ViT模型——pytorch实现
论文传送门:AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
ViT模型的特点:
抛弃Conv结构,使用Transformer对图像进行特征提取,完成图像分类任务。
ViT模型的结构:

①Embedding:包括Patch Embedding、Position Embedding和Class Embedding;
Patch Embedding:将输入图像划分成一个又一个的子图像(Patch),并转换成向量序列(token);
Position Embedding:在Patch token前添加(拼接)class token,用于分类,为可训练参数;
Position Embedding:对token的位置信息进行编码,使用矩阵加法来实现,为可训练参数;
②Transformer Encoder:将Transformer Encoder Block重复堆叠L层,Transformer Encoder Block的结构如图右所示,为LayerNorm + Multi-Head Attention + Residual + LayerNorm + MLP + Residual;
LayerNorm:NLP领域常用的Normalization方法,计算公式与BN相似,但与Batch无关,而是对每个token(词)进行标准化处理,参考文献:Layer Normalization;
Multi-Head Attention:self-attention的一种,结构与计算公式如下,参考文献:Attention Is All You Need;



MLP:Linear + GELU + Dropout + Linear + Dropout;
③MLP Head:进行LayerNorm,提取class token,然后进行Linear,输出节点个数为类别数量。
(若针对ImageNet-21k数据集,则对class token进行Linear + Tanh + Linear)
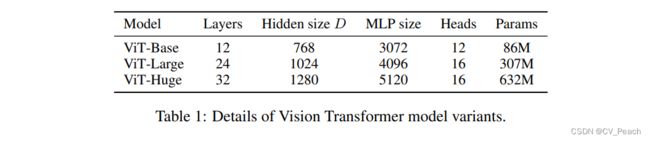
不同规模的ViT模型:
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange
class Embedding(nn.Module): # Patch Embedding + Position Embedding + Class Embedding
def __init__(self, image_channels=3, image_size=224, patch_size=16, dim=768, drop_ratio=0.):
super(Embedding, self).__init__()
self.num_patches = (image_size // patch_size) ** 2 # Patch数量
self.patch_conv = nn.Conv2d(image_channels, dim, patch_size, patch_size) # 使用卷积将图像划分成Patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, dim)) # class embedding
self.pos_emb = nn.Parameter(torch.zeros(1, self.num_patches + 1, dim)) # position embedding
self.dropout = nn.Dropout(drop_ratio)
def forward(self, x):
x = self.patch_conv(x)
x = rearrange(x, "B C H W -> B (H W) C")
cls_token = torch.repeat_interleave(self.cls_token, x.shape[0], dim=0) # (1,1,dim) -> (B,1,dim)
x = torch.cat([cls_token, x], dim=1) # (B,1,dim) cat (B,num_patches,dim) --> (B,num_patches+1,dim)
x = x + self.pos_emb
return self.dropout(x) # token
class MultiHeadAttention(nn.Module): # Multi-Head Attention
def __init__(self, dim, num_heads=8, drop_ratio=0.):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.qkv = nn.Linear(dim, dim * 3, bias=False) # 使用一个Linear,计算得到qkv
self.dropout = nn.Dropout(drop_ratio)
self.proj = nn.Linear(dim, dim)
def forward(self, x):
# B: Batch Size / P: Num of Patches / D: Dim of Patch / H: Num of Heads / d: Dim of Head
qkv = self.qkv(x)
qkv = rearrange(qkv, "B P (C H d) -> C B H P d", C=3, H=self.num_heads, d=self.head_dim)
q, k, v = qkv[0], qkv[1], qkv[2] # 分离qkv
k = rearrange(k, "B H P d -> B H d P")
# Attention(Q, K, V ) = softmax(QKT/dk)V (T表示转置)
attn = torch.matmul(q, k) * self.head_dim ** -0.5 # QKT/dk
attn = F.softmax(attn, dim=-1) # softmax(QKT/dk)
attn = self.dropout(attn)
x = torch.matmul(attn, v) # softmax(QKT/dk)V
x = rearrange(x, "B H P d -> B P (H d)")
x = self.proj(x)
x = self.dropout(x)
return x
class MLP(nn.Module): # MLP
def __init__(self, in_dims, hidden_dims=None, drop_ratio=0.):
super(MLP, self).__init__()
if hidden_dims is None:
hidden_dims = in_dims * 4 # linear的hidden_dims默认为in_dims的4倍
self.fc1 = nn.Linear(in_dims, hidden_dims)
self.fc2 = nn.Linear(hidden_dims, in_dims)
self.gelu = nn.GELU()
self.dropout = nn.Dropout(drop_ratio)
def forward(self, x):
# Linear + GELU + Dropout + Linear + Dropout
x = self.fc1(x)
x = self.gelu(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
return x
class EncoderBlock(nn.Module): # Transformer Encoder Block
def __init__(self, dim, num_heads=8, drop_ratio=0.):
super(EncoderBlock, self).__init__()
self.layernorm1 = nn.LayerNorm(dim)
self.multiheadattn = MultiHeadAttention(dim, num_heads)
self.dropout = nn.Dropout(drop_ratio)
self.layernorm2 = nn.LayerNorm(dim)
self.mlp = MLP(dim)
def forward(self, x):
# 两次残差连接,分别在Multi-Head Attention和MLP之后
x0 = x
x = self.layernorm1(x)
x = self.multiheadattn(x)
x = self.dropout(x)
x1 = x + x0 # 第一次残差连接
x = self.layernorm2(x1)
x = self.mlp(x)
x = self.dropout(x)
return x + x1 # 第二次残差连接
class MLPHead(nn.Module): # MLP Head
def __init__(self, dim, num_classes=1000):
super(MLPHead, self).__init__()
self.layernorm = nn.LayerNorm(dim)
# 对于一般数据集,此处为1层Linear; 对于ImageNet-21k数据集,此处为Linear+Tanh+Linear
self.mlphead = nn.Linear(dim, num_classes)
def forward(self, x):
x = self.layernorm(x)
cls = x[:, 0, :] # 去除class token
return self.mlphead(cls)
class ViT(nn.Module): # Vision Transformer
def __init__(self, image_channels=3, image_size=224, num_classes=1000, patch_size=16, dim=768, num_heads=12,
layers=12):
super(ViT, self).__init__()
self.embedding = Embedding(image_channels, image_size, patch_size, dim)
self.encoder = nn.Sequential(
*[EncoderBlock(dim, num_heads) for i in range(layers)] # encoder结构为layers(L)个Transformer Encoder Block
)
self.head = MLPHead(dim, num_classes)
def forward(self, x):
x_emb = self.embedding(x)
feature = self.encoder(x_emb)
return self.head(feature)
def vit_base(num_classes=1000): # ViT-Base
return ViT(image_channels=3, image_size=224, num_classes=num_classes, patch_size=16, dim=768, num_heads=12,
layers=12)
def vit_large(num_classes=1000): # ViT-Large
return ViT(image_channels=3, image_size=224, num_classes=num_classes, patch_size=16, dim=1024, num_heads=16,
layers=24)
def vit_huge(num_classes=1000): # ViT-Huge
return ViT(image_channels=3, image_size=224, num_classes=num_classes, patch_size=16, dim=1280, num_heads=16,
layers=32)
if __name__ == "__main__":
images = torch.randn(8, 3, 224, 224)
vb = vit_base()
vl = vit_large()
vh = vit_huge()
print(vb(images).shape)
print(vl(images).shape)
print(vh(images).shape)