图数据库——大数据时代的高铁
如果把传统关系型数据库比做火车的话,那么到现在大数据时代,图数据库可比做高铁。它已成为NoSQL中关注度最高,发展趋势最明显的数据库。
简介
在众多不同的数据模型里,关系数据模型自20世纪80年代就处于统治地位,而且出现了不少巨头,如Oracle、MySQL和MSSQL,它们也被称为关系数据库管理系统(RDBMS)。然而,随着关系数据库使用范围的不断扩大,也暴露出一些它始终无法解决问题,其中最主要的是数据建模中的一些缺陷和问题,以及在大数据量和多服务器之上进行水平伸缩的限制。同时,互联网发展也产生了一些新的趋势变化:
- 用户、系统和传感器产生的数据量呈指数增长,其增长速度因大部分数据量集中在Amazon、Google和其他云服务的分布式系统上而进一步加快;
- 数据内部依赖和复杂度的增加,这一问题因互联网、Web2.0、社交网络,以及对大量不同系统的数据源开放和标准化的访问而加剧。
而在应对这些趋势时,关系数据库产生了更多的不适应性,从而导致大量解决这些问题中某些特定方面的不同技术出现,它们可以与现有RDBMS相互配合或代替它们——亦被称为混合持久化(Polyglot Persistence)。数据库替代品并不是新鲜事物,它们已经以对象数据库(OODBMS)、层次数据库(如LDAP)等形式存在很长时间了。但是,过去几年间,出现了大量新项目,它们被统称为NoSQL数据库(NoSQL-databases)。
NoSQL数据库
NoSQL(Not Only SQL,不限于SQL)是一类范围非常广泛的持久化解决方案,它们不遵循关系数据库模型,也不使用SQL作为查询语言。其数据存储可以不需要固定的表格模式,也经常会避免使用SQL的JOIN操作,一般有水平可扩展的特征。
简言之,NoSQL数据库可以按照它们的数据模型分成4类:
- 键-值存储库(Key-Value-stores)
- BigTable实现(BigTable-implementations)
- 文档库(Document-stores)
- 图形数据库(Graph Database)
在NoSQL四种分类中,图数据库从最近十年的表现来看已经成为关注度最高,也是发展趋势最明显的数据库类型。图1就是db-engines.com对最近三年来所有数据库种类发展趋势的分析结果。
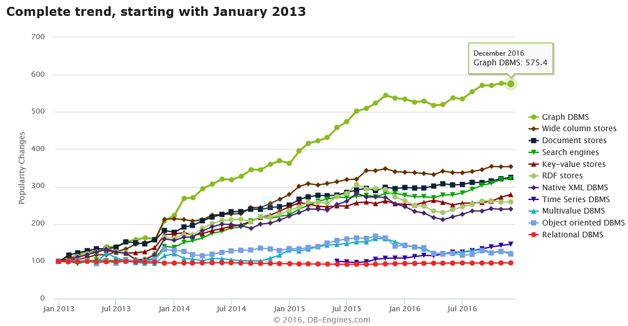
图数据库
图数据库源起欧拉和图理论,也可称为面向/基于图的数据库,对应的英文是Graph Database。图数据库的基本含义是以“图”这种数据结构存储和查询数据,而不是存储图片的数据库。它的数据模型主要是以节点和关系(边)来体现,也可处理键值对。它的优点是快速解决复杂的关系问题。
图具有如下特征:
- 包含节点和边;
- 节点上有属性(键值对);
- 边有名字和方向,并总是有一个开始节点和一个结束节点;
- 边也可以有属性。
说得正式一些,图可以说是顶点和边的集合,或者说更简单一点儿,图就是一些节点和关联这些节点的联系(relationship)的集合。图将实体表现为节点,实体与其他实体连接的方式表现为联系。我们可以用这个通用的、富有表现力的结构来建模各种场景,从宇宙火箭的建造到道路系统,从食物的供应链及原产地追踪到人们的病历,甚至更多其他的场景。
通常,在图计算中,基本的数据结构表达就是:
G=(V, E)
V=vertex(节点)
E=edge(边)
如图2所示。
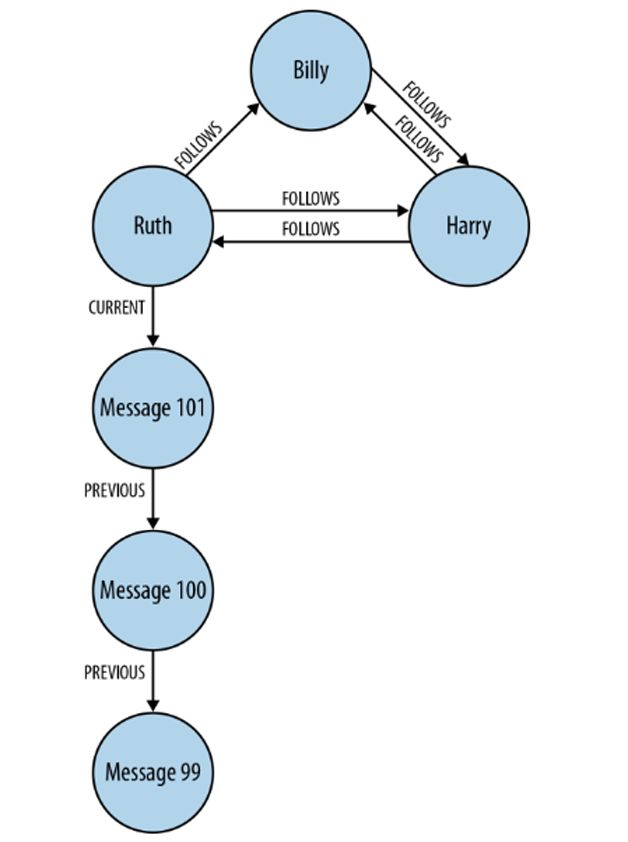
当然,图模型也可以更复杂,例如图模型可以是一个被标记和标向的属性多重图(multigraph)。被标记的图每条边都有一个标签,它被用来作为那条边的类型。有向图允许边有一个固定的方向,从末或源节点到首或目标节点。
属性图允许每个节点和边有一组可变的属性列表,其中的属性是关联某个名字的值,简化了图形结构。多重图允许两个节点之间存在多条边,这意味着两个节点可以由不同边连接多次,即使两条边有相同的尾、头和标记。如图3所示。
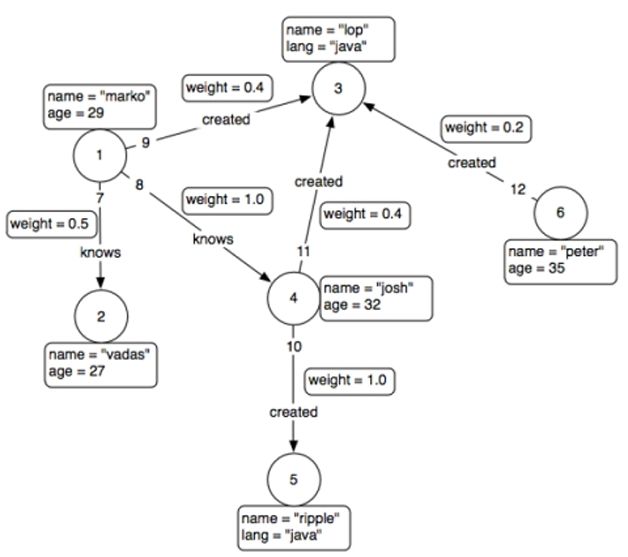
图数据库存储一些顶点和边与表中的数据。他们用最有效的方法来寻找数据项之间、模式之间的关系,或多个数据项之间的相互作用。
一张图里数据记录在节点,或包括的属性里面,最简单的图是单节点的,一个记录,记录了一些属性。一个节点可以从单属性开始,成长为成千上亿,虽然会有一点麻烦。从某种意义上讲,将数据用关系连接起来分布到不同节点上才是有意义的。
图计算是在实际应用中比较常见的计算类别,当数据规模大到一定程度时,如何对其进行高效计算即成为迫切需要解决的问题。大规模图数据,例如支付宝的关联图,仅好友关系已经形成超过1600亿节点、4000亿边的巨型图,要处理如此规模的图数据,传统的单机处理方式显然已经无能为力,必须采用由大规模机器集群构成的并行图数据库。
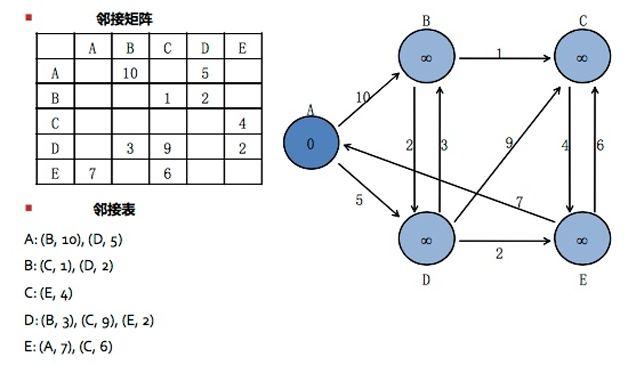
在处理图数据时,其内部存储结构往往采用邻接矩阵或邻接表的方式,图4就是这两种存储方式的简单例子。在大规模并行图数据库场景下,邻接表的方式更加常用,大部分图数据库和处理框架都采用了这一存储结构。
图数据库架构
在研究图数据库技术时,有两个特性需要多加考虑。
- 底层存储
一些图数据库使用原生图存储,这类存储是优化过的,并且是专门为了存储和管理图而设计的。不过并不是所有图数据库使用的都是原生图存储,也有一些会将图数据序列化,然后保存到关系型数据库或面向对象数据库,或是其他通用数据存储中。
原生图存储的好处是,它是专门为性能和扩展性设计建造的。但相对的,非原生图存储通常建立在非常成熟的非图后端(如MySQL)之上,运维团队对它们的特性烂熟于心。原生图处理虽然在遍历查询时性能优势很大,但代价是一些非遍历类查询会比较困难,而且还要占用巨大的内存。
- 处理引擎
图计算引擎技术使我们可以在大数据集上使用全局图算法。图计算引擎主要用于识别数据中的集群,或是回答类似于“在一个社交网络中,平均每个人有多少联系?”这样的问题。
图5展示了一个通用的图计算引擎部署架构。该架构包括一个带有OLTP属性的记录系统(SOR)数据库(如MySQL、Oracle或Neo4j),它给应用程序提供服务,请求并响应应用程序在运行中发送过来的查询。每隔一段时间,一个抽取、转换和加载(ETL)作业就会将记录系统数据库的数据转入图计算引擎,供离线查询和分析。
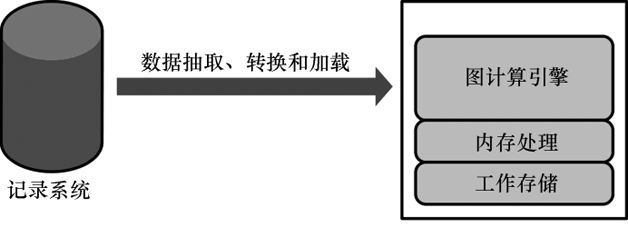
图计算引擎多种多样。最出名的是有内存的、单机的图计算引擎Cassovary和分布式的图计算引擎Pegasus和Giraph。大部分分布式图计算引擎基于Google发布的Pregel白皮书,其中讲述了Google如何使用图计算引擎来计算网页排名。
一个成熟的图数据库架构应该至少具备图的存储引擎和图的处理引擎,同时应该有查询语言和运维模块,商业化产品还应该有高可用HA模块甚至容灾备份机制。一个典型的图数据库架构如图6所示。
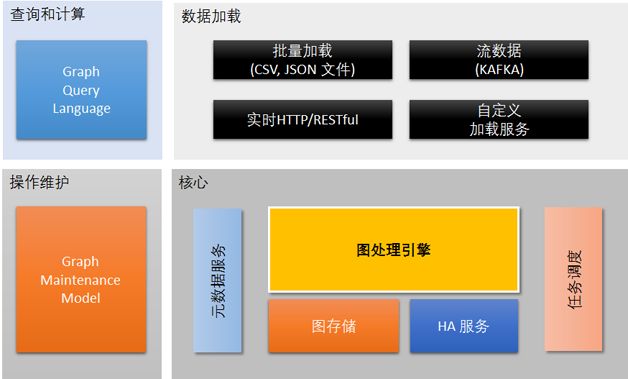
各模块功能说明如下:
- 查询和计算:最终用户用于在此语言基础之上进行图的遍历和查询,最终返回运行结果,如能提供RESTful API则能给开发者提供不少便利之处。
- 操作和运维:用于系统实时监控,例如系统配置、安装、升级、运行时监控,甚至包括可视化界面等。
- 数据加载:包括离线数据加载和在线数据加载,既可以是批量的数据加载,也可以是流数据加载方式。
- 图数据库核心:主要包括图存储和图处理引擎这两个核心。图处理引擎负责实时数
据更新和执行图运算;图存储负责将关系型数据及其他非结构化数据转换成图的存储格式;HA服务负责处理处理数据容错、数据一致性以及服务不间断等功能。
在图数据库和对外的接口上,图数据库应该也具有完备的对外数据接口和完善的可视化输出界面,如图7所示。
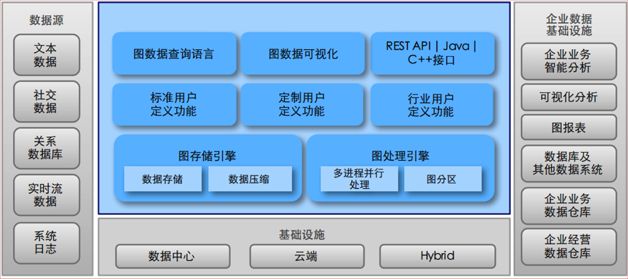
图数据库不仅可以导入传统关系型数据库中的结构化数据,也可以是文本数据、社交数据、机器日志数据、实时流数据等。
同时,计算结果可以通过标准的可视化界面展现出来,商业化的图数据库产品还应该能将图数据库中的数据进一步导出至第三方数据分析平台做进一步的数据分析。
图数据库的应用
我们可以将图领域划分成以下两部分:
- 用于联机事务图的持久化技术(通常直接实时地从应用程序中访问)。
- 这类技术被称为图数据库,它们和“通常的”关系型数据库世界中的联机事务处理(Online Transactional Processing,OLTP)数据库是一样的。
- 用于离线图分析的技术(通常都是按照一系列步骤执行)。
这类技术被称为图计算引擎。它们可以和其他大数据分析技术看做一类,如数据挖掘和联机分析处理(Online Analytical Processing,OLAP)。
图数据库一般用于事务(OLTP)系统中。图数据库支持对图数据模型的增、删、改、查(CRUD)方法。相应地,它们也对事务性能进行了优化,在设计时通常需要考虑事务完整性和操作可用性。
目前图数据库的巨大用途得到了认可,它跟不同领域的很多问题都有关联。最常用的图论算法包括各种类型的最短路径计算、测地线(Geodesic Path)、集中度测量(如PageRank、特征向量集中度、亲密度、关系度、HITS等)。那么,什么样的应用场景可以很好地利用图数据库?
目前,业内已经有了相对比较成熟的基于图数据库的解决方案,大致可以分为以下几类。
金融行业应用
反欺诈多维关联分析场景
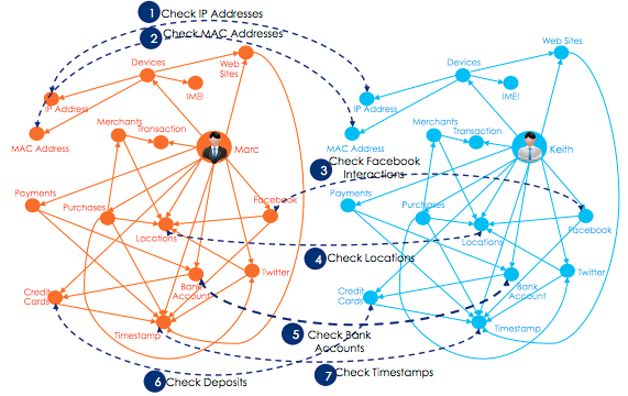
通过图分析可以清楚地知道洗钱网络及相关嫌疑,例如对用户所使用的帐号、发生交易时的IP地址、MAC地址、手机IMEI号等进行关联分析。
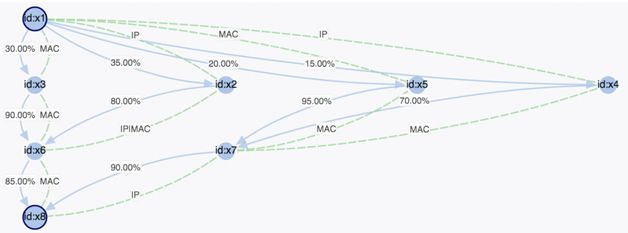
反欺诈多维关联分析场景
反欺诈已经是金融行业一个核心应用,通过图数据库可以对不同的个体、团体做关联分析,从人物在指定时间内的行为,例如去过地方的IP地址、曾经使用过的MAC地址(包括手机端、PC端、WIFI等)、社交网络的关联度分析,同一时间点是否曾经在同一地理位置附近出现过,银行账号之间是否有历史交易信息等。
社交网络图谱
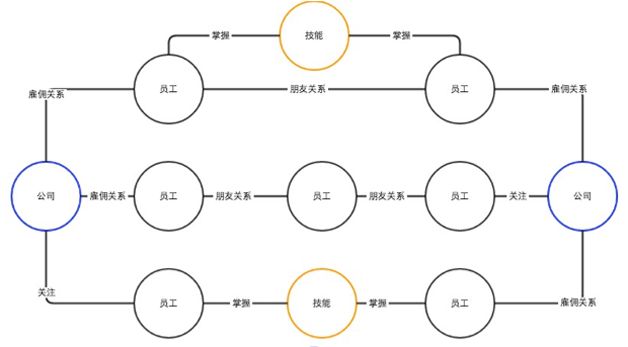
在社交网络中,公司、员工、技能的信息,这些都是节点,它们之间的关系和朋友之间的关系都是边,在这里面图数据库可以做一些非常复杂的公司之间关系的查询。比如说公司到员工、员工到其他公司,从中找类似的公司、相似的公司,都可以在这个系统内完成。
企业关系图谱
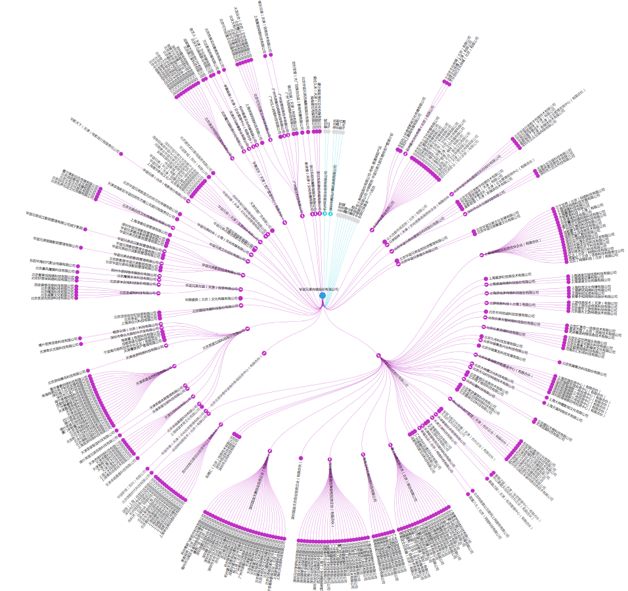
图数据库可以对各种企业进行信息图谱的建立,包括最基本的工商信息,包括何时注册、谁注册、注册资本、在何处办公、经营范围、高管架构。围绕企业的经营范围,继续细化去查询企业究竟有哪些产品或服务,例如通过企业名称查询到企业的自媒体,从而给予其更多关注和了解。另外也包括对企业的产品和服务的数据关联,查看该企业有没有令人信服的自主知识产权和相关资质来支撑业务的开展。
企业在日常经营中,与客户、合作伙伴、渠道方、投资者都会打交道,这也决定了企业对社会各个领域都广有涉猎,呈现面错综复杂,因此可以通过企业数据图谱来查询,层层挖掘信息。基于图数据的企业信息查询可以真正了解企业的方方面面,而不再是传统单一的工商信息查询。
图数据库的优缺点
数十年来,开发者试图使用关系型数据库处理关联的、半结构化的数据集。关系型数据库设计之初是为了处理纸质表格以及表格化结构,它们试图对这种实际中的特殊联系进行建模。然而讽刺的是,关系型数据库在处理联系上做得却并不好。
关系数据库是强大的主流数据库,经过40年的发展和改进,已经非常可靠、强大并且很实用,可以保存大量的数据。如果你想查询关系型数据库里的单一结构或对应数据信息的话,在任何时间内都可以查询关于项目的信息,或者你想查询许多项目在相同类型中的总额或平均值,也将会很快得到答案。
关系型数据库不擅长什么呢?当你寻找数据项、关系模式或多个数据项之间的关系时,它们常会以失败告终。
关系确实存在于关系型数据库自身的术语中,但只是作为连接表的手段。我们经常需要对连接实体的联系进行语义区分,同时限制它们的使用,但是关联关系什么也做不了。更糟糕的是,随着数据成倍地增加,数据集的宏观结构将愈发复杂和不规整,关系模型将造成大量表连接、稀疏行和非空检查逻辑。关系世界中连通性的增强都将转化为JOIN操作的增加,这会阻碍性能,并使已有的数据库难以响应变化的业务需求。
而图数据库天生的特点决定了其在关联关系上具有完全的优势,特别是在我们这个社交网络得到极大发展的互联网时代。例如我们希望知道谁LOVES(爱着)谁(无论爱是否是单相思的),也想知道谁是谁的COLLEAGUE_OF(同事),谁是所有人的BOSS_OF(老板)。我们想知道谁没有市场了,因为他们和别人是MARRIED_TO(结婚)联系。我们甚至可以通过数据库在其他社交网络中发现不善交际的元素,用DISLIKES(不喜欢)联系来表示即可。通过我们所掌握的这个图,就可以看看图数据库在处理关联数据时的性能优势了。
例如在下面这个例子中,我们希望在一个社交网络里找到最大深度为5的朋友的朋友。假设随机选择两个人,是否存在一条路径,使得关联他们的关系长度最多为5?对于一个包含100万人,每人约有50个朋友的社交网络,我们就以典型的开源图数据库Neo4j参与测试,结果明显表明,图数据库是用于关联数据的最佳选择,如表1所示。
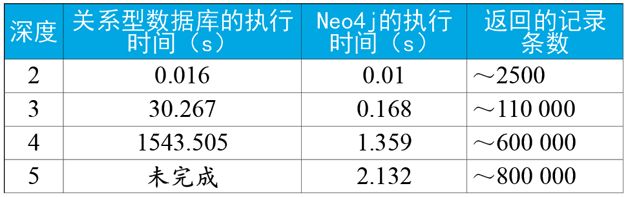
在深度为2时(即朋友的朋友),假设在一个在线系统中使用,无论关系型数据库还是图数据库,在执行时间方面都表现得足够好。虽然Neo4j的查询时间为关系数据库的2/3,但终端用户很难注意到两者间毫秒级的时间差异。当深度为3时(即朋友的朋友的朋友),很明显关系型数据库无法在合理的时间内实现查询:一个在线系统无法接受30s的查询时间。相比之下,Neo4j的响应时间则保持相对平坦:执行查询仅需要不到1s,这对在线系统来说足够快了。
在深度为4时,关系型数据库表现出很严重的延迟,使其无法应用于在线系统。Neo4j所花时间也有所增加,但其时延在在线系统的可接受范围内。最后,在深度为5时,关系型数据库所花时间过长以至于没有完成查询。相比之下,Neo4j则在2 s左右的时间就返回了结果。在深度为5时,事实证明几乎整个网络都是我们的朋友,因此在很多实际用例中,我们可能需要修剪结果,并进行时间控制。
将社交网络替换为任何其他领域时,你会发现图数据库在性能、建模和维护方面都能获得类似的好处。无论是音乐还是数据中心管理,无论是生物信息还是足球统计,无论是网络传感器还是时序交易,图都能对这些数据提供强有力而深入的理解。
而关系型数据库对于超出合理规模的集合操作普遍表现得不太好。当我们试图从图中挖掘路径信息时,操作慢了下来。我们并非想要贬低关系型数据库,它在所擅长的方面有很好的技术能力,但在管理关联数据时却无能为力。任何超出寻找直接朋友或是寻找朋友的朋友这样的浅遍历查询,都将因为涉及的索引数量而使查找变得缓慢。而图数据库由于使用的是图遍历技术,所需要计算的数据量远小于关系型数据库,所以非常迅速。
不过,图数据库也并非完美,它虽然弥补了很多关系型数据库的缺陷,但是也有一些不适用的地方,例如以下领域:
- 记录大量基于事件的数据(例如日志条目或传感器数据);
- 对大规模分布式数据进行处理,类似于Hadoop;
- 二进制数据存储;
- 适合于保存在关系型数据库中的结构化数据。
虽然图数据库也能够处理“大数据”,但它毕竟不是Hadoop、HBase或Cassandra,通常不会在图数据库中直接处理海量数据(以PB为单位)的分析。但如果你乐于提供关于某个实体及其相邻数据的关系(比如可以提供一个Web页面或某个API返回其结果),那么它是一种良好的选择。无论是简单的CRUD访问,或是复杂的、深度嵌套的资源视图都能够胜任。
综上所述,虽然关系型数据库对于保存结构化数据来说依然是最佳的选择,但图数据库更适合于管理半结构化数据、非结构化数据以及图形数据。如果数据模型中包含大量的关联数据,并且希望使用一种直观、有趣并且快速的数据库进行开发,那么可以考虑尝试图数据库。
在实际的生产环境下,一个真正成熟、有效的分析环境是应该包括关系型数据库和图数据库的,根据不同的应用场景相互结合起来进行有效分析。
整体而言,图数据库还有很多问题未解决,许多技术还需发展,比如超级节点问题和分布式大图的存储。可以预见的是,随着互联网数据的膨胀,图数据库将迎来发展契机,基于图的各种计算和数据挖掘岗位也会越来越热。