【论文汇总】人群计数中Transformer的应用,持续更新
1.CCTrans: Simplifying and Improving Crowd Counting with Transformer
论文地址:https://arxiv.org/pdf/2109.14483v1.pdf
代码:https://github.com/wfs123456/CCTrans
全监督+弱监督
Transformer backbone:Twins
我的解读:CCTrans: Simplifying and Improving Crowd Counting with Transformer解读和代码踩坑记录_算法卷死我算了的博客-CSDN博客
2.TransCrowd: Weakly-Supervised Crowd Counting with Transformer
论文:https://arxiv.org/abs/2104.09116
代码:GitHub - dk-liang/TransCrowd: TransCrowd: Weakly-Supervised Crowd Counting with Transformer
弱监督 ,Transformer backbone:VIT
我的解读:TransCrowd: Weakly-Supervised Crowd Counting with Transformer解读_算法卷死我算了的博客-CSDN博客

3.Joint CNN and Transformer Network via weakly supervised Learning for efficient crowd counting
论文:https://arxiv.org/abs/2203.06388
弱监督,Transformer backbone:Swin transformer

4.An End-to-End Transformer Model for Crowd Localization
论文:https://arxiv.org/abs/2202.13065
人群定位的任务,decoder也用的transformer,无代码,Transformer backbone:应该是DETR

5.Congested Crowd Instance Localization with Dilated Convolutional Swin Transformer
人群定位的任务,encoder用的Swin transformer,decoder是金字塔卷积,无代码。
论文:https://arxiv.org/pdf/2108.00584.pdf

6.Boosting Crowd Counting with Transformers
论文:https://arxiv.org/abs/2105.10926
写的一言难尽,没有代码,感觉是把这篇文章Tokens-to-token ViT: Training vision transformers from scratch on imagenet用在了crowd counting上面。
Tokens-to-token ViT中提到的deep narrow VIT和VIT的区别主要在于更深以及维度更小

7.CrowdFormer: Weakly-supervised Crowd counting with Improved Generalizability
论文:https://arxiv.org/abs/2203.03768

弱监督。backbone是PVT-V2(PVT-V1的升级版),回归只用了一个线性层,盲猜和TransCrowd一个回归,应该是就用了linear来做回归。

8.Boosting Crowd Counting via Multifaceted Attention(CVPR2022)
论文:https://arxiv.org/abs/2203.02636v1
作者解读:【可学区域注意力】Boosting Crowd Counting via Multifaceted Attention - 知乎
代码: 已公布GitHub - LoraLinH/Boosting-Crowd-Counting-via-Multifaceted-Attention: Official Implement of CVPR 2022 paper 'Boosting Crowd Counting via Multifaceted Attention'

9. Counting Varying Density Crowds Through Density Guided Adaptive Selection CNN and Transformer Estimation
论文:https://arxiv.org/abs/2206.10075
arxiv尚为公布代码,backboneVGG-16,CNN+Transformer的双分支

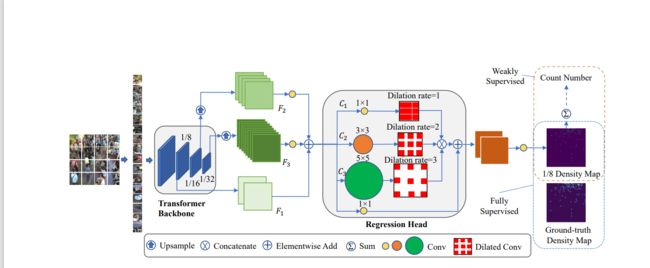
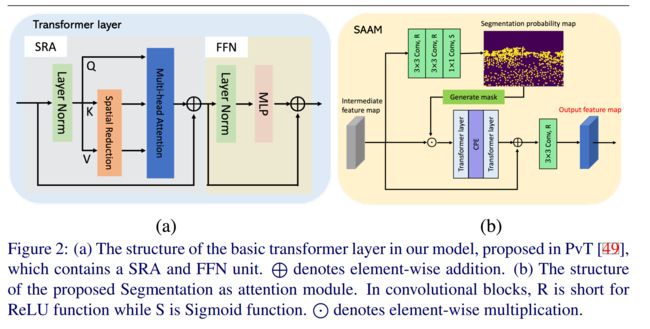
10.【CUT】Segmentation Assisted U-shaped Multi-scale Transformer for Crowd Counting
论文:发表于BMVChttps://www.researchgate.net/publication/364030579_Segmentation_Assisted_U-shaped_Multi-scale_Transformer_for_Crowd_Counting
Backbone是:Twins-PCPVT,思路和cctrans有点像,cctrans用的Twins里的Twins-SVT-L作为transformer backbone。loss没什么新意,拼了dm-count和Focal loss.不过对每个阶段的特征都进行监督。SAAM模块里面做了一个语义分割的额外任务,mask会放到简单transformer block里面学习。

11.MAFNet: A Multi-Attention Fusion Network for RGB-T Crowd Counting
论文:https://arxiv.org/abs/2208.06761
RGB-T(输入为RGB图像和热图)人群计数任务 。backbone为VGG19,在后面的模块中用了self-attention和跨模态的self-attention。
我的解读:【MAFNet】 A Multi-Attention Fusion Networkfor RGB-T Crowd Counting解读_行走的人参的博客-CSDN博客
12.Spatio-channel Attention Blocks for Cross-modal Crowd Counting(ACCV2022)
论文链接:
https://openaccess.thecvf.com/content/ACCV2022/papers/Zhang_Spatio-channel_Attention_Blocks_for_Cross-modal_Crowd_Counting_ACCV_2022_paper.pdf 代码:https://github.com/VCLLab/CSCA
跨模态的双分支网络,CSCA模块中采用了non-local的跨模态的注意力。和第11篇挺像。挺简单的,代码改编自RGBT-CC数据集那篇(CVPR2021)。
13. Attention-Guided Collaborative Counting
发表在:IEEE Transactions on Image Processing
论文链接:Attention-Guided Collaborative Counting | IEEE Journals & Magazine | IEEE Xplore
提出了一个注意力引导模块和协同计数模块,双transformer(空间transformer和通道transformer)
