实体解析/实体匹配:DeepER—Distributed Representations of Tuples for Entity Resolution文章阅读笔记
Distributed Representations of Tuples for Entity Resolution
写在前面:个人理解,如有错误请指出
1 INTRODUCTION
-
ER困难:随之而来的困难是大数据的规模、数量和来源的多样性迅速增加。
-
典型的ER任务流程
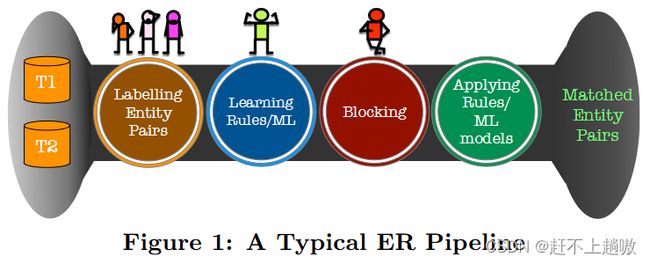
- STEP1:将实体对标注为匹配和非匹配。(人工标注数据集)
- STEP2:利用标记数据学习规则/ML模型。(用训练集进行模型训练,其中规则可以基于领域知识来手工制定)
- STEP3:分块操作,为了减少两两比较次数。(指定分块函数,生成块,使得匹配实体共存于同一块中。)
- STEP4:应用规则/ML模型。(测试模型)
-
ER任务挑战:需要人工干涉。减少人工,增加准确率。
-
ER任务观察:在步骤1中需要大量人力标注;在步骤2中需要专家制定相似性函数规则、阈值;在步骤3中只对少数属性制定阻断工作。
-
本文主要贡献
- 元组的分布式表示(词向量),该文章采用两种方式
- 将元组的每个token的分布式表示做平均
- 利用RNN和LSTM来进行整个元组的分布式表示
- 使用端到端的方法为ER任务定制DR
- 基于元组DRs和局部敏感哈希提出了两种高效的阻塞算法,考虑了所有属性的语义相关性
- 元组的分布式表示(词向量),该文章采用两种方式
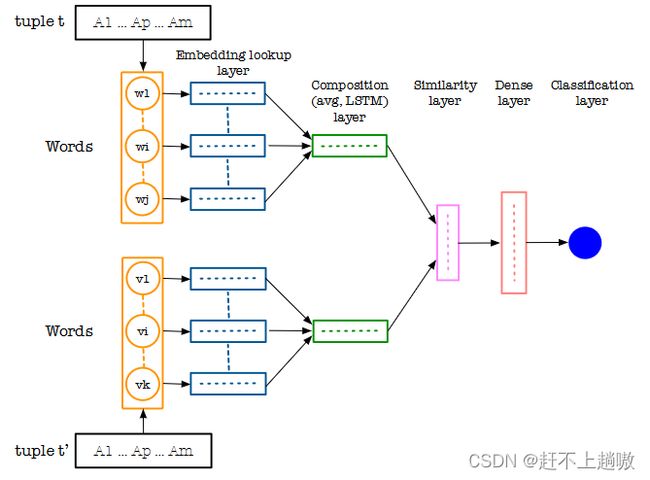
2 DISTRIBUTED REPRESENTATIONS OF TUPLES FOR ENTITY RESOLUTION
2.1 Entity Resolution(ER任务定义)
设T是具有 n 个元组,m 个属性 { A1,…,Am} 的实体集合。这些实体可以来自一个表或者多个表(具有可以对齐属性)。我们用 t[Ai] 表示属性Ai在元组t上的值。实体解析(ER)问题是给定来自T的所有不同元组对(t , t′),其中 t≠t′,判断哪些元组对指的是相同的现实世界实体。
2.3 Distributed Representations of Tuples
与词嵌入类似,给定一个元组,需要将其转换为一个向量表示,这样可以通过计算两个元组对应向量之间的距离来衡量它们之间的相似性。
-
一个元组 t 具有 m 个属性,记为 { A1,…,Am}。
用 v(t[Ak]) 来表示元组 t 中的 Ak 属性的分布式表示,也就是向量表示。
用 v(t) 来表示元组 t 的向量表示。
用 v(x) 来代表单词 x 的向量表示。
用|v|来代表向量v的维数。
-
实例
表1为两个元组,表2为单词向量表示。
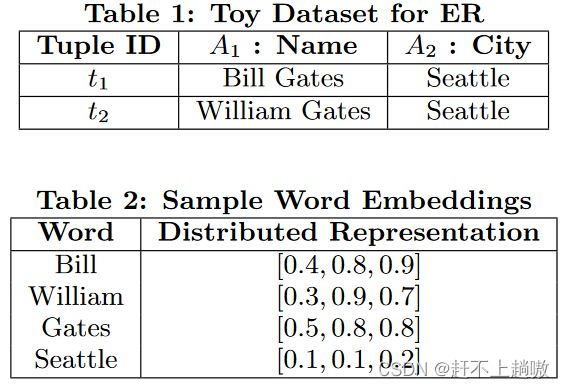
之后分别用两种方法来得到元组 t 的整体向量表示 v(t):
1)A Simple Approach – Averaging;
2)A Compositional Approach – RNN with LSTM
计算出元组的整体表示后,用向量计算相似性:Computing Distributional Similarity
- A Simple Approach – Averaging
- 首先将元组的每一个属性 t[Ak] 分解为单词,然后为每一个单词进行词向量嵌入。这块使用Glove进行嵌入。对于不在语料库中的词赋予UNK
- 在最初的方法中,一个属性的 t[Ak] 向量由构成属性的单词的词向量做平均来表示。而整个元组的向量表示由属性的向量表示聚合而成,例如每个属性由一个 d 维向量表示,那如果元组具有m个属性,其元组就由 |v(t)|=d×m 向量表示。每一列为一个属性的向量表示。
- A Compositional Approach – RNN with LSTM
-
A Simple Approach – Averaging忽略了语序
-
采用具有长短期记忆( LSTM )隐藏单元的单向和双向循环神经网络( RNN ),即LSTM - RNNs。RNNs通过对词进行处理,将所有属性值(即元组的词)的词序列编码成一个复合向量。
-
简单来说就是将构成一个元组的所有属性的单词的词向量输入LSTM,学习出来整个元组的向量表示。
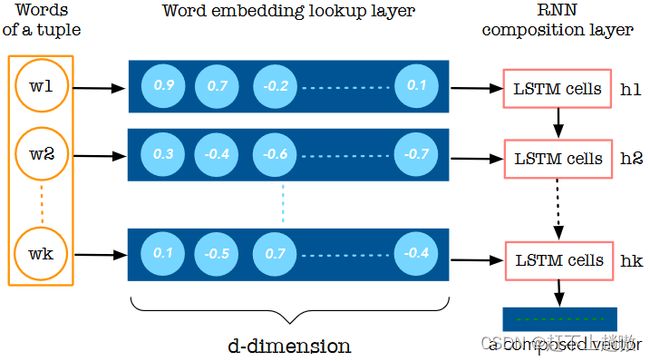
- Computing Distributional Similarity
- 有了两个元组的向量表示,之后计算他们之间的相似度。
- 对于用平均值计算的,计算相似度的方法是对于分别属于两个元组的每个 d 维向量,也就是表示一个属性的向量,分别对属于两个元组的所有的对应两个d维向量做余弦相似度计算
- 对于使用LSTM的向量表示,出来的是 x 维向量,可以使用向量差或乘法(hadamard product)相应的向量条目,从而得到一个 x 维的相似度向量。
2.4 ER as a Classification Problem using Distributed Representations of Tuples
ER通常被视为二分类问题,即输出匹配或不匹配。
计算出一对元组(t , t’)的分布式表示之后,计算其相似度,然后给出他们是否是匹配的,扔进SVM(决策树、随机森林等)分类器进行训练。
3 LEARNING AND TUNING DISTRIBUTED REPRESENTATIONS
学习和调整分布式表示。
用分布式表示来进行ER任务一般基于两个假设
- 对于数据集中大多数单词可以进行预训练的词向量表示。
- 以任务不可知的方式训练的预训练词嵌入足以用于ER任务。
3.1 General Data with Full Coverage
符合ER任务的两个假设。可以使用Glove转化元组为向量。之后进行相似性度量。
3.2 General Data with Partial Coverage
一些与ER任务有关的词汇并没有出现在Glove的语料库中,也就是不能进行词向量化。
本文倾向使用Vocabulary Retrofitting(词汇重组)来解决该问题。
设 W 为数据集中所有词语的集合,U 为其中不具有词嵌入向量的词语集合。为每个单词创建一个图的顶点,两个顶点( vi , vj)如果共同出现在某个元组中,则它们之间是连通的。如果出现在同一个属性中,也人为他们是连通的。对于属于 W 并且不属于 U 的词,我们给它分配词向量嵌入。对于属于 U 的词,我们将其初始值赋为其K个最频繁共现词的平均值。然后为每个单词w∈W创建一组新的顶点W′
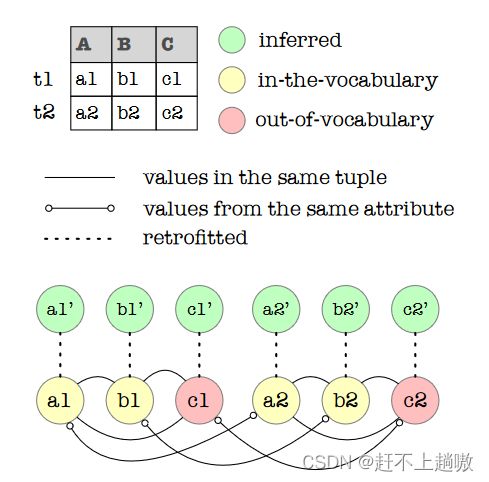
3.3 Specific Data with Minimal Coverage
最小覆盖率数据集。是特定的数据。
还有一种常见的情况是在有专门信息的数据集上执行ER。例如,对专门领域的科学文章或特定于组织的数据执行ER。在这种情况下,属性中往往包含GloVe字典中没有的深奥词汇。解决的方案有以下几种:
-
来自数据集的无监督表示
如果两个需要合并的数据集是足够大的话,可以自动学习词嵌入。
-
基于相关语料的无监督学习
如果数据集不够大,那么可以寻找另一个替代资源来学习词嵌入。GloVe和word2vec是分别通过在Common Crawl和Google News等大型语料库上训练学习词向量。如果能以文档等非结构化数据的形式找到类似领域信息的海量语料,则可用于学习该专业数据集的词向量。例如,虽然来自GloVe的词嵌入可能不知道p53和癌症相关,但从PubMed文章中训练的词嵌入可以。
-
自定义词嵌入
对于特定任务,设置词嵌入的先验方法。
3.4 Tuning Word Embeddings for an ER Task
4 BLOCKING FOR DISTRIBUTED REPRESENTATIONS
高效的ER系统使用Blocking的方法进行,因为两个 n×m 的表如果要进行ER任务,那么就需要比对2n次。时间复杂度非常高。Blocking技术将一些元组聚集到一块,成为blocks。只需要在块内进行ER任务,减少搜索空间,减少比较次数,但也存在着遗漏两个不同的块比较的缺点。
4.1 New Opportunities for Blocking
- 传统Blocking方法面临的挑战
- 需要专家协助
- Blocking 的规则通常只考虑少数的属性,那么很有可能出现一种情况就是将考虑的属性是相似的,但是其余的属性有非常大的不同,这种记录放在一个block里,这样是无意义的。
- 往往没有考虑元组间的语义相似性
- 通常很难调整blocking策略来控制召回率和/块的大小
- 使用LSH则避免了这些问题。
4.2 LSH Primer
- 定义1:一个哈希函数族H是对(R, cR, P1, P2)敏感的,那么对于任意两项p和q:

-
实施LSH
如果元组 t 和 t’ 是很相似的,那么它们哈希后的h(t)=h(t’)的概率应该很大。一个元组t用k个哈希函数来编码得到h1(t),h2(t),……,hk(t),用k维二进制向量来代表元素t(类似于k维的01向量),重复上述过程L次。每个元组被哈希到了L张表上,哈希码为g1(t),……,gL(t),g为k个h函数,也就是h1(t),h2(t),……,hk(t)的集合。例如k=10,L=2,则每个元组被一个10维二进制向量表示,并储存在两个表上。注意,L个不同的哈希表对应的是不同的g个函数,g也就是k个h哈希函数的集合,每一个哈希表内部是由该表对应的h个哈希函数h1(t),h2(t),……,hk(t)构造出来的代表t的二进制向量
-
基于Cosine Distance的哈希族
需要K个哈希函数h1,…,hK,因此我们随机选择K个超平面,并将每个元组与它们进行哈希运算,得到K维哈希码。然后对所有的L个哈希表重复这个过程。
4.3 LSH-based Blocking
基于LSH的Blocking。在这里使用的相似性度量是Cosine值。首先对L个哈希表利用随机超平面构建 K 个哈希函数h1,……,hk。就是利用这k个哈希函数将元组构建成k维的二进制向量,然后每一个二进制向量就相当于一个块,这样就把元组t分配到一个块中。
将元组t的DR表示(向量表示)索引到L个表上,LSH能让相似的元组DR具有相似的hash code,也就是具有相似的k维二进制向量,它们在同一个块中。之后考虑每个哈希表中的每个块,并对块中的不同的两个组成的一对应用分类器,看是匹配还是不匹配
举例说明:我们只对元组t1和t2的属性A1进行DR散列。令K = 4,L = 1。令哈希函数为h1 = [ -1 , 1 , 1],h2 = [ 1、1、1],h3 = [ -1 , -1 , 1]和h4 = [ -1 , 1 , -1],(代表h1,……,hk)。记v1 [ t1 ] = [ 0.45、0.8、0.85],v1 [ t2 ] = [ 0.4、0.85、0.75],(代表元组 t1 和元组 t2 的DR表示)。如果对每个 hi 做v1 [ t1 ]的点乘(做哈希操作),得到[ 0.86、1.53、- 0.26、- 0.39]。v1 [ t2 ]对应的输出为[ 0.86、1.46、- 0.33、- 0.26]。这两个输出也就是将元组的DR表示构建成k维的二进制向量。注意,LSH哈希码是通过阈值化使得正值得到+ 1,负值得到- 1的值得到的。因此这两个元组的哈希码均为[ 1 , 1 , -1 , -1]。证明在同一个桶中。
这样使用LSH的时间复杂度较高,为O( L × b2max × Bmax),其中L是哈希表的数量,bmax是任意哈希表中最大块的大小,Bmax是任意哈希表中非空块的最大数量。

4.4 Multi-Probe LSH for Blocking
==上一节中所讲的,通过增加K,我们保证了不相似元组落入相同块的概率降低。通过增加L,我们保证相似元组在L个哈希表中至少有一个落在同一个块中。==因此,当增加L确保我们不会错过一个真正的重复对时,它是以在非重复元组之间进行额外比较的额外代价来实现的。
本文期望提出基于LSH的算法来达到两个目标:
-
减少不必要的比较次数
-
在不严重影响召回的情况下,减少哈希表的数量L
-
减少不必要的比较
期望重复的元组之间具有较高的相似度,从而更有可能靠近彼此,因此即使一个块有大量的元组,也不需要比较所有元组对。
给定一个元组t,可以对其K个最近邻进行比对,来看匹不匹配。这是通过整理每个L哈希表中落入与t相同块的所有元组来实现的。然后计算t与每个候选元组的相似度,并返回前N个元组。只比对这N个即可。所以复杂度可以从b×b缩减到b×N。
-
减小L
其核心思想是对传统的LSH方案进行扩展,**通过精心设计的探测序列寻找多个桶(同一个哈希表的),这些桶(同一个哈希表的)能够以高概率包含相似的元组。**这种方法被称为multi-probe LSH。
根据LSH的性质,如果查询点q的近邻p没有被映射到q所在的桶,那么p很可能在q所在桶附近的桶中。multi-probe LSH的目的就是找到这些邻近的桶,增大找到q的近邻点的概率。
考虑一个元组t和另一个非常相似的元组t′。有可能t和t′不落入同一个桶(特别是当K较大时)。然而,由于LSH的设计,我们期望t′落入一个哈希码与t落入的桶非常相似的" close by "桶中。
例如,一个大小为1的multi-probe将考虑所有哈希码汉明距离为1的桶,以此类推,寻找符合该条件的桶。

4.5 Tuning LSH Parameters for Blocking
LSH可以控制Recall和占用率。
5 EXPERIMENTAL RESULTS
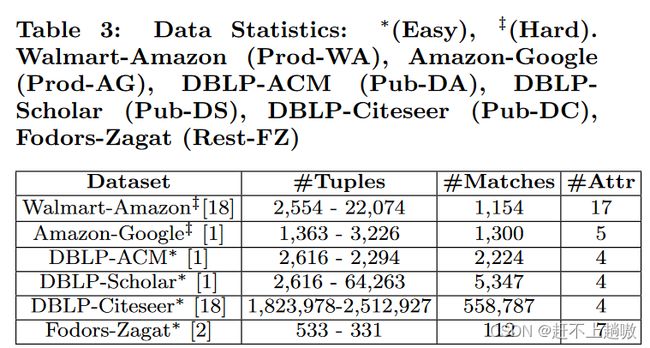
5.1 Experimental Setup
采用七个不同的数据集。将数据集分为两类:容易的和具有挑战的。容易的是结构化数据,具有较少噪声,现有的ER方法也都能达到0.9的F-score值。具有挑战性的数据集往往具有非结构化属性(如产品描述),这些属性也是噪声的。在我们研究的"挑战性"数据集上,ML和基于规则的方法都难以实现高F值,通常取值在0.6到0.7之间。这两个类别的共同之处在于它们需要领域专家的广泛努力来进行清洗、特征工程和阻塞以达到良好的效果。正如我们后面将要展示的,我们的方法以最小的专家努力在所有数据集上超过了现有最好的结果。
-
DeepER Setup
-
实验的Setup是对之前ER评估的改变,来处理DR。改变如下。
-
本文使用Cosine相似度来计算元组对之间的相似性系数,因为其更适合元组的分布式表示
-
本文不是任意地选取阈值,而是将其设置为训练数据集中匹配元组对的最小相似度。
-
-
DeepER Architecture
- 使用Glove来DR
- DL Model训练20epochs, batch size为16,学习率0.01,正则化参数1e-3
- 对于RNN - LSTM组合,使用单个RNN层,其中LSTM的记忆维度为150。相似度层的维度为50。当启用端到端学习时,嵌入更新率设置为0.01。
- 每一个元组由m × d维向量表示,其中m表示属性个数,d表示DR的维度。对于每一个属性,我们会使用标准的tokenizer并将Glove得到的DR做平均。给定一对元组,组合相似度被计算为相应属性的余弦相似度,从而得到一个m维相似度向量。
5.2 Comparison with Existing Methods
还有一种端到端的EM方法:Magellan。DeepER和Magellan可以相互融合。
在核苷酸数据库中确定重复序列的问题中应用DeepER方法。
5.3 Understanding DeepER Performance
得到一些结论。
-
有关训练集大小
DeepER具有足够的鲁棒性,可以在只有10 %的训练数据的情况下与其他方法竞争。
当然随着数据集的增大,模型性能也会提升。
-
不正确标签的影响
会存在标签标注错误问题。实验时采用使用10%的训练集的情况,并且改变其中标签。虽然F-测量随着错误标签比例的增加而减少,但实验也表明我们的方法是非常鲁棒的。在10 %噪声下,所有数据集的F-测量值相对于完美标注情况的平均降幅仅为2.6,标准差为2.6。30 %时平均降幅为8 %,标准差为7 %。我们还可以看到,在10 %的噪声下,我们的方法仍然与最先进的方法竞争。
-
动态vs静态词嵌入
评估了为ER任务调优DR是否提高了我们模型的性能。
对于"挑战性"数据集,在端到端学习框架中更新词嵌入对结果有一定的促进作用,而对于"容易"数据集,要么有较小的负面影响,要么完全没有影响。因此,我们建议在一般情况下,最好采用端到端的框架。
-
改变框架
三种框架来由单词词向量计算句子向量:简单的平均方法、LSTM、Sentence2Vec三种方法。简单的数据集使用平均方法效果好。有挑战性的数据集使用LSTM效果好。
-
改变词嵌入词典
学习了词嵌入词典对DR的影响。较小的字典上训练时,F1得分会有一个陡降。用于训练词向量的语料规模越大,越有利于识别语义关系。
-
改变词嵌入模型
在GloVe, Word2Vec, FastText,三个模型上进行测试。不同方法之间只有微小的差异。
-
多语言数据集
该方法可以在多语言数据集上无缝工作。
5.4 Evaluating LSH-based Blocking
评估了基于LSH的Blocking方法。通过调整 K (哈希码的大小)和 L (哈希表的数量)以实现可调的性能。
- 举一个例子:假设相似元组以概率P1 = 0.95落入同一个桶,不相似元组以概率P2≤0.5落入同一个桶。假设我们对Pub - DS的DBLP数据集进行索引。基于如下方程计算出需要一个K = 12,L = 2的LSH .
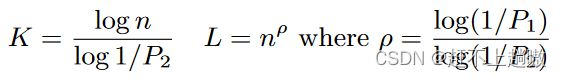
-
度量Blocking的指标
-
efficiency or reduction ratio (RR)
是通过我们的方法比较的元组对的数量与T中所有可能对的数量之比。换句话说,一个较小的值表明所做的比较的数量减少较多。就是使用方法实际比较的元组对数目和总共的元组对数量之比。
-
recall or pair completeness (PC)
是我们的方法所比较的真实重复数与T中重复数总数的比率。PC的值越高,意味着我们的方法将重复的元组对放在同一个块中。就是我们的方法比较的是重复对的和总体的重复对的比率,那这个比值越高就说明我们找的这个重复对找的准,在一个块中的可能性大。
-
-
有关K和L对RR和PC的影响
-
L不变时,K增大,PC减小
这是由于对于固定的L,增加K降低了两个相似元组被放置在同一个块中的可能性,从而减少了落入同一个块的重复数。
-
L不变时,K增大,会显著减小RR
这是由于较大的K值增加了可分配元组的LSH桶的数量。
-
K不变时,L增大,PC增大
因为当涉及多个哈希表时,两个相似元组被分配到同一个桶的概率增加。也就是说,即使一个真正的副本在一个哈希表中不落入同一个桶,它也可以在其他哈希表中落入同一个桶。
-
K不变时,L增大,对于RR指标会有负面影响
因为可能出现假阳性的元组。
-
-
有关K和L对DeepER方法的Precision和Recall的影响
Precision和Recall两个放在实体匹配中的理解就是:Precision是我们的方法匹配成功的中有多少是真值标注的匹配成功的。Recall是所有真值标注的匹配成功的里面有多少是我们预测匹配成功的。
-
Recall随着K的增加而减少
随着K的增加,召回率下降,因为越来越多的重复数据不在同一个块中,导致DeepER漏掉它们。
-
Precision随着K的增加略有增加
因为越来越多的非重复数据不再被比较。
-
-
有关multi-probe的结论
- 使用单个多探测序列也可以显著提高召回率。
- 增加N的大小并不能显著提高召回率。N表示前top-N
6 RELATED WORK
6.1 Entity Resolution
先前的方法大概基于三种:声明性规则;ML;众包
声明性规则:代表DNF,为元组匹配制定规则。
ML:代表SVM,主动学习,聚类
众包:相似度函数+阈值+专家参与
另外现有的EM系统大多需要专家参与。
6.2 Blocking
常见分为基于块和基于规则的。