差分隐私 深度学习
Link to part 1 (Basics of Federated Learning): https://towardsdatascience.com/preserving-data-privacy-in-deep-learning-part-1-a04894f78029
链接到第1部分(联合学习的基础): https : //towardsdatascience.com/preserving-data-privacy-in-deep-learning-part-1-a04894f78029
Link to part 2 (Distribution of CIFAR10 into real-world/non-IID dataset):https://towardsdatascience.com/preserving-data-privacy-in-deep-learning-part-2-6c2e9494398b
链接到第2部分(将CIFAR10分发到现实世界/非IID数据集中): https ://towardsdatascience.com/preserving-data-privacy-in-deep-learning-part-2-6c2e9494398b
Many thanks to renowned data scientist Mr. Akshay Kulkarni for his inspiration and guidance on this tutorial.
非常感谢著名的数据科学家Akshay Kulkarni先生对本教程的启发和指导。
What is Federated Learning? What is the non-IID dataset? What changes to make to accumulate non-IID data in Federated Learning? What are the use cases of this type of Deep Learning method?
什么是联合学习? 什么是非IID数据集? 为了在联合学习中累积非IID数据需要进行哪些更改? 这种深度学习方法的用例是什么?
These are some of the questions because of which you are here. This blog is part 3 of the series Preserving Data Privacy in Deep Learning and focuses on the implementation of federated learning with the non-IID dataset. In part 1 of this series, we explored the underlying architecture of federated learning and its basic implementation using PyTorch. But part 1, was unable to deal with the real-world dataset, where any client can have any number of images from the give classes. To tackle this issue, in part 2, we distributed CIFAR 10 (balanced dataset) into non-IID/real-world distribution and further divided it into clients. Now, in order to construct a federated learning model for real-world/non-IID datasets, I am writing this tutorial. In this part of the series, we will use the architecture of federated learning (in part 1) with non-IID clients (in part 2); thus it can be considered as a real-world use case of federated learning.
这些是您在这里遇到的一些问题。 该博客是“在深度学习中保留数据隐私”系列的第3部分,重点介绍了如何使用非IID数据集实现联合学习。 在本系列的第1部分中,我们探索了联合学习的底层体系结构及其使用PyTorch的基本实现。 但是第1部分无法处理现实世界的数据集,在该数据集中,任何客户端都可以从Give类获得任何数量的图像。 为了解决这个问题,在第2部分中 ,我们将CIFAR 10(平衡数据集)分发到了非IID /真实世界的分发中,并将其进一步划分为客户。 现在,为了构建用于实际/非IID数据集的联合学习模型,我正在编写本教程。 在本系列的这一部分中,我们将使用非IID客户端( 第2 部分 )中的联合学习的体系结构( 第1 部分 ); 因此,可以将其视为联合学习的实际用例。
After completing this tutorial, you will know:
完成本教程后,您将知道:
- Federated Learning 联合学习
- Federated Learning architecture for non-IID data 非IID数据的联合学习架构
- Retraining and communication approach in Federated Learning 联合学习中的再培训和交流方法
- Weighted Mean as aggregation technique 加权均值聚合技术
什么是联合学习? (快速回顾) (What is Federated Learning? (A quick recap))
Federated Learning is a type of privacy-preserving method which aims at training an AI model on multiple devices (clients) possessing personal data, without explicitly exchanging or storing the data samples. A global model (weights) is transferred to these devices where the actual training takes place concurrently, incorporating the client-specific features and then updating (aggregating) the global model with all the new features learned during the training at individual devices.
˚Federated学习是一种类型的隐私保护方法的,其目的是培养在多个设备(客户端)具有个人数据的AI模型,没有明确地交换或储存的数据样本。 全局模型(权重)被传输到这些设备上,在这些设备上同时进行实际训练,合并特定于客户端的功能,然后使用在各个设备上训练期间学到的所有新功能来更新(汇总)全局模型。
The next word prediction by Google keyboard is a distinguished example of Federated Learning. Federated Learning processes the device history (typing history) to suggest improvements to the next iteration of Gboard’s query suggestion model.
Google键盘的下一个单词预测是联合学习的杰出示例。 联合学习处理设备历史记录(键入历史记录),以提出对Gboard查询建议模型下一次迭代的改进建议。

Federated Learning is very similar to that of a flower. Just like all the petals (clients) are held by the pedicel (global server), with each petal having different dimensions, and pattern but similar to other petals which constitute to flower (non-IID dataset) and how all the nutrients (weights of the models) are transferred by the pedicel to the petals simultaneously, a flower is a real-life analogy to federated learning.
联合学习与花朵非常相似。 就像所有花瓣(客户端)都由花梗(全局服务器)握住一样,每个花瓣具有不同的尺寸和样式,但类似于构成花朵的其他花瓣(非IID数据集)以及所有养分(重量)的大小。模型)被花梗同时转移到花瓣上,一朵花是联邦学习的现实类比。
To develop a deeper understanding regarding the basic implementation of Federated Learning using Pytorch, please head over to Part 1 of this series.
要加深对使用Pytorch进行联合学习的基本实现的理解,请转到本系列的第1部分 。
Now we are good to proceed to the next and the most exciting section of this blog, playing with the code. This tutorial builds a federated learning model from scratch using PyTorch by converting the balanced CIFAR10 dataset to the non-IID/real-world dataset. There are many aggregating techniques for federated learning, but this study implements the weighted mean of all the weights.
现在,我们很高兴继续阅读本博客的下一个最令人兴奋的部分,并使用代码。 本教程通过将平衡的CIFAR10数据集转换为非IID /真实世界数据集,使用PyTorch从零开始构建联合学习模型。 联合学习有很多汇总技术,但是本研究实现了所有权重的加权平均值。
1.导入库 (1. Importing the libraries)
2.超参数 (2. Hyper-parameters)
classes_pc: classes per client, further this is used to divide the balanced dataset to non-IID dataset by creating an unbalanced representation of classes among the clients. For e.g. if the classes_pc=1, then all the clients will have images from one class only, thus creating an extensive imbalance among the clients.
classes_pc:每个客户端的类,此外,它用于通过在客户端之间创建类的不平衡表示将平衡数据集划分为非IID数据集。 例如,如果classes_pc = 1,则所有客户端将仅具有来自一个类别的图像,从而在客户端之间造成广泛的失衡。
num_clients: Number of clients among which images are to be distributed.
num_clients :要在其中分发图像的客户端数。
num_selected: Number of randomly selected clients from num_clients during the start of each communication round. To be used in the training phase of the global model. Typically, num_selected is around 30–40% of the num_clients.
num_selected:在每个通信回合开始期间,从num_clients中随机选择的客户端数。 将在全局模型的训练阶段中使用。 通常,num_selected约为num_clients的30–40%。
num_rounds: Total number of communication rounds for the global model to train. In each communication round, training on individual clients takes place simultaneously.
num_rounds:全局模型要训练的通信回合总数。 在每一轮交流中,同时针对个别客户进行培训。
epochs: Number of local training rounds on each client’s device.
纪元:每个客户设备上的本地培训回合数。
batch_size: Loading of the data into the data loader in batches.
batch_size:批量将数据加载到数据加载器中。
baseline_num: Total number of baseline images to be saved on the global server for retraining of the client’s model before aggregation. This technique of retraining all the models on the global server deals with non-IID/real-world datasets.
baseline_num:聚合之前要保存在全局服务器上以重新训练客户端模型的基准图像总数。 这种重新训练全局服务器上所有模型的技术处理非IID /真实世界数据集。
retrain_epochs: Total number of retraining rounds on the global server after receiving the model weights from all the clients that participated in the communication round.
retrain_epochs:从参与通信回合的所有客户端收到模型权重后,全局服务器上的重新训练回合总数。
3.将平衡的CIFAR10转换并划分为非IID数据集。 (3. Converting and dividing balanced CIFAR10 into a non-IID dataset.)
CIFAR10 dataset is converted into an extreme non-IID dataset (Refer to part2). CIFAR10 consists of 60,000 color images of 32x32 pixels in 10 classes. The training set consists of 50,000 images, and the remaining 10,000 images are for test purposes.
将CIFAR10数据集转换为极端的非IID数据集(请参阅part2 )。 CIFAR10由10种类别的60,000张32x32像素彩色图像组成。 训练集包含50,000张图像,其余10,000张图像用于测试。
Below is the code, that is explained in detail in part 2 of this series. Please head over to part 2 to understand the following snippet in more detail.
下面是代码,在本系列的第2部分中将对其进行详细说明。 请转到第2部分 ,以更详细地了解以下代码段。
To get deeper insights into the above functions, please read part 2 of this series, where each and every function is explained in detail.
为了对上述功能有更深入的了解,请阅读本系列的第2部分,其中详细介绍了每个功能。
4.建立神经网络(模型架构) (4. Building the Neural Network (Model Architecture))
VGG19 (16 Convolution layers, 3 Fully Connected layers, 5 MaxPool layers, and 1 SoftMax layer) is used in this tutorial.
本教程中使用VGG19(16个卷积层,3个完全连接层,5个MaxPool层和1个SoftMax层)。
5.联合学习的助手功能 (5. Helper functions for Federated Learning)
The baseline_data function creates a loader for the baseline data on which the client’s model is retrained before the aggregation of weights on the global server. ‘num’ is the number of images on which the retraining of client’s model on the global server is supposed to take place. Lines 9–10 gets the CIFAR10 data, and shuffle the training set. Line 12, selects num images from this shuffled dataset, following which it is used to create a Data Loader at line 14.
baseline_data函数为基准数据创建一个加载器,在全局服务器上的权重聚集之前,将在该加载器上对客户机的模型进行重新训练。 “ num”是应该在全局服务器上进行客户端模型重新训练的映像数。 第9–10行获取CIFAR10数据,并拖曳训练集。 第12行从此随机数据集中选择num个图像,然后在第14行将其用于创建数据加载器。
The client_update function trains the client model on the given private client data. This is the local training round that takes place for every selected client, i.e. num_sleected (6 in our case).
client_update函数在给定的私有客户端数据上训练客户端模型。 这是针对每个选定客户进行的本地培训,即num_sleected(在我们的示例中为6)。
The client_sync function synchronizes the client model (before training) with global weights. It helps in the case when a particular client has not participated in the previous communication rounds, so it makes sure that all the selected clients have the previously trained weights from the global model.
client_sync函数(在训练之前)将客户端模型与全局权重同步。 当特定客户未参加之前的交流回合时,它会有所帮助,因此可以确保所有选定的客户都具有全局模型中先前训练过的权重。
The server_aggregate function aggregates the model weights received from every client and updates the global model with updated weights. In this tutorial, the weighted mean of the weights is calculated. In part 1 of this series, instead of the weighted mean, the mean is used as an aggregation method.
server_aggregate函数汇总从每个客户端收到的模型权重,并使用更新的权重更新全局模型。 在本教程中,将计算权重的加权平均值 。 在本系列的第1部分中 ,该平均值代替了加权平均值,而被用作聚合方法。
The test function is the standard function for evaluating the global model with the test dataset. It returns the test loss and test accuracy, which is used for a comparative study of different approaches.
测试函数是用于使用测试数据集评估全局模型的标准函数。 它返回测试损失和测试准确性,用于不同方法的比较研究。
Now, we are done with all the pre-processing of the data and some helper-functions for federated learning. So, lets deep dive into the training of the model, i.e. federated learning with the non-IID dataset.
现在,我们完成了对数据的所有预处理以及用于联合学习的一些辅助功能。 因此,让我们深入研究模型的训练,即使用非IID数据集进行联合学习。
6.训练模型 (6. Training the model)

Global model, client’s models are initialized with the VGG19, and training is done on a GPU. Line 6–11, initializes the model with VGG19 on a GPU (Cuda). At line 14, the optimizer (SGD) is defined along with the learning rate. We can also add the momentum term in our optimizer. At line 17, the baseline data is added to a loader with ‘baseline_num’ images, i.e. 100 images as defined above.
全局模型,客户模型使用VGG19初始化,并在GPU上进行训练。 第6–11行使用GPU(Cuda)上的VGG19初始化模型。 在第14行,定义了优化器(SGD)以及学习率。 我们还可以在优化器中添加动量项。 在第17行,将基线数据与“ baseline_num”图像(即,如上定义的100个图像)一起添加到加载器。
The non-IID data is loaded into a train_loader using the above functions, which ensures the data is non-IID. Classes_pc=2, num_clients=20, batch_size=32.
使用上述函数将非IID数据加载到train_loader中,以确保数据为非IID。 Classes_pc = 2,num_clients = 20,batch_size = 32。
Lines 1–4 create a list for keeping track of the loss and accuracy of the model on train and test dataset. Line 7 starts the training of individual clients in communication rounds (num_rounds). In every communication round, first, the selected clients are updated with the global weights. Then the local model is trained on the client’s device itself, following which the retraining round takes place on the global server. After retraining the client’s model, the aggregation of weights takes place.
第1至4行创建了一个列表,用于跟踪训练和测试数据集上模型的损失和准确性。 第7行开始在通信回合(num_rounds)中对单个客户进行培训。 在每个通信回合中,首先,使用全局权重更新选定的客户端。 然后,在客户端设备本身上训练本地模型,然后在全局服务器上进行重新训练。 在重新训练了客户的模型之后,进行权重的汇总。
Line 9 selects the num_selected clients from num_clients, i.e. six clients are randomly selected from a total of 20 clients. Training at the client’s device is done (Lines 13–17) using the client_sync(line 15), where the local models are updated with the global weights before the training, and then client_update function (line 16) is used to start the training. Once the local models are trained on the device itself, ensuring the privacy of the private data, they are sent to the global server. First, the retraining (lines 12–17) of these models with the baseline data is done. It is followed by the aggregation (line 27) of these local models (weights) into one global model. After updating the global model, this global model is used to test the training (line 28) with the help of the test function defined above.
第9行从num_clients中选择num_selected个客户端,即从总共20个客户端中随机选择了六个客户端。 使用client_sync(第15行)在客户端设备上进行训练(第13-17行),其中在训练之前使用全局权重更新局部模型,然后使用client_update函数(第16行)开始训练。 一旦在设备本身上训练了本地模型,确保了私有数据的私密性,它们就会被发送到全局服务器。 首先,使用基线数据对这些模型进行重新训练(第12-17行)。 接下来是将这些局部模型(权重)聚合(第27行)成为一个全局模型。 更新全局模型后,该全局模型将在上面定义的测试功能的帮助下测试训练(第28行)。
This process continues for num_rounds, i.e. 150 communication rounds in our case. This is the example of the federated learning with the non-IID dataset, and similar can be done for the real-world dataset (defined in part 2), which can be further applied to a real client-based system.
此过程持续num_rounds次,即本例中为150次通信回合。 这是使用非IID数据集进行联合学习的示例,并且可以对真实世界的数据集(在第2部分中定义)执行类似的操作,该数据集可以进一步应用于基于真实客户端的系统。
7.结果 (7. Results)
With 6 selected clients, each running 5 local epochs and retaining on the global server with 20 epochs on the top of 150 communication rounds, below is the truncated test result.
在选择了6个客户端后,每个客户端运行5个本地纪元,并在150个通信回合的顶部保留20个纪元的全局服务器上,以下是截断的测试结果。
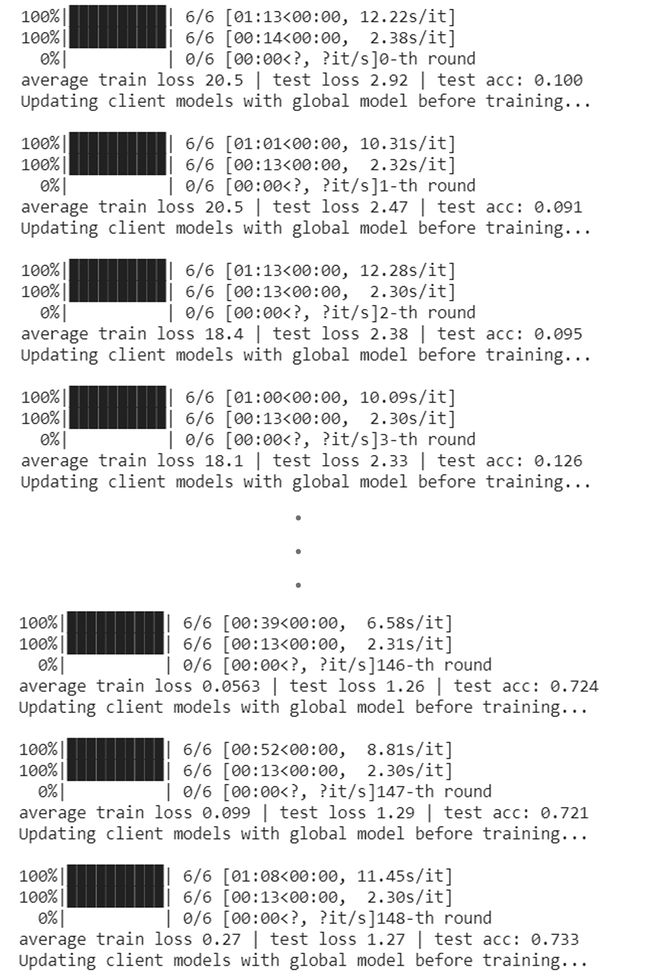
Comparatively, the approach used in this tutorial gives around 72% accuracy, while the one used in part 1 of this series gives around 35% accuracy when applied on a non-IID dataset. Moreover, the current approach (retraining on a global server) is far more stable when compared with other methods available.
相比之下,本教程中使用的方法的准确性约为72% ,而本系列第1部分中使用的方法应用于非IID数据集时的准确性约为35% 。 而且,与其他可用方法相比,当前方法( 在全局服务器上进行再培训 )要稳定得多。
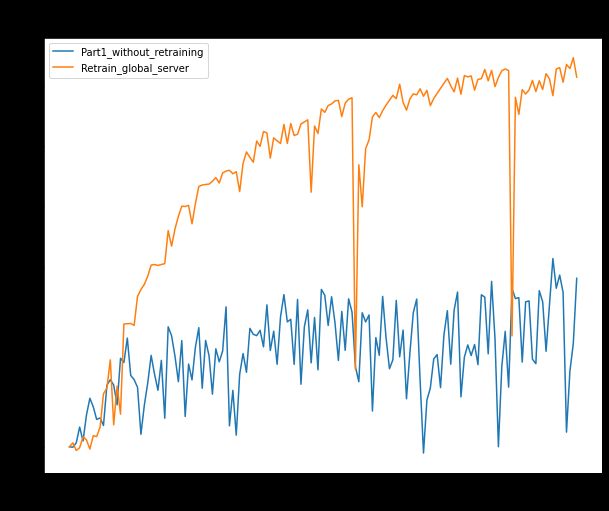
On the comparative study of this approach (retaining on a global server with weighted-mean) with the approach used in part 1, i.e. the basic federated learning with mean, approach 2 (retraining on a global server) outclassed the one used in part 1. This entire tutorial shows the importance of retaining on a global server to handle the dataset’s non-IID issue. Hence, this study is an excellent method to deal with a non-IID dataset problem and can be used in real-world use cases.
在将这种方法(保留在具有加权均值的全局服务器上)与第1部分中使用的方法(即具有均值的基本联合学习)进行的比较研究中,方法2(在全局服务器上进行再培训)优于第1部分中使用的方法。整个教程显示了保留在全局服务器上以处理数据集的非IID问题的重要性。 因此,这项研究是处理非IID数据集问题的绝佳方法,可用于现实世界中的用例。
摘要 (SUMMARY)
In this tutorial, you discovered how to preserve data privacy in deep learning models using federated learning with PyTorch and can be applied to real-world problems.
在本教程中,您发现了如何使用PyTorch的联合学习在深度学习模型中保护数据隐私,并将其应用于实际问题。
Specifically, you learned:
具体来说,您了解到:
- The implementation of Federated Learning with non-IID Dataset 非IID数据集联合学习的实现
- Weighted mean as aggregation technique (we used mean of the weights in part 1) 加权平均值作为聚合技术(我们在第1部分中使用了加权平均值)
- Synchronization of the clients with global weights before training and retraining the client’s models with baseline data on the global server. 在使用全局数据上的基准数据训练和重新训练客户端的模型之前,使客户端与全局权重同步。
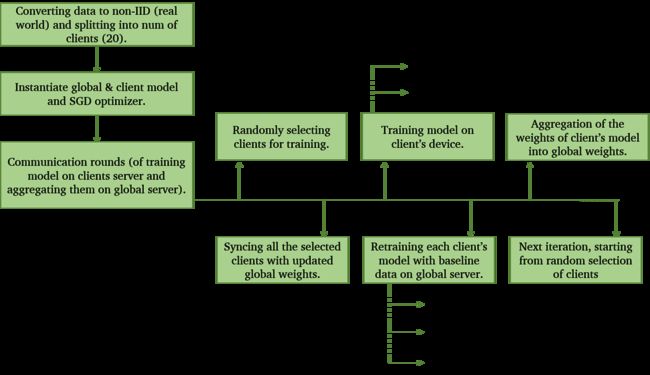
Below is the flow diagram for a quick revision of the entire process.
下面是整个过程的快速修订流程图。
结论 (CONCLUSION)
Federated Learning is one of the leading methods for preserving data privacy in machine learning models. The safety of the client’s data is ensured by only sending the updated weights of the model, not the data. This approach of retraining each client’s model with baseline data deals with the problem of non-IID data. Also, the synchronization of each client’s model with global weights along with the weighted_mean as an aggregation of technique helps in getting a good accuracy of this model. This tutorial deals with the extreme case of a non-IID dataset, but when used for real-life data, it performs better than these results of ours, and it is because the current data is actually more truncated than the ones we deal in a real-life scenario.
联合学习是在机器学习模型中保护数据隐私的主要方法之一。 通过仅发送模型的更新权重而不发送数据来确保客户数据的安全性。 这种用基准数据重新训练每个客户模型的方法解决了非IID数据的问题。 此外,每个客户端模型与全局权重的同步以及作为技术集合的weighted_mean的同步有助于获得此模型的良好准确性。 本教程处理的是非IID数据集的极端情况,但是当用于真实数据时,它的性能要比我们的结果更好,这是因为当前数据实际上比我们处理的数据更被截断。现实场景 。
In the upcoming tutorials, you will not only get to learn about different aggregation techniques in federated learning, but also, homomorphic encryption of the model weights, differential privacy and it’s hybrid with federated learning, and a few more topics helping in preserving the data privacy.
在即将到来的教程中,您不仅将学习联邦学习中的不同聚合技术,而且还将了解模型权重的同态加密,差分隐私及其与联邦学习的混合以及其他一些有助于保护数据隐私的主题。 。
参考资料 (REFERENCES)
[1] Felix Sattler, Robust and Communication-Efficient Federated Learning from Non-IID Data, arXiv:1903.02891
[1] Felix Sattler, 从非IID数据进行的健壮且通信高效的联合学习, arXiv:1903.02891
[2] H.Brendan McMahan, Communication-Efficient Learning of Deep Networks from Decentralized Data, Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS) 2017. JMLR: W&CP volume 54
[2] H.Brendan麦默恩, 从分散的数据深层网络进行通信的,高效的学习 ,第20届国际会议上的人工智能和统计(AISTATS)2017年JMLR论文集:W&CP量54
翻译自: https://towardsdatascience.com/preserving-data-privacy-in-deep-learning-part-3-ae2103c40c22
差分隐私 深度学习