ubuntu darknet中选择cuda版本_darknet源码学习(一):在VS上构建并编译darknet解决方案...
1 darknet 简介
darknet是谷歌开发的一款轻量级神经网络框架,基于C语言和CUDA编写,其优点是代码非常精炼,运行速度快(经我测试,其在某些分类任务上的训练速度是PyTorch的至少10倍),同时易于迁移到实际工程中;缺点是不够灵活,只提供了最基本的训练和测试接口。因此,该框架非常适合在具有海量训练数据和固定单一的训练策略的情况下训练网络模型。darknet主要可以训练分类网络和目标检测模型,著名的深度学习目标检测算法YOLO(You Only Look Once)即是基于darknet实现的。
本系列文章首先介绍darknet的编译和使用方法,然后介绍darknet的代码结构和训练流程,接着将代码与YOLO论文相结合,详细介绍论文中的细节在代码中的具体实现。
2 准备工作
darknet原本是在linux系统上使用的框架,但是直接在linux系统上(尤其是一些没有图形界面的linux系统,例如Ubuntu server)学习C代码无疑会平添很大的难度,因为我们可能只能通过winSCP等工具远程一个个地查看C文件,同时代码缺少工程组织,导致我们可能在搜寻某个函数或者变量在多个不同的引用文件中的位置时消耗大量的时间和心力。
工欲行其事,必先利其器。幸运的是,在github上有一个毛大帝提供了darknet的VS工程,我们首先将其克隆到本地:https://github.com/AlexeyAB/darknet
有了这个工程,接下来要做的就是配置合适的运行环境,以及解决编译过程中可能遇到的错误和问题(通常是工程提供者和下载者的环境差异导致)。下面我将按照我的安装步骤对遇到的问题和解决方法进行记录。
下文的配置方法在 VS2019、CUDA开发套件10.1和CUDNN 环境下适用,显卡是1060 MAXQ,建议读者卸载电脑上其他版本的VS和CUDA开发套件。安装CUDA开发套件时必须勾选“VS整合模块”,否则VS可能无法正常识别或编译.cu文件;同时建议不要勾选安装程序中的驱动和其他的没卵用的东西,以免出现意外的错误。
3 配置流程和遇到的问题及解决方案
我首先使用CUDA开发套件11.1进行编译。
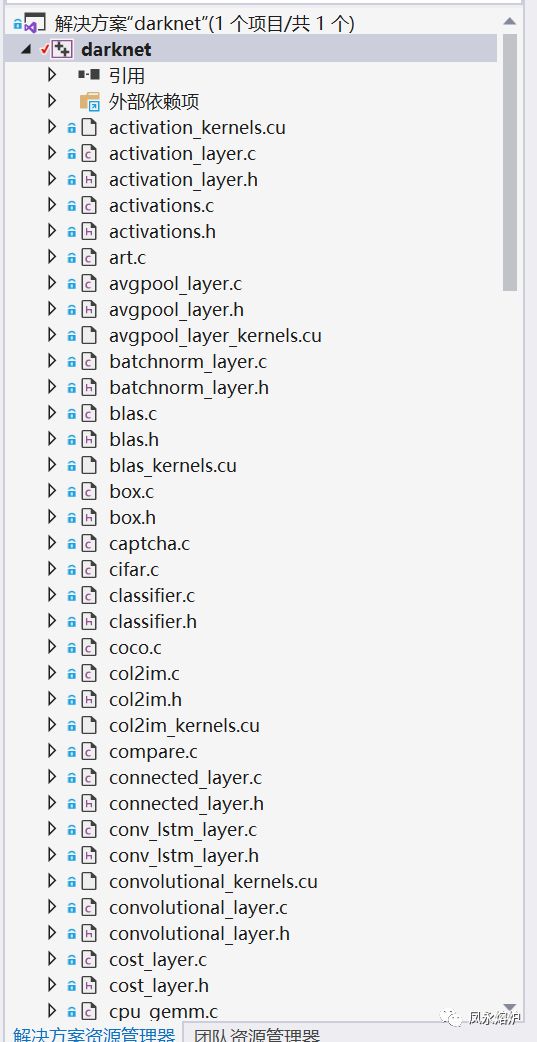
使用VS2019打开工程解决方案darknet.sln,这时我们可以看到已经被组织好的工程:
先配置Release版本。
错误1
现在我们将解决方案平台设置为Release x64,重新生成整个工程,可以看到报错信息:找不到xxx10.1.props。这是因为工程配置文件中配置的是10.1的CUDA,而我们装的是11.1的CUDA,因此会报错。解决方法很简单,进入 build\darknet\ 目录,打开darknet.vcxproj,这是GPU版本的darknet的VS工程配置文件。将其中的两处CUDA版本号10.1替换为11.1。
...
"$(VCTargetsPath)\Microsoft.Cpp.props" />"ExtensionSettings">"$(VCTargetsPath)\BuildCustomizations\CUDA 11.1.props" />
..."$(VCTargetsPath)\Microsoft.Cpp.targets" />"ExtensionTargets">"$(VCTargetsPath)\BuildCustomizations\CUDA 11.1.targets" />我一开始装的是10.1的CUDA,但是后续会遇到诸如CL.EXE找不到等等奇怪的错误,11.1的错误少一些。
有时即使在安装CUDA时勾选了整合VS,这里配置完了可能还是会报错,这时需要从CUDA的解压包中手动将11.1.props及其同目录下的文件复制到错误信息说的那个路径下。
错误2
再次编译,还是报错,找不到opencv相关,打开项目属性,把附加包含目录和链接器配置成自己机器上的opencv相关参数即可,我用的是opencv440。
现在再次编译,Release版本通过。
然后配置Debug版本,这是主要的。
Debug版本配置起来比较麻烦,错误比较多。
错误3
首先按照上述配置消除错误1和2,然后编译,可以发现出现了新的错误:
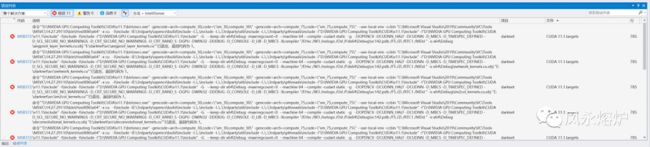
这个问题乍一看让人摸不着头脑,但是不要着急,看一下编译输出:
"D:\NVIDIA GPU Computing Toolkit\CUDA\v11.1\bin\nvcc.exe" -gencode=arch=compute_30,code=\"sm_30,compute_30\" -gencode=arch=compute_75,code=\"sm_75,compute_75\" --use-local-env -ccbin 这时就明白了,原来debug版本的工程配置文件中的算力设置的是30,而11.1的CUDA已经不支持30了,因此将30改为与Release的配置相同的35,这个问题就解决了。
错误4
再次编译,发现还是通不过:

这次难办了,跟上一个错误类似,但是没有任何提示,怎么办呢?
我先是试图把这个nvcc的编译命令复制到命令行里执行查看具体的错误是什么,然后发现在命令行里执行和VS执行的环境有差异,导致出现了新的错误,因此这样做不是一个高效的方案。
不要担心,既然Release模式都编过了,那么只要研究一下Debug和Release在编译时的参数有哪些不同,把有差异的参数挨个删除,直到错误消失即可。现在我们再看一下工程配置文件,对比一下二者的预定义宏:
OPENCV;CUDNN_HALF;CUDNN;_CRTDBG_MAP_ALLOC;_MBCS;_TIMESPEC_DEFINED;_SCL_SECURE_NO_WARNINGS;_CRT_SECURE_NO_WARNINGS;_CRT_RAND_S;GPU;WIN32;DEBUG;_CONSOLE;_LIB;%(PreprocessorDefinitions)
OPENCV;CUDNN_HALF;CUDNN; _TIMESPEC_DEFINED;_SCL_SECURE_NO_WARNINGS;_CRT_SECURE_NO_WARNINGS;_CRT_RAND_S;GPU;WIN32; _CONSOLE;_LIB;%(PreprocessorDefinitions)
可见,Debug模式下的宏比Release多了几个,逐个删除之后发现,是_CRTDBG_MAP_ALLOC的存在,导致了编译失败,删除这个宏之后,错误消失。
错误5
再次编译,发现还是编不过,但是这次错误简单多了:
![]() 可见是
可见是convolutional_kernels.cu中调用了函数show_image_cv,但是链接器找不到函数show_image_cv的实现,导致报错:

这个函数是在image.c里定义的。看一下上边的预定义宏可以发现,明明已经添加了宏OPENCV,为什么还是找不到呢?因为下边还有一行忽略宏列表:
OPENCV;
这个列表中添加的宏会再次被去掉,因此删除该行即可。
错误6
现在我们运行检测命令:
E:\darknet>E:\darknet\build\darknet\x64\darknet.exe detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
没想到在运行时出现了新的错误:
This indicates that the provided PTX was compiled with an unsupported toolchain.
这个错误的解释可以在英伟达官方手册(https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__TYPES.html)中找到:
This indicates that the provided PTX was compiled with an unsupported toolchain. The most common reason for this, is the PTX was generated by a compiler newer than what is supported by the CUDA driver and PTX JIT compiler.
也就是说,CUDA开发套件11.1的版本过高,高于当前CUDA驱动的版本。因此,在11.1上编译出来的darknet是无法使用的。无奈之下我只能卸载了11.1然后重新安装了10.1。
错误7
回退到10.1版本后,按照当前的配置执行编译,可以看到报错:

尽管上边的nvcc命令报了很多错误,但是这些命令都是由下边的.PDB文件无法写入衍生出来的。而该错误也指出了解决方案,即在编译命令中添加“/FS”指令。注意,这个命令需要添加在工程属性 -> CUDA C/C++ -> Host的Additional Compiler Options中,在C/C++中配置无效。
添加该指令后,在CUDA 10.1平台下的编译终于通过了,现在再次执行检测命令,我们终于可以看到狗图的检测结果了。

至此,Darknet的Win10 GPU VS 编译终于成功。后续我们可以在强大的VS中学习darknet代码了,这样会方便很多。