干货!基于模型的多目标强化学习及其在传染病控制的应用
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
新型冠状病毒(COVID-19)等严重传染病对公众健康构成巨大威胁。停课、居家令等严厉管控措施,在效果显着的同时,也带来经济损失。面对新出现的传染病,政策制定者面临的一个关键问题是,在巨大的不确定性下,如何权衡利弊并及时实施适当的干预措施。在这项工作中,我们提出了一个基于多目标模型的强化学习框架,以促进数据驱动的决策并最大限度地降低整体长期成本。具体来说,在每个决策点,首先学习一个贝叶斯流行病学模型作为环境模型,然后应用所提出的基于模型的多目标规划算法来寻找一组帕累托最优策略。该框架与每项政策的预测区间相结合,为政策制定者提供了实时决策支持工具。该方法的有效性被基于真实数据的仿真得到了证明。
本期AI TIME PhD直播间,我们邀请到北卡州立大学统计学博士——万润哲,为我们带来报告《基于模型的多目标强化学习及其在传染病控制的应用》

万润哲:
北卡州立大学统计学博士,导师为宋瑞教授。研究方向主要是强化学习,在线学习,以及最优决策等。在包括 NeurIPS,ICML,KDD 等会议与期刊一作发表多篇论文。获 ASA Norman Breslow Young Investigator 等奖项。
01
背 景
自2019年底,我们与新型冠状病毒的斗争已经两年左右了。除了紧急研发疫苗之外,我们首先采取了自我防护,居家,停课,降低人群流动性的策略,控制疫情发展。由于病毒变异的不确定性,应对的疫苗也并没有完善到可以完全免疫,因此那些非药物的决策对于控制疫情发挥了很有效的作用。但是停工,停课等举措带来的社会损失也是不容忽视的,如疫情期间经济下滑非常显著等。
在传染病控制中的决策面临着许多各种各样的挑战,主要在以下三个方面:
1)巨大的干预成本;
2)不确定性对疾病的传染性,各种干预措施的有效性,以及当前的传播状况;
3)考虑长期影响。
对于新冠疫情这种大规模传染病,现有的工作还没能提出解决这种不确定场景下的多目标实时最优顺序决策问题的方法。因此,本文工作引入了一个实时数据驱动的决策支持框架,该框架:
1)在多目标马尔可夫决策过程(MOMDP)框架下正式化了上述问题;
2)集成了流行病学模型、统计方法和强化学习算法;
3)最大化人民预期的长期总体利益。
02
方 法
(1)GSIR模型
SIR模型是传染病模型中的经典模型,其中S表示易感者,I表示感染者,R表示移除者。标准确定的SIR模型中的传播率高度依赖采取的防控政策,并且在现实生活中SIR模型也不是确定的,而是一个基于合理分布假设的随机模型。
本文提出了Generalized SIR(GSIR)作为过渡模型,如下图所示。

(2)MOMDP模型
下面是多目标马尔可夫决策过程(MOMDP)的描述,传染病防控决策问题可自然建模为多目标马尔可夫决策过程。对于每个区域l,在每个决策点t,根据估计的过渡模型、当前状态及其判断,决策者确定一个政策,目的是最大限度地降低总体长期成本,并根据政策选择实施的行动。

(3)Online Planning框架
Online Planning问题是指在每个决策点,使用历史数据为当前状态选择最佳操作。而在每个决策点,采用Learning-and-then-planning的方式,learning阶段进行模型估计,planning阶段进行决策,具体过程分为以下四步:
1)使用来自所有区域的累积数据和具有域知识的先验,估计θ的后验为ρt0;
2)通过policymakers选择一个trade-off的权重;
3)通过下面的式子学习一个确定的policy ;
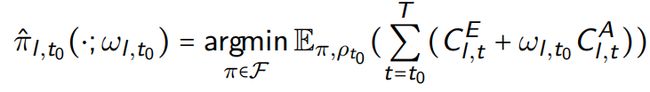
4)实现action 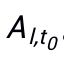
下图总结了Online Planning框架的过程。
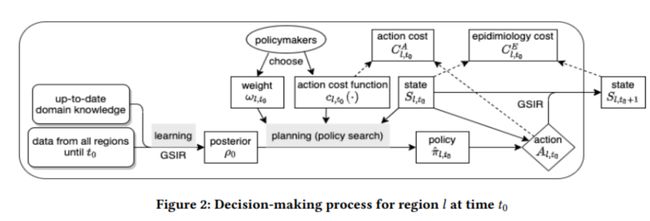
模型估计:
在每个时间点t0,我们需要估计GSIR并且量化传染病的不确定性。本文使用贝叶斯方法利用有价值的域知识作为先验,更好地捕捉不确定性(后验)。后验推导通过选择独立共轭先验,应用马尔可夫性质,并利用具有恒等链接函数的广义线性模型的结果来显式形式。
策略搜索:
1)给定权重

其中,F是可解释性(受限参数化策略类)和全局最优性(高度非参数化的策略类)之间的权衡。
2)可解释策略类
下面列举一个可解释策略类的例子——基于阈值的方法。
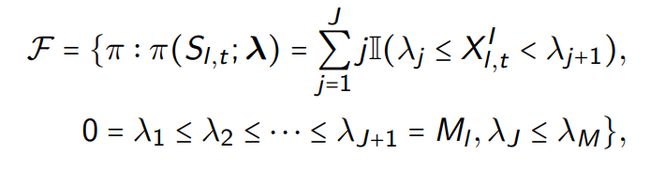
当疫情越严重的时候,我们做出的管控应该越严格,相应的阈值限制也会增大。
最终我们提出基于Rollout的直接决策搜索:蒙特卡罗(近似目标函数)+随机优化(找到解决方案)
3)黑盒策略类
如果可解释性可以换取全局最优性,则可以考虑更复杂的策略类(例如,蒙特卡罗树搜索的所有可能轨迹)。由于action集合是离散的,因此现有工作中多种规划算法是适用的,例如蒙特卡洛树搜索与状态聚合。


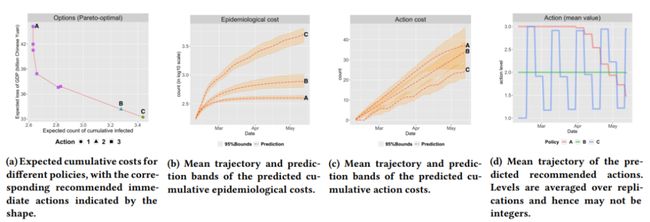
下图是展示给用户的一些信息的演示。计算结果为2020年2月10日中国北京的数据。对于三个样本策略,我们在子批次(b)-(d)中绘制它们的预测行为。预测结果在1000次复制中聚合。根据子批次(d),政策A和B可解释为研究的抑制和缓解政策,政策C与定期锁定政策接近。
03
实 验
数据集方面:
本文将提出的框架应用于一些中国新型冠状病毒疫情防控数据,中国已经通过了第一个峰值,这为验证提供了高质量的数据。为了进一步研究我们的框架对其他疾病的适用性及其鲁棒性,我们还对2009年H1N1流感大流行的参数进行了实验,并进行了一些敏感性分析。
具体地,本文收集中国几十个城市的感染人数、政府管控强度(哪天执行哪种强度的管控)、经济损失、传播强度等先验知识等作为数据内容。
GSIR的验证:
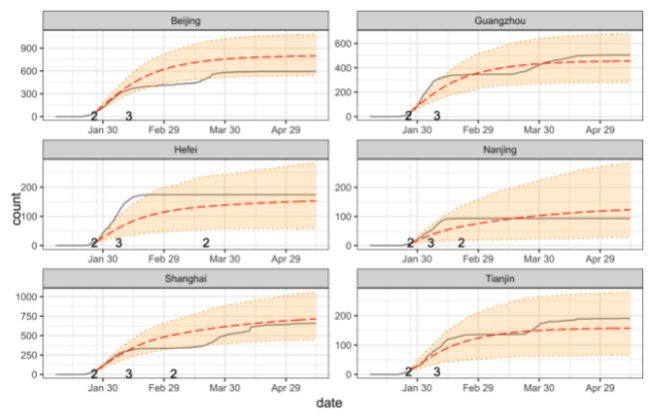
我们学习策略的性能和权重的选择都依赖于估计的GSIR模型的预测精度,首先通过时间验证检查这一点。
下图是中国六个重要城市的验证结果。实线是累积感染病例的观察计数。红色虚线表示平均预测数,阴影区域表示99%的预测带。当采取不同的action时,我们会在变更点上标记新的action级别。
GSIR估计:
下表是使用截至到0的所有六个城市的数据获得的后验平均值和标准偏差(括号中)。


Pareto-optimal策略评估:
评估流程是从真实数据中拟合环境,按照政策建议的行动,模拟从大流行第一天开始的轨迹,收集已存在的损失代价。
下图是实验结果,不同policy下的累积流行病学成本和经济成本平均超过100次。越靠近左下角越好。标准误差可以忽略不计。在每条曲线上,不同的标记表示具有不同超参数的策略的性能。
04
总 结
基于正在进行的2019冠状病毒疾病和决策者所面临的挑战,本文在概念上,提出了一种新的基于多目标模型的强化学习框架来辅助实时数据驱动的决策;在方法上,设计有效和具体的方法,以尽量减少长期总成本。组成部分包括统计学、强化学习和流行病学;实验表明,该方法在数值研究中具有良好的性能。
提
醒
点击阅读原文
即可观看分享回放哦!
整理:AI Timer
审核:万润哲
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至[email protected]!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

我知道你在看哟

点击“阅读原文”查看精彩回放