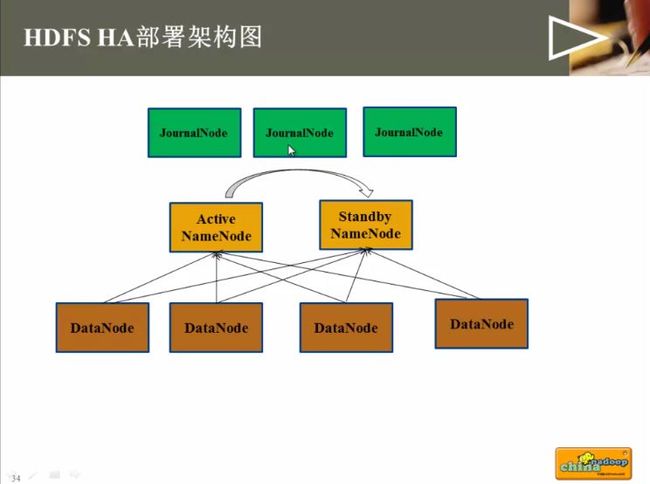
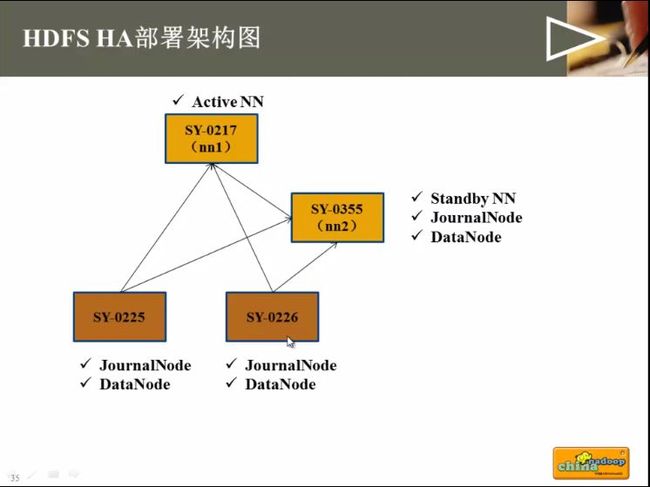
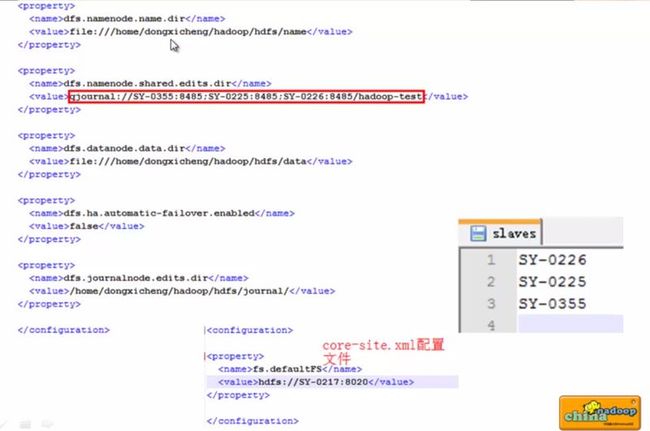
- hadoop运行java程序命令_使用命令行编译打包运行自己的MapReduce程序 Hadoop2.6.0
emi0wb
网上的MapReduceWordCount教程对于如何编译WordCount.java几乎是一笔带过…而有写到的,大多又是0.20等旧版本版本的做法,即javac-classpath/usr/local/hadoop/hadoop-1.0.1/hadoop-core-1.0.1.jarWordCount.java,但较新的2.X版本中,已经没有hadoop-core*.jar这个文件,因此编辑和打
- docker-compose -volumes 两种不同定义方式
胖胖胖胖胖虎
Dockerdockerhadoopbigdata
学习docker-compose部署hadoop集群、看到docker-compose一种不同volumes定义方式version:"3"services:namenode:image:bde2020/hadoop-namenode:2.0.0-hadoop2.7.4-java8volumes:-namenode:/hadoop/dfs/nameenvironment:-CLUSTER_NAME=
- spark程序提交到集群上_Spark集群模式&Spark程序提交
毫无特色
spark程序提交到集群上
Spark集群模式&Spark程序提交1.集群管理器Spark当前支持三种集群管理方式Standalone—Spark自带的一种集群管理方式,易于构建集群。ApacheMesos—通用的集群管理,可以在其上运行HadoopMapReduce和一些服务应用。HadoopYARN—Hadoop2中的资源管理器。Tip1:在集群不是特别大,并且没有mapReduce和Spark同时运行的需求的情况下,用
- Hadoop常用端口号
海洋 之心
Hadoop问题解决hadoophbase大数据
Hadoop是一个由多个组件构成的分布式系统,每个组件都会使用一些特定的端口号来进行通信和交互。以下是Hadoop2.x常用的端口号列表:HDFS端口号:NameNode:50070SecondaryNameNode:50090DataNode:50010DataNode(数据传输):50020YARN端口号:ResourceManager:8088NodeManager:8042MapReduc
- Ubuntu下配置安装Hadoop 2.2
weixin_30501857
大数据java运维
---恢复内容开始---这两天玩Hadoop,之前在我的Mac上配置了好长时间都没成功的Hadoop环境,今天想在win7虚拟机下的Ubuntu12.0464位机下配置,然后再建一个组群看一看。参考资料:1.InstallingsinglenodeHadoop2.2.0onUbuntu:http://bigdatahandler.com/hadoop-hdfs/installing-single-
- 大数据集群搭建基础:Hadoop完全分布式搭建学习指南!!
初次知晓
大数据分布式hadoop
Hadoop完全分布式搭建学习指南Hadoop版本:Hadoop2.XJDK版本:JDK1.8一、准备工作设置主机名和IP在三台CentOS7.4机器上分别设置主机名和IP:node1:192.168.14.10node2:192.168.14.20node3:192.168.14.30修改主机名(以node1为例):hostnamectlset-hostnamenode1配置网络(依据具体网络环
- spark python入门_python pyspark入门篇
weixin_39686634
sparkpython入门
一.环境介绍:1.安装jdk7以上2.python2.7.113.IDEpycharm4.package:spark-1.6.0-bin-hadoop2.6.tar.gz二.Setup1.解压spark-1.6.0-bin-hadoop2.6.tar.gz到目录D:\spark-1.6.0-bin-hadoop2.62.配置环境变量Path,添加D:\spark-1.6.0-bin-hadoop2
- Hadoop3.3.4伪分布式环境搭建
凡许真
分布式hadoop伪分布式hadoop3.3.4
文章目录前言一、准备1.下载Hadoop2.配置环境变量3.配置免密二、Hadoop配置1.hadoop-env.sh2.hdfs-site.xml3.core-site.xml4.mapred-site.xml5.yarn-site.xml三、格式化四、启动五、访问web页面前言hadoop学习——伪分布式环境——普通用户搭建一、准备1.下载Hadoop2.配置环境变量vi~/.bash_pro
- window10下编译hadoop报错:Failed to execute goal org.apache.maven.plugins:maven-antrun-plugin:1.7:
huangxgc
hadoophadoopwindows
Windows10下buildhadoop2.7.3报错:Failedtoexecutegoalorg.apache.maven.plugins:maven-antrun-plugin:1.7:[ERROR]Failedtoexecutegoalorg.apache.maven.plugins:maven-antrun-plugin:1.7:run(dist)onprojecthadoop-hdf
- Hadoop学习笔记 --- YARN执行流程与工作原理
杨鑫newlfe
数据仓库大数据挖掘与大数据应用案例YARNHadoop大数据资源调度数据仓库
一、YARN简述首先介绍一下YARN在Hadoop2.0版本引进的资源管理系统,直接从MapReduceV1演化而来(由于引擎的功能缺陷);原因是将MapReduce1中的JobTracker的资源管理和作业调度两个功能分开,分别由ResourceManager和ApplicationMaster进行实现;ResourceManager:负责整个集群的资源管理和调度ApplicationMaste
- 【深入浅出 Yarn 架构与实现】1-1 设计理念与基本架构
大数据王小皮
深入浅出Yarn架构与实现架构hadoop大数据yarnjava
一、Yarn产生的背景Hadoop2之前是由HDFS和MR组成的,HDFS负责存储,MR负责计算。一)MRv1的问题耦合度高:MR中的jobTracker同时负责资源管理和作业控制两个功能,互相制约。可靠性差:管理节点是单机的,有单点故障的问题。资源利用率低:基于slot的资源分配模型。机器会将资源划分成若干相同大小的slot,并划定哪些是mapslot、哪些是reduceslot。无法支持多种计
- 【YARN】yarn 基础知识整理——hadoop1.0与hadoop2.0区别、yarn总结
时间的美景
HadoopYarnhadoophadoop1hadoop2大数据
文章目录1.hadoop1.0和hadoop2.0区别1.1hadoop1.01.1.1HDFS1.1.2Mapreduce1.2hadoop2.01.2.1HDFS1.2.2Yarn/MapReduce22.Yarn2.1Yarn(YetAnotherResourceNegotiator)概述2.2Yarn的优点2.3Yarn重要概念2.3.1ResourceManager2.3.2NodeMa
- 调试Hadoop源代码
一张假钞
hadoopeclipse大数据
个人博客地址:调试Hadoop源代码|一张假钞的真实世界Hadoop版本Hadoop2.7.3调试模式下启动HadoopNameNode在${HADOOP_HOME}/etc/hadoop/hadoop-env.sh中设置NameNode启动的JVM参数,如下:exportHADOOP_NAMENODE_OPTS="-Xdebug-Xrunjdwp:transport=dt_socket,addr
- Yarn介绍 - 大数据框架
why do not
大数据hadoop
YARN的概述YARN是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序YARN是Hadoop2.x版本中的一个新特性。它的出现其实是为了解决第一代MapReduce编程框架的不足,提高集群环境下的资源利用率,这些资源包括内存,磁盘,网络,IO等。Hadoop2.X版本中重新设计的这个YARN集群
- 大数据知识总结(三):Hadoop之Yarn重点架构原理
Lansonli
大数据大数据hadoop架构Yarn
文章目录Hadoop之Yarn重点架构原理一、Yarn介绍二、Yarn架构三、Yarn任务运行流程四、Yarn三种资源调度器特点及使用场景Hadoop之Yarn重点架构原理一、Yarn介绍ApacheHadoopYarn(YetAnotherReasourceNegotiator,另一种资源协调者)是Hadoop2.x版本后使用的资源管理器,可以为上层应用提供统一的资源管理平台。二、Yarn架构Y
- 《Hadoop系列》Docker安装Hadoop
DATA数据猿
HadoopDockerdockerhadoop
文章目录Docker安装Hadoop1安装docker1.1添加docker到yum源1.2安装docker2安装Hadoop2.1使用docker自带的hadoop安装2.2免密操作2.2.1master节点2.2.2slave1节点2.2.3slave2节点2.2.4将三个容器中的authorized_keys拷贝到本地合并2.2.5将本地authorized_keys文件分别拷贝到3个容器中
- Spark整合hive(保姆级教程)
万家林
sparkhivesparkhadoop
准备工作:1、需要安装配置好hive,如果不会安装可以跳转到Linux下编写脚本自动安装hive2、需要安装配置好spark,如果不会安装可以跳转到Spark安装与配置(单机版)3、需要安装配置好Hadoop,如果不会安装可以跳转到Linux安装配置Hadoop2.6操作步骤:1、将hive的conf目录下的hive-site.xml拷贝到spark的conf目录下(也可以建立软连接)cp/opt
- hadoop-yarn资源分配介绍-以及推荐常用优化参数
Winhole
hadoopLinux
根据网上的学习,结合工作进行的一个整理。如果有什么不正确的欢迎大家一起交流学习~Yarn前言作为Hadoop2.x的一部分,YARN采用MapReduce中的资源管理功能并对其进行打包,以便新引擎可以使用它们。这也简化了MapReduce,使其能够做到最好,处理数据。使用YARN,您现在可以在Hadoop中运行多个应用程序,所有应用程序都共享一个公共资源管理。那资源是有限的,YARN如何识别资源并
- Hadoop手把手逐级搭建 第二阶段: Hadoop完全分布式(full)
郑大能
前置步骤:1).第一阶段:Hadoop单机伪分布(single)0.步骤概述1).克隆4台虚拟机2).为完全分布式配置ssh免密3).将hadoop配置修改为完全分布式4).启动完全分布式集群5).在完全分布式集群上测试wordcount程序1.克隆4台虚拟机1.1使用hadoop0克隆4台虚拟机hadoop1,hadoop2,hadoop3,hadoop41.1.0克隆虚拟机hadoop11.1
- 【解决方案】pyspark 初次连接mongo 时报错Class not found exception:com.mongodb.spark.sql.DefaultSource
能白话的程序员♫
Sparkspark
部分报错如下:Traceback(mostrecentcalllast): File"/home/cisco/spark-mongo-test.py",line7,in df=spark.read.format("com.mongodb.spark.sql.DefaultSource").load() File"/home/cisco/spark-2.4.1-bin-hadoop2.
- Hadoop-Yarn-ResourceManagerHA
隔着天花板看星星
hadoop大数据分布式
在这里先给屏幕面前的你送上祝福,祝你在未来一年:技术步步高升、薪资节节攀升,身体健健康康,家庭和和美美。一、介绍在Hadoop2.4之前,ResourceManager是YARN集群中的单点故障ResourceManagerHA是通过Active/Standby体系结构实现的,在任何时候其中一个RM都是活动的,并且一个或多个RM处于备用模式,等待在活动发生任何事情时接管。二、架构官网的架构图如下:
- java大数据hadoop2.9.2 hive操作
crud-boy
java大数据大数据hivehadoop
1、创建常规数据库表(1)创建表createtablet_stu2(idint,namestring,hobbymap)rowformatdelimitedfieldsterminatedby','collectionitemsterminatedby'-'mapkeysterminatedby':';(2)创建文件student.txt1,zhangsan,唱歌:非常喜欢-跳舞:喜欢-游泳:一般
- java大数据hadoop2.9.2 Flume安装&操作
crud-boy
java大数据大数据flume
1、flume安装(1)解压缩tar-xzvfapache-flume-1.9.0-bin.tar.gzrm-rfapache-flume-1.9.0-bin.tar.gzmv./apache-flume-1.9.0-bin//usr/local/flume(2)配置cd/usr/local/flume/confcp./flume-env.sh.template./flume-env.shvifl
- Hadoop2.7配置
不会吐丝的蜘蛛侠。
Hadoophadoop大数据hdfs
core-site.xmlfs.defaultFShdfs://bigdata/ha.zookeeper.quorum192.168.56.70:2181,192.168.56.71:2181,192.168.56.72:2181-->hadoop.tmp.dir/export/data/hadoop/tmpfs.trash.interval1440io.file.buffer.size13107
- 现成Hadoop安装和配置,图文手把手交你
叫我小唐就好了
一些好玩的事hadoop大数据分布式课程设计运维
为了可以更加快速的可以使用Hadoop,便写了这篇文章,想尝试自己配置一下的可以参考从零开始配置Hadoop,图文手把手教你,定位错误资源1.两台已经配置好的hadoop2.xshell+Vmware链接:https://pan.baidu.com/s/1oX35G8CVCOzVqmtjdwrfzQ?pwd=3biz提取码:3biz--来自百度网盘超级会员V4的分享两台虚拟机用户名和密码均为roo
- 如何对HDFS进行节点内(磁盘间)数据平衡
格格巫 MMQ!!
hadoophdfshdfshadoop大数据
1.文档编写目的当HDFS的DataNode节点挂载多个磁盘时,往往会出现两种数据不均衡的情况:1.不同DataNode节点间数据不均衡;2.挂载数据盘的磁盘间数据不均衡。特别是这种情况:当DataNode原来是挂载了几个数据盘,当磁盘占用率很高之后,再挂载新的数据盘。由于Hadoop2.x版本并不支持HDFS的磁盘间数据均衡,因此,会造成老数据磁盘占用率很高,新挂载的数据盘几乎很空。在这种情况下
- spark运维问题记录
lishengping_max
Sparkspark
环境:spark-2.1.0-bin-hadoop2.71.Spark启动警告:neitherspark.yarn.jarsnotspark.yarn.archiveisset,fallingbacktouploadinglibrariesunderSPARK_HOME原因:如果没设置spark.yarn.jars,每次提交到yarn,都会把$SPARK_HOME/jars打包成zip文件上传到H
- 大数据组件部署下载链接
运维道上奔跑者
大数据zookeeperhbasekafkahadoophive
Hadoop2.7下载连接:https://archive.apache.org/dist/hadoop/core/hadoop-2.7.6/Hive2.3.2下载连接:http://archive.apache.org/dist/hive/hive-2.3.2/Zookeeper下载连接:https://archive.apache.org/dist/zookeeper/zookeeper-3.
- 【大数据开发运维解决方案】Hadoop+Hive+HBase+Kylin 伪分布式安装指南
运维道上奔跑者
大数据hadoop分布式
Hadoop2.7.6+Mysql5.7+Hive2.3.2+Hbase1.4.9+Kylin2.4单机伪分布式安装文档注意:####################################################################本文档已经有了最新版本,主要改动地方为:1、zookeeper改为使用安装的外置zookeeper而非hbase自带zookeeper,新
- Hadoop2.7.6+Mysql5.7+Hive2.3.2+zookeeper3.4.6+kafka2.11+Hbase1.4.9+Sqoop1.4.7+Kylin2.4单机伪分布式安装及官方案例测
运维道上奔跑者
分布式hbasezookeeperhadoop
####################################################################最新消息:关于spark和Hudi的安装部署文档,本人已经写完,连接:Hadoop2.7.6+Spark2.4.4+Scala2.11.12+Hudi0.5.1单机伪分布式安装注意:本篇文章是在本人写的Hadoop+Hive+HBase+Kylin伪分布式安装指南
- 关于旗正规则引擎规则中的上传和下载问题
何必如此
文件下载压缩jsp文件上传
文件的上传下载都是数据流的输入输出,大致流程都是一样的。
一、文件打包下载
1.文件写入压缩包
string mainPath="D:\upload\"; 下载路径
string tmpfileName=jar.zip; &n
- 【Spark九十九】Spark Streaming的batch interval时间内的数据流转源码分析
bit1129
Stream
以如下代码为例(SocketInputDStream):
Spark Streaming从Socket读取数据的代码是在SocketReceiver的receive方法中,撇开异常情况不谈(Receiver有重连机制,restart方法,默认情况下在Receiver挂了之后,间隔两秒钟重新建立Socket连接),读取到的数据通过调用store(textRead)方法进行存储。数据
- spark master web ui 端口8080被占用解决方法
daizj
8080端口占用sparkmaster web ui
spark master web ui 默认端口为8080,当系统有其它程序也在使用该接口时,启动master时也不会报错,spark自己会改用其它端口,自动端口号加1,但为了可以控制到指定的端口,我们可以自行设置,修改方法:
1、cd SPARK_HOME/sbin
2、vi start-master.sh
3、定位到下面部分
- oracle_执行计划_谓词信息和数据获取
周凡杨
oracle执行计划
oracle_执行计划_谓词信息和数据获取(上)
一:简要说明
在查看执行计划的信息中,经常会看到两个谓词filter和access,它们的区别是什么,理解了这两个词对我们解读Oracle的执行计划信息会有所帮助。
简单说,执行计划如果显示是access,就表示这个谓词条件的值将会影响数据的访问路径(表还是索引),而filter表示谓词条件的值并不会影响数据访问路径,只起到
- spring中datasource配置
g21121
dataSource
datasource配置有很多种,我介绍的一种是采用c3p0的,它的百科地址是:
http://baike.baidu.com/view/920062.htm
<!-- spring加载资源文件 -->
<bean name="propertiesConfig"
class="org.springframework.b
- web报表工具FineReport使用中遇到的常见报错及解决办法(三)
老A不折腾
finereportFAQ报表软件
这里写点抛砖引玉,希望大家能把自己整理的问题及解决方法晾出来,Mark一下,利人利己。
出现问题先搜一下文档上有没有,再看看度娘有没有,再看看论坛有没有。有报错要看日志。下面简单罗列下常见的问题,大多文档上都有提到的。
1、repeated column width is largerthan paper width:
这个看这段话应该是很好理解的。比如做的模板页面宽度只能放
- mysql 用户管理
墙头上一根草
linuxmysqluser
1.新建用户 //登录MYSQL@>mysql -u root -p@>密码//创建用户mysql> insert into mysql.user(Host,User,Password) values(‘localhost’,'jeecn’,password(‘jeecn’));//刷新系统权限表mysql>flush privileges;这样就创建了一个名为:
- 关于使用Spring导致c3p0数据库死锁问题
aijuans
springSpring 入门Spring 实例Spring3Spring 教程
这个问题我实在是为整个 springsource 的员工蒙羞
如果大家使用 spring 控制事务,使用 Open Session In View 模式,
com.mchange.v2.resourcepool.TimeoutException: A client timed out while waiting to acquire a resource from com.mchange.
- 百度词库联想
annan211
百度
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>RunJS</title&g
- int数据与byte之间的相互转换实现代码
百合不是茶
位移int转bytebyte转int基本数据类型的实现
在BMP文件和文件压缩时需要用到的int与byte转换,现将理解的贴出来;
主要是要理解;位移等概念 http://baihe747.iteye.com/blog/2078029
int转byte;
byte转int;
/**
* 字节转成int,int转成字节
* @author Administrator
*
- 简单模拟实现数据库连接池
bijian1013
javathreadjava多线程简单模拟实现数据库连接池
简单模拟实现数据库连接池
实例1:
package com.bijian.thread;
public class DB {
//private static final int MAX_COUNT = 10;
private static final DB instance = new DB();
private int count = 0;
private i
- 一种基于Weblogic容器的鉴权设计
bijian1013
javaweblogic
服务器对请求的鉴权可以在请求头中加Authorization之类的key,将用户名、密码保存到此key对应的value中,当然对于用户名、密码这种高机密的信息,应该对其进行加砂加密等,最简单的方法如下:
String vuser_id = "weblogic";
String vuse
- 【RPC框架Hessian二】Hessian 对象序列化和反序列化
bit1129
hessian
任何一个对象从一个JVM传输到另一个JVM,都要经过序列化为二进制数据(或者字符串等其他格式,比如JSON),然后在反序列化为Java对象,这最后都是通过二进制的数据在不同的JVM之间传输(一般是通过Socket和二进制的数据传输),本文定义一个比较符合工作中。
1. 定义三个POJO
Person类
package com.tom.hes
- 【Hadoop十四】Hadoop提供的脚本的功能
bit1129
hadoop
1. hadoop-daemon.sh
1.1 启动HDFS
./hadoop-daemon.sh start namenode
./hadoop-daemon.sh start datanode
通过这种逐步启动的方式,比start-all.sh方式少了一个SecondaryNameNode进程,这不影响Hadoop的使用,其实在 Hadoop2.0中,SecondaryNa
- 中国互联网走在“灰度”上
ronin47
管理 灰度
中国互联网走在“灰度”上(转)
文/孕峰
第一次听说灰度这个词,是任正非说新型管理者所需要的素质。第二次听说是来自马化腾。似乎其他人包括马云也用不同的语言说过类似的意思。
灰度这个词所包含的意义和视野是广远的。要理解这个词,可能同样要用“灰度”的心态。灰度的反面,是规规矩矩,清清楚楚,泾渭分明,严谨条理,是决不妥协,不转弯,认死理。黑白分明不是灰度,像彩虹那样
- java-51-输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。
bylijinnan
java
public class PrintMatrixClockwisely {
/**
* Q51.输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。
例如:如果输入如下矩阵:
1 2 3 4
5 6 7 8
9
- mongoDB 用户管理
开窍的石头
mongoDB用户管理
1:添加用户
第一次设置用户需要进入admin数据库下设置超级用户(use admin)
db.addUsr({user:'useName',pwd:'111111',roles:[readWrite,dbAdmin]});
第一个参数用户的名字
第二个参数
- [游戏与生活]玩暗黑破坏神3的一些问题
comsci
生活
暗黑破坏神3是有史以来最让人激动的游戏。。。。但是有几个问题需要我们注意
玩这个游戏的时间,每天不要超过一个小时,且每次玩游戏最好在白天
结束游戏之后,最好在太阳下面来晒一下身上的暗黑气息,让自己恢复人的生气
&nb
- java 二维数组如何存入数据库
cuiyadll
java
using System;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Xml;
using System.Xml.Serialization;
using System.IO;
namespace WindowsFormsApplication1
{
- 本地事务和全局事务Local Transaction and Global Transaction(JTA)
darrenzhu
javaspringlocalglobaltransaction
Configuring Spring and JTA without full Java EE
http://spring.io/blog/2011/08/15/configuring-spring-and-jta-without-full-java-ee/
Spring doc -Transaction Management
http://docs.spring.io/spri
- Linux命令之alias - 设置命令的别名,让 Linux 命令更简练
dcj3sjt126com
linuxalias
用途说明
设置命令的别名。在linux系统中如果命令太长又不符合用户的习惯,那么我们可以为它指定一个别名。虽然可以为命令建立“链接”解决长文件名的问 题,但对于带命令行参数的命令,链接就无能为力了。而指定别名则可以解决此类所有问题【1】。常用别名来简化ssh登录【见示例三】,使长命令变短,使常 用的长命令行变短,强制执行命令时询问等。
常用参数
格式:alias
格式:ali
- yii2 restful web服务[格式响应]
dcj3sjt126com
PHPyii2
响应格式
当处理一个 RESTful API 请求时, 一个应用程序通常需要如下步骤 来处理响应格式:
确定可能影响响应格式的各种因素, 例如媒介类型, 语言, 版本, 等等。 这个过程也被称为 content negotiation。
资源对象转换为数组, 如在 Resources 部分中所描述的。 通过 [[yii\rest\Serializer]]
- MongoDB索引调优(2)——[十]
eksliang
mongodbMongoDB索引优化
转载请出自出处:http://eksliang.iteye.com/blog/2178555 一、概述
上一篇文档中也说明了,MongoDB的索引几乎与关系型数据库的索引一模一样,优化关系型数据库的技巧通用适合MongoDB,所有这里只讲MongoDB需要注意的地方 二、索引内嵌文档
可以在嵌套文档的键上建立索引,方式与正常
- 当滑动到顶部和底部时,实现Item的分离效果的ListView
gundumw100
android
拉动ListView,Item之间的间距会变大,释放后恢复原样;
package cn.tangdada.tangbang.widget;
import android.annotation.TargetApi;
import android.content.Context;
import android.content.res.TypedArray;
import andr
- 程序员用HTML5制作的爱心树表白动画
ini
JavaScriptjqueryWebhtml5css
体验效果:http://keleyi.com/keleyi/phtml/html5/31.htmHTML代码如下:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml"><head><meta charset="UTF-8" >
<ti
- 预装windows 8 系统GPT模式的ThinkPad T440改装64位 windows 7旗舰版
kakajw
ThinkPad预装改装windows 7windows 8
该教程具有普遍参考性,特别适用于联想的机器,其他品牌机器的处理过程也大同小异。
该教程是个人多次尝试和总结的结果,实用性强,推荐给需要的人!
缘由
小弟最近入手笔记本ThinkPad T440,但是特别不能习惯笔记本出厂预装的Windows 8系统,而且厂商自作聪明地预装了一堆没用的应用软件,消耗不少的系统资源(本本的内存为4G,系统启动完成时,物理内存占用比
- Nginx学习笔记
mcj8089
nginx
一、安装nginx 1、在nginx官方网站下载一个包,下载地址是:
http://nginx.org/download/nginx-1.4.2.tar.gz
2、WinSCP(ftp上传工
- mongodb 聚合查询每天论坛链接点击次数
qiaolevip
每天进步一点点学习永无止境mongodb纵观千象
/* 18 */
{
"_id" : ObjectId("5596414cbe4d73a327e50274"),
"msgType" : "text",
"sendTime" : ISODate("2015-07-03T08:01:16.000Z"
- java术语(PO/POJO/VO/BO/DAO/DTO)
Luob.
DAOPOJODTOpoVO BO
PO(persistant object) 持久对象
在o/r 映射的时候出现的概念,如果没有o/r映射,就没有这个概念存在了.通常对应数据模型(数据库),本身还有部分业务逻辑的处理.可以看成是与数据库中的表相映射的java对象.最简单的PO就是对应数据库中某个表中的一条记录,多个记录可以用PO的集合.PO中应该不包含任何对数据库的操作.
VO(value object) 值对象
通
- 算法复杂度
Wuaner
Algorithm
Time Complexity & Big-O:
http://stackoverflow.com/questions/487258/plain-english-explanation-of-big-o
http://bigocheatsheet.com/
http://www.sitepoint.com/time-complexity-algorithms/