FFT频谱分析(补零、频谱泄露、栅栏效应、加窗、细化、频谱混叠、插值),Matlab、C语言代码
文章目录
- 引言
- Matlab FFT函数
- 频谱混叠
- 栅栏效应
- 细化技术
-
- 什么是细化技术?
- 细化FFT技术的应用:
- Zoom-FFT算法介绍及MATLAB实现
- Zoom-FFT根本没有实现“细化“?
- 到底该怎么实现“细化”?
- 补零
-
- 补零对频谱的影响
- 补零与离散傅里叶变换的分辨率
- 补零与插值对FFT的影响
- 频谱泄露
-
- 信号的截断
- 频谱泄露定义
- 窗
-
- 窗的概念
-
- 常用窗函数
- 如何选择“窗函数”?
- 窗函数选择标准
- 频谱泄漏的原因
- 加窗应用(汉宁窗)
- 加窗对频率和幅值的影响
- FFT变换的幅值和能量校正
-
- 幅值修正谱
- 能量修正谱
- 转换的比例因子关系
- 插值
-
- Matlab仿真
- 三次样条插值
- C语言实现
引言
在对信号进行谐波分析的过程中,对时域信号进行FFT之后发现时域中本来相同幅值的信号分量,在频域中频率点正确,但是频域幅值却出现了不同,因此对此现象进行分析的探讨
此FFT的频率分辨率为0.36,后续通过增加采样点的方式将频率分辨率提升到0.18,但是仍然出现频域幅值不一致的现象。
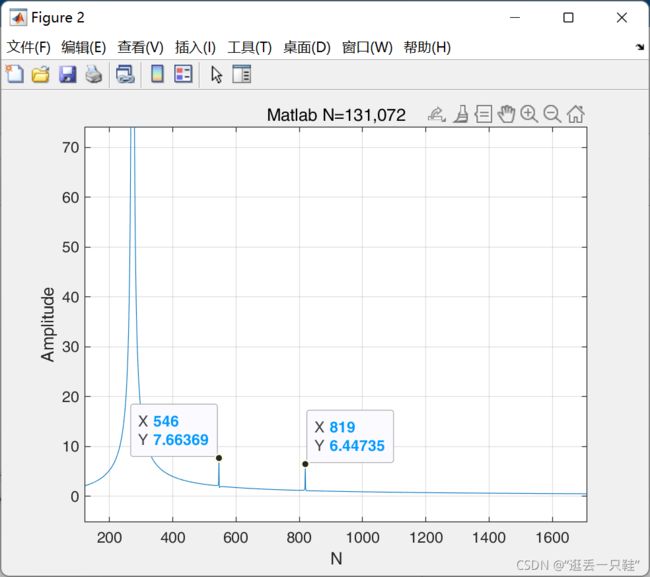
接着FFT过程中的疑问,本文收集了FFT过程中涉及到的 补零、频谱泄露、栅栏效应、加窗、细化、频谱混叠 等概念,尝试对上述出现的问题进行答案的寻找
最终以实现频域与时域更加精确的对照
Matlab FFT函数
首先说明一下,用MATLAB做FFT并不要求数据点个数必须为以2为基数的整数次方。之所以很多资料上说控制数据点数为以2为基数的整数次方,是因为这样就能采用以2为基的FFT算法,提升运算性能。
如果数据点数不是以2为基数的整数次方,处理方法有两种
一种是在原始数据开头或末尾补零,即将数据补到以2为基数的整数次方,这是“补零”的一个用处;
第二种是采用以任意数为基数的FFT算法。

而MATLAB的[公式]函数在参数[公式]正好就是数据[公式]的长度,但又不是以2为基数的整数次方时,并不会采用补零的方法,而应该是采用以任意数为基数的FFT算法(说“应该”是因为帮助文档里没有明确说明),这样也能得到很好的结果,只不过速度要稍稍慢了一些,以通常的计算量是体现不出来的。
频谱混叠
定义:一般原因时域信号采样离散化时,采样频率fc不满足奈奎斯特采样定理:fc>=2*fmax
奈奎斯特采样定理:模数转换时,采样频率fc符合这个定理,就能采出合适的信号,采的的离散信号无论是从时域还是频域都可以很好的恢复原信号。
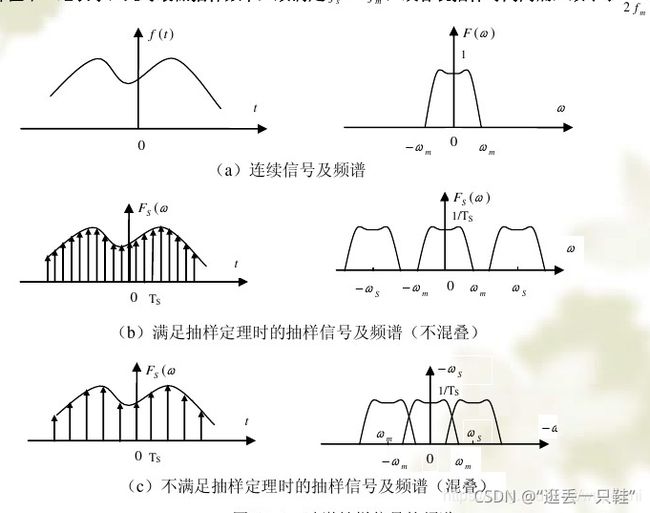
奈奎斯特定理已被众所周知了,所以几乎所有人的都知道为了不让频谱混叠,理论上采样频谱大于等于信号的最高频率。
了解了概念,那和时域上联系起来的关系是什么呢?
设定采样点数为 N,采样频率 fs,最高频率 fh,故频谱分辨率 f = fs / N,而 fs >= 2fh,所以可以看出最高频率与频谱分辨率是相互矛盾的,提高频谱分辨率f的同时,在 N 确定的情况下必定会导致最高频率 fh 的减小;同样的,提高最高频率 fh 的同时必会引起f的增大,即分辨率变大。
栅栏效应
在进行DFT的过程中,最后需要对信号的频谱进行采样。经过这种采样所显示出来的频谱仅在各采样点上,而不在此类点上的频谱都显示不出来,即使在其他点上有重要的峰值也会被忽略,这就是栅栏效应。

这一效应对于周期信号尤为重要,因其频谱是离散的,如处理不当这些离散谱线可能不被显示。
不管是时域采样还是频域采样,都有相应的栅栏效应。只是当时域采样满足采样定理时,栅栏效应不会有什么影响。而频域采样的栅栏效应则影响很大,“挡住”或丢失的频率成分有可能是重要的或具有特征的成分,使信号处理失去意义。
减小栅栏效应可用提高采样间隔也就是频率分辨力的方法来解决。间隔小,频率分辨力高,被“挡住”或丢失的频率成分就会越少。但会增加采样点数,使计算工作量增加。
解决此项矛盾可以采用如下方法:在满足采样定理的前提下,采用频率细化技术(ZOOM),亦可用把时域序列变换成频谱序列的方法。
在对周期信号DFT处理时,解决栅栏效应应以致解决泄露效应的一个极为有效的措施是所谓“整周期截取”。
而对于非周期信号,如果希望减小栅栏效应的影响,尽可能多地观察到谱线,则需要提高频谱的分辨率。
细化技术
在解决栅栏效应中,碰到了一个概念,叫做细化,对与本设计中出现的问题,因为频率分辨率最后已经达到了0.36,频率点也都比较准确,所以出现栅栏效应的可能性较小。
但是,对于栅栏效应和细化技术,还是很值的去探索一下
也对 Zoom-FFT算法 进行一个学习
什么是细化技术?
**细化技术是一种一定频率范围内提高频率分辨率的测量技术,也叫细化傅里叶分析。**即在所选择的频带内,进行与基带分析有同样多的谱线的分析。从而能大大提高频率分辨率。
选带分析时频率分辨率为:
选带傅氏分析(细化)的主要步骤是:
(a) 输入信号先经模拟抗混滤波,滤去所需分析的最高频率即基带分析中的最高分析频率以上的频率成分;
(b) 经过模数转换,变为数字信号序列;
© 将采样信号经数字移频,移频后的Fk处的谱线将落在频率轴上的零频处;
(d) 将移频后的数字信号再经数字低通滤波,滤去所需频带以外的信号;
(e) 对滤波后的信号的时间序列进行重采样,此时分析的是一段小频段为原来的1/M。这样在一小频段上采样,采样量还是N,但采样时间加了M倍,提高了分辩率。
细化FFT技术的应用:
一些不能增加总的采样点数而分辨率又要求精细的场合,细化FFT分析是很有用的。例如:
(a)区分频谱图中间距很近的共振尖峰,用常规分析不能很好分开时,用细化分析就能得到满意的结果。
(b)用于增加信噪比,提高谱值精度,这是由于细化时采用了数字滤波器,混叠与泄漏产生的误差都非常小;
(c ) 用于分离被白噪声淹没的单频信号,由于白噪声的功率谱与频率分辨率有关,每细化一个2倍,白噪声的功率谱值降低3dB,若细化256倍,白噪声功率谱值即下降24 dB,而单频信号的谱线就会被突出出来。
Zoom-FFT算法介绍及MATLAB实现
下面对该方法进行仿真,仿真参数如下
| 参数值 | 参数名称 |
|---|---|
| 采样频率 | 1000Hz |
| 细化倍数 | 50 |
| 滤波器阶数 | 200 |
| FFT点数 | 2048 |
| 频率 | 166.4Hz、165Hz |
下面对该方法进行仿真,仿真参数如下
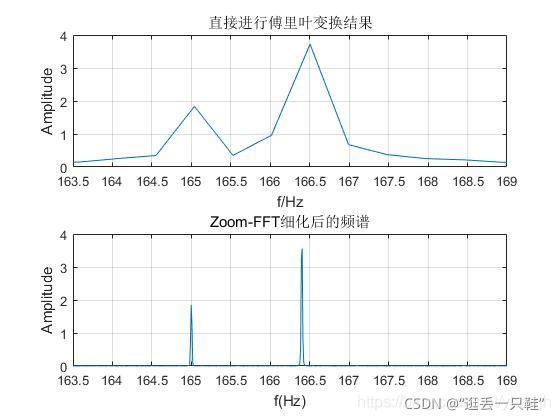
从图中可以看出,直接进行FFT,频率与原始频率有些许误差,并且不是很能分辨,但是细化后的频谱能够很好地区分信号的频率,很准确地得到了信号的频率。
clear;
close all;
clc;
fs=1000; %采样频率
N=2048; %傅里叶变换点数
D=50; %细化倍数
M=200; %滤波器阶数
t=(0:N*D+2*M)/fs; %时间轴
x=4*sin(2*pi*166.4*t)+2*sin(2*pi*165*t+pi/6)...
+0.6*randn(1,N*D+2*M+1); %信号
xf=fft(x,N); %傅里叶变换
xf=abs(xf(1:N/2))/N*2;
subplot(211);
plot((0:N/2-1)*fs/N,xf);
axis([163.5 169 0 4])
grid on
xlabel('f/Hz');ylabel('Amplitude')
title('直接进行傅里叶变换结果')
% 细化
fe=167; %中心频率
k=1:M;
w=0.5+0.5*cos(pi*k/M); %Hanning函数
fl=max(fe-fs/(4*D),-fs/2.2); %频率下限
fh=min(fe+fs/(4*D),fs/2.2); %频率上限
yf=D*fl;
df=fs/D/N; %分辨率
f=fl:df:fl+(N/2-1)*df;
xz=zeros(1,N/2);
wl=2*pi*fl/fs; %归一化角频率
wh=2*pi*fh/fs;
hr(1)=(wl-wh)/pi;
hr(2:M+1)=(sin(wl*k)-sin(wh*k))./(pi*k).*w;
hi(1)=0;
hi(2:M+1)=(cos(wl*k)-cos(wh*k))./(pi*k).*w;
p=0:N-1;
w=0.5-0.5*cos(2*pi*p/N);
xrz=zeros(1,N/2);
xiz=zeros(1,N/2);
L=10; %循环次数
for i=1:L
for k=1:N
kk=(k-1)*D+M;
xrz(k)=x(kk+1)*hr(1)+sum(hr(2:M+1).*(x(kk+2:kk+M+1)+x(kk:-1:kk-M+1)));
xiz(k)=x(kk+1)*hi(1)+sum(hi(2:M+1).*(x(kk+2:kk+M+1)-x(kk:-1:kk-M+1)));
end
xzt=(xrz+1j*xiz).*exp(-1j*2*pi*(0:N-1)*yf/fs);
xzt=xzt.*w;
xzt=xzt-sum(xzt)/N;
xzt=fft(xzt);
xz=xz+(abs(xzt(1:N/2))/N*2).^2;
end
xz=(xz./L).^0.5;
subplot(212);
plot(f,xz);
axis([163.5 169 0 4])
grid on
xlabel('f(Hz)');ylabel('Amplitude')
title('Zoom-FFT细化后的频谱')
Zoom-FFT根本没有实现“细化“?
首先说频率分辨率的概念,默认指的信号客观的物理可达到的分辨率,即物理分辨率;并非“计算分辨率”
假设信号的采样时间Delta_T定了,信号在频域上的理论最高分辨率也就已经确定了,等于Delta_f=1/Delta_T;
如下信号及其对应频谱
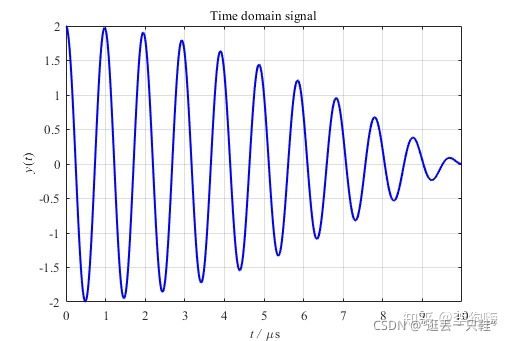

通过细化的原理我们可以知道,本质上为选择一个频带范围,针对这个频带进行补零的操作,时域中补零之后,我们可以看到,频谱点密集了不少


通过上述的一个对比,我们可以非常直观的得到结论,如果你把信号补一倍长度的0,可以计算出一个分辨率为0.5*Delta_f的频谱,但这对信号分析没有增加新的物理信息,其实仅仅是数学游戏;增加的是“计算分辨率”,没有增加任何“物理分辨率”。
再说什么是细化。
所谓细化,我认为定义应该是:(不增加信号时域长度的情况下),提高其频谱分析物理分辨率的操作。
ZoomFFT,实现时,如果细化为原来的D倍,变为Delta_f/D;则要求采样长度相应的也应该是原来的D倍,D*N;
而既然如此,直接经FFT得到的频谱,其实分辨率本身就是Delta_f/D。ZoomFFT所做的, 只不过直接FFT计算点数是D*N,ZoomFFT通过巧妙的办法,使计算量仍旧是N;并且,只选取我们所关心的“频带”去计算。
对我们而言,我们也可以直接FFT得到频谱后,只绘制我们关心的那个“频带”;相对该直接FFT方法,在获得信息上ZoomFFT没有任何增加;仅仅提高了效率(连这其实都值得商榷,如果我们同时有关心其他频率,ZoomFFT还得重算)。
所以,我认为ZoomFFT的更确切的称呼,应该是“选带分析”,而非“细化分析”;当然这是沿用我理解的前面的细化的定义。
ZoomFFT这一“手段”,在高性能个人数字计算机普及之前的分析仪器时代,对性能的提高意义是十分巨大的,因为那时,哪怕做一组512点的FFT,耗时都是很可观的;但现在,意义已经不再如过去那么显著;毕竟,在PC机上,计算哪怕是较长的FFT已经都是ms-秒级的时间。
当然,目前来说ZoomFFT这一“手段”,对于存储量、计算能力相对弱的便携计算机/仪器而言,还是有意义的。补零确实不能提高客观实在的“物理分辨率”
可是好多振动信号处理领域的学者没有意识到这点。细化是针对FFT分析点数固定的情况下来说的.这在20年前计算机内存小,计算速度慢是有意义的,现在计算机速度快了.可以不用考虑细化技术了
但是,在FFT出现栅栏效应时,可以有弥补作用
到底该怎么实现“细化”?
我理解,除非对原始信号进行外推或者就是认为采时间上更长的信号,再经FFT得到频谱,否则无法实现真正的“细化”。
现代功率谱分析方法,隐含了对信号的外推,可以突破前述Delta_f=1/Delta_T的限制。
提高频率分辨率最实用的办法是采样更长时间的数据?
正确。
但是还要注意一个问题,采样数据不宜太长,太长的话,即使不考虑存储问题,直接通过FFT做出离散傅里叶频谱还会引起两方面问题:
- DFT没有考虑到系统的时变特性,太长时间里时不变假设还能否成立是个问题
- 分析线数过高,分辨率过高的话;有用信号在频域上分得过细,从测量的角度噪声就可以更加趁虚而入了。
刘馥清教授曾在LMS的培训会上谨慎地建议1600线就可以了,再高的话意义不是太大。
补零
对细化有了更深的了解之后,其实补零也就清晰了
补零对频谱的影响
进行zero padding只是增加了数据的长度,而不是原信号的长度。就好比本来信号是一个周期的余弦信号,如果又给它补了9个周期长度的0,那么信号并不是10个周期的余弦信号,而是一个周期的余弦加一串0,补的0并没有带来新的信息。
其实zero padding等价于频域的sinc函数内插,而这个sinc函数的形状(主瓣宽度)是由补0前的信号长度决定的,补0的作用只是细化了这个sinc函数,并没有改变其主瓣宽度。
而频率分辨率的含义是两个频率不同的信号在频率上可分,也就要求它们不能落到一个sinc函数的主瓣上。
所以,如果待分析的两个信号频率接近,而时域长度又较短,那么在频域上它们就落在一个sinc主瓣内了,补再多的0也是无济于事的。
补零与离散傅里叶变换的分辨率
离散傅里叶变换(DFT)的输入是一组离散的值,输出同样是一组离散的值。在输入信号而言,相邻两个采样点的间隔为采样时间Ts。在输出信号而言,相邻两个采样点的间隔为频率分辨率fs/N,其中fs为采样频率,其大小等于1/Ts,N为输入信号的采样点数。
这也就是说,DFT的频域分辨率不仅与采样频率有关,也与信号的采样点数有关。
那么,如果保持输入信号长度不变,但却对输入信号进行补零,增加DFT的点数,此时的分辨率是变还是不变?
答案是此时分辨率不变,增加0可以更细致观察频域上的信号,但不会增加频谱分辨率。
从时域来看,假定要把频率相差很小的两个信号区分开来,直观上理解,至少要保证两个信号在时域上相差一个完整的周期,也即是相位相差2*pi。
举个例子,假定采样频率为1Hz,要将周期为10s的正弦信号和周期为11s的正弦信号区分开来,那么信号至少要持续110s,两个信号才能相差一个周期,此时周期为10s的那个信号经历的周期数为11,而11s的那个信号经历的周期书为10。转化到频域,这种情况下,时域采样点为110,分辨率为1/110=0.00909,恰好等于两个信号频率只差(1/10-1/11)。如果两个信号在时域上不满足“相差一个完整周期“的话,补零同样也不能满足“相差一个完整周期”,即分辨率不发生变化。
另外,从信息论的角度,也很好理解,对输入信号补零并没有增加输入信号的信息,因此分辨率不会发生变化。
那么,补零到底会带来什么样的影响呢?因为DFT可以看做是对DTFT的采样,补零仅是减小了频域采样的间隔。这样有利于克服由于栅栏效应带来的有些频谱泄露的问题。也就是说,补零可以使信号能在频域被更细致地观察。如果不满足上述“至少相差一个完整周期”的要求,即便是如DTFT一般在频域连续,也无法分辨出两个信号。
那么,影响DFT分辨率最本质的物理机制是什么呢?在于DFT的积累时间,分辨率为积累时间T的倒数。这点从数学公式上可以很容易得到:
fs / N = 1 /(N * Ts)= 1 / T
举个例子说,如果输入信号的时长为10s,那么无论采样频率为多少,当然前提是要满足奈奎斯特定理,其分辨率为1/10=0.1Hz。
补零与插值对FFT的影响
我们常常在对序列进行FFT变换之前会进行补零或者插值操作,但是二者对FFT的影响我一直很模棱两可,现在结合频率分辨率与matlab仿真结果对两者的影响进行总结与分析。
仿真的代码如下:
% 看看插值和补零对FFT结果的影响。
clc
clear
% 采样频率
fs = 4000;
% 三个频率分量
f1 = 200;
f2 = 400;
f3 = 600;
% 采样800个点,1000个点
n = 800;
m = 1200;
t = 0:1/fs:(n-1)/fs;
tt= 0:1/fs:(m-1)/fs;
x = 0.4*sin(2*pi*t*f1) + 0.2*sin(2*pi*t*f2) + 0.1*sin(2*pi*t*f3);
% 补零到1200
x1 = [x zeros(1,1200-length(x))];
% 插值到1200
t2 = 0:1/fs/1.5:(n-1)/fs;
% 进行插值
x2 = interp1(t,x,t2,'linear');
x3 = 0.4*sin(2*pi*tt*f1) + 0.2*sin(2*pi*tt*f2) + 0.1*sin(2*pi*tt*f3);
% 进行FFT变换
y = fft(x);
y1 = fft(x,1200);
y2 = fft(x1);
y3 = fft(x2);
y4=fft(x3);
% 计算,横坐标换算为Hz,纵坐标换算为幅值
figure(1)
plot(fs*[0:length(x)-1]/length(x),abs(y)*2/length(x));title('采样点 800 ');
figure(2)
plot(fs*[0:length(x1)-1]/length(x1),abs(y1)*2/length(x1));title('“高密度”的FFT变换(即FFT变换的点数大于信号的点数)');
figure(3)
plot(fs*[0:length(x1)-1]/length(x1),abs(y2)*2/length(x));title('对原序列进行补零后再进行FFT变换');
figure(4)
plot(fs*[0:length(x2)-1]/length(x2),abs(y3)*2/length(x2));title('插值后再进行FFT变换');
figure(5)
plot(fs*[0:length(x3)-1]/length(x3),abs(y4)*2/length(x3));title('对采样时间延长的信号序列进行FFT变换');
上面五个结果分辨是对原信号直接进行傅立叶变换,第二个是进行“高密度”的FFT变换(即FFT变换的点数大于信号的点数),第三个是对原序列进行补零后再进行FFT变换,第四个是进行插值后再进行FFT变换,第五个是对采样时间延长的信号序列进行FFT变换。
结果如图所示:
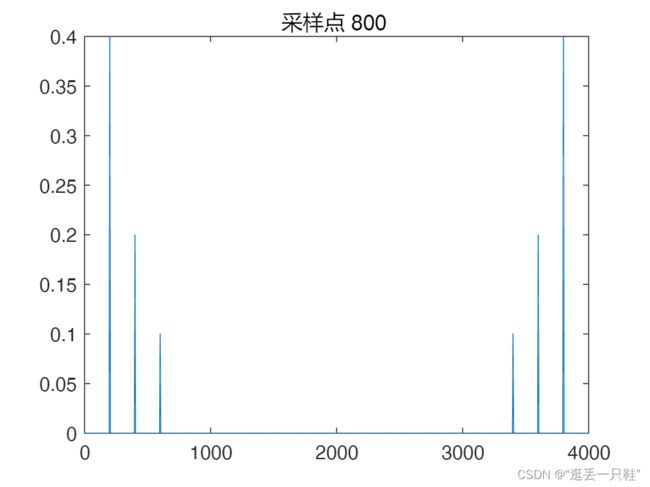

通过两幅图的结果我们可以发现,采样时间延长的谱线会更细一点,频谱的分辨率会更高(即能区分的频率间隔更小),这一点通过对两幅图放大后可以更加直观的发现。



通过上面三幅图的结果可以发现:图一跟图二是一样的,这是因为高密度FFT的处理过程也是先对原序列补零然后再进行FFT,所以两种结果是一样的。
这也提示我们不用自己人为地去给序列做补零操作,在Matlab的变换中,只需要改变进行FFT变换的点数即可。
虽然插值后时域点数增多,但是插值后的谱线宽度也没有减小,这是因为插值相当于提高了采样频率,所以点数会增多,但是采样的时间并没有变,所以频率的分辨率并没有变小,即谱线并没有变细。
如果通过细致地观察,我们还可以发现原序列插值后的FFT结果的旁瓣会减小,但是会出现别的频率分量(小凸起)
频谱泄露
信号的截断
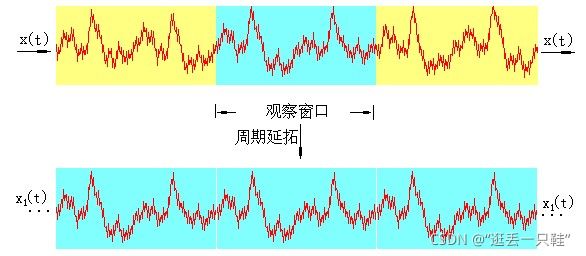
傅里叶变换是研究整个时间域和频率域的关系.然而,当运用计算机实现工程测试信号处理时,不可能对无限长的信号进行测量和运算,而是取其有限的时间片段进行分析。
做法是从信号中截取一个时间片段,然后用观察的信号时间片段进行周期延拓处理,得到虚拟的无限长的信号,然后就可以对信号进行傅里叶变换、相关分析等数学处理。
频谱泄露定义
周期延拓后的信号与真实信号是不同的,下面从数学的角度来看这种处理带来的误差情况。
设有余弦信号x(t)在时域分布为无限长(- ∞,∞),当用矩形窗函数w(t)与其相乘时,得到截断信号xT(t)=x(t)w(t)。根据博里叶变换关系,余弦信号的频谱X(ω)是位于ω。处的δ函数,而矩形窗函数w(t)的谱为sinc(ω)函数,按照频域卷积定理,则截断信号xT(t)的谱XT(ω) 应为
![]()
将截断信号的谱 XT(ω)与原始信号的谱X(ω)相比较可知,它已不是原来的两条谱线,而是两段振荡的连续谱.这表明 原来的信号被截断以后,其频谱发生了畸变,原来集中在f0处的能量被分散到两个较宽的频带中去了,这种现象称之为频谱能量泄漏(Leakage)。
信号截断以后产生的能量泄漏现象是必然的
因为窗函数w(t)是一个频带无限的函数,所以即使原信号x(t)是限带宽信号,而在截断以后也必然成为无限带宽的函数,即信号在频域的能量与分布被扩展了。
又从采样定理可知,无论采样频率多高,只要信号一经截断,就不可避免地引起混叠,因此信号截断必然导致一些误差,这是信号分析中不容忽视的问题。
窗
窗的概念
使用FFT分析信号的频率成分时,分析的是有限的数据集合。FFT认为波形是一组有限数据的集合,一个连续的波形是由若干段小波形组成的。对于FFT而言,时域和频域都是环形的拓扑结构。时间上,波形的前后两个端点是相连的。如测量的信号是周期信号,采集时间内刚好有整数个周期,那么FFT的上述假设合理。

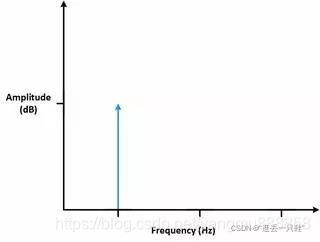
在很多情况下,并不能测量到整数个周期。因此,测量到的信号就会被从周期中间切断,与时间连续的原信号显示出不同的特征。有限数据采样会使测量信号产生剧烈的变化。 这种剧烈的变化称为不连续性。
采集到的周期为非整数时,端点是不连续的。这些不连续片段在FFT中显示为高频成分。这些高频成分不存在于原信号中。这些频率可能远高于奈奎斯特频率,在0~采样率的一半的频率区间内产生混叠。使用FFT获得的频率,不是原信号的实际频率,而是一个改变过的频率。类似于某个频率的能量泄漏至其他频率。这种现象叫做频谱泄漏。频率泄漏使好的频谱线扩散到更宽的信号范围中。
通过加窗来尽可能减少在非整数个周期上进行FFT产生的误差。数字化仪采集到的有限序列的边界会呈现不连续性。加窗可减少这些不连续部分的幅值。加窗包括将时间记录乘以有限长度的窗,窗的幅值逐渐变小,在边沿处为0。加窗的结果是尽可能呈现出一个连续的波形,减少剧烈的变化。这种方法也叫应用一个加窗。

如果增大截断长度T,即矩形窗口加宽,则窗谱W(ω)将被压缩变窄(π/T减小)。虽然理论上讲,其频谱范围仍为无限宽,但实际上中心频率以外的频率分量衰减较快,因而泄漏误差将减小。
当窗口宽度T趋于无穷大时,则谱窗W(ω)将变为δ(ω)函数,而δ(ω)与X(ω)的卷积仍为H(ω),这说明,如果窗口无限宽,即不截断,就不存在泄漏误差。

为了减少频谱能量泄漏,可采用不同的截取函数对信号进行截断,截断函数称为窗函数,简称为窗。泄漏与窗函数频谱的两侧旁瓣有关,如果两侧p旁瓣的高度趋于零,而使能量相对集中在主瓣,就可以较为接近于真实的频谱。
为此,在时间域中可采用不同的窗函数来截断信号。
常用窗函数
实际应用的窗函数,可分为以下主要类型:
幂窗:采用时间变量某种幂次的函数,如矩形、三角形、梯形或其它时间函数x(t)的高次幂;
三角函数窗:应用三角函数,即正弦或余弦函数等组合成复合函数,例如汉宁窗、海明窗等;
指数窗:采用指数时间函数,如e-st形式,例如高斯窗等。
下面介绍几种常用窗函数的性质和特点。
(1)矩形窗
矩形窗属于时间变量的零次幂窗,函数形式为
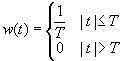
相应的窗谱为
![]()
矩形窗使用最多,习惯上不加窗就是使信号通过了矩形窗。这种窗的优点是主瓣比较集中,缺点是旁瓣较高,并有负旁瓣(下图所示),导致变换中带进了高频干扰和泄漏,甚至出现负谱现象。

(2) 三角窗
三角窗亦称费杰(Fejer)窗,是幂窗的一次方形式,其定义为
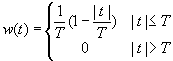
相应的窗谱为
![]()
三角窗与矩形窗比较,主瓣宽约等于矩形窗的两倍,但旁瓣小,而且无负旁瓣,如下图所示。

(3)hamming窗
函数其实很简单。可以使用一个公式来表示:
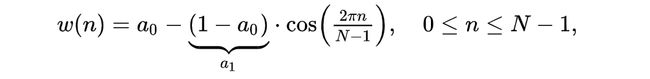
时域加窗在时域上表现的是点乘,因此在频域上则表现为卷积。卷积可以被看成是一个平滑的过程,相当于一组具有特定函数形状的滤波器,因此,原始信号中在某一频率点上的能量会结合滤波器的形状表现出来,从而减小泄漏。

从上图可以看出时域加窗会导致主瓣变宽而旁瓣得到明显降低,并且最大幅值也有所降低。
如何选择“窗函数”?
根据信号的不同,可选择不同类型的加窗函数。要理解窗对信号频率产生怎样的影响,就要先理解窗的频率特性。
窗的波形图显示了窗本身为一个连续的频谱,有一个主瓣,若干旁瓣。主瓣是时域信号频率成分的中央,旁瓣接近于0。旁瓣的高度显示了加窗函数对于主瓣周围频率的影响。对强正弦信号的旁瓣响应可能会超过对较近的弱正弦信号主瓣响应。
一般而言,低旁瓣会减少FFT的泄漏,但是增加主瓣的带宽。旁瓣的跌落速率是旁瓣峰值的渐进衰减速率。增加旁瓣的跌落速率,可减少频谱泄漏。
选择加窗函数并非易事。每一种加窗函数都有其特征和适用范围。要选择加窗函数,必须先估计信号的频率成分
对于一次过程时间小于窗口的暂态信号或冲击波形,信号开始和结束处本身就是零,不存在截断引起的泄露,不需要加窗抑制,因此只需要用矩形窗即可。
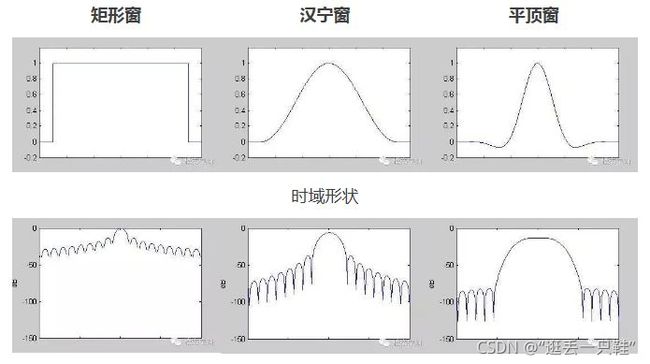

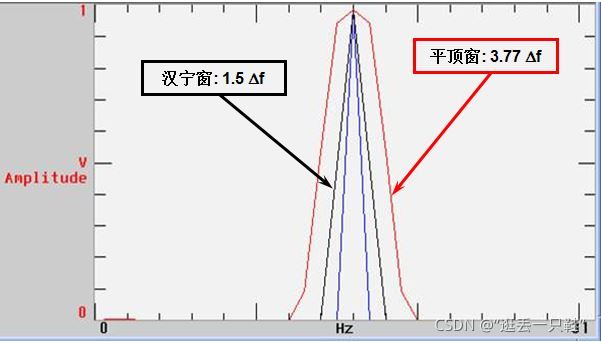
在需要频率分辨率高时,使用旁瓣少的窗口,如汉宁窗,而矩形窗旁瓣太高,泄漏太大;在需要幅值准确时,还可以使用平顶窗。
对于连续的周期性波形,可以结合不同的窗口获得所关注的结果。
窗函数选择标准
如果您的信号具有强干扰频率分量,与感兴趣分量相距较远,那么就应选择具有高旁瓣下降率的平滑窗。
如果您的信号具有强干扰频率分量,与感兴趣分量相距较近,那么就应选择具有低最大旁瓣的窗。
如果感兴趣频率包含两种或多种很距离很近的信号,这时频谱分辨率就非常重要。 在这种情况下,最好选用具有窄主瓣的平滑窗。
如果一个频率成分的幅值精度比信号成分在某个频率区间内精确位置更重要,选择宽主瓣的窗。
如信号频谱较平或频率成分较宽,使用统一窗,或不使用窗。
总之,Hanning窗适用于95%的情况。 它不仅具有较好的频率分辨率,还可减少频谱泄露。如果您不知道信号特征但是又想使用平滑窗,那么就选择Hanning窗。
Hamming窗和Hanning窗都有正弦波的外形。两个窗都会产生宽波峰低旁瓣的结果。Hanning窗在窗口的两端都为0,杜绝了所有不连续性。Hamming窗的窗口两端不为0,信号中仍然会呈现不连续性。Hamming窗擅长减少最近的旁瓣,但是不擅长减少其他旁瓣。Hamming窗和Hanning适用于对频率精度要求较高对旁瓣要求较低的噪声测量。
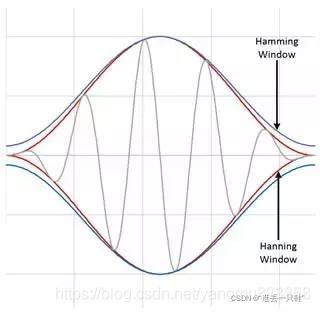
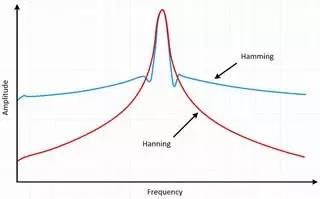
频谱泄漏的原因
结合上述分析,可以得出结论,泄漏的原因来自两方面。
第一:输入频率不是 fs / n 的整数倍。因为DFT只能输出在 fs / n 的频率点上的功率,所以当输入频率不在 fs / n 的整数倍时,在DFT的输出上就没有与输入频率相对应得点(DFT输出是离散的),那么输入频率就会泄漏到所有的输出点上,具体的泄漏分布取决于所采用的窗的连续域复利叶变换,对于没有使用窗的,相当于使用了矩形窗,矩形窗在进行连续傅立叶变换在一般的信号与系统书上都有。
第二:而对于非矩形窗,窗本身就会产生一定的泄漏,是通过加大主瓣的宽度来降低旁瓣的幅度,通常主瓣的宽度变成了矩形窗的两倍,例如当我们输入一个 fs / n 的整数倍的输入频率时,经过非矩形窗,DFT输出会在两个 fs / n 的频点上有功率。
解决办法,可以扩大窗函数的宽度(时域上的宽了,频域上就窄了,(时域频域有相对性),也就是泄露的能量就小了),或者不要加矩形的窗函数,可以加缓变的窗函数,也可以让泄露的能量变下。
因为泄露会照成频谱的扩大,所以也可能会造成频谱混叠的现象,而泄露引起的后果就是降低频谱分辨率。
频谱泄露会令主谱线旁边有很多旁瓣,这就会造成谱线间的干扰,更严重就是旁瓣的能量强到分不清是旁瓣还是信号本身的,这就是所谓的谱间干扰。
加窗应用(汉宁窗)
对于音频信号,最常用的就是汉宁窗
对具体的信号进行加窗的分析
clc;clear;close all;
[x, fs] = audioread('sine_24bit_48k.wav');
N=8192*8; %设置短时傅里叶变换的长度,同时也是汉明窗的长度
h=hamming(N); %设置汉明窗
%sprintf("%d",h);
for m=1:N %用汉明窗截取信号,长度为N,主要是为了减少截断引起的栅栏效应等
b(m)=x(m)*h(m);
end
for mm=1:N
y1(mm)=x(mm);
end
ya=20*log10(abs(fft(y1))); %做傅里叶变换,取其模值,即幅频特性,然后用分贝(dB)表示
% ya=abs(fft(y1));
subplot(2,1,1), %分配画布,一幅图上共两个图,这是第一个
plot(ya);title('original signal'); %画出原始信号,即前面这个音频信号的原始波形
grid %添加网格线
y=20*log10(abs(fft(b))); %做傅里叶变换,取其模值,即幅频特性,然后用分贝(dB)表示
% y=abs(fft(b));
subplot(2,1,2) %分配画布,第二副图
plot(y);title('hamming added signal'); %画出短时谱
grid

加窗对频率和幅值的影响
傅里叶变换后主要的特征有频率、幅值和相位,而加窗对相位的影响是线性的,所以一般不用考虑,下面主要讨论加窗对频率和幅值的影响。
加窗对频率和幅值的影响是关联的,对于时域的单个频率信号,加窗之后的频谱就是将窗谱的谱峰位置平移到信号的频率处,然后进行垂直缩放。说明加窗的影响取决于窗的功率谱,也就容易理解为什么总常看到对窗特征主瓣、旁瓣等的描述。

主瓣变宽就可能与附近的频率的谱相叠加,意味着更难找到叠加后功率谱中最大的频率点,即降低了频率分辨率,较难定位中心频率。旁瓣多意味着信号功率泄露多,主瓣被削弱了,即幅值精度降低了。
由于加窗计算中衰减了原始信号的部分能量,因此对于最后的结果还需要加上修正系数。
FFT变换的幅值和能量校正
对于从时域通过傅立叶变换计算频谱的大多数人来说,幅值和能量校正一直是个困惑点。首先要说的是,数据中包括的信息和幅值与能量修正的频谱是等效的。幅值和能量修正谱的唯一的区别在于计算的比例因子。
幅值修正谱
单独使用分析仪时,你会发现,幅值修正谱通常是默认的设置。每条谱线是时域信号每个频率分量的有效值。如果你有一个有效值为1V的正弦波(如图1所示),用FFT频谱分析仪进行测量,谱线的高度,或信号谱线的组合将始终加起来等于1V的有效值。
1V有效值,20Hz正弦波
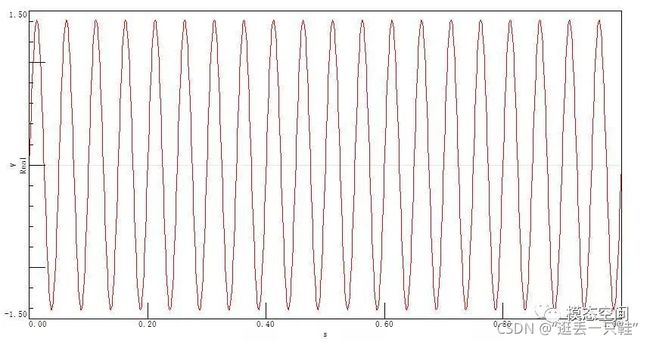
如果在计算这个正弦信号的FFT之前,用户不对时域信号施加任何窗函数,并且信号的频率正好与离散的FFT的某条谱线重叠,那么,这个信号的谱线高度将是1伏的有效值。
也就是意味着若信号的采样频率是48K,同时FFT的采样点数量也是48K,这样,频谱分辨率就会恰好为1Hz,结果是有效值为1V的单条谱线,与预期相同。此时,查看这个频谱的属性,发现窗函数修正模式为幅值修正。

当用户在计算频谱之前,对时域信号施加一个窗函数(通常是汉宁窗)时,得到的结果会让人感到迷惑。
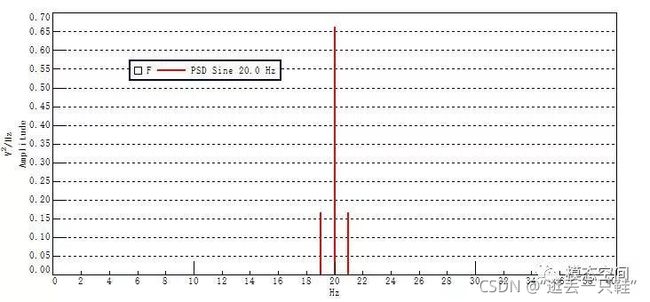
结果如下图所示,不再是单条谱线,而是3条谱线,这3条谱线对应的频率分别为19Hz,20Hz和21Hz,对应的有效值分别为0.5,1和0.5V。查看这个频谱的属性,发现窗函数修正模式仍为幅值修正。
因为施加的窗函数使得时域波形变窄,那么此时,得到的结果是单频的正弦信号却用3条谱线来描述。

这1V有效值的正弦波并没有改变。记得,有效值等于功率谱的平方根,即RMS=sqrt(Power)
因此,这三条谱线的功率总和必须等于1V RMS
但是。这样计算出来的RMS值大于1V,原始时域信号的有效值并没有改变,但为何计算出来的有效值却变大了呢?

从这里,我们也可以发现,幅值修正时,并没有修正每条谱线。如果对每条谱线进行了修正,那么修正后的有效值应该与原始信号的有效值相等,但实际情况却不相等,说明幅值修正不对每条谱线进行修正,那么,幅值修正体现在哪里呢?
当我们采用商业软件来计算有效值时,发现计算得到的有效值仍是1V,这就说明在计算有效值时进行了某种处理,而这个处理恰恰是幅值修正过程。也就是说幅值修正体现在计算有效值时,而不是对每条谱线进行幅值修正。
施加汉宁窗时,汉宁窗的有效噪声带宽(ENBW)是1.5,我们必须用所有谱线的幅值平方和除以这个有效噪声带宽,然后再取平方根。此时,得到的结果为1V的有效值,与预期一样。
因此,如果是幅值修正,计算有效值是用总能量或总功率(所有谱线幅值的平方和)除以有效噪声带宽,然后再开根号,即

也就是说,幅值修正不修正每条谱线的幅值,而是体现在计算信号的有效值时。
仍对之前的时域正弦信号施加汉明窗,频率分辨率为0.5Hz,得到的频谱如图所示
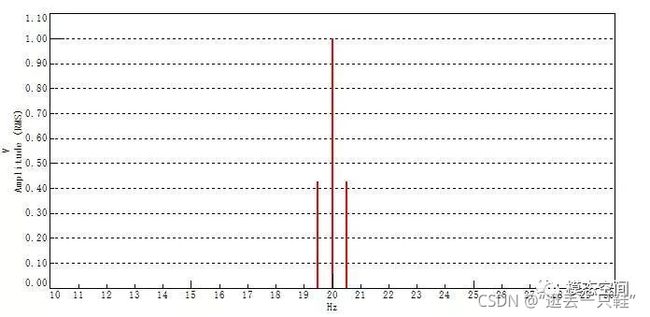
仍为3条频谱,频率分别为19.5Hz、20Hz和20.5Hz,对应的幅值分别为0.4254、0.9989和0.4254V,而汉明窗的有效噪声带宽为1.36,按上式求解有效值为

每个窗函数的有效噪声带宽是个常数,如矩形窗的有效噪声带宽为1.0,汉宁窗为1.5,汉明窗为1.36,平顶窗为3.77等。
遇到的特殊情况是频率分辨率Δf = 1Hz ,如以施加一次汉宁窗为例,ENBW= 1.5 Hz,之前说计算得到的RMS除以2(幅值修正因子),再乘以1.63(能量修正因子)。当然之前说得比较复杂一点,在这仅考虑了有效噪声带宽,但二者是相同的,这是因为
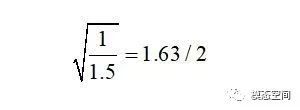
很多同行可能曾经碰到这样的问题:通过软件计算某个频段内的RMS值与将数据导出到excel自行计算得到的总RMS值对不上。这就是因为没有考虑修正的原因造成的。
在Test.Lab软件中,当计算的函数为频谱、线性自功率谱、功率谱时都采用的是幅值修正形式。哪怕功率谱是平方形式,仍采用幅值修正形式。
如图所示为施加汉宁窗的自功率谱,频率分辨率为1Hz,得到3条频线,幅值分别为0.25,1和0.25V2。由于已经是能量形式,所以三个幅值直接相加为 1.5 V2。

能量修正谱
接下来,考虑能量修正。
原始时域信号仍是之前1V的正弦波,对它施加汉宁窗,频率分辨率为1Hz,计算功率谱密度PSD,得到的结果如图所示。结果仍为3条谱线,对应的幅值分别0.167,0.666和0.167。求它的有效值为

可见,对功率谱密度PSD计算有效值时,无须再考虑修正因子ENBW。
查看数据属性,发现窗函数的修正模式为能量修正。也就是说,能量修正已经考虑了修正因子ENBW,计算RMS时,无须再考虑这个修正因子。另一方面,能量修正是对每条谱线进行了修正。正是因为已对每条谱线进行了修正,则在计算有效值时,无须再考虑修正因子。
转换的比例因子关系
等同于计算RMS的公式为:
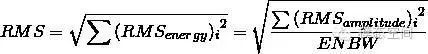
遇到的特殊情况是频率分辨率Δf = 1Hz ,ENBW= 1.5 Hz。这意味着幅值修正比例因子和能量修正比例因子的倍数关系是![]() 或0.816。
或0.816。
插值
对于频谱泄露和栅栏效应,还有一种常见的处理方法就是插值
插值有很多种方法,这里挑选几种进行介绍
插值法又称“内插法”,是利用函数f (x)在某区间中已知的若干点的函数值,作出适当的特定函数,在区间的其他点上用这特定函数的值作为函数f (x)的近似值,这种方法称为插值法。如果这特定函数是多项式,就称它为插值多项式。
线性插值法是指使用连接两个已知量的直线来确定在这两个已知量之间的一个未知量的值的方法。
假设我们已知坐标(x0,y0)与(x1,y1),要得到[x0,x1]区间内某一位置x在直线上的值。根据图中所示,我们得到两点式直线方程:
![]()

假设方程两边的值为α,那么这个值就是插值系数—从x0到x的距离与从x0到x1距离的比值。由于x值已知,所以可以从公式得到α的值:
![]()
同样:
![]()
这样,在代数上就可以表示成为:
y = (1 − α)y0 + αy1
或者,
y = y0 + α(y1 − y0)
这样通过α就可以直接得到 y。实际上,即使x不在x0到x1之间并且α也不是介于0到1之间,这个公式也是成立的。在这种情况下,这种方法叫作线性外插—参见 外插值。
已知y求x的过程与以上过程相同,只是x与y要进行交换。
Matlab仿真
%{
MATLAB中的插值函数为interp1,其调用格式为: yi= interp1(x,y,xi,'method')
其中x,y为插值点,yi为在被插值点xi处的插值结果;x,y为向量,
'method'表示采用的插值方法,MATLAB提供的插值方法有几种:
'nearest'是最邻近插值, 'linear'线性插值; 'spline'三次样条插值; 'pchip'立方插值.缺省时表示线性插值
注意:所有的插值方法都要求x是单调的,并且xi不能够超过x的范围。
%}
x = 0:2*pi;
y = sin(x);
xx = 0:0.5:2*pi;
% interp1对sin函数进行分段线性插值,调用interp1的时候,默认的是分段线性插值
y1 = interp1(x,y,xx,'linear');
subplot(2,2,1);
plot(x,y,'o',xx,y1,'r')
title('分段线性插值')
% 临近插值
y2 = interp1(x,y,xx,'nearest');
subplot(2,2,2);
plot(x,y,'o',xx,y2,'r');
title('临近插值')
%球面线性插值
y3 = interp1(x,y,xx,'spline');
subplot(2,2,3);
plot(x,y,'o',xx,y3,'r')
title('球面插值')
%三次多项式插值法
y4 = interp1(x,y,xx,'pchip');
subplot(2,2,4);
plot(x,y,'o',xx,y4,'r');
title('三次多项式插值')
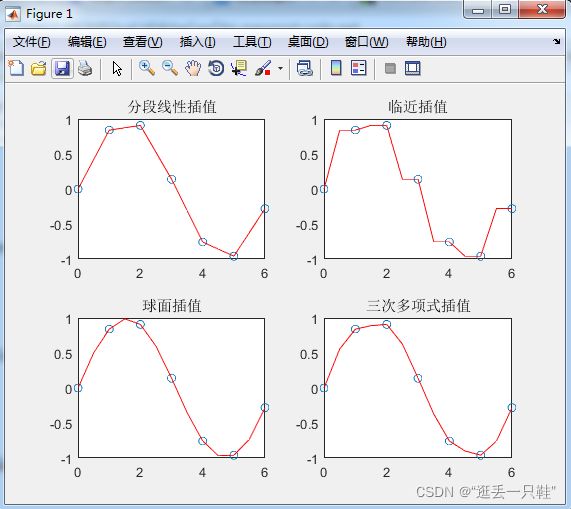
图中可以观察到对于不同的插值方法最后的结果相差还是挺大的
三次样条插值
对于插值,最终根据这篇文章中的分析,采用了三次样条插值的方法
矩阵与数值计算(13)——分段低次插值与三次样条插值
C语言实现
C语言实现代码如下
#include "stdafx.h"
#include "spline.h"
#include 
上述代码经过验证后,在插值48000->65536过程中,插值到44500左右会出现插值出错
不过一般不会对这么长的数据进行插值
下面是另一个spline插值算法,没有了上面代码的长度限制
//=====================================================================================
//函数说明
//函数名称:Spline
//函数功能:三次样条插值(自然边界条件)算法
//使用方法:double *x ---- 结点横坐标
// double *y ---- 结点纵坐标
// double *dy --- 过程变量(调用该函数之前只需为其开辟空间),个数是结点个数
// int n ------- 结点个数
//
// double *t ---- 插入点横坐标
// double *z ---- 插入点拟合值,为输出值
// double *s ---- 过程变量(调用该函数之前只需为其开辟空间),个数是插入点个数
// int m ------- 插入点个数
//=====================================================================================
void Spline(double *x, double *y, double *dy, int n, double *t, double *z, double *s, int m)
{
int i, j;
double h0, h1, alpha, beta;
//-------------------------------------------------------------------
//计算aj和bj
//-------------------------------------------------------------------
dy[0] = -0.5; //a0
h0 = x[1]-x[0];
s[0] = 3.0 *(y[1]-y[0])/(2.0 *h0); //b0
for (j = 1; j <= n-2; j++)
{
h1 = x[j+1]-x[j];
alpha = h0/(h0+h1);
beta = (1.0-alpha)*(y[j]-y[j-1])/h0;
beta = 3.0 *(beta+alpha *(y[j+1]-y[j])/h1);
dy[j] = -alpha/(2.0+(1.0-alpha) *dy[j-1]);//aj
s[j] = (beta-(1.0-alpha) *s[j-1]);
s[j] = s[j]/(2.0+(1.0-alpha) *dy[j-1]); //bj
h0 = h1;
}
//-------------------------------------------------------------------
//利用各结点上的函数值和一阶导数值计算插值点t的函数
//-------------------------------------------------------------------
dy[n-1] = (3.0 *(y[n-1]-y[n-2])/h1-s[n-2])/(2.0+dy[n-2]);
for (j = n-2; j >= 0; j--) //计算结点上的一阶导数值
{
dy[j] = dy[j] *dy[j+1]+s[j];
}
for (j = 0; j <= n-2; j++) //计算hj
{
s[j] = x[j+1]-x[j];
}
for (j = 0; j <= m-1; j++) //计算插值点t的函数值
{
if (t[j] >= x[n-1]) //判断t[j]的所在区间
{
i = n-2;
}
else
{
i = 0;
while (t[j] > x[i+1])
{
i = i+1;
}
}
h1 = (x[i+1]-t[j])/s[i]; //求解
h0 = h1 * h1;
z[j] = (3.0 *h0-2.0 * h0 * h1) *y[i];
z[j] = z[j]+s[i]*(h0-h0 * h1) *dy[i];
h1 = (t[j]-x[i])/s[i];
h0 = h1 * h1;
z[j] = z[j]+(3.0 *h0-2.0 * h0 * h1) *y[i+1];
z[j] = z[j]-s[i]*(h0-h0 * h1) *dy[i+1];
}
}
插值法最大的好处还是可以讲采样信号插值成整数周期,这样就不会导致栅栏效应与频谱泄露