数据挖掘,计算机网络、操作系统刷题笔记35
数据挖掘,计算机网络、操作系统刷题笔记35
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
考网警特招必然要考操作系统,计算机网络,由于备考时间不长,你可能需要速成,我就想办法自学速成了,课程太长没法玩
刷题系列文章
【1】Oracle数据库:刷题错题本,数据库的各种概念
【2】操作系统,计算机网络,数据库刷题笔记2
【3】数据库、计算机网络,操作系统刷题笔记3
【4】数据库、计算机网络,操作系统刷题笔记4
【5】数据库、计算机网络,操作系统刷题笔记5
【6】数据库、计算机网络,操作系统刷题笔记6
【7】数据库、计算机网络,操作系统刷题笔记7
【8】数据库、计算机网络,操作系统刷题笔记8
【9】操作系统,计算机网络,数据库刷题笔记9
【10】操作系统,计算机网络,数据库刷题笔记10
【11】操作系统,计算机网络,数据库刷题笔记11
【12】操作系统,计算机网络,数据库刷题笔记12
【13】操作系统,计算机网络,数据库刷题笔记13
【14】操作系统,计算机网络,数据库刷题笔记14
【15】计算机网络、操作系统刷题笔记15
【16】数据库,计算机网络、操作系统刷题笔记16
【17】数据库,计算机网络、操作系统刷题笔记17
【18】数据库,计算机网络、操作系统刷题笔记18
【19】数据库,计算机网络、操作系统刷题笔记19
【20】数据库,计算机网络、操作系统刷题笔记20
【21】数据库,计算机网络、操作系统刷题笔记21
【22】数据库,计算机网络、操作系统刷题笔记22
【23】数据库,计算机网络、操作系统刷题笔记23
【24】数据库,计算机网络、操作系统刷题笔记24
【25】数据库,计算机网络、操作系统刷题笔记25
【26】数据库,计算机网络、操作系统刷题笔记26
【27】数据库,计算机网络、操作系统刷题笔记27
【28】数据库,计算机网络、操作系统刷题笔记28
【29】数据库,计算机网络、操作系统刷题笔记29
【30】数据库,计算机网络、操作系统刷题笔记30
【31】数据库,计算机网络、操作系统刷题笔记31
【32】数据库,计算机网络、操作系统刷题笔记32
【33】数据库,计算机网络、操作系统刷题笔记33
【34】数据库,计算机网络、操作系统刷题笔记34
文章目录
- 数据挖掘,计算机网络、操作系统刷题笔记35
-
- @[TOC](文章目录)
- 数据挖掘
-
- 数据分类
- 单属性分析
- 单属性分析——异常值分析
- 对比分析
- 结构分析
- 分布分析
- 实战代码来玩一下上面的分布,展示HR.csv里面数据的分布啥的,给它分析分析
- CSMA/CD采用IEEE 802.3标准。
- 数字签名能够解决篡改,伪造等安全性问题
- TCP协议是有状态协议,而http/udp/ip是无状态协议
- 将一个C类网络划分20个子网,最适合的子网掩码是多少()
- 下列W命令中可以用于检测本机配置的DNS服务器是否工作正常的命令是( )
- 在 TCP/IP 协议族的层次中,解决计算机之间通信问题是在 ()
- 隧道技术是 IPV4 向 IPV6 过渡的常用技术之一,它( )
- 一个标准的分类的IP地址128.202.99.65所属的网络是
- 下列属于五层分层(物理层、数据链路层、网络层、运输层和应用层)结构的是_ 。
- STP:Spanning Tree Protocol 生成树协议
- 顺序文件是指按记录进入文件的先后顺序存放、其逻辑顺序和物理顺序一致的文件。
- 当今设计高性能计算机的重要技术途径是()
- 在任一时刻t,都存在一个集合,它包含所有最近k次(该题窗口大小为6)内存访问所访问过的页面。这个集合w(k, t)就是工作集。
- 关于磁盘引导区描述正确的是?()
- 访问不同临界资源的两个进程不要求必须互斥的进入临界区
- 文件的物理结构一般有( )。
- 总结
文章目录
- 数据挖掘,计算机网络、操作系统刷题笔记35
-
- @[TOC](文章目录)
- 数据挖掘
-
- 数据分类
- 单属性分析
- 单属性分析——异常值分析
- 对比分析
- 结构分析
- 分布分析
- 实战代码来玩一下上面的分布,展示HR.csv里面数据的分布啥的,给它分析分析
- CSMA/CD采用IEEE 802.3标准。
- 数字签名能够解决篡改,伪造等安全性问题
- TCP协议是有状态协议,而http/udp/ip是无状态协议
- 将一个C类网络划分20个子网,最适合的子网掩码是多少()
- 下列W命令中可以用于检测本机配置的DNS服务器是否工作正常的命令是( )
- 在 TCP/IP 协议族的层次中,解决计算机之间通信问题是在 ()
- 隧道技术是 IPV4 向 IPV6 过渡的常用技术之一,它( )
- 一个标准的分类的IP地址128.202.99.65所属的网络是
- 下列属于五层分层(物理层、数据链路层、网络层、运输层和应用层)结构的是_ 。
- STP:Spanning Tree Protocol 生成树协议
- 顺序文件是指按记录进入文件的先后顺序存放、其逻辑顺序和物理顺序一致的文件。
- 当今设计高性能计算机的重要技术途径是()
- 在任一时刻t,都存在一个集合,它包含所有最近k次(该题窗口大小为6)内存访问所访问过的页面。这个集合w(k, t)就是工作集。
- 关于磁盘引导区描述正确的是?()
- 访问不同临界资源的两个进程不要求必须互斥的进入临界区
- 文件的物理结构一般有( )。
- 总结
数据挖掘
数据分类
类别
顺序–低中高,无法用值衡量
定距离–不能说温度20是10度的2倍
定比:可以节点数据的差值和比例

单属性分析

单属性分析——异常值分析
连续异常

将k取3之上的数都是连续异常值
比如,马云和你的工资平均,发现你贼他妈有钱
这就很离谱
离散异常值:

集合A是你的离散数据
非A就是异常
知识异常:
身高10米?离谱

对比分析
通过比较的方式来达到数据的好坏衡量
比什么??数
绝对数:直接原数比
相对数比较:结构相对【各种率】,比例【同比】,比较【不同竞争对手】,动态【速度】,强度【人均GDP】
对比的维度:
时间:同比【去年同期】,环比【本年上个周期】
充分考虑季节问题
空间:现实方位上的,国家,城市,地区,
逻辑空间:不同的部门
经验与计划的比较:历史上的失业率多大就会暴乱
计划排期与工作进度的比较

对已有方法的整理很重要
结构分析
总体与部分
静态:组成,第一123产业的比例,产业结构,与其他国家的对比啥的
动态:时间变化,不同5年计划期间,三大产业的比例对比

分布分析
直接拿概率分布
比如正态分布,瑞利分布,卡方分布
f(x)
正态分布的均值,方差啥的,很好用
1sigma之内占比85%
2sigma之内的95%
极大似然:相似程度的衡量
一串数和一个分布像不像?
所有概率的乘积,就是极大似然
单因子稍微好点
不复杂
实战代码来玩一下上面的分布,展示HR.csv里面数据的分布啥的,给它分析分析
这是咱们之前说的HR表,在这个文章我介绍过
咱们来看看有没有异常值
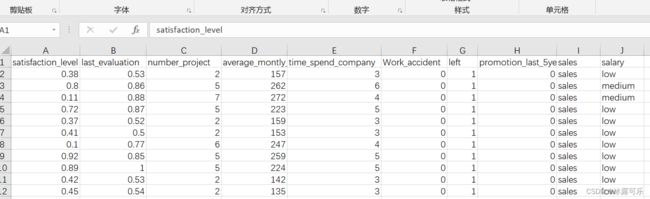
通过isnull函数查
df = pd.read_csv('HR_comma_sep.csv')
# 15001条,
sa_l = df['satisfaction_level']
# print(sa_l.isnull()) # 看看是否有null异常值
print(sa_l[sa_l.isnull()]) # 把这个 内部为true的打印出来
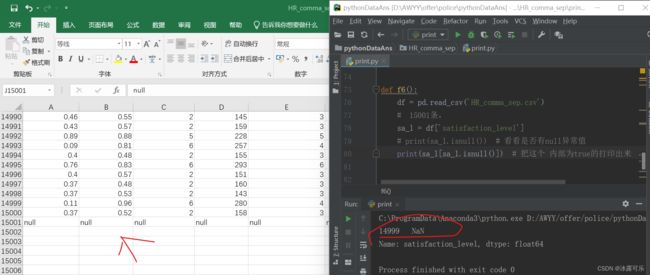
序列【true】:将这个结果为true的范围
我看看是不是将true换成别的数据,也能打印??
no
将刚刚null这个行展示出来的话
可以通过行列索引搞定
print(df[sa_l.isnull()])
satisfaction_level last_evaluation ... sales salary
14999 NaN NaN ... NaN NaN
[1 rows x 10 columns]
直接将其判空,满足条件就给它打印
好说
对于这null这种,我们直接丢弃
print(sa_l.dropna()) # 直接丢弃null,然后打印结果
14997 0.11
14998 0.37
Name: satisfaction_level, Length: 14999, dtype: float64
或者我们可以将null填充为别的数据
print(sa_l.fillna(0)) # 将null填充为0
14998 0.37
14999 0.00
Name: satisfaction_level, Length: 15000, dtype: float64
如果有异常值的话,看看能算均值吗
print(sa_l.mean()) # 貌似均值不算null????
print(sa_l.dropna().mean()) # 貌似均值不算null????
0.6128335222348166
0.6128335222348166
null好像自己就搞废了
去掉null,我们可以看看直方图
统计某个区间内的数量
sa_l = sa_l.dropna()
print(np.histogram(sa_l.values, bins=np.arange(0,1.1,0.1))) # bins分为01间隔,统计values它的直方图
(array([ 195, 1214, 532, 974, 1668, 2146, 1972, 2074, 2220, 2004],
dtype=int64), array([0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1. ]))
Process finished with exit code 0
可以看到x分区
每个区间内个数不同
去掉nullOK
咱看看第二个字段
last_evaluation
def f7():
df = pd.read_csv('HR_comma_sep.csv')
# 15001条,
le_s = df['last_evaluation']
# print(le_s[le_s.isnull()]) # 只看那些有null为true的值
14999 NaN
Name: last_evaluation, dtype: float64
去掉异常值的话
df = pd.read_csv('HR_comma_sep.csv')
# 15001条,
le_s = df['last_evaluation']
# print(le_s[le_s.isnull()]) # 只看那些有null为true的值
# print(le_s.mean()) # 其他的都好说
# print(le_s.max()) # 其他的都好说
# print(le_s.min()) # 其他的都好说
# print(le_s.skew()) # 其他的都好说
# print(le_s.kurt()) # 其他的都好说
# print(le_s[le_s>1]) # 这很离谱!!属于异常值,干掉
print(le_s[le_s <= 1]) # 反着取
14996 0.53
14997 0.96
14998 0.52
Name: last_evaluation, Length: 14999, dtype: float64
上四分位数和下四分位数
来决定上下界
之间的叫正常值
超过了就是异常
q_low = le_s.quantile(q=0.25)
q_high = le_s.quantile(q=0.75)
q_interval = q_high - q_low # 上下界差值
k = 1.5 # 1.5---3k上下界
lower = q_low - k * q_interval
upper = q_high + k * q_interval
print(lower)
print(upper)
le_s_normal = le_s[le_s<=upper][le_s>=lower]
print(le_s_normal) # le_s控制俩条件
hs_data = np.histogram(le_s_normal.values, bins=np.arange(lower, upper,0.1))
print(hs_data)
0.09500000000000014
1.335
0 0.53
1 0.86
2 0.88
3 0.87
4 0.52
...
14994 0.57
14995 0.48
14996 0.53
14997 0.96
14998 0.52
Name: last_evaluation, Length: 14999, dtype: float64
(array([ 0, 0, 179, 1389, 3174, 2242, 2275, 2752, 2705, 283, 0,
0], dtype=int64), array([0.095, 0.195, 0.295, 0.395, 0.495, 0.595, 0.695, 0.795, 0.895,
0.995, 1.095, 1.195, 1.295]))
上面咱们讲过的一个正常数据的范围怎么定?
k = 1.5 # 1.5---3k上下界
lower = q_low - k * q_interval
upper = q_high + k * q_interval
k你定就行
通过上下四分位数来定
然后这样就可以限定数据为正常数据,异常的干掉
分析这些异常,OK吧
再看下一个字段
def f8():
df = pd.read_csv('HR_comma_sep.csv')
np_s = df['number_project']
print(np_s.mean())
print(np_s.std())
print(np_s.max())
print(np_s.min())
print(np_s.skew())
print(np_s.kurt())
3.80305353690246
1.2325923553183857
7.0
2.0
0.3377056123598222
-0.4954779519008947
我们也可以数一下不同的值出现了多少次
print(np_s.value_counts())
4.0 4365
3.0 4055
5.0 2761
2.0 2388
6.0 1174
7.0 256
Name: number_project, dtype: int64
假如但看它占比呢?
print(np_s.value_counts(normalize=True))
4.0 0.291019
3.0 0.270351
5.0 0.184079
2.0 0.159211
6.0 0.078272
7.0 0.017068
Name: number_project, dtype: float64
4个项目的人做得最多
美滋滋
反正政协函数要学,这是数据分析与应用岗必须知识
这个函数默认是按照统计结果排序的
如果我们就是要按照这个值本身升序排序呢
print(np_s.value_counts(normalize=True).sort_index())
2.0 0.159211
3.0 0.270351
4.0 0.291019
5.0 0.184079
6.0 0.078272
7.0 0.017068
Name: number_project, dtype: float64
这也不难
这就是静态结构分析法
下一个字段
没月平均时长
df = pd.read_csv('HR_comma_sep.csv')
av_s = df['average_montly_hours']
# print(av_s.mean())
# print(av_s.std())
# print(av_s.max())
# print(av_s.min())
# print(av_s.skew())
# print(av_s.kurt())
lower = av_s.quantile(q=0.25)
upper = av_s.quantile(q=0.75)
interval = upper - lower
lower = lower - 1.5 * interval # 正常边界
upper = upper + 1.5 * interval
am_normal = av_s[av_s>=lower][av_s<=upper] # 排除异常值
print(am_normal)
print(len(am_normal)) # 正常的数量
再看间隔
his = np.histogram(am_normal.values, bins=10) # 分成几份
print(his)
his2 = np.histogram(am_normal.values, bins=np.arange(am_normal.min(), am_normal.max(), 10))
print(his2)
(array([ 367, 1240, 2733, 1722, 1628, 1712, 1906, 2240, 1127, 324],
dtype=int64), array([ 96. , 117.4, 138.8, 160.2, 181.6, 203. , 224.4, 245.8, 267.2,
288.6, 310. ]))
(array([ 168, 171, 147, 807, 1153, 1234, 1072, 824, 818, 758, 751,
738, 856, 824, 987, 1002, 1045, 935, 299, 193, 149],
dtype=int64), array([ 96., 106., 116., 126., 136., 146., 156., 166., 176., 186., 196.,
206., 216., 226., 236., 246., 256., 266., 276., 286., 296., 306.]))
Process finished with exit code 0
print(am_normal.value_counts(bins=np.arange(am_normal.min(), am_normal.max(), 10))) # 类似于统计各个区间的量
左闭右开啥的
(146.0, 156.0] 1277
(136.0, 146.0] 1159
(256.0, 266.0] 1063
(236.0, 246.0] 1006
(156.0, 166.0] 992
(246.0, 256.0] 987
(126.0, 136.0] 886
(216.0, 226.0] 873
(266.0, 276.0] 860
(166.0, 176.0] 832
(226.0, 236.0] 814
(176.0, 186.0] 813
(186.0, 196.0] 761
(196.0, 206.0] 755
(206.0, 216.0] 731
(276.0, 286.0] 319
(95.999, 106.0] 187
(286.0, 296.0] 164
(116.0, 126.0] 162
(106.0, 116.0] 162
(296.0, 306.0] 128
Name: average_montly_hours, dtype: int64
value_counts跟np.histogram类似的
下一个字段:公司待了多久
df = pd.read_csv('HR_comma_sep.csv')
avt_s = df['time_spend_company'] # 在公司待的时间
# 快速分析
print(avt_s.value_counts().sort_index())
2.0 3244
3.0 6443
4.0 2557
5.0 1473
6.0 718
7.0 188
8.0 162
10.0 214
Name: time_spend_company, dtype: int64
大多数待了3你年,跳槽
高工资,跳槽高薪
看看有事故吗?
def f11():
df = pd.read_csv('HR_comma_sep.csv')
avt_s = df['Work_accident'] # 在公司待的时间
# 快速分析
print(avt_s.value_counts().sort_index())
if __name__ == '__main__':
f11()
0.0 12830
1.0 2169
Name: Work_accident, dtype: int64
就俩取值
print(avt_s.value_counts(normalize=True))
Name: Work_accident, dtype: int64
0.0 0.85539
1.0 0.14461
Name: Work_accident, dtype: float64
平均事故率为14%
看下一个字段
def f12():
df = pd.read_csv('HR_comma_sep.csv')
avt_s = df['left'] # 在公司待的时间
# 快速分析
print(avt_s.value_counts().sort_index())
if __name__ == '__main__':
f12()
0.0 11428
1.0 3571
Name: left, dtype: int64
left
最近五年晋升
def f13():
df = pd.read_csv('HR_comma_sep.csv')
avt_s = df['promotion_last_5years'] #
# 快速分析
print(avt_s.value_counts().sort_index())
if __name__ == '__main__':
f13()
0.0 14680
1.0 319
Name: promotion_last_5years, dtype: int64
并不会有多少人得到了晋升
看看销售字段
def f14():
df = pd.read_csv('HR_comma_sep.csv')
avt_s = df['sales'] #
# 快速分析
print(avt_s.value_counts().sort_index())
if __name__ == '__main__':
f14()
IT 1227
RandD 787
accounting 767
hr 739
management 630
marketing 858
product_mng 902
sales 4140
support 2229
technical 2720
Name: sales, dtype: int64
咱们可以加一个异常值
avt_s = avt_s.where(avt_s !='gg') # 将gg赋值为NaN
print(avt_s)
14999 NaN
Name: sales, Length: 15000, dtype: object
这样就将其解决了
还可以直接干掉null
avt_s = avt_s.where(avt_s !='gg').dropna() # 将gg赋值为NaN
print(avt_s)
美滋滋
回顾一波,value_counts
统计各个value的个数
最后一个字段薪水
def f15():
df = pd.read_csv('HR_comma_sep.csv')
avt_s = df['salary'] #
# 快速分析
print(avt_s.value_counts().sort_index())
if __name__ == '__main__':
f15()
high 1237
low 7316
medium 6446
Name: salary, dtype: int64
中等收入人数多
美滋滋
好,整体我们来做一波异常值的消除
异常值出现的话,我们删除行呢?还是列,当然一般是行
def f16():
df = pd.read_csv('HR_comma_sep.csv')
avt_s = df.dropna(axis=0, how='any') # 整体去null,删除行?
# how:any只要出现null,整行干掉,all整体都是空,才干掉这行
# axis:0行,1列
print(avt_s)
if __name__ == '__main__':
f16()
14998 0.37 0.52 ... support low
[14999 rows x 10 columns]
你看看这个就不再了
再通过控制不同字段满足啥条件,就可以去掉异常值
avt_s = avt_s[avt_s['last_evaluation']<=1] # 通过规则去掉异常
avt_s = avt_s[avt_s['sales'] != 'gg']
print(avt_s)
14997 0.11 0.96 ... support low
14998 0.37 0.52 ... support low
[14999 rows x 10 columns]
咱们以部门为单位,进行分组
group by
和数据库一样
def f17():
df = pd.read_csv('HR_comma_sep.csv')
avt_s = df.dropna(axis=0, how='any') # 整体去null,删除行?
# how:any只要出现null,整行干掉,all整体都是空,才干掉这行
# axis:0行,1列
# print(avt_s)
avt_s = avt_s[avt_s['last_evaluation']<=1] # 通过规则去掉异常
avt_s = avt_s[avt_s['department'] != 'gg']
# 然后分组,聚合,和数据库一样哦
nt = avt_s.groupby("department").mean()
print(nt)
if __name__ == '__main__':
f17()
satisfaction_level ... promotion_last_5years
department ...
IT 0.618142 ... 0.002445
RandD 0.619822 ... 0.034307
accounting 0.582151 ... 0.018253
hr 0.598809 ... 0.020298
management 0.621349 ... 0.109524
marketing 0.618601 ... 0.050117
product_mng 0.619634 ... 0.000000
sales 0.614447 ... 0.024155
support 0.618300 ... 0.008973
technical 0.607897 ... 0.010294
[10 rows x 8 columns]
这样就根据部门分组,然后统计额一波均值,
离散的字段直接干掉
怎么说,和Oracle数据是不是很相似呢?????
简直一模一样,卧槽
爽的
假如你想单独看某一个列
那就是要切片,全选行,但是只要列
# 单独看一列
# 然后分组,聚合,和数据库一样哦
nt = avt_s.loc[:, ['last_evaluation','department']]
nt = nt.groupby("department").mean()
print(nt)
last_evaluation
department
IT 0.716830
RandD 0.712122
accounting 0.717718
hr 0.708850
management 0.724000
marketing 0.715886
product_mng 0.714756
sales 0.709717
support 0.723109
technical 0.721099
Process finished with exit code 0
这不就单独列出这个le这列
然后我们再按照分组
相当于我们再Oracle数据库中先把where条件控制好,from表中拿俩列
再去分组,聚合
easy
在读取表格时,你也可以直接控制条件,只取特定的数据
另外,聚合函数不仅仅可以用mean
还可以通过apply来自定义,对这个字段里面的值进行操作
比如max-min
# 单独看一列
# 然后分组,和数据库一样哦
nt = avt_s.loc[:, ['average_montly_hours', 'department']]
nt = nt.groupby("department")
## 然后通过自定义函数来聚合
nt = nt['average_montly_hours'].apply(lambda x:x.max()-x.min())
print(nt)
department
IT 212.0
RandD 210.0
accounting 213.0
hr 212.0
management 210.0
marketing 214.0
product_mng 212.0
sales 214.0
support 214.0
technical 213.0
Name: average_montly_hours, dtype: float64
以上整个过程就是对比分析的方法
去掉异常
分组分析也就是对比分析了
很容易的
CSMA/CD采用IEEE 802.3标准。
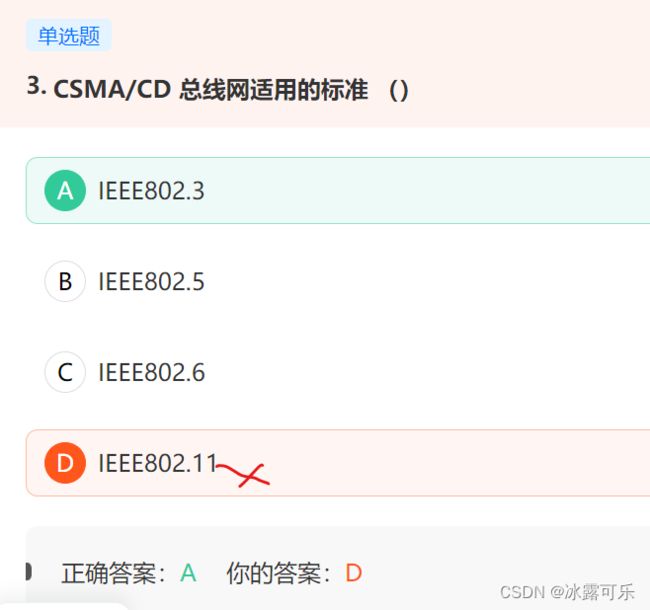
链接:https://www.nowcoder.com/questionTerminal/c921efa05dda4c339f07e28044344882
来源:牛客网
CSMA/CD是一种争用型的介质访问控制协议
CSMA/CD应用在 OSI 的第二层数据链路层
它的工作原理是: 发送数据前 先侦听信道是否空闲 ,若空闲,则立即发送数据。若信道忙碌,则等待一段时间至信道中的信息传输结束后再发送数据;若在上一段信息发送结束后,同时有两个或两个以上的节点都提出发送请求,则判定为冲突。若侦听到冲突,则立即停止发送数据,等待一段随机时间,再重新尝试。
其原理简单总结为:先听后发,边发边听,冲突停发,随机延迟后重发
CSMA/CD采用IEEE 802.3标准。
它的主要目的是:提供寻址和媒体存取的控制方式,使得不同设备或网络上的节点可以在多点的网络上通信而不相互冲突。
数字签名能够解决篡改,伪造等安全性问题
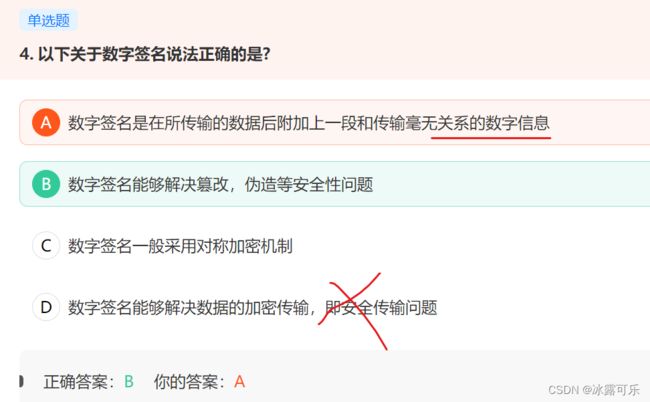
链接:https://www.nowcoder.com/questionTerminal/54ec74b28ce24f60b54109b382fd9751
来源:牛客网
本题考查数字摘要算法的基本概念。
数字签名技术是将摘要用发送者的私钥加密,与原文一起传送给接收者。
接收者只有用发送者的公钥才能解密被加密的摘要,然后用Hash函数对收到的原文产生一个摘要,与解密的摘要对比,
如果相同,则说明收到的信息是完整的,在传输过程中没有被修改,
否则,就是被修改过,不是原信息。
同时,也证明发送者发送了信息,防止了发送者的抵赖。 B正确。
实现数字签名的主要技术是非对称密钥加密技术。C错。
但是,数字签名并不能保证信息在传输过程中不被截获。D错。
既然是加密,怎么着也和这个原文有关系,不可能一点关系没有
A错误
TCP协议是有状态协议,而http/udp/ip是无状态协议
第二次错误了
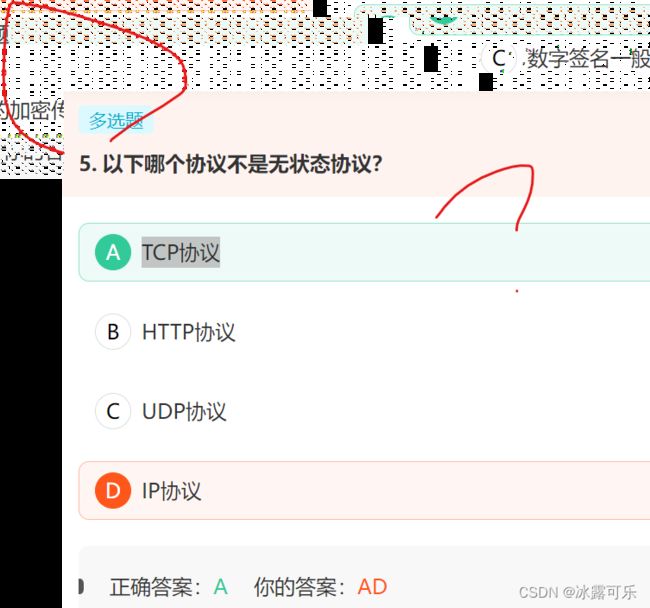
这他妈不是多选?????
将一个C类网络划分20个子网,最适合的子网掩码是多少()
这是子网,不是主机
所以5个1在前面,而不是后面
操蛋

这样是错误的
应该下面这样

下列W命令中可以用于检测本机配置的DNS服务器是否工作正常的命令是( )
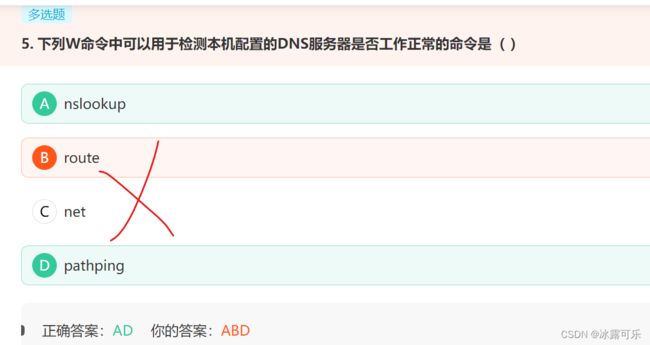
链接:https://www.nowcoder.com/questionTerminal/a40ab1893aa04d58a6837583b4ea524f
来源:牛客网
pathping 是指提供有关在源和目标之间的中间跃点处网络滞后和网络丢失的信息。
pathping 8.8.8.8
nslookup可以指定查询的类型,可以查到DNS记录的生存时间还可以指定使用哪个 DNS服务器 进行解释。
nslookup www.baidu.com
在 TCP/IP 协议族的层次中,解决计算机之间通信问题是在 ()
别看错了不是tcp/udp
而是协议簇
这样的话,那就要认识到
端到端=进程之间:运输层=传输层
用户应用进程之间:应用层
主机之间:网际层
链接:https://www.nowcoder.com/questionTerminal/0edade7fcbf54329b9015b6be2ac159d
来源:牛客网
在TCP/IP协议族的四个层次中:
应用层:直接为用户的应用进程提供服务,这里的进程指正在运行的程序。
运输层:负责向两个主机中进程之间的通讯提供服务。一个主机可同时运行多个进程。所以运输层是端对端的。
网际层:负责为分组交换网上的不同主机提供通信服务。网络层的一个主要任务就是要选择合适的路由,使源主机运输层所传下来的分组(packet,或者包),能够在网络中找到目的主机。所以网络层是主机对主机的。
隧道技术是 IPV4 向 IPV6 过渡的常用技术之一,它( )

反正使得ipv4和ipv6互通,这样不至于浪费
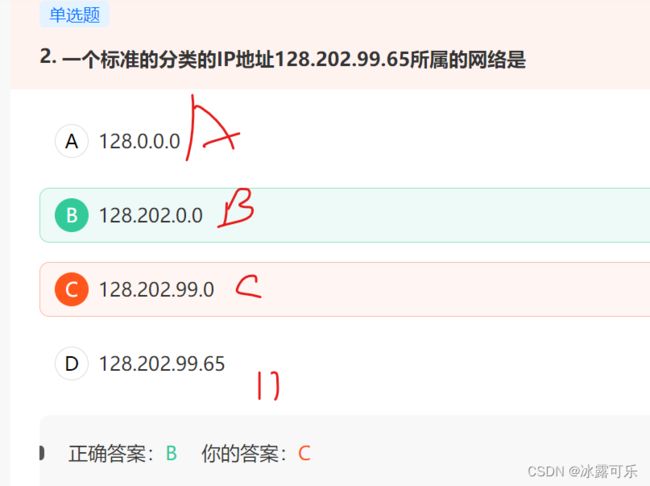
一个标准的分类的IP地址128.202.99.65所属的网络是
128是B类地址
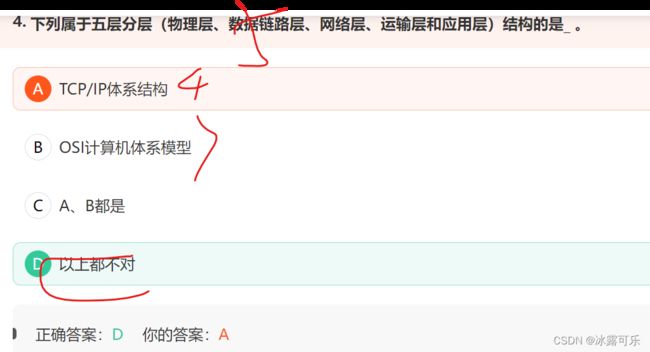
下列属于五层分层(物理层、数据链路层、网络层、运输层和应用层)结构的是_ 。
STP:Spanning Tree Protocol 生成树协议

STP(生成树协议)的原理是按照树的结构来构造网络拓扑,消除网络中的环路,避免由于环路的存在而造成广播风暴问题。
顺序文件是指按记录进入文件的先后顺序存放、其逻辑顺序和物理顺序一致的文件。

正确答案:D 顺序文件是指按记录进入文件的先后顺序存放、其逻辑顺序和物理顺序一致的文件。 一切存储在顺序存取存储器(如磁带)上的文件,都只能是顺序文件。 对A:显然,插入新纪录时不能插入到已经有顺序的文件的中间,只能在末尾。 对B:如果查找第i个记录,必须从头找起。 对C:如果要更新,必须复制整个文件,更新,然后在放到另外一块顺序存储器上。 显然,D是错误的,顺序记录的顺序和逻辑记录的顺序是一致的,也因此导致了前三个选项是正确的。
当今设计高性能计算机的重要技术途径是()
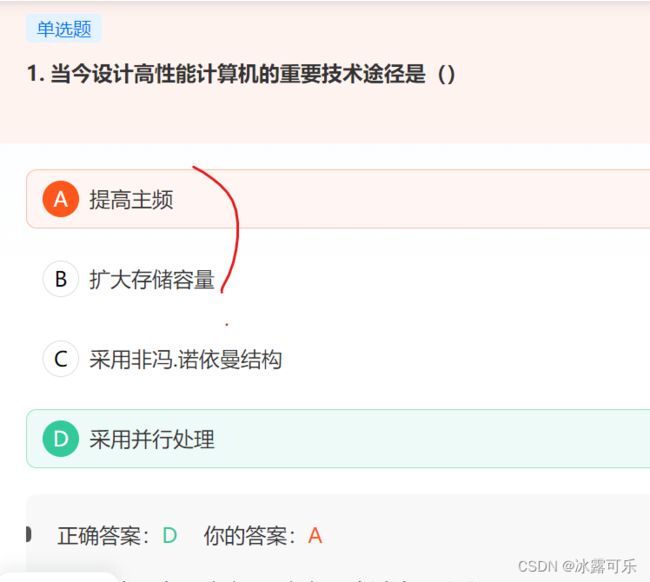
链接:https://www.nowcoder.com/questionTerminal/df1e59be966c4b4e99d192d05109a758
来源:牛客网
早期的计算机是串行逐位处理的,称为串行计算机。
随着计算机技术的发展,现代计算机均有不同程度的并行性,
并行处理计算机主要指:能同时执行多条指令或同时处理多个数据项的单处理器计算机,以及多处理系统,其性能大大地提高
骚啊
在任一时刻t,都存在一个集合,它包含所有最近k次(该题窗口大小为6)内存访问所访问过的页面。这个集合w(k, t)就是工作集。

关于磁盘引导区描述正确的是?()

链接:https://www.nowcoder.com/questionTerminal/a308095077c04d5eabed1e0037034aa9
来源:牛客网
磁盘引导区记录着磁盘的一些最基本的信息,磁盘的第一个扇区被保留为主引导扇区,它位于整个硬盘的0磁道0柱面1扇区,包括硬盘主引导记录MBR(Main Boot Record)和分区表DPT(Disk Partition Table)以及磁盘的有效标志。其中主引导记录的作用就是检查分区表是否正确以及确定哪个分区为引导分区,并在程序结束时把该分区的启动程序(也就是操作系统引导扇区)调入内存加以执行。
FORMAT需要指定要格式化的盘符。
访问不同临界资源的两个进程不要求必须互斥的进入临界区
既然是不同
那可以随意
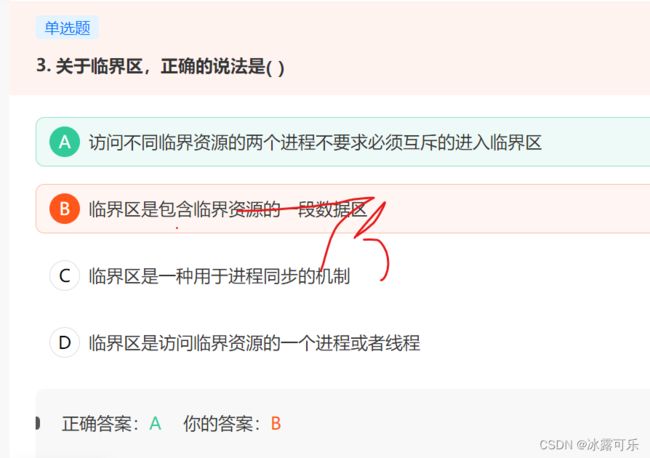
临界区是指一个访问共用资源的程序片段,而这些共用资源又无法同时被多个线程访问的特性。
进程进入临界区的调度原则是:
1、如果有若干进程要求进入空闲的临界区,一次仅允许一个进程进入。
2、任何时候,处于临界区内的进程不可多于一个。如已有进程进入自己的临界区,则其它所有试图进入临界区的进程必须等待。
3、进入临界区的进程要在有限时间内退出,以便其它进程能及时进入自己的临界区。
4、如果进程不能进入自己的临界区,则应让出CPU,避免进程出现“忙等”现象。
不是数据区………………
文件的物理结构一般有( )。

链接:https://www.nowcoder.com/questionTerminal/22893193defc48db836e206a14820a50
来源:牛客网
文件的逻辑结构
文件的逻辑结构时从用户观点出发所看到的文件组织形式,是用户可以直接处理的数据及其结构。
记录式的有结构文件
字符流式的无结构文件
文件的物理结构
文件的物理结构是指一个文件在外存上的存储组织形式,它与存储介质的存储特性有关。
①顺序结构/连续结构
将一个逻辑文件的信息存放在外存的连续物理块中。
优点:a顺序访问容易;b顺序访问速度快
缺点:a要求有连续的存储空间;b事先必须知道文件的长度
②链接结构/串联结构
将一个逻辑上连续的文件信息存放在外存的不连续物理块中。
隐式链接:在文件目录的每个目录项中,都须含有指向链接文件第一个盘块喝最后一个盘块的指针。
缺点:a只适用于顺序访问,对随机访问极其低效。b可靠性较差
显式链接:把用于链接文件各物理块的指针,显式地存放在内存地一张链表中
缺点:a不能支持高效的直接存取。b 文件分配表FAT(File Allocation Table)需要占用较大的内存空间
③索引结构
将一个逻辑文件的信息存放与外存的若干个物理块中,并为每个文件建立一个索引表,索引表中的每个表目用于存放文件信息所在的逻辑块号和与之对应的物理块号。
优点:a既适用于顺序存取,还易于进行文件的增删。
缺点:a增加了存储空间的开销。
总结
提示:重要经验:
1)
2)学好oracle,操作系统,计算机网络,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。