InstDisc 代码解读
目录
Unsupervised Feature Learning via Non-Parametric Instance Discrimination 代码解读
0. 概览
1. lemniscate
1.1 lemniscate 的定义
1.2 NCEAverage
1.3 训练时,如何使用这个 NCEAverage 对象
1.4 NCEFunction
2. criterion
Unsupervised Feature Learning via Non-Parametric Instance Discrimination 代码解读
论文下载地址:https://arxiv.org/pdf/1805.01978.pdf
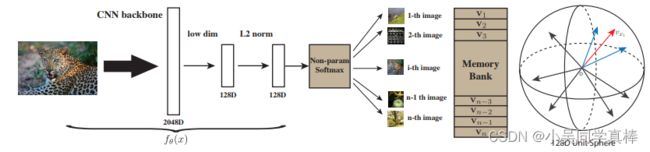
代码地址:GitHub - zhirongw/lemniscate.pytorch: Unsupervised Feature Learning via Non-parametric Instance Discrimination
0. 概览
这里将解读代码最核心的部分:计算 loss 和更新 memory bank 的部分。
在 main.py 文件中找到前向计算 loss 部分的代码:
lemniscate.pytorch/main.py at master · zhirongw/lemniscate.pytorch · GitHub
# compute output
feature = model(input)
output = lemniscate(feature, index)
loss = criterion(output, index) / args.iter_size1. lemniscate
1.1 lemniscate 的定义
lemniscate.pytorch/main.py at master · zhirongw/lemniscate.pytorch · GitHub
# define lemniscate and loss function (criterion)
ndata = train_dataset.__len__() # ndata:整个数据集的长度,也就是 memory bank 的长度
if args.nce_k > 0: # args.nce_k:负样本的个数,默认是采样 4096 个负样本
lemniscate = NCEAverage(args.low_dim, ndata, args.nce_k, args.nce_t, args.nce_m).cuda()
# args.low_dim:memory bank 里存特征的维度 128(看图)
# args.nce_t:计算 NCE Loss 里的温度系数
# args.nce_m:动量更新 memory bank 里特征的 momentum
criterion = NCECriterion(ndata).cuda()
else:
lemniscate = LinearAverage(args.low_dim, ndata, args.nce_t, args.nce_m).cuda()
criterion = nn.CrossEntropyLoss().cuda()所以,lemniscate 是一个 NCEAverage 对象。
1.2 NCEAverage
https://github.com/zhirongw/lemniscate.pytorch/blob/master/lib/NCEAverage.py#L72
class NCEAverage(nn.Module):
def __init__(self, inputSize, outputSize, K, T=0.07, momentum=0.5, Z=None):
super(NCEAverage, self).__init__()
self.nLem = outputSize # 传进来的是 ndata:整个数据集的长度,也就是 memory bank 的长度
self.unigrams = torch.ones(self.nLem) # 创建一个形状为 (ndata, ) 的张量,里面全是 1
self.multinomial = AliasMethod(self.unigrams) # AliasMethod 在这里是用于:随机采样负样本
self.multinomial.cuda()
self.K = K # 随机采样负样本的数量
self.register_buffer('params',torch.tensor([K, T, -1, momentum])); # 用 params 保存参数 K, T, momentum 的值,用于后面计算 NCE loss
stdv = 1. / math.sqrt(inputSize/3)
self.register_buffer('memory', torch.rand(outputSize, inputSize).mul_(2*stdv).add_(-stdv)) # 随机初始化 memory bank
def forward(self, x, y):
batchSize = x.size(0)
idx = self.multinomial.draw(batchSize * (self.K+1)).view(batchSize, -1) # 用 AliasMethod 为 batch 里的每个样本都采样 4096 个负样本的 idx
out = NCEFunction.apply(x, y, self.memory, idx, self.params)
return out总结,lemniscate 这个 NCEAverage 对象在初始化时定义了:用于随机采样负样本的 AliasMethod 对象,随机初始化的 memory bank。
1.3 训练时,如何使用这个 NCEAverage 对象
output = lemniscate(feature, index)可以看到,因为 lemniscate 是 NCEAverage 对象,所以这里自动调用调用了 NCEAverage 的 forward 方法,并传入这个 batch 的图片经过 CNN 提取的特征 feature,以及这个 batch 的图片在数据集的 index。
在 NCEAverage 中 forward 方法里,做了几件事:
- 用 AliasMethod 为 batch 里的每个样本都采样 4096 个负样本的 idx
- 新建 NCEFunction 对象 out,计算输入特征 x 属于 memory bank 中第 i 个样本的概率;由于 NCEFunction 继承 torch.autograd,所以在模型 backward 更新参数的时候,会调用 NCEFunction 里的 backward 函数动量更新 memory bank
1.4 NCEFunction
https://github.com/zhirongw/lemniscate.pytorch/blob/master/lib/NCEAverage.py#L7
forward 函数计算输入特征 x 属于 memory bank 中第 i 个样本的概率,对应论文里的公式:
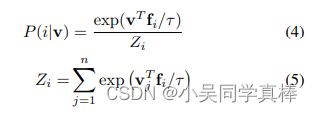
class NCEFunction(Function):
@staticmethod
def forward(self, x, y, memory, idx, params):
K = int(params[0].item())
T = params[1].item()
Z = params[2].item()
momentum = params[3].item()
batchSize = x.size(0)
outputSize = memory.size(0)
inputSize = memory.size(1)
# sample positives & negatives
idx.select(1,0).copy_(y.data)
# sample correspoinding weights
weight = torch.index_select(memory, 0, idx.view(-1))
weight.resize_(batchSize, K+1, inputSize)
# inner product
out = torch.bmm(weight, x.data.resize_(batchSize, inputSize, 1))
out.div_(T).exp_() # batchSize * self.K+1
x.data.resize_(batchSize, inputSize)
if Z < 0:
params[2] = out.mean() * outputSize
Z = params[2].item()
print("normalization constant Z is set to {:.1f}".format(Z))
out.div_(Z).resize_(batchSize, K+1)
self.save_for_backward(x, memory, y, weight, out, params) # 保存变量,在 backward 的时候再更新 memory bank
return outbackward 函数里动量更新 memory bank
@staticmethod
def backward(self, gradOutput):
x, memory, y, weight, out, params = self.saved_tensors
K = int(params[0].item())
T = params[1].item()
Z = params[2].item()
momentum = params[3].item()
batchSize = gradOutput.size(0)
# gradients d Pm / d linear = exp(linear) / Z
gradOutput.data.mul_(out.data)
# add temperature
gradOutput.data.div_(T)
gradOutput.data.resize_(batchSize, 1, K+1)
# gradient of linear
gradInput = torch.bmm(gradOutput.data, weight)
gradInput.resize_as_(x)
# update the non-parametric data: # 动量更新 memory bank
weight_pos = weight.select(1, 0).resize_as_(x)
weight_pos.mul_(momentum)
weight_pos.add_(torch.mul(x.data, 1-momentum))
w_norm = weight_pos.pow(2).sum(1, keepdim=True).pow(0.5)
updated_weight = weight_pos.div(w_norm)
memory.index_copy_(0, y, updated_weight)
return gradInput, None, None, None, None2. criterion
计算 NCE Loss:
https://github.com/zhirongw/lemniscate.pytorch/blob/master/lib/NCECriterion.py#L6
class NCECriterion(nn.Module):
def __init__(self, nLem):
super(NCECriterion, self).__init__()
self.nLem = nLem
def forward(self, x, targets):
batchSize = x.size(0)
K = x.size(1)-1
Pnt = 1 / float(self.nLem)
Pns = 1 / float(self.nLem)
# eq 5.1 : P(origin=model) = Pmt / (Pmt + k*Pnt)
Pmt = x.select(1,0)
Pmt_div = Pmt.add(K * Pnt + eps)
lnPmt = torch.div(Pmt, Pmt_div)
# eq 5.2 : P(origin=noise) = k*Pns / (Pms + k*Pns)
Pon_div = x.narrow(1,1,K).add(K * Pns + eps)
Pon = Pon_div.clone().fill_(K * Pns)
lnPon = torch.div(Pon, Pon_div)
# equation 6 in ref. A
lnPmt.log_()
lnPon.log_()
lnPmtsum = lnPmt.sum(0)
lnPonsum = lnPon.view(-1, 1).sum(0)
loss = - (lnPmtsum + lnPonsum) / batchSize
return