作图的目的是希望在图里面发现问题或者解释问题,当然更本质一点就是你想解决什么问题?
前几天做了一个PCA的图,图是画出来了,但是问题有很多,比如说主成分是是啥意思,图里面的箭头有什么含义?为了不做无意义的重复,所以写一篇文章尝试做一个解释。
我们以R语言自带的数据集iris作为例子来演示。
data(iris)
iris翻译成中文就是鸢(yuan, 第一声)尾花(如下图), 我建议你在R语言里用?iris了解更多这个数据集的出处。

先让我们用head简单看下这个数据集的前面几行。其中前面四列是一朵鸢尾花的一些形态特征衡量值,自行翻译各个单词的含义。最后一列是这朵花的所属物种,根据分类,这些花来自于"setosa, versicolor,virginica"
> head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
在平常人眼里, 看到这些数值可能没有任何想法,也不知道这到底是什么品种,但是对于一个研究鸢尾花的人,这些数值可能会在他们的脑海里重构出一朵鸢尾花,然后迅速判断出这是什么品种。我和阅读文章的人都一样,也不知道如何区分鸢尾花的品种,如果想去研究这种规律,应该怎么做呢?
人类的学习过程过程大多数多看多提出一些模型规律,然后基于这个规律去判断,如果错了改正模型,直到找到一个好用的标准为止。因此,后面我们也就是在当前的数据集下多试试,看看能不能提出一些模型。
可视化是非常强大的工具,让我们先看看能不能用“ Sepal.Length”和“ Sepal.Width”进行区分
library(ggplot2)
ggplot(iris,aes(x=Sepal.Length, y=Sepal.Width)) + geom_point(aes(colour=Species))

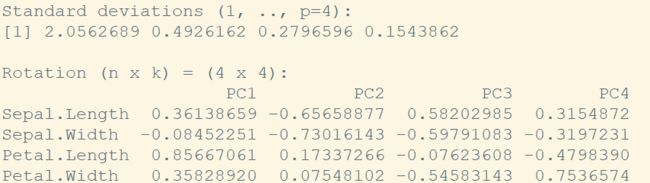
从上图中,我们发现根据萼片(sepal)的宽度和长度似乎能够区分出"setosa"和"versicolor","virginica",但是"versicolor","virginica"不太好分。
让我们再试试花瓣(petal)的长度和宽度。从下图,我们可以发现在这两个属性下,不同品种的鸢尾花似乎有了明显的分界线。
ggplot(iris,aes(x=Petal.Length, y=Petal.Width)) + geom_point(aes(colour=Species))

我们可以建立一个模型就是
- 当花瓣长度小于2时就一定是setosa
- 当花瓣的宽度在0.75~1.75之间,花瓣的长度在3~5,则是versicolor,
- 当花瓣的宽度大于1.75时,花瓣的长度大于5,则是virginica
这个模型依旧还不完善,存在一些点难以区分。不过我们还可以以花瓣长度和萼片长度,花瓣宽度和萼片宽度等你能想到的组合进行作图,说不定能找到更好的模型。更好的情况是,如果人类能够想象出一个四维的空间,在这个空间里面同时展现这四个变量,或许就能更加直观的找到规律,可惜,我们目前还没有这种能力
有没有一种方法能够把这种多维数据降维,也就是抓住数据集的主要矛盾呢?当然是有,这个方法就是100多年前,由卡尔·皮尔森提出的 主成分分析,通过将原来众多具有一定相关性的变量,重新组合成一组新的互相无关的综合变量。比如说我们可以将花瓣长度和宽度组合成花瓣的面积,当然实际计算可能更加复杂,你需要看机器学习中的数学(4)-线性判别分析(LDA), 主成分分析(PCA)。
反正PCA最终的目的就是让原本的数据在降维后方差最大,也就是能把数据分开。我们一般人记住这一点,然后会用软件,能解读结果就好。
R语言能做主成分分析功能很多,比如说prcomp,princomp,principal. 这里用到是prcomp,它使用的是奇异值分解而不是特征值分解,至于这两个有啥区别,其实这不是我关心的,当然你想深入了解到话,建议阅读 机器学习中的数学(5)-强大的矩阵奇异值分解(SVD)及其应用
代码如下:
pca.results <- prcomp(iris[1:4],center = TRUE, retx = T)
prcomp会返回一个列表,里面包含如下内容,你可以用print(pca.results)查看
- sdev: 对应每个主成分的标准偏差,值越大说明解释变异越大。
- rotation: 变量的负荷(loading)矩阵,用于衡量一个变量在各个主成分重要性。
- x: 原矩阵经线性变化后的矩阵(下图不显示,可以用
pca.results$x提取)
虽然有现成的工具提取pca.results里的数据进行作图,但这样无助于理解,我们需要自己手动提取结果进行作图。
iris_rotate_df <- as.data.frame(pca.results$x[,c("PC1","PC2")])
iris_rotate_df$Species <- iris$Species
p <- ggplot(iris_rotate_df, aes(x=PC1, y=PC2)) + geom_point(aes(colour=Species))
print(p)
这个结果虽然也无法完美地区分出"versicolor"和"virginica",但是比我们盲目的寻找好多了。这里的主成分是原来的各个变量线性组合结果。
当然我们还有一个问题,各个变量在不同的主成分里的权重是多少?这个就要看负荷矩阵了,也就是Rotation部分。
在PCA中,我们将协方差矩阵分成了标量部分(特征值)和有向部分(特征向量),通过计算特征向量和开方后特征值的乘积,就称之为负荷(loading)
我们发现在PC1里面Petal.Length的绝对值最大,而在PC2里面,Sepal.Width的绝对值最大,于是我们就可以从原来的数据集中提取这两个变量进行作图了。
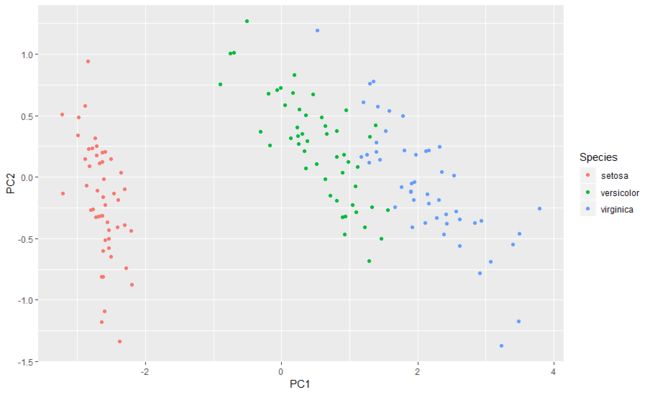
ggplot(iris,aes(x=Sepal.Width, y=Petal.Length)) + geom_point(aes(colour=Species))
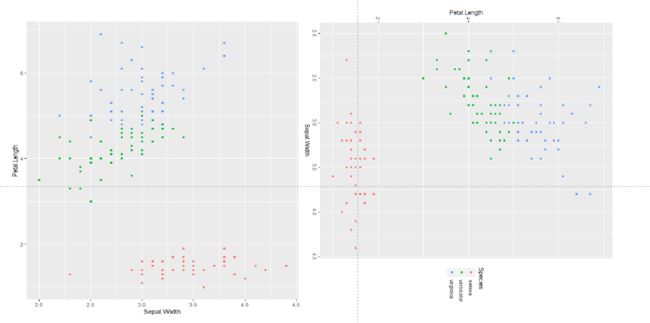
下面的作图直接画图的结果,是不是感觉和上面的PCA图很像。当我手动将其旋转后得到下面的右图,你会发现这和PCA的结果几乎一摸一样。
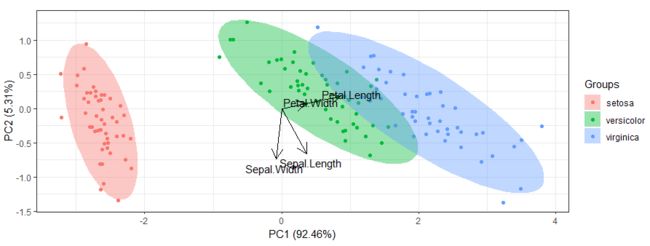
那么我们如何在图上展示各个变量在各个PC的占比呢?这个就需要画几个箭头了,
p + annotate("segment", x=0,xend=0.35,y=0,yend=-0.65,arrow=arrow()) +
annotate("text", x=0.35,y=-0.68, label="Sepal.Length") +
annotate("segment", x=0,xend=-0.08,y=0,yend=-0.73,arrow=arrow()) +
annotate("text", x=-0.08,y=-0.75, label="Sepal.Width")
下图中"Septal.Width"朝下,Petal.Length朝右,如果你手动旋转一下,就是差不多是以"Septal.With"为X轴,"Petal.Length"为Y轴的结果了。 所以箭头的朝向不重要,重点是长度。

当然也有现成的包来完成上图, 不过知道原理后的你应该会解读结果了吧
library(ggord)
ggord(pca.results, iris$Species, size=1.25)
当然要想真正的理解PCA分析,你还是了解一点线性代数的知识