深度学习之图像分类(二十二)-- AS-MLP网络详解
深度学习之图像分类(二十二)AS-MLP网络详解
目录
-
- 深度学习之图像分类(二十二)AS-MLP网络详解
-
- 1. 前言
- 2. AS-MLP 网络结构
- 3. AS-MLP Block
-
- 3.1 Block 结构
- 3.2 Axis Shift
-
- 3.2.1 感受野分析
- 3.2.2 并行串行分析
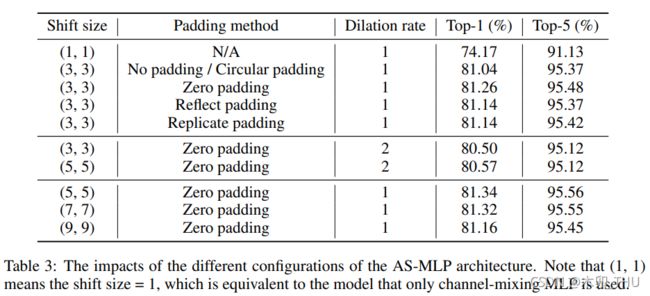
- 3.2.3 padding 分析
- 3.3 额外补充
- 4. AS-MLP 与下游任务
- 5. 总结
- 6. 代码
在上一讲 MLP-Mixer 最后,我提出了几个问题: MLP-Mixer 是否可以为分割、识别等下游任务提供太大的帮助呢?MLP-Mixer 能不能也增加 patch 内的信息交流(局部性)呢?在本节中,我们学习 AS-MLP,它便解决了上面所述的问题。

1. 前言
AS-MLP 是上海科技大学和腾讯优图实验室共同合作发表的文章,论文为 AS-MLP: AN AXIAL SHIFTED MLP ARCHITECTURE FOR VISION。纯 MLP 网络架构专注于全局的信息交流,却忽略了局部信息的收集,而在计算机视觉中,局部特征非常重要,他们可以提供传统计算机视觉中定义的底层特征(边缘,纹理,拐点等等)。为此,本论文提出 Axial shifted,通过特征图的沿空间轴向的 shift,使得不同空间位置的特征处于同一个 Channel,此后的 Channel Projection 就可以融合不同位置的特征,实现局部性信息交流(其思想和 ShuffleNet 也有一定程度的相似)。AS-MLP是首个迁移到下游任务的 MLP 架构,其作为 backbone 的思想和 Swin 基本一致,通过将 token 进行叠加实现下采样。AS-MLP 在ImageNet 数据集上取得了优于其他 MLP 架构的性能,在 COCO 检测与 ADE20K 分割任务上取得了与 Swin 作为 backbone 相当(略弱)的性能。
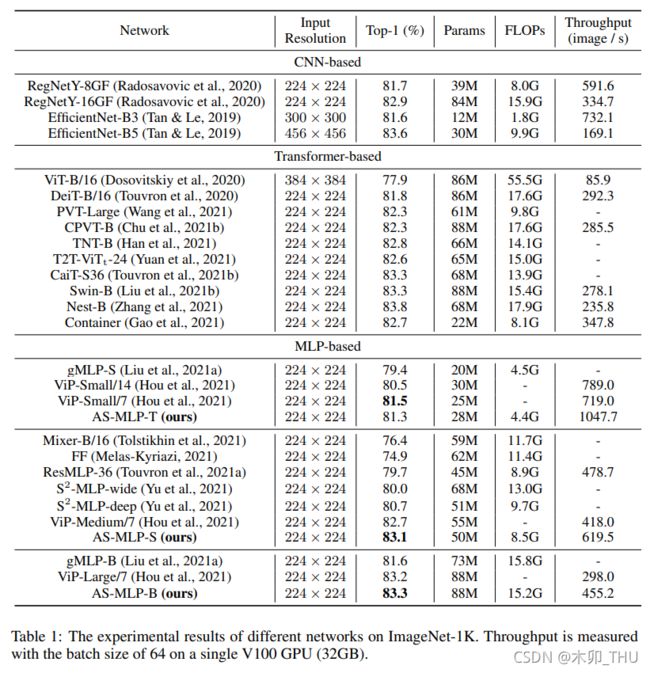
2. AS-MLP 网络结构
AS-MLP 和 Swin 类似,其作为 Backbone 的部分如下图所示。在每个阶段中其实 AS-MLP block 被重复了多次。我们先来全局性地讲一下 AS-MLP怎么工作的:
- 首先是对于一个 3 × H × W 3 \times H \times W 3×H×W 的输入 RGB 图像,将其进行 patch 切片(patch partition),patch 大小为 4 × 4 4 \times 4 4×4,其实也就是 16 个像素暴力叠放到一起这样子,就变成了 48 × H / 4 × W / 4 48 \times H/4 \times W/4 48×H/4×W/4。为什么 patch 大小为 4 × 4 4 \times 4 4×4 呢?我提供一种理解:在 ResNet 等过去的 CNN 中,首先是通过卷积核尺寸为 7 × 7 7 \times 7 7×7 且 stride = 2 的卷积,这里进行了一次下采样。然后经过 BN 和 ReLU 后在经过 maxpooling,又进行了一次下采样,随后馈入多个 Stage 中。所以这里一开始也进行了两倍的下采样,就和过去的 Backbone 一样了。
- 随后 48 × H / 4 × W / 4 48 \times H/4 \times W/4 48×H/4×W/4 的特征图被视为 H / 4 × W / 4 H/4 \times W/4 H/4×W/4 个 token,每个 token 的维度为 48。将其经过一个 Linear Embedding 变为通道数 C = 96 或者 128 等等。之后经过 AS-MLP block。AS-MLP block 延续了 CNN 和 Transformer 等的思想,并不对 token 的维度进行修改,也就是输入多大,输出多大。每经过一个 Stage (多个 AS-MLP block)后,进行一次 patch partition,将 2 × 2 2 \times 2 2×2 领域进行合并,视为一次下采样。则第一个 Stage 后特征图为 4 C × H / 8 × W / 8 4C \times H/8 \times W/8 4C×H/8×W/8 。为了控制维度,就像 CNN 中 Block 一开始的 1 × 1 1 \times 1 1×1 卷积一样,特征图 4 C × H / 8 × W / 8 4C \times H/8 \times W/8 4C×H/8×W/8 被 Linear Embedding 降维到 2 C × H / 8 × W / 8 2C \times H/8 \times W/8 2C×H/8×W/8 ,注意这里的 Linear Embedding 并没有在下图中标注出来。之后的 Stage 和这里的一样,先将 2 × 2 2 \times 2 2×2 领域进行合并,然后进行降维 50%。
- 最后的输出结果经过全局池化和全连接层,就可以得到输出了。

基于 DeiT 和 Swin 等工作的设置,AS-MLP 也提出了 Tiny,Small 和 Base 三种不同的配置,主要涉及 Token 一开始被 Linear Embedding 的维度和每个 Stage 中 AS-MLP block 重复的次数。这样的话不同网络参数量接近,方便进行比较。

3. AS-MLP Block
3.1 Block 结构
在对 AS-MLP 网络整体有个概念后,我们来看看单个 Block 是怎么设计的。粗眼一看,AS-MLP block 和 Transformer block 的整体结构相似,不过将 Multi-Head Self-Attention 部分替换为了 Axial Shift 模块。单个 Axial Shift 模块包含四个全连接层,分别对应于下图中四个 Channel Projection。
-
首先是特征图输入后,对 Channel 进行一个全连接,这里是对于特定位置信息进行交流,其实也就是 1 × 1 1 \times 1 1×1 卷积。
-
中间使用了一个并行结构,分别对特征图进行水平和竖直方向的 circular shift。我们考虑水平方向进行举例,如果 shift size = 3,dilation = 1,则意味着相邻三个特征图分别移动 +1,0,-1;然后再后面三个特征图也这样移动。如果 shift size = 5,dilation = 2,则意味着相邻三个特征图分别移动 +4,+2,0,-2,-4;然后再后面五个特征图也这样移动。分割成组是靠 torch.chunk 函数实现的,旋转则是靠 torch.roll 函数实现的。竖直方向则是一样地操作,就不多做赘述。这样不同位置的特征被重新对齐在一个通道上,对 Channel 进行一个全连接,这里则是对于不同位置信息进行交流,其实也是 1 × 1 1 \times 1 1×1 卷积。得到之后将水平和竖直方向移动后的结果相加,就得到局部交流之后的结果。
-
最后再对 Channel 进行一个全连接,为了将融合后的信息进行整合,其实也就是 1 × 1 1 \times 1 1×1 卷积。
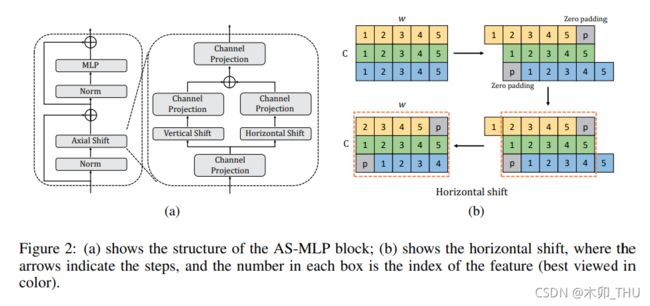
AS-MLP Block 实现的伪代码如图所示:

3.2 Axis Shift
3.2.1 感受野分析
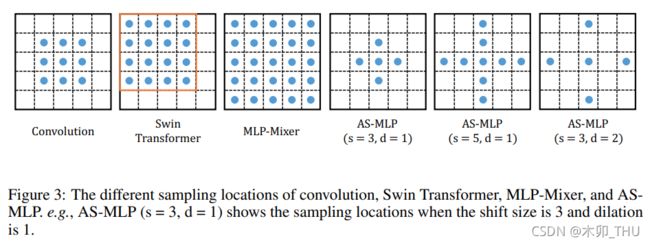
通过轴向移动特征信息,AS-MLP 可以得到不同方向的信息流,这有助于捕获局部相关性。该操作使得我们采用纯 MLP 架构即可取得与 CNN 概念相同的感受野,并可以类似卷积核设置 AS-MLP 模块的感受野尺寸以及扩张因子。下图比较了不同架构模块的感受野范围:
- 传统稠密型卷积的感受野是方状的,是局部依赖;
- Swin 则是在窗口内进行 Self-Attention,感受野在整个窗口内,是局部依赖;
- MLP-Mixer 是全连接层,相当于一个超大型卷积,感受野是整个特征图,是长距离依赖,所以对于局部性特征把握性较差;
- AS-MLP 因为是将水平和竖直方向的移动解耦开,然后进行相加,其得到的是十字形感受野。通过调节感受野尺寸以及扩张因子可以得到不同的感受野。不同设置使得采样位置包含局部依赖与长距离依赖。
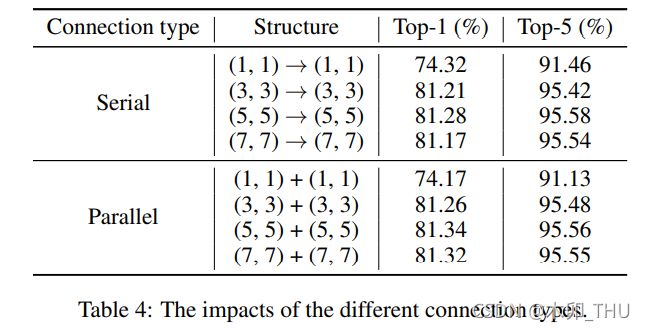
3.2.2 并行串行分析
水平和竖直移动处理已经被解耦开来了,那么将水平和竖直移动串行好还是并行好呢?我认为直观上是并行好,因为这样移动时语义是一致的。作者的实验也发现,并行效果会好一点。至于 shift size = 1,dilation = 1 串行更好其实是没有意义的,因为这时候相当于没有移动,只是两个 1 × 1 1 \times 1 1×1 卷积,之所以结果略有不同是跑的时候的合理波动吧。所以只用看后三行,并行更好一些。
3.2.3 padding 分析
特征图旋转肯定会有特征移动出特征图范围,那么这时候是通过 zero-padding 还是 cycle-padding 好呢?我认为直观上是 zero-padding 好。我提供个人的两个观点:
- 作者采用的转动是暴力的全部转动,水平转动时最左边一列会移动出去,最右边一列会空出来,就造成了一列的信息损失。这时候能够把最左边移动出去的那一列补到右边吗?实际是不好的,因为我们在做图像,且 AS-MLP 对位置是敏感的,图像最左边和最右边不一定有关系,这时候强迫图像最左边和最右边的信息交流不一定能 work。
- 采用 zero-padding 看似会产生信息缺失,实际上在移动的时候是分前中后特征图的,该位置的信息依然可以通过没有移动的中间特征图进行保留。也就是在图像最左边的像素点,它只和它右边的那些像素点进行交流,这是完全 ok 的。至于 Reflect padding 和 replicate padding 其实可被视为在图像最左边的像素点处增加了自己或者右侧像素点的权重(即考虑两次自己和右边像素,或者考虑自己和两次右边像素),这其实意义不大。
综上分析,zero-padding 简单有效,也可理解,实验效果其实也最好。最后作者选择 stride = 5, dilation = 1 进行后续实验。
3.3 额外补充
有人指出,AS-MLP 与百度的那篇 S2-MLP: Spatial-Shift MLP Architecture for Vision (见下图核心模块)真的非常相似,都是采用了垂直、水平移位方式进行空间信息交互,而且还都是上下左右四个方向。可惜 AS-MLP 并未与 S2MLP 进行对比,反而比较晚(指的是见刊arxiv)的 ViP 进行的对比。
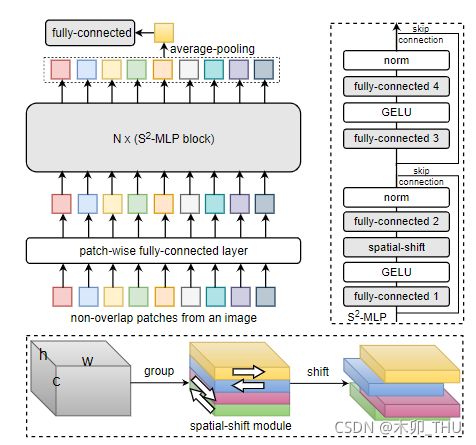
这里顺便将 AS-MLP 与 S2MLP 进行对比,参考知乎 AS-MLP:上海科技&腾讯优图开源首个检测与分割领域MLP架构。
- 在整体架构方面,AS-MLP 采用了类似 PVT 的分层架构,而 S2MLP 一文则是采用了类似 ViT 的柱状架构;
- 在应用方面,AS-MLP 即可应用于图像分类,还可以迁移到下游任务中;而 S2MLP 则仅适用于图像分类,并不适用下游任务;
- 在核心模型方面,AS-MLP 采用并行垂直、水平移动,分别进行特征汇聚后再进行特征相加汇聚;而 S2MLP 则采用分组方式,不同组进行不同方向的移动,然后再进行空间信息汇聚;
- 在模型性能方面,AS-MLP 取得了与 Swin 相当的性能,比 ViP 更优的性能;而 S2MLP 的性能则弱于 Swin 与 ViP;
- 最后一点,AS-MLP 开源了,但 S2MLP 并未开源。
4. AS-MLP 与下游任务
MLP-Mixer 为什么不能用于下游任务?它对于 H 和 W 是敏感的,因为会对 token 内进行映射。
CNN 为什么能用于下游任务?它对于 H 和 W 是不敏感的,因为只会对 channel 进行变换。
所以为了将 AS-MLP 应用于下游任务,其内部只能使用 Channel Projection。所以在只能使用通道维度 1 × 1 1 \times 1 1×1 卷积的基础上,通过把不同位置的特征重排到同一个 channel 是交流空间信息的做法。所以 Axis Shift 操作很自然也不难想到了。
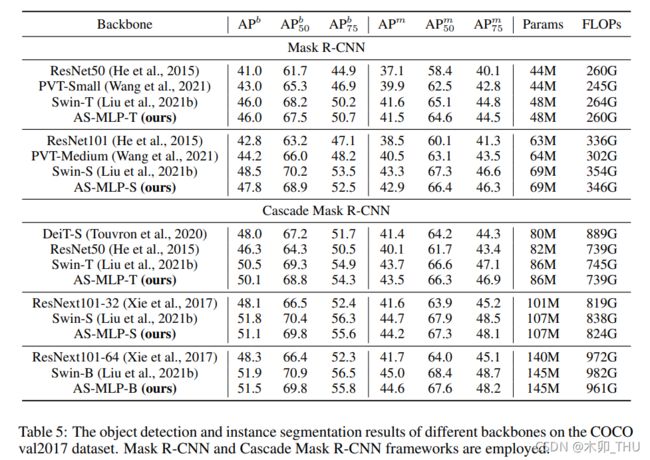
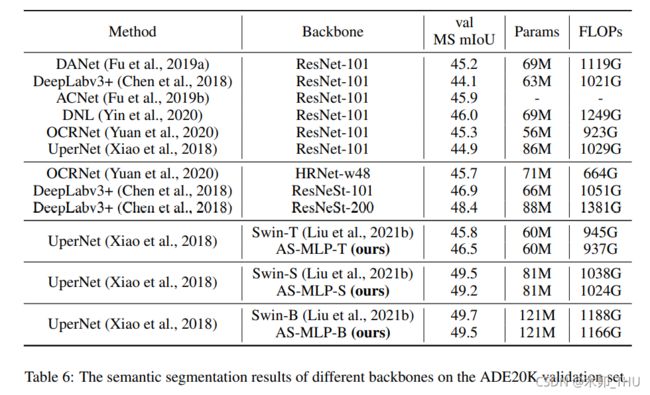
实验结果表明,AS-MLP 作为下游任务的 Backbone 相比于 Swin 略差。
5. 总结
对于 AS-MLP 的一些反思:十字形感受野好吗?十字形感受野操作,它可以更好的提取局部依赖关系吗?不一定!据我了解,暂无理论证明或者过去的传统计算机视觉表明十字形感受野操作可以更好提取视觉底层特征。我们最近的研究确实发现部分计算机底层特征在计算过程中是可以进行正交方向分解的,例如水平方向进行一个操作并在竖直方向进行不同的操作。但是这个感受野应该是类似 Swin 或者传统卷积的稠密型,这样才能得到鲁棒的计算机底层特征。虽然人的视网膜中存在随机性,也可以被视为稠密感受野上增加部分随机掩码,但是这个直接改成稀疏的十字形感受野也不见得好。
AS-MLP 作者最后选择 stride = 5, dilation = 1 进行后续实验。这个真的就能把握长距离依赖吗?对应感受野见 3.2.1 图所示,这其实和卷积中 5 × 5 5 \times 5 5×5 感受野的长宽一致,但是元素数量为 9 个,和卷积中 3 × 3 3 \times 3 3×3 感受野的感知能力一致,所以在我看来并没有实现特征的长距离依赖把握。
AS-MLP 的旋转能不能也考虑更为复杂的和 Swin 一样地分窗旋转呢?或者想 S2MLP 一样方形感受野呢?但是这样做了,依然没有能够把握长距离依赖,干嘛不直接使用 CNN 呢?

Swin 的窗口大,TNT 也可,但是在 MLP 中如何结合图像局部性和长距离依赖依然是值得探讨的点。
6. 代码
代码出处见 此处。 (代码太长,不止一个文件,涉及 Cuda 优化,建议直接看作者开源的工程更好)