CRF 条件随机场
目录
1. 基本概念
1.1 各种随机场
1.2 CRF模型的训练原理
1.3 条件随机场的参数化形式
1.4条件随机场对应的简化概率表达
2. 例子
定义CRF中的特征函数
从特征函数到概率
CRF与逻辑回归的比较
CRF与HMM的比较
HMM和CRF区别
3. Tensorflow实现
tf.contrib.crf
(1)tf.contrib.crf.crf_log_likelihood()
(2)tf.contrib.crf.viterbi_decode
(3)tf.contrib.crf.crf_decode
(4)代码实现
1. 基本概念
参考:
CRF 条件随机场 概述 - 简书
条件随机场CRF(二) 前向后向算法评估标记序列概率 - 刘建平Pinard - 博客园
CRF模型 - 简书
1.1 各种随机场
条件随机场(Conditional Random Fields, 以下简称CRF)是给定一组输入序列条件下另一组输出序列的条件概率分布模型,即CRF擅长解决相邻上下文相关的问题。
随机场:按照某种分布给一系列变量进行赋值,这些变量构成的整体就叫做随机场。(是由若干个位置组成的整体,当给每一个位置中按照某种分布随机赋予一个值之后,其全体就叫做随机场)。标注序列 ”OOBSOBMSOOO” 就是一个随机场
马尔科夫随机场:满足马尔可夫性的随机场,是随机场的特例,它假设随机场中某一个位置的赋值仅仅与和它相邻的位置的赋值有关,和与其不相邻的位置的赋值无关。
CRF:是马尔科夫随机场的特例,它假设马尔科夫随机场中只有X和Y两种变量,X一般是给定的,而Y一般是在给定X的条件下我们的输出。
线性链条件随机场:X和Y有相同的结构的CRF就构成了线性链条件随机场。
CRF的数学语言描述:设X与Y是随机变量,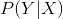 是给定X时Y的条件概率分布,若随机变量Y构成的是一个马尔可夫随机场,则称条件概率分布是条件随机场,(判别式模型)。
是给定X时Y的条件概率分布,若随机变量Y构成的是一个马尔可夫随机场,则称条件概率分布是条件随机场,(判别式模型)。
linear-CRF的数学定义:设
![]()
均为线性链表示的随机变量序列,在给定随机变量序列X的情况下,随机变量Y的条件概率分布构成条件随机场,即满足马尔可夫性:
![]()
则称为线性链条件随机场。
1.2 CRF模型的训练原理
根据公式![]() ,我们可以将其拆解为两个部分来看:
,我们可以将其拆解为两个部分来看:
- 一部分是
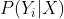 ):对应的特征函数被称为节点特征函数(发射函数);
):对应的特征函数被称为节点特征函数(发射函数); - 一部分是
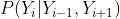 :对应的特征函数被称为局部特征函数(转移函数)。
:对应的特征函数被称为局部特征函数(转移函数)。
为了建一个条件随机场,首先要定义一个特征函数集,每个特征函数都以整个句子s,当前位置i,位置i和i-1的标签和为输入。然后为每一个特征函数赋予一个权重,然后针对每一个标注序列Y,对所有的特征函数加权求和,必要的话,可以把求和的值转化为一个概率值
特征函数的取值为0和1,表示满足特征条件还是不满足特征条件。同时我们给予每个特征函数一个权重 ,表示我们对这个特征函数的信任程度。而特征函数所对应的权重就可以看做是模型参数。
,表示我们对这个特征函数的信任程度。而特征函数所对应的权重就可以看做是模型参数。
NER中,X=LSTM对输入提取的更高级的特征;Y=标记序列;学习目标=CRF的模型参数(每个特征函数f的权重)。


1.3 条件随机场的参数化形式
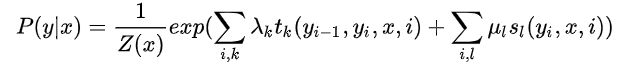
![]()
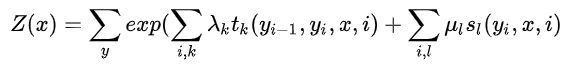
- 转移特征 / 转移函数:其中
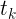 是定义在边上的局部特征函数,即,我们称之为转移特征,它同时依赖于当前位置和上一个位置。
是定义在边上的局部特征函数,即,我们称之为转移特征,它同时依赖于当前位置和上一个位置。 - 状态特征 / 发射函数:而
 是定义在节点上的节点特征函数,即,我们称之为状态特征,它仅仅依赖于当前位置。
是定义在节点上的节点特征函数,即,我们称之为状态特征,它仅仅依赖于当前位置。 - 以上两个变量都依赖于位置,属于局部特征,在满足条件时它们的取值为1,不满足条件时,它们的取值为0,
1.4条件随机场对应的简化概率表达

2. 例子
参考:轻松理解条件随机场(CRF)_慕课手记
上面所说的动词后面还是动词就是一个特征函数,我们可以定义一个特征函数集合,用这个特征函数集合来为一个标注序列打分,并据此选出最靠谱的标注序列。也就是说,每一个特征函数都可以用来为一个标注序列评分,把集合中所有特征函数对同一个标注序列的评分综合起来,就是这个标注序列最终的评分值。
- 标注序列:相当于y
- 特征函数:相当于x(x1,x2,x3,...)
简单说:为了建一个条件随机场,我们首先要定义一个特征函数集,每个特征函数都以整个句子s,当前位置 ,位置和
,位置和 的标签为输入。然后为每一个特征函数赋予一个权重,然后针对每一个标注序列l,对所有的特征函数加权求和,必要的话,可以把求和的值转化为一个概率值。
的标签为输入。然后为每一个特征函数赋予一个权重,然后针对每一个标注序列l,对所有的特征函数加权求和,必要的话,可以把求和的值转化为一个概率值。
定义CRF中的特征函数
现在,我们正式地定义一下什么是CRF中的特征函数,所谓特征函数,就是这样的函数,它接受四个参数:
-
句子s(就是我们要标注词性的句子)
- ,用来表示句子s中第i个单词
-
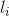 ,表示要评分的标注序列给第i个单词标注的词性
,表示要评分的标注序列给第i个单词标注的词性 -
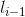 ,表示要评分的标注序列给第i-1个单词标注的词性
,表示要评分的标注序列给第i-1个单词标注的词性
它的输出值是0或者1,0表示要评分的标注序列不符合这个特征,1表示要评分的标注序列符合这个特征。
Note:这里,我们的特征函数仅仅依靠当前单词的标签和它前面的单词的标签对标注序列进行评判,这样建立的CRF也叫作线性链CRF,这是CRF中的一种简单情况。为简单起见,本文中我们仅考虑线性链CRF。
从特征函数到概率
定义好一组特征函数后,我们要给每个特征函数f_j赋予一个权重λ_j。现在,只要有一个句子s,有一个标注序列l,我们就可以利用前面定义的特征函数集来对l评分。

上式中有两个求和,外面的求和用来求每一个特征函数评分值的和,里面的求和用来求句子中每个位置的单词的的特征值的和。
特征函数集中:每个特征函数求取句子中每个位置的单词特征值,内层求和即求特征值的和,外层求和是求特征汉书集中每一个特征函数评分值的和。
对这个分数进行指数化和标准化,我们就可以得到标注序列l的概率值p(l|s),如下所示:

 为一个标注序列,
为一个标注序列,![]() 为所有标注序列
为所有标注序列
CRF与逻辑回归的比较
是不是有点逻辑回归的味道?
事实上,条件随机场是逻辑回归的序列化版本。
- 逻辑回归:是用于分类的对数线性模型;
- 条件随机场:是用于序列化标注的对数线性模型。
CRF与HMM的比较
对于词性标注问题,HMM模型也可以解决。HMM的思路是用生成办法,就是说,在已知要标注的句子s的情况下,去判断生成标注序列l的概率,如下所示:
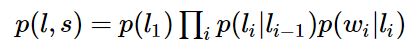
这里:
![]() :是转移概率,比如,
:是转移概率,比如,![]() 是介词,
是介词,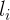 是名词,此时的p表示介词后面的词是名词的概率。
是名词,此时的p表示介词后面的词是名词的概率。
![]() :表示发射概率(emission probability),比如是名词,
:表示发射概率(emission probability),比如是名词, 是单词“ball”,此时的p表示在是名词的状态下,是单词“ball”的概率。
是单词“ball”,此时的p表示在是名词的状态下,是单词“ball”的概率。
那么,HMM和CRF怎么比较呢?
答案是:CRF比HMM要强大的多,它可以解决所有HMM能够解决的问题,并且还可以解决许多HMM解决不了的问题。事实上,我们可以对上面的HMM模型取对数,就变成下面这样:
![]()
我们把这个式子与CRF的式子进行比较:
不难发现,如果我们把第一个HMM式子中的log形式的概率看做是第二个CRF式子中的特征函数的权重的话,我们会发现,CRF和HMM具有相同的形式。换句话说,我们可以构造一个CRF,使它与HMM的对数形式相同。怎么构造呢?
对于HMM中的每一个转移概率p(l_i=y|l_i-1=x),我们可以定义这样的一个特征函数:
![]()
该特征函数仅当l_i = y,l_i-1=x时才等于1。这个特征函数的权重如下:
![]()
同样的,对于HMM中的每一个发射概率,我们也都可以定义相应的特征函数,并让该特征函数的权重等于HMM中的log形式的发射概率。
用这些形式的特征函数和相应的权重计算出来的p(l|s)和对数形式的HMM模型几乎是一样的!
用一句话来说明HMM和CRF的关系就是这样:每一个HMM模型都等价于某个CRF
但是,CRF要比HMM更加强大,原因主要有两点:
-
CRF可以定义数量更多,种类更丰富的特征函数。HMM模型具有天然具有局部性,就是说,在HMM模型中,当前的单词只依赖于当前的标签,当前的标签只依赖于前一个标签。这样的局部性限制了HMM只能定义相应类型的特征函数,我们在上面也看到了。但是CRF却可以着眼于整个句子s定义更具有全局性的特征函数,如这个特征函数:
![]()
如果i=1,l_i=动词,并且句子s是以“?”结尾时,f2=1,其他情况f2=0。
- CRF可以使用任意的权重: 将对数HMM模型看做CRF时,特征函数的权重由于是log形式的概率,所以都是小于等于0的,而且概率还要满足相应的限制,如
![]()
但在CRF中,每个特征函数的权重可以是任意值,没有这些限制。
HMM和CRF区别
HMM有2个假设:
- 一阶马尔可夫假设:即任意时刻的状态只依赖前一时刻的状态,与其他时刻无关;
- 观测独立性假设:任意时刻的观测只依赖于该时刻的状态,与其他状态无关。
1)HMM是生成式模型,CRF是判别式模型
https://www.cnblogs.com/hellochennan/p/6624509.html
两者都是用了马尔科夫链作为隐含变量的概率转移模型,只不过HMM使用隐含变量生成可观测状态,其生成概率有标注集统计得到,是一个生成模型;而CRF反过来通过可观测状态判别隐含变量,其概率亦通过标注集统计得来,是一个判别模型。
2)HMM是概率有向图,CRF是概率无向图
3)HMM求解过程可能是局部最优,CRF可以全局最优
4)CRF概率归一化较合理,HMM则会导致label bias 问题
5)CRF和HMM都假设隐变量是满足马尔科夫性的,即当前状态仅和上一个状态有概率转移关系而与其它位置的状态无关。
6)CRF优于HMM的地方在于,它可以引入更多的特征,包括词语本身特征和词语所在上下文的特征,而非单词本身。
https://www.zhihu.com/question/53458773
- 判别式模型:直接对建模;
- 生成式模型:训练阶段对
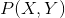 建模,inference再对新的sample计算。
建模,inference再对新的sample计算。
3. Tensorflow实现
tf.contrib.crf
(1)tf.contrib.crf.crf_log_likelihood():学习问题,训练
在一个条件随机场里面计算标签序列的log-likelihood
函数的目的:使用crf 来计算损失,里面用到的优化方法是:最大似然估计
参数:max_seq_len = 一个句子的字数
- inputs: 一个形状为 [batch_size, max_seq_len, num_tags] 的tensor,也就是每个标签的预测概率值,这个值根据实际情况选择计算方法,CNN,RNN...都可以,一般使用BILSTM处理之后输出转换为他要求的形状作为CRF层的输入。
- tag_indices: 一个形状为[batch_size, max_seq_len] 的矩阵,其实就是真实标签序列。
- sequence_lengths:一个形状为[batch_size] 的向量,表示batch中每个序列的长度。这是一个样本真实的序列长度,因为为了对齐长度会做些padding,但是可以把真实的长度放到这个参数里
- transition_params: 形状为[num_tags, num_tags] 的转移矩阵,可以没有,没有的话这个函数也会算出来。
返回:
- log_likelihood: 标量,log-likelihood
- transition_params: 形状为[num_tags, num_tags] 的转移矩阵,转移概率,如果输入没输,它就自己算个给返回。
(2)tf.contrib.crf.viterbi_decode:解码问题,预测
viterbi_decode(score,transition_params)
通俗一点,作用就是返回最好的标签序列,这个函数只能够在测试时使用,在tensorflow外部解码。
参数:
- score: 一个形状为[seq_len, num_tags] matrix of unary potentials.
- transition_params: 形状为[num_tags, num_tags] 的转移矩阵
返回:
- viterbi: 一个形状为[seq_len] 显示了最高分的标签索引的列表.
- viterbi_score: A float containing the score for the Viterbi sequence.
(3)tf.contrib.crf.crf_decode
crf_decode(potentials,transition_params,sequence_length)
在tensorflow内解码
参数:
- potentials: 一个形状为[batch_size, max_seq_len, num_tags] 的tensor,
- transition_params: 一个形状为[num_tags, num_tags] 的转移矩阵
- sequence_length: 一个形状为[batch_size] 的 ,表示batch中每个序列的长度
返回:
- decode_tags:一个形状为[batch_size, max_seq_len] 的tensor,类型是tf.int32,表示最好的序列标记。
- best_score: 一个形状为[batch_size] 的tensor,包含每个序列解码标签的分数。
(4)代码实现
# !/home/wcg/tools/local/anaconda3/bin/python
# coding=utf8
import numpy as np
import tensorflow as tf
# 1.data settings
num_examples = 10 # 句子数
num_words = 20 # 每个句子字数
num_features = 100 # 每个汉字特征数
num_tags = 5 # 标签数
# 2. x shape = [10,20,100] y shape = [10,20]
x = np.random.rand(num_examples,num_words,num_features).astype(np.float32)
# Random tag indices representing the gold sequence.
y = np.random.randint(num_tags,size = [num_examples,num_words]).astype(np.int32)
# 真实序列的长度
# sequence_lengths = [19,19,19,19,19,19,19,19,19,19]
sequence_lengths = np.full(num_examples,num_words - 1,dtype=np.int32)
# 3.Train and evaluate the model.
with tf.Graph().as_default():
with tf.Session() as session:
# Add the data to the TensorFlow gtaph.
x_t = tf.constant(x) #观测序列
y_t = tf.constant(y) # 标记序列
sequence_lengths_t = tf.constant(sequence_lengths)
# Compute unary scores from a linear layer.
# weights shape = [100,5]
weights = tf.get_variable("weights", [num_features, num_tags])
# matricized_x_t shape = [200,100]
matricized_x_t = tf.reshape(x_t, [-1, num_features])
# compute [200,100] [100,5] get [200,5]
# 计算结果
matricized_unary_scores = tf.matmul(matricized_x_t, weights)
# unary_scores shape = [10,20,5] [10,20,5]
unary_scores = tf.reshape(matricized_unary_scores, [num_examples, num_words, num_tags])
# compute the log-likelihood of the gold sequences and keep the transition
# params for inference at test time.
# shape shape [10,20,5] [10,20] [10]
log_likelihood,transition_params = tf.contrib.crf.crf_log_likelihood(unary_scores,y_t,sequence_lengths_t)
viterbi_sequence, viterbi_score = tf.contrib.crf.crf_decode(unary_scores, transition_params, sequence_lengths_t)
loss = tf.reduce_mean(-log_likelihood) # add a training op to tune the parameters.
# 定义梯度下降算法的优化器
#learning_rate 0.01
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
#train for a fixed number of iterations.
session.run(tf.global_variables_initializer())
'''
#eg:
In [61]: m_20
Out[61]: array([[ 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]])
In [62]: n_20
Out[62]: array([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
In [59]: n_20