【机器学习】周志华西瓜书第八章集成学习习题8.5--编程实现Bagging模型,以决策树桩为基学习器,在西瓜数据集3.0a上训练一个Bagging集成,并与教材图8.6进行比较。
(1)问题理解与分析
编程实现Bagging模型,以决策树桩为基学习器,在西瓜数据集3.0a上训练一个Bagging集成,并与教材图8.6进行比较。
(2)Bagging算法原理阐述
若想得到泛化性能强的集成,集成中的个体学习器应尽可能相互独立;虽然 “独立” 在现实任务中无法做到,但可以设法使基学习器尽可能具有较大的差异。给定一个训练数据集,一种可能的做法是对训练样本进行采样,产生出若干个不同的子集,再从每个数据子集中训练出一个基学习器。这样,由于训练数据不同,我们获得的基学习器可望具有比较大的差异。然而,为获得好的集成,我们同时还希望个体学习器不能太差。如果采样出的每个子集都完全不同,则每个基学习器只用到了一小部分训练数据,甚至不足以进行有效学习,这显然无法确保产生出比较好的基学习器。为解决这个问题,我们可考虑使用相互有交叠的采样子集。
Bagging是并行式集成学习方法最著名的代表。从名字即可看出,它直接基于自助采样法(bootstrap sampling)。给定包含m个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样,经过m次随机采样操作,我们得到含m个样本的采样集,初始训练集中有的样本在采样集里多次出现,有的则从未出现。可以做一个简单的估计,初始训练集中约有36.8%的样本未出现在采样集中,约有63.2%的样本出现在采样集中。照这样,我们可采样出T个含m个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些基学习器进行结合。这就是Bagging的基本流程。在对预测输出进行结合时,Bagging通常对分类任务使用简单投票法,对回归任务使用简单平均法。若分类预测时出现两个类收到同样票数的情形,则最简单的做法是随机选择一个,也可进一步考察学习器投票的置信度来确定最终胜者。
3)Bagging算法设计思路
Bagging集成模型流程图如下:
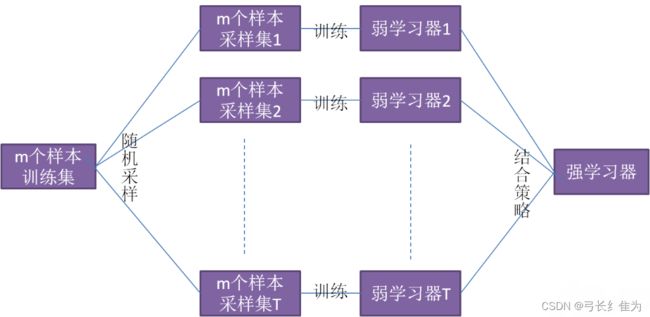
(4)Bagging实验流程分析
Bagging集成模型伪代码描述如下:

(5)实验数据的选择(训练集和测试集划分)、实验结果展示、优化与分析
本实验使用的数据集是西瓜数据集3.0,只使用连续型属性。题目要求采用的基学习器是决策树桩,本身偏差较大,并且Bagging集成只有降低方差的效果,对于偏差并无改善,所以集成后的训练误差仍然很低,于是将基学习器改为完整决策树。当基学习器数量为3时,我的结果与周志华《机器学习》(西瓜书)对比如下:
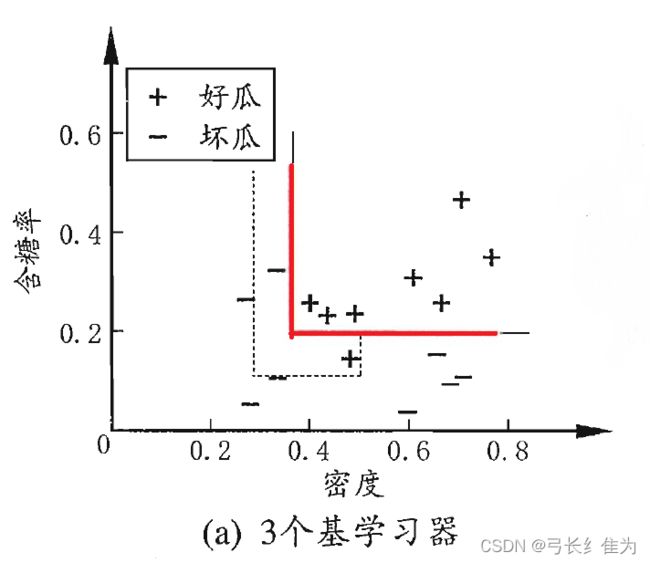
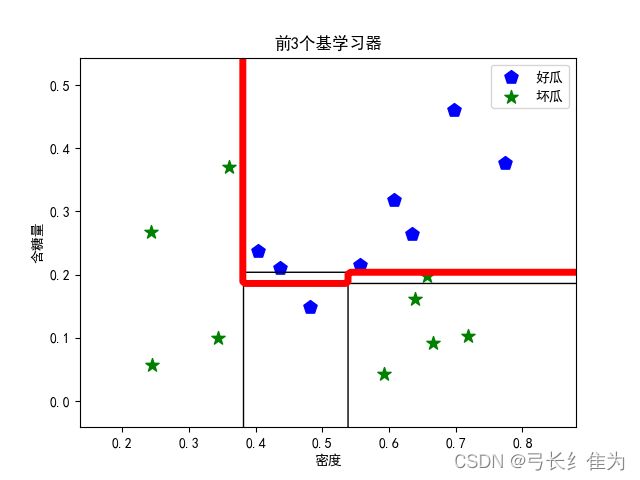
前者17个样本预测正确16个,正确率为94.1%;后者17个样本预测正确16个,正确率94.1%。
当基学习器数量为5时,我的结果与周志华《机器学习》(西瓜书)对比如下:
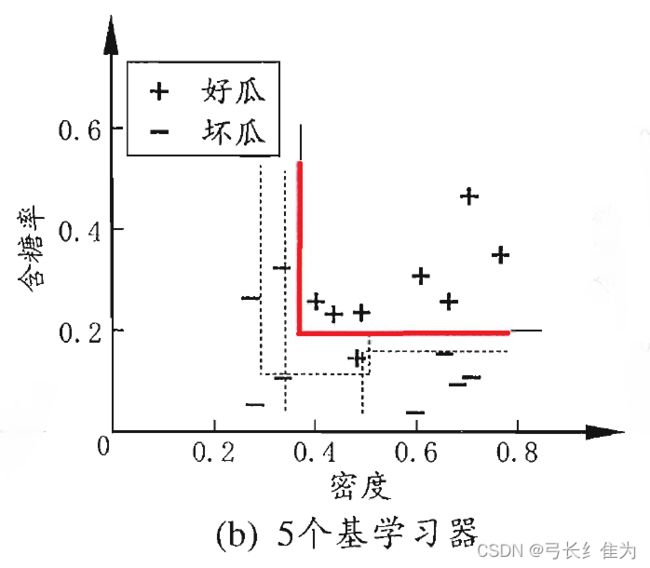
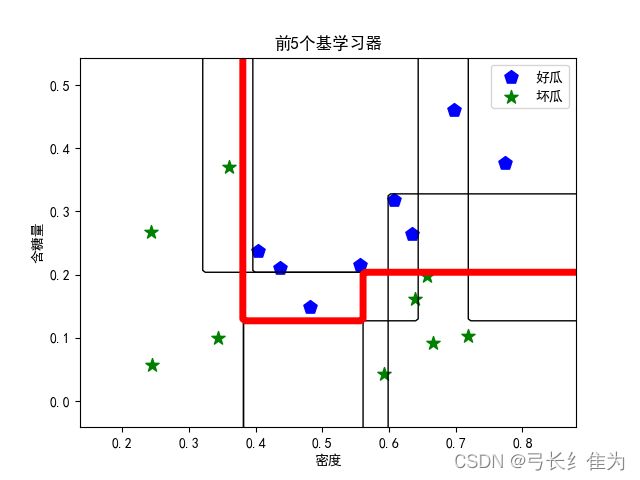
前者17个样本预测正确16个,正确率为94.1%;后者17个样本预测正确17个,正确率100%。
当基学习器数量为11时,我的结果与周志华《机器学习》(西瓜书)对比如下:
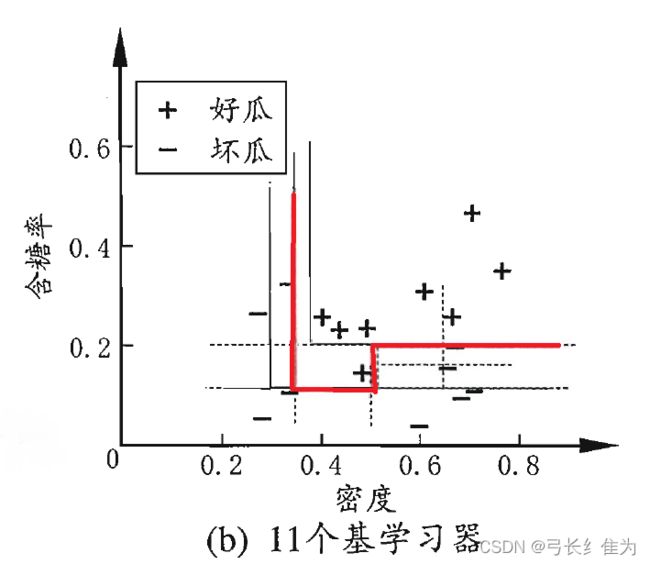
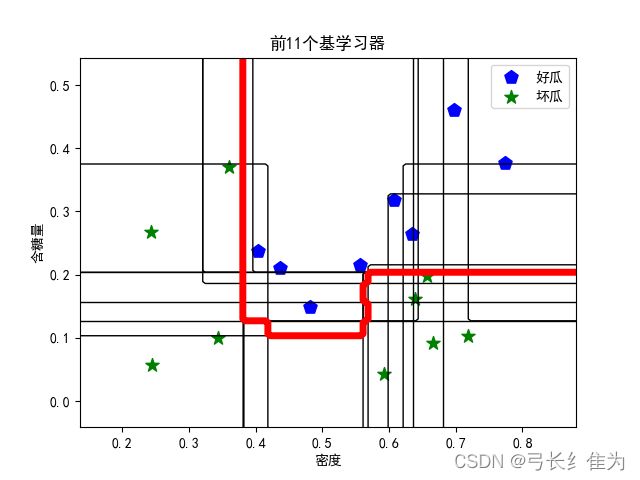
前者17个样本预测正确17个,正确率为100%;后者17个样本预测正确17个,正确率100%。
(6)代码结构注释、核心源代码简要分析
Bagging集成模型核心代码如下。列表H保存各个基学习器,H_pre存储每次迭代后H对于训练集的预测结果,error保存每次迭代后H的训练误差。
T = 20
H = []
m = len(Y)
H_pre = np.zeros(m)
error = []
for t in range(T):
boot_strap_sampling = np.random.randint(0, m, m)
Xbs = X[boot_strap_sampling]
Ybs = Y[boot_strap_sampling]
h = tree.DecisionTreeClassifier().fit(Xbs, Ybs)
H.append(h)
# 计算并存储当前步的训练误差
H_pre += h.predict(X)
Y_pre = (H_pre >= 0) * 2 - 1
error.append(sum(Y_pre != Y) / m)
def predict(H, X1, X2):
# 预测结果
# 仅X1和X2两个特征,X1和X2同维度
X = np.c_[X1.reshape(-1, 1), X2.reshape(-1, 1)]
Y_pre = np.zeros(len(X))
for h in H:
Y_pre += h.predict(X)
Y_pre = 2 * (Y_pre >= 0) - 1
Y_pre = Y_pre.reshape(X1.shape)
return Y_pre
(7)本次实验解决的主要问题、在理论学习与动手编程上的主要收获
在本次实验中,我编程实现了Bagging集成模型,并与AdaBoost集成模型进行了对比。在样本选择上,Bagging的训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的,而Boosting每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化,而权值是根据上一轮的分类结果进行调整。Bagging使用均匀取样,每个样例的权重相等,Boosting根据错误率不断调整样例的权值,错误率越大则权重越大。Bagging的所有预测函数的权重相等,Boosting的每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。Bagging的各个预测函数可以并行生成,Boosting的各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
完整代码:
# -*- coding: utf-8 -*-
"""
前面采用决策树桩来进行Bagging集成,效果较差,
现在改用全决策树full-tree来集成,观察效果。
全决策树算法不再自编,直接采用sklearn工具。
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn import tree
# 设置出图显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def predict(H, X1, X2):
# 预测结果
# 仅X1和X2两个特征,X1和X2同维度
X = np.c_[X1.reshape(-1, 1), X2.reshape(-1, 1)]
Y_pre = np.zeros(len(X))
for h in H:
Y_pre += h.predict(X)
Y_pre = 2 * (Y_pre >= 0) - 1
Y_pre = Y_pre.reshape(X1.shape)
return Y_pre
# >>>>>西瓜数据集3.0α
X = np.array([[0.697, 0.46], [0.774, 0.376], [0.634, 0.264], [0.608, 0.318], [0.556, 0.215],
[0.403, 0.237], [0.481, 0.149], [0.437, 0.211], [0.666, 0.091], [0.243, 0.267],
[0.245, 0.057], [0.343, 0.099], [0.639, 0.161], [0.657, 0.198], [0.36, 0.37],
[0.593, 0.042], [0.719, 0.103]])
Y = np.array([1, 1, 1, 1, 1, 1, 1, 1, -1, -1, -1, -1, -1, -1, -1, -1, -1])
# >>>>>Bagging
T = 20
H = [] # 存储各个决策树桩,每行表示#划分特征,划分点,左枝取值,右枝取值
m = len(Y)
H_pre = np.zeros(m) # 存储每次迭代后H对于训练集的预测结果
error = [] # 存储每次迭代后H的训练误差
for t in range(T):
boot_strap_sampling = np.random.randint(0, m, m)
Xbs = X[boot_strap_sampling]
Ybs = Y[boot_strap_sampling]
h = tree.DecisionTreeClassifier().fit(Xbs, Ybs)
H.append(h)
# 计算并存储当前步的训练误差
H_pre += h.predict(X)
Y_pre = (H_pre >= 0) * 2 - 1
error.append(sum(Y_pre != Y) / m)
# >>>>>绘制训练误差变化曲线
plt.title('训练误差的变化')
plt.plot(range(1, T + 1), error, 'o-', markersize=2)
plt.xlabel('基学习器个数')
plt.ylabel('错误率')
plt.show()
# >>>>>观察结果
x1min, x1max = X[:, 0].min(), X[:, 0].max()
x2min, x2max = X[:, 1].min(), X[:, 1].max()
x1 = np.linspace(x1min - (x1max - x1min) * 0.2, x1max + (x1max - x1min) * 0.2, 100)
x2 = np.linspace(x2min - (x2max - x2min) * 0.2, x2max + (x2max - x2min) * 0.2, 100)
X1, X2 = np.meshgrid(x1, x2)
for t in [3, 5, 11]:
plt.title('前%d个基学习器' % t)
plt.xlabel('密度')
plt.ylabel('含糖量')
# 画样本数据点
plt.scatter(X[Y == 1, 0], X[Y == 1, 1], marker='p', c='b', s=100, label='好瓜')
plt.scatter(X[Y == -1, 0], X[Y == -1, 1], marker='*', c='green', s=100, label='坏瓜')
plt.legend()
# 画基学习器划分边界
for i in range(t):
# 由于sklearn.tree类中将决策树的结构参数封装于内部,
# 不方便提取,这里采用一个笨办法:
# 用predict方法对区域内所有数据点(100×100)进行预测,
# 然后再用plt.contour的方法来找出划分边界
Ypre = predict([H[i]], X1, X2)
plt.contour(X1, X2, Ypre, colors='k', linewidths=1, levels=[0])
# 画集成学习器划分边界
Ypre = predict(H[:t], X1, X2)
plt.contour(X1, X2, Ypre, colors='r', linewidths=5, levels=[0])
plt.show()