先来看内层循环。
首先要获取dataloader中的data(也就是图片和标签),并把他们放到GPU上:
for data in train_dataloader:
train_img,train_label=data
train_img=train_img.to(device)
train_label=train_label.to(device)
然后把图片输入模型得到输出后和标签计算交叉熵loss:
train_logits,train_prob=model(train_img)
train_loss=criterion.forward(train_logits,train_label)
之后标准的三段式反向传播:
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
之后计算一下在这一个batch_size输入情况下的分类精度(这里指top1准确度,即找预测出来最大概率对应的标签,与真值标签对比,然后给batch_size中的结果做平均),并输出loss和精度:
train_pred=torch.argmax(train_prob,dim=1)
train_acc=(train_pred==train_label).float()
train_acc=torch.mean(train_acc)
print('loss:',train_loss.item(), 'acc:', train_acc.item())
最后我们套一个外层循环来表示每个epoch就好了,然后设置一下模型的保存规则(我这里是每五代保存一次):
for epoch in range(epoch_num):
## 内层循环代码
if (epoch+1)%5==0:
state_dict=model.state_dict()
torch.save(state_dict,'model.pth')
但是这样看很难直观的看出训练的情况,因此我在前面说想可视化一下训练的loss,用每一个epoch平均loss来代替这个epoch的训练loss。
在外层循环中,我们初始化这一epoch的平均loss,并且设置一个变量用于表示数据集中图片的余量(这个也是算这一epoch平均loss用的):
for epoch in range(epoch_num):
print(epoch+1,"epoch:")
total_train_loss=0
res_num=len(train_dataset)
然后在内层循环中,我们通过下面的逻辑来获取每次dataloader读入的图片数量cnt,以及目前数据集还剩下的余量res_num:
if (res_num - batch_size) > 0:
cnt=batch_size
res_num = res_num - batch_size
else:
cnt=res_num
res_num = 0
然后内层循环的最后,我们把这个dataloader的总loss算出来并且加到这一epoch的总loss上:
total_train_loss=total_train_loss+train_loss*cnt
然后在外层循环计算这个epoch的平均loss,并放到用于存储每个epoch的loss的列表中:
total_train_loss=total_train_loss/len(train_dataset)
total_loss.append(total_train_loss.item())
最后在所有的epoch都训练完后,我们画出图像:
plt.xlabel('epoch')
plt.ylabel('loss')
plt.plot(total_loss)
plt.legend(['train loss'])
plt.show()
我这里训练了100个epoch后得到的训练loss图像如下:
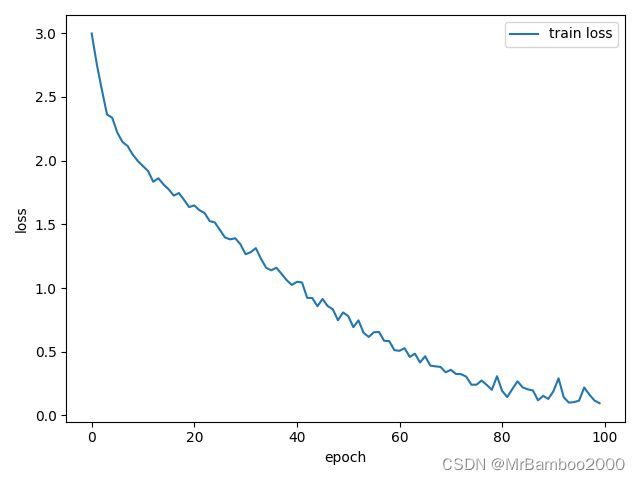
可以看到loss总体是下降的然后在七八十代大概进入了收敛阶段,开始波动。
完整训练代码如下:
# 训练代码
train_dataset=ClassifyDataset(root_path,train_data_file)
train_dataloader=data_utils.DataLoader(train_dataset,batch_size,shuffle=True,num_workers=0)
criterion=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(model.parameters(),lr=lr)
epoch_num=20
total_loss=[]
for epoch in range(epoch_num):
print(epoch+1,"epoch:")
total_train_loss=0
res_num=len(train_dataset)
for data in train_dataloader:
if (res_num - batch_size) > 0:
cnt=batch_size
res_num = res_num - batch_size
else:
cnt=res_num
res_num = 0
train_img,train_label=data
train_img=train_img.to(device)
train_label=train_label.to(device)
train_logits,train_prob=model(train_img)
train_loss=criterion.forward(train_logits,train_label)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
train_pred=torch.argmax(train_prob,dim=1)
train_acc=(train_pred==train_label).float()
train_acc=torch.mean(train_acc)
print('loss:',train_loss.item(), 'acc:', train_acc.item())
total_train_loss=total_train_loss+train_loss*cnt
total_train_loss=total_train_loss/len(train_dataset)
total_loss.append(total_train_loss.item())
# if (epoch+1)%5==0:
# state_dict=model.state_dict()
# torch.save(state_dict,'model_100_epoch.pth')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.plot(total_loss)
plt.legend(['train loss'])
plt.show()
测试
测试代码基本上可以照着训练代码写,只不过不需要进行反传(所以不需要定义优化器了),也不需要进行多轮epoch的测试。但是为了让让结果更加直观,我这里计算了分类问题常用的top1准确度和top5准确度这两个评价指标。这里我们先把代码都放在这里,重点讲一下两个指标的计算:
# 测试代码
state_dict = torch.load('model_50_epoch.pth')
model.load_state_dict(state_dict)
model.eval()
test_dataset=ClassifyDataset(root_path,test_data_file)
test_dataloader = data_utils.DataLoader(test_dataset, batch_size, shuffle=True, num_workers=0)
criterion = nn.CrossEntropyLoss()
res_num=len(test_dataset)
total_acc=0
total_top5_acc=0
for data in test_dataloader:
if (res_num-batch_size)>0:
cnt=batch_size
res_num = res_num - batch_size
else:
cnt=res_num
res_num = 0
test_img,test_label=data
test_img=test_img.to(device)
test_label=test_label.to(device)
test_logits,test_prob=model(test_img)
test_loss=criterion.forward(test_logits,test_label)
# Top1 准确率
test_pred = torch.argmax(test_prob, dim=1)
test_acc = (test_pred == test_label).float()
test_acc = torch.mean(test_acc)
total_acc = total_acc + test_acc * cnt
# Top5 准确率
_,test_top5_pred=test_logits.topk(5,1,True,True)
test_top5_acc=torch.eq(test_top5_pred,test_label.view(-1, 1)).sum().float().item()
total_top5_acc=total_top5_acc+test_top5_acc
print('loss:',test_loss.item(), 'top1:',test_acc.item() ,'top5:',test_top5_acc/cnt)
total_acc=total_acc/len(test_dataset)
total_top5_acc=total_top5_acc/len(test_dataset)
print('\n')
print('Top-1 Accuracy:',total_acc.item())
print('Top-5 Accuracy:', total_top5_acc)
需要注意的一点是,在进行预测时,一定要加model.eval(),这个方法的意义是不启用 BatchNormalization 和 Dropout,保证BN和dropout不发生变化。否则会对测试结果造成影响。
top1准确率的计算和上面训练loss的计算思路一致,就是我们算出每个进来的dataloader里面有几张图是正确分类(概率最大的那一类被判作是预测结果,和标签进行比较,一致则为正确分类)的,然后正确分类的图片累加,就可以得到整个测试集有多少图片正确分类。然后再除以测试集总图片数量,就得到了top1准确率。
top5准确率就相对来说比较复杂,我们这里借助了pytorch的自带的函数topk。官方中文文档给出的介绍如下:

我们需要的是他的第二个输出indices,即概率排在前五的元素的下标,也就是其预测最有可能的五个类别。
_,test_top5_pred=test_logits.topk(5,1,True,True)
然后就是用真值标签和预测标签进行比较,这里用到torch.eq()方法,这个方法会返回一个tensor,表明两个输入的按位置的对应关系。
我们输出一下作torch.eq()后的结果
print(torch.eq(test_top5_pred,test_label.view(-1, 1)))
发现是这么个东西:

也就是test_label.view(-1, 1)中的每个元素分别在test_top5_pred中的哪个位置,如果不存在则全为false。
然后我们再小小转化一下,.sum().float().item()依次表示求和、转为float然后再放到cpu上。
然后只需要累加起来最后除以测试集大小即可。
我测试了一下经过100epoch训练后的输出效果反不如50epoch训练后的结果,推测可能有点过拟合了。
下面是50epoch时的运行部分结果截图:
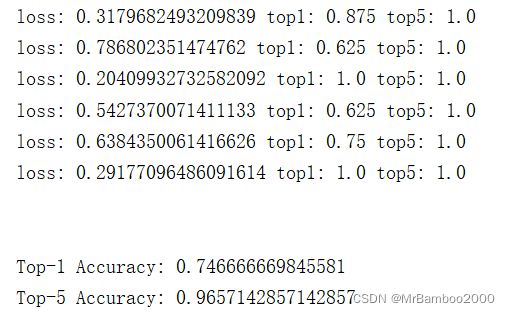
从上面运行结果就能看出来,其实我们这个CNN模型效果并不是特别好。毕竟这是我们随便搭的一个网络,其性能肯定是不如那些经典的网络结构(如vgg系列、resnet系列)。