时间序列-Auto-ARIMA模型
文章目录
-
-
-
- 1.数据格式
- 2.连续预测
- 3.滚动预测
- 4.下一次更新-ARIMA
-
-
我也是初学者,话不多说,直接上代码,欢迎交流!!!
1.数据格式
2.连续预测
#!usr/bin/env python
# !usr/bin/env python
# -*- coding:utf-8 _*-
"""
@author: liujie
@software: PyCharm
@file: auto_arima.py
@time: 2020/11/7 21:27
"""
# 一次性预测多个值
'''
# 文档部分参考:http://alkaline-ml.com/pmdarima/modules/generated/pmdarima.arima.auto_arima.html?highlight=auto_arima
ARIMA是一个非常强大的时间序列预测模型,但是数据准备与参数调整过程非常耗时
Auto ARIMA让整个任务变得非常简单,舍去了序列平稳化,确定d值,创建ACF值和PACF图,确定p值和q值的过程
Auto ARIMA的步骤:
1.加载数据并进行数据处理,修改成时间索引
2.预处理数据:输入的应该是单变量,因此需要删除其他列
3.拟合Auto ARIMA,在单变量序列上拟合模型
4.在验证集上进行预测
5.计算RMSE:用验证集上的预测值和实际值检查RMSE值
Auto-ARIMA通过进行差分测试,来确定差分d的顺序,然后在定义的start_p、max_p、start_q、max_q范围内拟合模型。
如果季节可选选项被启用,auto-ARIMA还会在进行Canova-Hansen测试以确定季节差分的最优顺序D后,寻找最优的P和Q超参数。
为了找到最好的模型,给定information_criterion auto-ARIMA优化,(‘aic’,‘aicc’,‘bic’,‘hqic’,‘oob’)
并返回ARIMA的最小值。
注意,由于平稳性问题,auto-ARIMA可能无法找到合适的收敛模型。如果是这种情况,将抛出一个ValueError,
建议在重新拟合之前使数据变稳定,或者选择一个新的顺序值范围。
非逐步的(也就是网格搜索)选择可能会很慢,特别是对于季节性数据。Hyndman和Khandakar(2008)中概述了逐步算法。
'''
import warnings
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from datetime import datetime
from math import sqrt
from sklearn.metrics import mean_squared_error
from pmdarima.arima import auto_arima
def main():
warnings.filterwarnings(action='ignore')
# 第一步:加载数据
# 定义将字符串时间转化成日期时间数组
date_parser = lambda dates: datetime.strptime(dates, '%Y/%m/%d')
data = pd.read_csv('../data/Data.csv', header=0, parse_dates=['month'], date_parser=date_parser, index_col='month')
data.fillna(method='pad', inplace=True)
# print(data.head(5))
# print(data.index)
# print(data.dtypes)
# 第二步:预处理数据-由于所给数据本身就是单变量序列,并且没有空值,因此,可以不进行这一步处理
# 将数据分成训练集与验证集
val_size = 100
train_size = 10 * val_size
train, val = data[-(train_size + val_size):-val_size + 1]['data'], data[-val_size:]['data']
# plot the data
fig = plt.figure()
fig.add_subplot()
plt.plot(train, 'r-', label='train_data')
plt.plot(val, 'y-', label='val_data')
plt.legend(loc='best')
plt.show(block=False)
# 第三步:buliding the model
# 仅需要fit命令来拟合模型,而不必要选择p、d、q的组合,模型会生成AIC值和BIC值,以确定参数的最佳组合
# AIC和 BIC是用于比较模型的评估器,这些值越低,模型就越好
'''
网址:http://alkaline-ml.com/pmdarima/modules/generated/pmdarima.arima.auto_arima.html?highlight=auto_arima
auto_arima部分参数解析(季节性参数未写):
1.start_p:p的起始值,自回归(“AR”)模型的阶数(或滞后时间的数量),必须是正整数
2.start_q:q的初始值,移动平均(MA)模型的阶数。必须是正整数。
3.max_p:p的最大值,必须是大于或等于start_p的正整数。
4.max_q:q的最大值,必须是一个大于start_q的正整数
5.seasonal:是否适合季节性ARIMA。默认是正确的。注意,如果season为真,而m == 1,则season将设置为False。
6.stationary :时间序列是否平稳,d是否为零。
6.information_criterion:信息准则用于选择最佳的ARIMA模型。(‘aic’,‘bic’,‘hqic’,‘oob’)之一
7.alpha:检验水平的检验显著性,默认0.05
8.test:如果stationary为假且d为None,用来检测平稳性的单位根检验的类型。默认为‘kpss’;可设置为adf
9.n_jobs :网格搜索中并行拟合的模型数(逐步=False)。默认值是1,但是-1可以用来表示“尽可能多”。
10.suppress_warnings:statsmodel中可能会抛出许多警告。如果suppress_warnings为真,那么来自ARIMA的所有警告都将被压制
11.error_action:如果由于某种原因无法匹配ARIMA,则可以控制错误处理行为。(warn,raise,ignore,trace)
12.max_d:d的最大值,即非季节差异的最大数量。必须是大于或等于d的正整数。
13.trace:是否打印适合的状态。如果值为False,则不会打印任何调试信息。值为真会打印一些
'''
model = auto_arima(train, start_p=0, start_q=0, max_p=6, max_q=6, max_d=2,
seasonal=True, test='adf',
error_action='ignore',
information_criterion='aic',
njob=-1, trace=True, suppress_warnings=True)
model.fit(train)
# 第四步:在验证集上进行预测
forecast = model.predict(n_periods=len(val))
print(forecast)
forecast = pd.DataFrame(forecast, index=val.index, columns=['prediction'])
# calculate rmse
rmse = np.sqrt(mean_squared_error(val, forecast))
print('RMSE : %.4f' % rmse)
# plot predictions
fig = plt.figure()
fig.add_subplot()
plt.plot(train, 'r-', label='train')
plt.plot(val, 'y-', label='val')
plt.plot(forecast, 'b-', label='prediction')
plt.legend(loc='best')
plt.title('RMSE : %.4f' % rmse)
plt.show(block=False)
if __name__ == '__main__':
main()

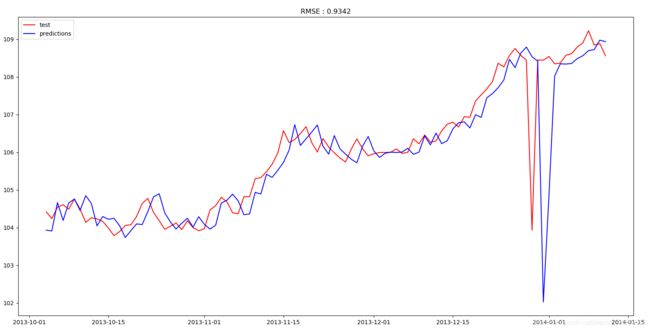
3.滚动预测
#!usr/bin/env python
# !usr/bin/env python
# -*- coding:utf-8 _*-
"""
@author: liujie
@software: PyCharm
@file: auto_arima.py
@time: 2020/11/8 14:29
"""
# 滚动预测-滚动窗口大小为120,预测个数为100
'''
# 文档部分参考:http://alkaline-ml.com/pmdarima/modules/generated/pmdarima.arima.auto_arima.html?highlight=auto_arima
ARIMA是一个非常强大的时间序列预测模型,但是数据准备与参数调整过程非常耗时
Auto ARIMA让整个任务变得非常简单,舍去了序列平稳化,确定d值,创建ACF值和PACF图,确定p值和q值的过程
Auto ARIMA的步骤:
1.加载数据并进行数据处理,修改成时间索引
2.预处理数据:输入的应该是单变量,因此需要删除其他列
3.拟合Auto ARIMA,在单变量序列上拟合模型
4.在验证集上进行预测
5.计算RMSE:用验证集上的预测值和实际值检查RMSE值
Auto-ARIMA通过进行差分测试,来确定差分d的顺序,然后在定义的start_p、max_p、start_q、max_q范围内拟合模型。
如果季节可选选项被启用,auto-ARIMA还会在进行Canova-Hansen测试以确定季节差分的最优顺序D后,寻找最优的P和Q超参数。
为了找到最好的模型,给定information_criterion auto-ARIMA优化,(‘aic’,‘aicc’,‘bic’,‘hqic’,‘oob’)
并返回ARIMA的最小值。
注意,由于平稳性问题,auto-ARIMA可能无法找到合适的收敛模型。如果是这种情况,将抛出一个ValueError,
建议在重新拟合之前使数据变稳定,或者选择一个新的顺序值范围。
非逐步的(也就是网格搜索)选择可能会很慢,特别是对于季节性数据。Hyndman和Khandakar(2008)中概述了逐步算法。
'''
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
from sklearn.metrics import mean_squared_error
from pmdarima.arima import auto_arima
# 生成一个路径
def generpath(path):
if not os.path.exists(path):
os.makedirs(path)
# 生成文件
def generfile(path,filename,m):
if not os.path.exists(path+filename):
order = [x for x in range(1,m+1)]
dataframe = pd.DataFrame({"order":order})
dataframe.to_csv(path+filename,sep=',') # 将对象写入文件中
# 生成数据
def datasave(savepath,saveindex,y_test_pre):
sdata =pd.read_csv(savepath)
sdata= pd.DataFrame(sdata)
y_test_pre = np.array(y_test_pre)
sdata[saveindex] = y_test_pre
sdata.to_csv(savepath,index = False)
def main():
# 加载数据
# 定义将字符串时间转化成日期时间数组
date_parser = lambda dates: datetime.strptime(dates, '%Y/%m/%d')
data = pd.read_csv('../data/Data.csv', header=0, parse_dates=['month'], date_parser=date_parser, index_col='month')
data.fillna(method='pad', inplace=True)
# print(data.head(5))
# print(data.index)
# print(data.dtypes)
# 预处理数据-由于所给数据本身就是单变量序列,并且没有空值,因此,可以不进行这一步处理
# 设置滚动预测的参数
columns = 'data'
ts = data[columns]
test_size = 100 # 需要预测的个数
rolling_size = 120 # 滚动窗口大小
ps = 1 # 每次预测的个数
horizon = 1 # 用来消除切片的影响
pre = [] # 存放预测值
test = ts[-test_size:]
# 滚动预测
for i in range(test_size):
print(i)
train = ts[-(rolling_size + test_size - i):-(test_size + horizon - i)]
'''
网址:http://alkaline-ml.com/pmdarima/modules/generated/pmdarima.arima.auto_arima.html?highlight=auto_arima
auto_arima部分参数解析:
1.start_p:p的起始值,自回归(“AR”)模型的阶数(或滞后时间的数量),必须是正整数
2.start_q:q的初始值,移动平均(MA)模型的阶数。必须是正整数。
3.max_p:p的最大值,必须是大于或等于start_p的正整数。
4.max_q:q的最大值,必须是一个大于start_q的正整数
5.seasonal:是否适合季节性ARIMA。默认是正确的。注意,如果season为真,而m == 1,则season将设置为False。
6.stationary :时间序列是否平稳,d是否为零。
6.information_criterion:信息准则用于选择最佳的ARIMA模型。(‘aic’,‘bic’,‘hqic’,‘oob’)之一
7.alpha:检验水平的检验显著性,默认0.05
8.test:如果stationary为假且d为None,用来检测平稳性的单位根检验的类型。默认为‘kpss’;可设置为adf
9.n_jobs :网格搜索中并行拟合的模型数(逐步=False)。默认值是1,但是-1可以用来表示“尽可能多”。
10.suppress_warnings:statsmodel中可能会抛出许多警告。如果suppress_warnings为真,那么来自ARIMA的所有警告都将被压制
11.error_action:如果由于某种原因无法匹配ARIMA,则可以控制错误处理行为。(warn,raise,ignore,trace)
12.max_d:d的最大值,即非季节差异的最大数量。必须是大于或等于d的正整数。
13.trace:是否打印适合的状态。如果值为False,则不会打印任何调试信息。值为真会打印一些
'''
model = auto_arima(train, start_p=0, start_q=0, max_p=6, max_q=6, max_d=2,
seasonal=True, test='adf',
error_action='ignore',
information_criterion='aic',
njob=-1, suppress_warnings=True)
model.fit(train)
forecast = model.predict(n_periods=ps)
pre.append(forecast[-1])
predictions_ = pd.Series(pre,index=test.index)
# print(predictions)
# 计算RMSE
rmse = np.sqrt(mean_squared_error(predictions_, test))
# 画图
fig = plt.figure()
fig.add_subplot()
plt.plot(test, 'r-', label='test')
plt.plot(predictions_, 'b-', label='predictions')
plt.title('RMSE : %.4f' % rmse)
plt.legend(loc='best')
plt.show(block=False)
predictions = np.array(pre).reshape(-1,1)
test = np.array(test[:len(predictions)].values).reshape(-1,1)
# 保存模型
savepath = "predata/AUTO-ARIMA/"
filename = "AUTO-ARIMA预测.csv"
saveindex = columns + "_" + "day" + str(horizon)
generpath(savepath)
generfile(savepath, filename, len(predictions))
datasave(savepath + filename, "y_true", test)
datasave(savepath + filename, saveindex, predictions)
if __name__ == '__main__':
main()
4.下一次更新-ARIMA
敬请期待!!!
如果对您有帮助,麻烦点赞关注,这真的对我很重要!!!如果需要互关,请评论留言!
