NLP文本摘要NO.3 seq2seq数据处理部分
seq2seq实现文本摘要的架构

编码器端负责将输入数据进行编码, 得到中间语义张量.
解码器端负责一次次的循环解析中间语义张量, 得到最终的结果语句.
一般来说, 我们将注意力机制添加在解码器端.
对比于英译法任务, 我们再来看文本摘要任务下的seq2seq架构图:
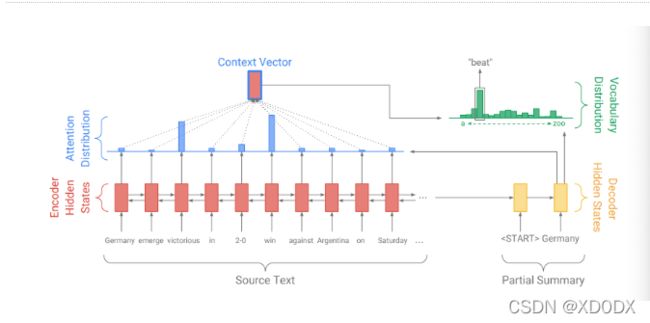
编码器端负责进行原始文本的编码.
注意力层结合编码张量和解码器端的当前输入, 得到总体上的内容张量.
最后在注意力机制的指导下, 解码器端得到完整的单词分布, 解码出当前时间步的单词.
复现Seq2Seq
首先是数据预处理:
这里用的原始数据集是汽车大师APP的数据。
如下:
train.csv长成这个样:
QID,Brand,Model,Question,Dialogue,Report
Q1,奔驰,奔驰GL级,方向机重,助力泵,方向机都换了还是一样,技师说:[语音]|车主说:新的都换了|车主说:助力泵,方向机|技师说:[语音]|车主说:换了方向机带的有|车主说:[图片]|技师说:[语音]|车主说:有助力就是重,这车要匹配吧|技师说:不需要|技师说:你这是更换的部件有问题|车主说:跑快了还好点,就倒车重的很。|技师说:是非常重吗|车主说:是的,累人|技师说:[语音]|车主说:我觉得也是,可是车主是以前没这么重,选吧助理泵换了不行,又把放向机换了,现在还这样就不知道咋和车主解释。|技师说:[语音]|技师说:[语音],随时联系
test.csv长这样:
QID,Brand,Model,Question,Dialogue,Report
Q1,大众(进口),高尔夫(进口),我的帕萨特烧机油怎么办怎么办?,技师说:你好,请问你的车跑了多少公里了,如果在保修期内,可以到当地的4店里面进行检查维修。如果已经超出了保修期建议你到当地的大型维修店进行检查,烧机油一般是发动机活塞环间隙过大和气门油封老化引起的。如果每7500公里烧一升机油的话,可以在后备箱备一些机油,以便机油报警时有机油及时补充,如果超过两升或者两升以上,建议你进行发动机检查维修。|技师说:你好|车主说:嗯
接下来需要实现几个工具函数:
第一步: 实现配置函数config.py
第二步: 实现多核并行处理的函数multi_proc_utils.py
第三步: 实现参数配置函数params_utils.py
第四步: 实现保存字典的函数word2vec_utils.py
第五步: 实现数据加载的函数data_loader.py
我这里就只说一下第四步和第五步。
第四步: 实现保存字典的函数word2vec_utils.py
主要做的工作是利用word2vec模型获得词向量矩阵,再提取word_to_id和id_to_word字典,以及保存word_to_id字典。
from gensim.models.word2vec import Word2Vec
def load_embedding_matrix_from_model(wv_model_path):
# 从word2vec模型中获取词向量矩阵
# wv_model_path: word2vec模型的路径
wv_model = Word2Vec.load(wv_model_path)
# wv_model.wv.vectors包含词向量矩阵
embedding_matrix = wv_model.wv.vectors
return embedding_matrix
def get_vocab_from_model(vocab_path, reverse_vocab_path):
# 提取映射字典
# vocab_path: word_to_id的文件存储路径
# reverse_vocab_path: id_to_word的文件存储路径
word_to_id, id_to_word = {}, {}
with open(vocab_path, 'r', encoding='utf-8') as f1:
for line in f1.readlines():
w, v = line.strip('\n').split('\t')
word_to_id[w] = int(v)
with open(reverse_vocab_path, 'r', encoding='utf-8') as f2:
for line in f2.readlines():
v, w = line.strip('\n').split('\t')
id_to_word[int(v)] = w
return word_to_id, id_to_word
def save_vocab_as_txt(filename, word_to_id):
# 保存字典
# filename: 目标txt文件路径
# word_to_id: 要保存的字典
with open(filename, 'w', encoding='utf-8') as f:
for k, v in word_to_id.items():
f.write("{}\t{}\n".format(k, v))
第五步: 实现数据加载的函数data_loader.py
1: 获取最大长度的函数.(待统计的数据为train_df[‘Question’])
2: 完成文本语句单词到id的数字映射函数.
把句子转换为index序列(被build_dataset调用) sentence: ‘word1 word2 word3 …’ -> [index1, index2, index3 …]
根据word_to_id字典的id进行转换,遇到未知词就填充UNK的索引
ids = [word_to_id[w] if w in word_to_id else word_to_id['<UNK>'] for w in words]
3: 填充特殊标识符的函数.
根据max_len和vocab填充<START> <STOP> <PAD> <UNK>
如下处理:
def pad_proc(sentence, max_len, word_to_id):
# 根据max_len和vocab填充<START> <STOP> <PAD> <UNK>
# 0. 按空格统计切分出词
words = sentence.strip().split(' ')
# 1. 截取规定长度的词数
words = words[:max_len]
# 2. 填充<UNK>
sentence = [w if w in word_to_id else '<UNK>' for w in words]
# 3. 填充<START> <END>
sentence = ['<START>'] + sentence + ['<STOP>']
# 4. 判断长度,填充<PAD>
sentence = sentence + ['<PAD>'] * (max_len - len(words))
# 以空格连接列表, 返回结果字符串
return ' '.join(sentence)
4: 加载停用词表的函数.
不必赘述
def load_stop_words(stop_word_path):
# 加载停用词(程序调用)
# stop_word_path: 停用词路径
# 打开停用词文件
f = open(stop_word_path, 'r', encoding='utf-8')
# 读取所有行
stop_words = f.readlines()
# 去除每一个停用词前后 空格 换行符
stop_words = [stop_word.strip() for stop_word in stop_words]
return stop_words
5: 清洗文本的函数.
用的是常规的那几个:
def clean_sentence(sentence):
# 特殊符号去除(被sentence_proc调用)
# sentence: 待处理的字符串
if isinstance(sentence, str):
# 删除1. 2. 3. 这些标题
r = re.compile("\D(\d\.)\D")
sentence = r.sub("", sentence)
# 删除带括号的 进口 海外
r = re.compile(r"[((]进口[))]|\(海外\)")
sentence = r.sub("", sentence)
# 删除除了汉字数字字母和,!?。.- 以外的字符
r = re.compile("[^,!?。\.\-\u4e00-\u9fa5_a-zA-Z0-9]")
# 用中文输入法下的,!?来替换英文输入法下的,!?
sentence = sentence.replace(",", ",")
sentence = sentence.replace("!", "!")
sentence = sentence.replace("?", "?")
sentence = r.sub("", sentence)
# 删除 车主说 技师说 语音 图片 你好 您好
r = re.compile(r"车主说|技师说|语音|图片|你好|您好")
sentence = r.sub("", sentence)
return sentence
else:
return ''
输入sentence = ‘技师说:你好!以前也出现过该故障吗?|技师说:缸压多少有没有测量一下?|车主说:没有过|车主说:没测缸
压|技师说:测量一下缸压 看一四缸缸压是否偏低|车主说:用电脑测,只是14缸缺火|车主说:[语音]|车主说:[语音]|技师
说:点火线圈 火花塞 喷油嘴不用干活 直接和二三缸对倒一下 跑一段在测量一下故障码进行排除|车主说:[语音]|车主>说:[语音]|车主说:[语音]|车主说:[语音]|车主说:师傅还在吗|技师说:调一下喷油嘴 测一下缸压 都正常则为发动机
电脑板问题|车主说:[语音]|车主说:[语音]|车主说:[语音]|技师说:这个影响不大的|技师说:缸压八个以上正常|车主说
:[语音]|技师说:所以说让你测量缸压 只要缸压正常则没有问题|车主说:[语音]|车主说:[语音]|技师说:可以点击头像
关注我 有什么问题随时询问 一定真诚用心为你解决|车主说:师傅,谢谢了|技师说:不用客气’
调用函数后效果:
res = clean_sentence(sentence)
print('res=', res)
res= !以前也出现过该故障吗?缸压多少有没有测量一下?没有过没测缸压测量一下缸压看一四缸缸压是否偏低用电脑测,只是14缸缺火点火线圈火花塞喷油嘴不用干活直接和二三缸对倒一下跑一段在测量一下故障码进行排除师傅还在吗调一下喷油嘴测一下缸压都正常则为发动机电脑板问题这个影响不大的缸压八个以上正常所以说让你测量缸压只要缸压正常则没有问题可以点击头像关注我有什么问题随时询问一定真诚用心为你解决师傅,谢谢了不用客气
6: 过滤停用词的函数.
不必赘述
def filter_stopwords(seg_list):
# 过滤一句切好词的话中的停用词(被sentence_proc调用)
# seg_list: 切好词的列表 [word1 ,word2 .......]
# 首先去掉多余空字符
words = [word for word in seg_list if word]
# 去掉停用词
return [word for word in words if word not in stop_words]
调用的话,先调用清洗函数,再用jieba.cut分词,得到“seg_list”,再调传入函数filter_stopwords。
即如下操作:
sentence = '技师说:你好!以前也出现过该故障吗?|技师说:缸压多少有没有测量一下?|车主说:没有过|车主说:没测缸
压|技师说:测量一下缸压 看一四缸缸压是否偏低|车主说:用电脑测,只是14缸缺火|车主说:[语音]|车主说:[语音]|技师
说:点火线圈 火花塞 喷油嘴不用干活 直接和二三缸对倒一下 跑一段在测量一下故障码进行排除|车主说:[语音]|车主>说:[语音]|车主说:[语音]|车主说:[语音]|车主说:师傅还在吗|技师说:调一下喷油嘴 测一下缸压 都正常则为发动机
电脑板问题|车主说:[语音]|车主说:[语音]|车主说:[语音]|技师说:这个影响不大的|技师说:缸压八个以上正常|车主说
:[语音]|技师说:所以说让你测量缸压 只要缸压正常则没有问题|车主说:[语音]|车主说:[语音]|技师说:可以点击头像
关注我 有什么问题随时询问 一定真诚用心为你解决|车主说:师傅,谢谢了|技师说:不用客气'
# 第一步: 先将原始文本执行清洗操作
res = clean_sentence(sentence)
# 第二步: 对清洗结果进行分词, 默认是精确模式, 当设置cut_all=True时, 采用全模式
words = jieba.cut(res)
# 第三步: 将分词的结果传入过滤停用词函数中, 并打印结果
result = filter_stopwords(words)
print(result)
效果:
[‘!’, ‘以前’, ‘出现’, ‘过该’, ‘故障’, ‘?’, ‘缸’, ‘压’, ‘有没有’, ‘测量’, ‘一下’, ‘?’, ‘没有’, ‘没测’, ‘缸’, ‘压’, ‘测量’, ‘一下’, ‘缸’, ‘压’, ‘看’, ‘一四缸’, ‘缸’, ‘压’, ‘是否’, ‘偏低’, ‘电脑’, ‘测’, ‘,’, ‘14’, ‘缸’, ‘缺火’, ‘点火’, ‘线圈’, ‘火花塞’, ‘喷油嘴’, ‘不用’, ‘干活’, ‘直接’, ‘二三’, ‘缸’, ‘倒’, ‘一下’, ‘跑’, ‘一段’, ‘测量’, ‘一下’, ‘故障’, ‘码’, ‘进行’, ‘排除’, ‘师傅’, ‘还’, ‘调’, ‘一下’, ‘喷油嘴’, ‘测’, ‘一下’, ‘缸’, ‘压’, ‘都’, ‘正常’, ‘发动机’, ‘电脑板’, ‘问题’, ‘影响’, ‘不大’, ‘缸’, ‘压’, ‘八个’, ‘以上’, ‘正常’, ‘说’, ‘测量’, ‘缸’, ‘压’, ‘缸’, ‘压’, ‘正常’, ‘没有’, ‘问题’, ‘点击’, ‘头像’, ‘关注’, ‘问题’, ‘随时’, ‘询问’, ‘一定’, ‘真诚’, ‘用心’, ‘解决’, ‘师傅’, ‘,’, ‘谢谢’, ‘不用’, ‘客气’]
7: 语句处理的函数.
①:sentence_proc函数
第一步: 执行清洗原始文本的操作
第二步: 执行分词操作, 默认精确模式, 全模式cut参数cut_all=True
第三步: 将分词结果输入过滤停用词函数中
其实就是整合了前面几步,返回字符串结果, 按空格分隔, 将过滤停用词后的列表拼接
return ' '.join(sentence)
②:预处理模块(处理一个句子列表, 对每个句子调用sentence_proc函数操作)
def sentences_proc(df):
# 预处理模块(处理一个句子列表, 对每个句子调用sentence_proc操作)
# df: 数据集
# 批量预处理训练集和测试集
for col_name in ['Brand', 'Model', 'Question', 'Dialogue']:
df[col_name] = df[col_name].apply(sentence_proc)
# 训练集Report预处理
if 'Report' in df.columns:
df['Report'] = df['Report'].apply(sentence_proc)
# 以Pandas的DataFrame格式返回
return df
8: 加载构建好的训练集和测试集的函数.
加载处理好的训练样本和训练标签.npy文件(执行完build_dataset后才能使用)和加载处理好的测试样本.npy文件(执行完build_dataset后才能使用)
import numpy as np
def load_train_dataset(max_enc_len=300, max_dec_len=50):
# max_enc_len: 最长样本长度, 后面的截断
# max_dec_len: 最长标签长度, 后面的截断
train_X = np.load(train_x_path)
train_Y = np.load(train_y_path)
train_X = train_X[:, :max_enc_len]
train_Y = train_Y[:, :max_dec_len]
return train_X, train_Y
def load_test_dataset(max_enc_len=300):
# max_enc_len: 最长样本长度, 后面的截断
test_X = np.load(test_x_path)
test_X = test_X[:, :max_enc_len]
return test_X
9: 完成本步骤总体逻辑的函数build_dataset()函数.
数据预处理总函数, 用于数据加载 + 预处理
①用pd.read_csv 加载原始数据
②利用pandas的dropna函数去除训练集测试集的空值
例:
train_df.dropna(subset=['Question', 'Dialogue', 'Report'], how='any', inplace=True)
test_df.dropna(subset=['Question', 'Dialogue'], how='any', inplace=True)

③利用多线程函数进行批量预处理数据,对每个句子都执行sentence_proc(即前文所讲的,清除无用词, 分词, 过滤停用词, 再用空格拼接为一个字符串)
train_df = parallelize(train_df, sentences_proc)
test_df = parallelize(test_df, sentences_proc)
处理后现在的训练集和测试集数据都长成类似这样:
! 以前 出现 过该 故障 ? 缸 压 有没有 测量 一下 ? 没有 没测 缸 压 测量 一下 缸 压 看 一四缸 缸 压 是否 偏低 电脑 测 , 14 缸 缺火 点火 线圈 火花塞 喷油嘴 不用 干活 直接 二三 缸 倒 一下 跑 一段 测量 一下 故障 码 进行 排除 师傅 还 调 一下 喷油嘴 测 一下 缸 压 都 正常 发动机 电脑板 问题 影响 不大 缸 压 八个 以上 正常 说 测量 缸 压 缸 压 正常 没有 问题 点击 头像 关注 问题 随时 询问 一定 真诚 用心 解决 师傅 , 谢谢 不用 客气
④合并训练测试集, 用于构造映射字典word_to_id
具体操作如下:
利用pandas的apply函数对训练测试集分别:新建一列merged列, 按行堆积。
例:新建merged列,把train_df里面的’Question’, ‘Dialogue’, 'Report’内容以空格连接在一起构成一行。
train_df['merged'] = train_df[['Question', 'Dialogue', 'Report']].apply(lambda x: ' '.join(x), axis=1)
test_df['merged'] = test_df[['Question', 'Dialogue']].apply(lambda x: ' '.join(x), axis=1)
如下:
Question,Dialogue,Report
奔驰 ML500 排气 凸轮轴 调节 错误,你 这个 有没有 电脑 检测 故障 代码 。 有发 一下 发动机 之前 亮 故障 灯 显示 是 失火 有点 缺缸 现在 又 没有 故障 发动机 多少 有点 抖动 检查 先前 的 故障 是 报 这个 故障 稍 等 显示 太大传 不了 这个 对 发动机 的 抖动 失火 缺缸 有 直接 联系 吗 ? 还有 就是 报 左右 排气 凸轮轴 作动 电磁铁 对 正极 短路 对 地 短路 对 导线 断路 这 几个 电磁阀 和 问 您 的 第一个 故障 有 直接 关系 吧 这个 有 办法 检测 它 好坏 吗 ? 谢谢 不 客气,随时 联系
变为:
merged
奔驰 ML500 排气 凸轮轴 调节 错误 你 这个 有没有 电脑 检测 故障 代码 。 有发 一下 发动机 之前 亮 故障 灯 显示 是 失火 有点 缺缸 现在 又 没有 故障 发动机 多少 有点 抖动 检查 先前 的 故障 是 报 这个 故障 稍 等 显示 太大传 不了 这个 对 发动机 的 抖动 失火 缺缸 有 直接 联系 吗 ? 还有 就是 报 左右 排气 凸轮轴 作动 电磁铁 对 正极 短路 对 地 短路 对 导线 断路 这 几个 电磁阀 和 问 您 的 第一个 故障 有 直接 关系 吧 这个 有 办法 检测 它 好坏 吗 ? 谢谢 不 客气 随时 联系
再把训练集测试集的merged列concat一起,(axis=0表示上下堆叠):
例:
merged_df = pd.concat([train_df[['merged']], test_df[['merged']]], axis=0)
训练集行数82871, 测试集行数20000, 合并数据集行数102871
merged列是训练集三列和测试集两列按行连接在一起再按列堆积, 用于构造映射字典
⑤保存分割处理好的train_seg_data.csv, test_set_data.csv
用pandas的drop函数把建立的列merged去掉, 该列对于神经网络无用,再将处理后的train和test数据存入csv文件

train_df = train_df.drop(['merged'], axis=1)
test_df = test_df.drop(['merged'], axis=1)
⑥保存合并数据merged_seg_data.csv, 用于构造映射字典word_to_id
merged_df.to_csv(merged_seg_path, index=None, header=False)
⑦构建word_to_id字典和id_to_word字典, 根据第6步存储的合并文件数据来完成.
主要是根据出现的次数来构造词与数之间的对应关系。
比如说:
a b a
则字典就会为 a:2
b:1
word_to_id = {}
count = 0
# 对训练集数据X进行处理
with open(merged_seg_path, 'r', encoding='utf-8') as f1:
for line in f1.readlines():
line = line.strip().split(' ')
for w in line:
if w not in word_to_id:
word_to_id[w] = 1
count += 1
else:
word_to_id[w] += 1
print('总体单词总数count=', count)
print('\n')
res_dict = {}
number = 0
# 筛选一下,出现次数大于等于5才当成字典的字
for w, i in word_to_id.items():
if i >= 5:
res_dict[w] = i
number += 1
print('进入到字典中的单词总数number=', number)
print('合并数据集的字典构造完毕, word_to_id容量: ', len(res_dict))
print('\n')
word_to_id = {}
count = 0
for w, i in res_dict.items():
if w not in word_to_id:
word_to_id[w] = count
count += 1
print('最终构造完毕字典, word_to_id容量=', len(word_to_id))
print('count=', count)
结果:
总体单词总数count= 124520
进入到字典中的单词总数number= 32227
合并数据集的字典构造完毕, word_to_id容量: 32227
最终构造完毕字典, word_to_id容量= 32227
count= 32227
⑧将Question和Dialogue用空格连接作为模型输入形成train_df[‘X’]
就是指把训练集测试集的‘Question’和‘Dialogue’对应的内容用空格拼接一起构成整个模型的输入‘X’
train_df['X'] = train_df[['Question', 'Dialogue']].apply(lambda x: ' '.join(x), axis=1)
test_df['X'] = test_df[['Question', 'Dialogue']].apply(lambda x: ' '.join(x), axis=1)
⑨填充
# 填充前训练集样本的最大长度为:
train_x_max_len = get_max_len(train_df['X'])
# 填充前测试集样本的最大长度为:
test_x_max_len = get_max_len(test_df['X'])
# 填充前训练集标签的最大长度为:
train_y_max_len = get_max_len(train_df['Report'])
# 选训练集和测试集中较大的值
x_max_len = max(train_x_max_len, test_x_max_len)
需要用到pad_proc函数;
函数如下:
def pad_proc(sentence, max_len, word_to_id):
# 根据max_len和vocab填充<START> <STOP> <PAD> <UNK>
# 0. 按空格统计切分出词
words = sentence.strip().split(' ')
# 1. 截取规定长度的词数
words = words[:max_len]
# 2. 填充<UNK>
sentence = [w if w in word_to_id else '<UNK>' for w in words]
# 3. 填充<START> <END>
sentence = ['<START>'] + sentence + ['<STOP>']
# 4. 判断长度,填充<PAD>
sentence = sentence + ['<PAD>'] * (max_len - len(words))
# 以空格连接列表, 返回结果字符串
return ' '.join(sentence)
对训练集‘X’测试集‘X’训练集‘Y’(Y其实就是‘Report’的内容)都做填充处理:
train_df['X'] = train_df['X'].apply(lambda x: pad_proc(x, x_max_len, word_to_id))
test_df['X'] = test_df['X'].apply(lambda x: pad_proc(x, x_max_len, word_to_id))
train_df['Y'] = train_df['Report'].apply(lambda x: pad_proc(x, train_y_max_len, word_to_id))
⑩保存填充
用to_csv函数保存即可。
train_df['X'].to_csv(train_x_pad_path, index=None, header=False)
train_df['Y'].to_csv(train_y_pad_path, index=None, header=False)
test_df['X'].to_csv(test_x_pad_path, index=None, header=False)
分别对训练集‘X’测试集‘X’训练集‘Y’处理并构造词典word_to_id
例(训练集‘X’):(对’测试集‘X’训练集‘Y’只是改下路径)
with open(train_x_pad_path, 'r', encoding='utf-8') as f1:
for line in f1.readlines():
line = line.strip().split(' ')
for w in line:
if w not in word_to_id:
word_to_id[w] = count
count += 1
构造逆向字典id_to_word:
id_to_word = {}
for w, i in word_to_id.items():
id_to_word[i] = w
更新vocab并保存
save_vocab_as_txt(vocab_path, word_to_id)
save_vocab_as_txt(reverse_vocab_path, id_to_word)
数据集转换 将词转换成索引 [
分别对训练集‘X’测试集‘X’训练集‘Y’处理,对他们中的每句话中的词转换成字典所对应的数字(ID)
例:
train_ids_x = train_df['X'].apply(lambda x: transform_data(x, word_to_id))
另外俩个类似,不赘述。
再把数据转换成numpy数组(需等长)
将索引列表转换成矩阵 [32800, 403, 986, 246, 231] --> array([[32800, 403, 986, 246, 231], …])
train_X = np.array(train_ids_x.tolist())
保存数据
np.save(train_x_path, train_X)
np.save(train_y_path, train_Y)
np.save(test_x_path, test_X)
调用:
if __name__ == '__main__':
build_dataset(train_raw_data_path, test_raw_data_path)